一种基于GAT-SVM的非侵入式设备状态识别方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及非侵入式设备识别技术领域,具体为一种基于GAT-SVM的非侵入式设备状态识别方法。
背景技术
非侵入式设备状态识别是指通过对设备的负荷数据进行分析和处理,从而实现对设备状态的识别,而不需要对设备进行任何改动或者干预,这种方法可以避免对设备的损坏或者影响设备的正常运行。
通常,非侵入式设备状态识别需要通过对设备的负荷数据进行采集和处理,提取设备的负荷特征,并将其与已知设备的负荷特征进行比对,从而实现对设备状态的识别。
然而,现有的非侵入式设备状态识别方法,存在以下问题:
1、提取设备的负荷特征,大多采用手工设计的特征来表示设备节点之间的关系,手工设计的特征往往无法充分表达设备之间的关系,从而增加获取设备之间的关联和交互的难度;
2、大多未对获取设备状态识别模型的支持向量机进行参数优化,设备状态识别模型可能存在过拟合或欠拟合,导致识别设备状态的准确性低。
发明内容
本发明的目的在于提供一种基于GAT-SVM的非侵入式设备状态识别方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种基于GAT-SVM的非侵入式设备状态识别方法,包括:
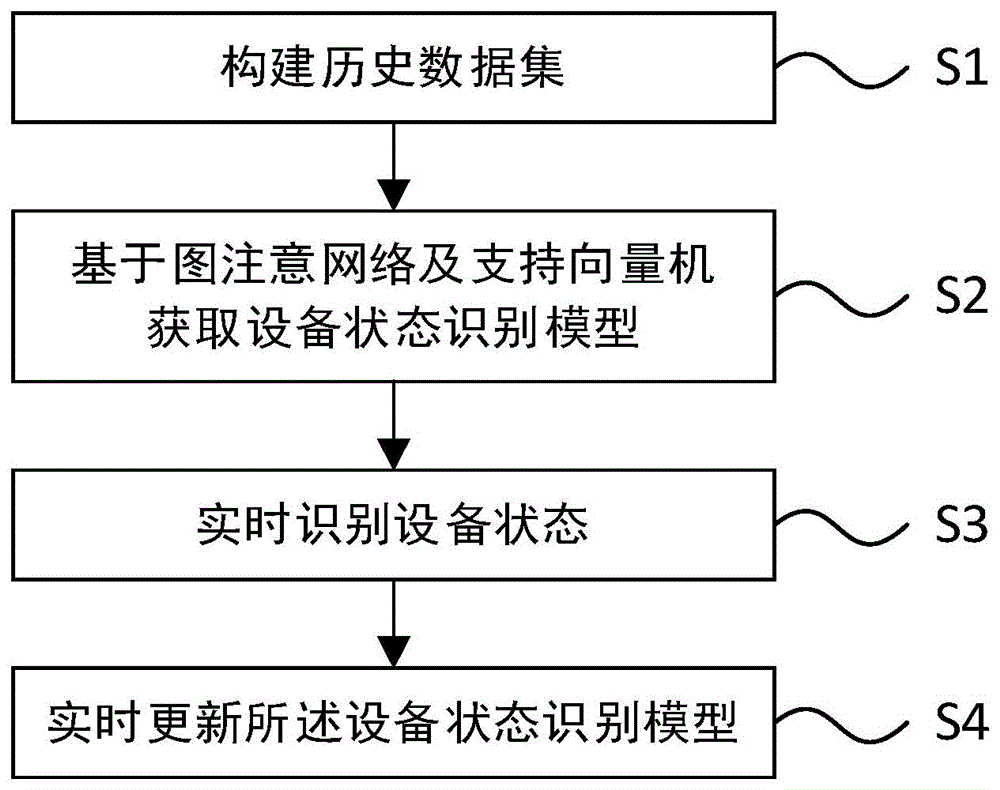
步骤S1:构建历史数据集。
步骤S2:基于图注意网络及支持向量机获取设备状态识别模型。
步骤S3:实时识别设备状态。
步骤S4:实时更新所述设备状态识别模型。
所述步骤S1,具体包括以下步骤:
步骤S1.1:对多个设备节点的设备历史数据进行采集,每个所述设备节点对应一个设备。
所述历史数据包括历史负荷数据及历史设备状态。
步骤S1.2:对所述历史数据进行预处理。
步骤S1.3:根据每个所述设备节点,对所述历史数据构建历史数据集,每个所述设备节点对应一个所述历史数据集。
所述图注意网络,用于对所述历史数据集进行特征提取,得到特征向量。
所述支持向量机,用于根据所述特征向量,获取所述设备状态识别模型。
所述步骤S2,具体包括以下步骤:
步骤S2.1:利用所述图注意网络对所述历史数据集中的所述历史负荷数据进行特征提取,并对所述设备节点之间的关系和特征进行学习和建模,得到每个所述设备的所述特征向量。
所述特征向量,用于表示多个所述设备之间的复杂关系和特征信息。
所述特征包括稳态特征和暂态特征。
步骤S2.2:将所述历史数据集中的所述历史设备状态与对应的所述特征向量进行关联,形成训练数据集。
步骤S2.3:通过所述支持向量机,学习所述历史设备状态的分类决策边界,获取所述设备状态识别模型。
所述分类决策边界用于对所述训练数据集进行分类。
步骤S2.4:通过交叉验证评估所述设备状态识别模型的性能和泛化能力。
步骤S2.5:将所述设备状态识别模型进行存储,用于所述步骤S3。
所述步骤S3,具体包括以下步骤:
步骤S3.1:实时获取每个所述用户节点的负荷数据。
步骤S3.2:对所述负荷数据进行所述预处理。
步骤S3.3:将经过所述预处理的所述负荷数据作为所述设备状态识别模型的输入。
步骤S3.4:所述设备状态识别模型输出所述设备状态,实现对所述设备状态进行分类和识别。
所述步骤S4,具体包括以下步骤:
步骤S4.1:根据所述负荷数据及所述设备状态,更新所述历史数据集。
步骤S4.2:根据更新后的所述历史数据集,更新所述训练数据集。
