一种基于多尺度特征并行融合的水下实时图像增强网络
文献发布时间:2024-04-18 20:01:30
技术领域
本发明属于图像处理技术领域,涉及一种基于多尺度特征并行融合的水下实时图像增强网络。
背景技术
水下图像增强任务是利用计算机视觉技术,来提高在水下环境中拍摄图像的质量和可视化效果。由于水下环境对光线的散射、折射等物理现象,获取到的真实水下图像经常出现对比度低、色彩失真、模糊、噪声等问题。这些问题对图像的利用和进一步分析造成了一定的阻碍。水下图像增强通过图像处理技术来缓解这些问题,从而获得更加清晰、蕴含信息更加丰富的图像。
尽管水下图像增强在各个领域都有重要的应用,但仍然存在一些挑战限制了其的有效性和实际落地应用。通过考虑水下光照条件和水环境特征,建立物理模型并对图像进行处理是一项复杂的任务。不同的水域和不同深度的水下环境,导致图像质量差异显著,难以建立一个普适性较高的物理模型。水下光照的波动和不规则性条件,阻碍了算法对图像细节和纹理特征的精确恢复。水下图像经常会遇到多种复杂的环境噪声、色彩失真、伪影等问题,进一步地导致了图像信息的丢失。克服这些困难并保证获取到有价值的信息是一个艰巨的任务。尤其是在实时水下机器人导航的应用场景中,迫切需要快速有效地进行图像增强的解决方法。解决这些苛刻的问题是当前的关键挑战。
现有的水下图像增强方法主要分为三类:基于视觉先验的方法、基于物理的方法和数据驱动的方法。虽然这些技术在一定程度上提高了水下图像的质量,但仍然存在一定的局限性。基于视觉先验的方法使用颜色校正、直方图均衡化和小波变换等技术来提高图像的对比度和清晰度。然而,这样的方法在处理复杂的问题时依然存在一定问题,比如照明条件变化和色彩失真。基于物理模型的技术主要通过对水下光的传播和水环境等因素进行建模,以减少光照波动和散射对图像带来的影响。然而,利用此方法需要精确的环境数据,并且在处理复杂的真实水下条件时,可能无法全面考虑多种因素的复杂关系。利用卷积神经网络(cnn)和生成对抗网络(gan)的数据驱动技术在学习水下图像特征上的有效性已经被证明。其能够完成诸如去噪、增强等任务,并在图像的质量效果上取得了显著提升。目前用于水下图像增强的深度学习模型虽然取得了成功,但仍有挑战需要克服。首先,深度学习模型的参数量太多,限制了其在嵌入式设备上的实时图像增强应用。而图像处理的实时性对水下机器人的作业任务至关重要,高计算量阻碍了对实时图像增强的需求满足。其次,复杂的模型需要大量的数据集来充分学习水下图像的特征。然而,目前可用于训练的水下环境数据集有限,尤其是缺少高质量标注的数据集。这种数据的稀缺的情况,对大参数模型训练造成了极大的阻碍,并且影响了模型的性能和泛化能力。
发明内容
为解决上述技术问题,本发明的目的是提供一种基于多尺度特征并行融合的水下实时图像增强网络,能利用极少的参数量达到良好地满足实时性的需求,使恢复的图像色彩更加鲜艳、饱满。
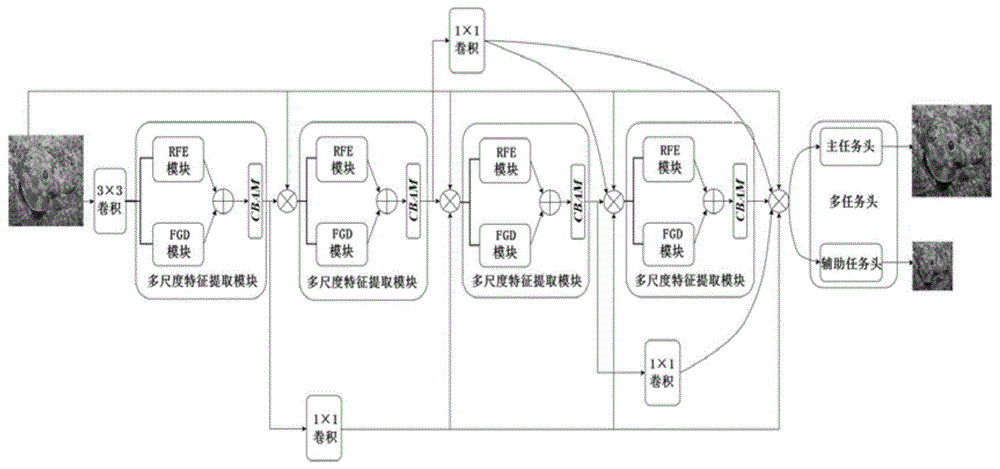
本发明提供一种基于多尺度特征并行融合的水下实时图像增强网络,包括四个串行连接的多尺度特征提取模块,所述多尺度特征提取模块包括感受野增强模块、细节优化模块和CBAM模块,感受野增强模块和细节优化模块的并行输出相加后通过CBAM模块处理后作为多尺度特征提取模块的输出;图像经过3×3的卷积处理后输入到第一个多尺度特征提取模块,当前多尺度特征提取模块的输出与原图以及之前所有阶段的多尺度特征提取模块的输出进行通道维度上的堆叠作为下一个阶段的输入,使整个网络模型形成稠密连接;水下图像经过四个多尺度特征提取模块的特征提取后,分别输出到一个主任务头和一个辅助任务头,实现在不同尺度上的监督。
进一步的,其特征在于,所述感受野增强模块能够扩大卷积核的感受野,使网络能够从输入图像中捕获更多的上下文信息;
特征图输入到感受野增强模块后先通过一个步长为2的3×3卷积层,在减小特征图尺寸的同时增加通道数,使后续的卷积核能获取到更大空间范围的信息;然后通过简单的近邻插值进行上采样,恢复到原有尺寸,并采用1×1卷积层减小通道数后与此模块输入的特征图进行通道维度上的堆叠;最后再通过3×3卷积对特征细化、融合。