步骤S4.3:通过所述支持向量机,更新所述设备状态识别模型。
所述步骤S2.1,具体包括以下步骤:
步骤S2.1.1:以第一特征对每个所述设备节点进行表示。
步骤S2.1.2:构建多个所述设备节点的特征组合。
所述特征组合的表达式为h={h
步骤S2.1.3:利用所述特征组合构建图结构。
步骤S2.1.4:对每个所述第一特征进行卷积操作,得到每个所述设备节点的新特征表示,以第二特征作为所述设备节点的新特征表示。
步骤S2.1.5:对所述第二特征进行加权,得到第三特征。
所述第三特征,用于获取多个所述设备节点之间的关系。
步骤S2.1.6:对所述第三特征进行池化操作,得到所述图结构的所述特征向量。
所述步骤S2.3,具体包括以下步骤:
步骤S2.3.1:初始化克隆免疫算法的具体参数。
所述具体参数包括克隆选择因子、免疫浓度、危险度及最大迭代次数。
所述克隆选择因子,影响着克隆操作时生成克隆群体的规模。
所述免疫浓度,用于反映抗体的多样性。
所述危险度,用于反映所述抗体的稳定性。
所述最大迭代次数,用于限制所述克隆免疫算法的运行次数。
步骤S2.3.2:设置所述支持向量机参数的上边界和下边界。
所述参数的表达式为(C,g),其中,C为惩罚因子,g为核函数参数。
所述参数的所述上边界及所述下边界,用于防止所述参数过大或过小。
步骤S2.3.3:计算初始多个抗体的适应度。
步骤S2.3.4:根据所述适应度大小进行克隆操作,产生克隆群体,并确定当前最优适应度以及所述抗体对应的最优位置。
步骤S2.3.5:根据所述免疫浓度和所述克隆选择因子的大小,更新所述克隆群体的位置。
步骤S2.3.6:根据所述免疫浓度和所述危险度的大小,更新所述抗体的位置。
步骤S2.3.7:计算多个所述抗体的实时适应度,将所述实时适应度与所述最优适应度进行比较,取全局最优适应度以及对应的抗体位置。
步骤S2.3.8:判断是否达到所述最大迭代次数。
若满足条件,将当前的所述参数作为所述支持向量机的最优参数;若不满足,则返回至所述步骤S2.3.3。
步骤S2.3.9:利用具有所述最优参数的所述支持向量机,根据所述训练数据集,获取所述设备状态识别模型。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
与现有技术相比,本发明的有益效果是:
1、通过图注意网络提取设备分负荷特征,可以自动学习设备节点之间的关系,并且在图结构数据中进行信息传播,从而减少获取设备之间的关联和交互的难度;
2、通过克隆免疫算法优化支持向量机的参数,可以找到更合适的参数配置,可以提高设备状态识别模型对设备状态的识别准确性。
附图说明
为了更清楚地说明本发明的实施方式或现有技术中的技术方案,下面将对实施方式或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图引申获得其他的实施附图。
图1为本发明整体流程图;
图2为本发明部分流程图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置的例子。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见图1所示,本发明提供一种基于GAT-SVM的非侵入式设备状态识别方法,包括:
步骤S1:构建历史数据集。
步骤S2:基于图注意网络及支持向量机获取设备状态识别模型。
步骤S3:实时识别设备状态。
步骤S4:实时更新所述设备状态识别模型。
所述图注意网络(GAT),用于对所述历史数据集进行特征提取,得到特征向量。
所述支持向量机(SVM),用于根据所述特征向量,获取所述设备状态识别模型。
所述步骤S1,具体包括以下步骤:
步骤S1.1:对多个设备节点的设备历史数据进行采集,每个所述设备节点对应一个设备。
所述历史数据包括历史负荷数据及历史设备状态。
步骤S1.2:对所述历史数据进行预处理。
所述预处理包括但不限于数据清洗、去噪及数据对齐,以确保所述历史负荷数据的质量和准确性。
步骤S1.3:根据每个所述设备节点,对所述历史数据构建历史数据集,每个所述设备节点对应一个所述历史数据集。
所述步骤S2,具体包括以下步骤:
步骤S2.1:对所述历史数据集中的所述历史负荷数据进行特征提取,利用所述图注意网络对所述设备节点之间的关系和特征进行学习和建模,得到每个所述设备的所述特征向量。
所述特征向量,用于表示多个所述设备之间的复杂关系和特征信息。
所述特征包括稳态特征和暂态特征。
所述稳态特征,为启动或关断所述设备前后,负荷处于稳定运行状态下的稳态电气量,所述电气量包括但不限于有功功率、无功功率、电流有效值、电流幅值、电流波峰系数、电压电流轨迹曲线、电流直流分量、三次谐波及五次谐波。
所述暂态特征,为启动或关断所述设备前后,负荷发生变化后短暂的时间内,发生变化的暂态电气量,所述暂态电气量包括但不限于电流脉冲峰值、暂态过程持续时间及电流凹凸系数。
步骤S2.2:将所述历史数据集中的所述历史设备状态与对应的所述特征向量进行关联,形成训练数据集。
步骤S2.3:利用所述支持向量机,学习所述历史设备状态的分类决策边界,获取所述设备状态识别模型。
所述分类决策边界用于对所述训练数据集进行分类。
步骤S2.4:利用交叉验证评估所述设备状态识别模型的性能和泛化能力,确保所述设备状态识别模型能够准确地对所述设备状态进行分类和识别。
步骤S2.5:将所述设备状态识别模型进行存储,用于所述步骤S3。
所述步骤S3,具体包括以下步骤:
步骤S3.1:实时获取每个所述用户节点的负荷数据。
步骤S3.2:对所述负荷数据进行所述预处理。
步骤S3.3:将经过所述预处理的所述负荷数据作为所述设备状态识别模型的输入。
步骤S3.4:所述设备状态识别模型输出所述设备状态,实现对所述设备状态进行分类和识别。
所述步骤S4,具体包括以下步骤:
步骤S4.1:根据所述负荷数据及所述设备状态,更新所述历史数据集。
步骤S4.2:根据更新后的所述历史数据集,更新所述训练数据集。
步骤S4.3:通过所述支持向量机,更新所述设备状态识别模型。
所述步骤S2.1,具体包括以下步骤:
步骤S2.1.1:以第一特征对每个所述设备节点进行表示。
步骤S2.1.2:构建多个所述设备节点的特征组合。
所述特征组合的表达式为h={h
步骤S2.1.3:利用所述特征组合构建图结构。
步骤S2.1.4:对每个所述第一特征进行卷积操作,得到每个所述设备节点的新特征表示,以第二特征作为所述设备节点的新特征表示。
步骤S2.1.5:对所述第二特征进行加权,得到第三特征。
所述第三特征,用于获取多个所述设备节点之间的关系。
步骤S2.1.6:对所述第三特征进行池化操作,得到所述图结构的所述特征向量。
通过所述图注意网络提取设备分负荷特征,可以自动学习设备节点之间的关系,并且在图结构数据中进行信息传播,从而减少获取设备之间的关联和交互的难度。这种工作方式解决了现有技术中存在“提取设备的负荷特征,大多采用手工设计的特征来表示设备节点之间的关系,手工设计的特征往往无法充分表达设备之间的关系,从而增加获取设备之间的关联和交互的难度”的问题。
所述步骤S2.3,具体包括以下步骤:
步骤S2.3.1:初始化克隆免疫算法的具体参数。
所述具体参数包括克隆选择因子、免疫浓度、危险度及最大迭代次数。
所述克隆选择因子,影响着克隆操作时生成克隆群体的规模,通过调整克隆选择因子可以控制克隆操作时生成所述克隆群体的规模,即控制所述克隆群体的大小,从而影响所述克隆免疫算法的收敛速度和全局搜索能力。
所述免疫浓度,用于反映抗体的多样性,免疫浓度越大,所述抗体的多样性越高,使所述克隆免疫算法的全局搜索能力提高。
所述危险度,用于反映所述抗体的稳定性,通过所述危险度可以对所述抗体进行更新和调整,以保持所述克隆免疫算法的稳定性和收敛性。
所述最大迭代次数,用于限制所述克隆免疫算法的运行次数,避免所述克隆免疫算法陷入无限循环,还可以控制所述克隆免疫算法的收敛速度和搜索能力。
步骤S2.3.2:设置所述支持向量机参数的上边界和下边界。
所述参数的表达式为(C,g),其中,C为惩罚因子,g为核函数参数。
所述参数的所述上边界及所述下边界,用于防止所述参数过大或过小,使所述参数在一个合理的范围内进行搜索和调整,从而提高所述支持向量机的泛化能力和稳定性。
步骤S2.3.3:计算初始多个抗体的适应度。
步骤S2.3.4:根据所述适应度大小进行所述克隆操作,产生所述克隆群体,并确定当前最优适应度以及所述抗体对应的最优位置。
步骤S2.3.5:根据所述免疫浓度和所述克隆选择因子的大小,更新所述克隆群体的位置。
通过结合所述免疫浓度和所述克隆选择因子的大小,可以根据所述抗体的多样性和所述克隆群体规模来调整所述克隆群体的位置,以达到更好的全局搜索能力和收敛速度。
步骤S2.3.6:根据所述免疫浓度和所述危险度的大小,更新所述抗体的位置。
通过结合所述免疫浓度和所述危险度的大小,可以根据所述抗体的多样性和稳定性来调整所述抗体的位置,以保持所述克隆免疫算法的稳定性和全局搜索能力。
步骤S2.3.7:计算多个所述抗体的实时适应度,将所述实时适应度与所述最优适应度进行比较,取全局最优适应度以及对应的抗体位置。
步骤S2.3.8:判断是否达到所述最大迭代次数。
若满足条件,将当前的所述参数作为所述支持向量机的最优参数;若不满足,则返回至所述步骤S2.3.3。
步骤S2.3.9:利用具有所述最优参数的所述支持向量机,根据所述训练数据集,获取所述设备状态识别模型。
通过所述克隆免疫算法优化所述支持向量机的参数,可以找到更合适的参数配置,可以提高设备状态识别模型对设备状态的识别准确性。这种工作方式解决了现有技术中“大多未对获取设备状态识别模型的支持向量机进行参数优化,设备状态识别模型可能存在过拟合或欠拟合,导致识别设备状态的准确性低”的问题。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
以上对本发明及其实施方式进行了描述,这种描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的内容并不局限于此,总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
- 一种BI系统多源数据库跨源跨库融合系统和融合方法
- 一种多源异构数据跨系统协同管理系统及方法
- 多源异构数据跨系统协同处理方法及系统