进一步的,所述细节优化模块使网络模型更好地获取局部信息,增强图像的细节特征;
特征图输入到细节优化模块后进行近邻上采样,使图像的高度和宽度都变为原来的2倍;接着通过1×1卷积层降低通道数,再通过步长为2的3×3卷积层,将特征图尺寸变化到原来大小;最后用3×3卷积层在改变通道数的同时,进一步细化微小的特征。
进一步的,主任务头负责相同尺寸的训练监督,辅助任务头在采用步长为2的3×3卷积核缩小特征图后,对缩小尺寸的图像进行训练监督。
进一步的,网络模型训练的损失函数L
L
L
其中,α和β是超参数,设置为0.7和5;L
进一步的,根据下式计算均方误差损失:
其中,B为批次大小,C为通道数,H和W分别为图像的高度和宽度,out
进一步的,根据下式计算VGG损失:
其中,M表示在VGG模型中提取的特征数量,VGG(out
进一步的,根据下式计算SSIM损失:
其中,x和y分别表示两个输入图像,μ
本发明的一种基于多尺度特征并行融合的水下实时图像增强网络,至少具有以下有益效果:
1、本发明的网络通过在不同图像尺度上提取特征,并利用稠密连接来充分利用网络模型不同阶段提取的特征。其仅采用了最小0.21MB的参数量,就能够良好地满足水下图像增强的实时性需求,有助于降低计算成本和提高实时性。
2、本发明的网络能够在Jetson Orin Nano开发板上达到最高52FPS的推理速度。其实时性和硬件兼容性,使其在水下机器人应用中具有重要价值。
3、采用本发明的图像增强网络,可提高水下图像的质量,有助于提高任务执行效率、导航精度和决策制定等各个水下机器人系统模块的执行效率和精度。这种关联性使得本发明的图像增强技术,在水下机器人系统中具有关键作用,提高了系统整体性能,使其更适用于各种任务,包括水下搜索、勘察、科学研究和资源管理。
附图说明
图1是本发明的一种基于多尺度特征并行融合的水下实时图像增强网络的结构图;
图2是感受野增强模块的示意图;
图3是细节优化模块的示意图。
具体实施方式
如图1所示,本发明的一种基于多尺度特征并行融合的水下实时图像增强网络,包括四个串行连接的多尺度特征提取模块,多尺度特征提取模块包括感受野增强模块(Receptive Field Enhanced,RFE)、细节优化模块(Fine-Grained Detail,FGD)和CBAM模块,感受野增强模块和细节优化模块的并行输出相加后通过CBAM模块处理后作为多尺度特征提取模块的输出。水下图像经过3×3的卷积处理后输入到第一个多尺度特征提取模块,当前多尺度特征提取模块的输出与原图以及之前所有阶段的多尺度特征提取模块的输出进行通道维度上的堆叠作为下一个阶段的输入,使整个网络模型形成稠密连接。水下图像经过四个多尺度特征提取模块的特征提取后,分别输出到一个主任务头和一个辅助任务头,实现在不同尺度上的监督。
当前多尺度特征提取模块的输出与之前阶段的多尺度特征提取模块的输出进行通道维度上的堆叠前,需要通过1×1卷积降低前面多尺度特征提取模块的输出的通道数后,再进行通道维度上堆叠。
本发明中采用稠密连接的网络形式促进了网络不同阶段之间的特征信息流动和重复利用,增强了网络模型捕获不同层次特征的能力。此外,稠密连接还利于梯度的反向传播,并在增强图像细节的同时,能够良好地保留原图的特征,得到更好的图像增强效果。
本发明采用CBAM模块将注意力机制同时运用在通道和空间两个维度上,其能告诉网络模型该注意什么,同时也能增强特定区域的表征。在不显著增加计算量和参数量的前提下能提升网络模型的特征提取能力。
如图2所示,本发明的感受野增强模块能够扩大卷积核的感受野,使网络能够从输入图像中捕获更多的上下文信息。特征图输入到感受野增强模块后先通过一个步长为2的3×3卷积层,在减小特征图尺寸的同时增加通道数,使后续的卷积核能获取到更大空间范围的信息。然后通过简单的近邻插值进行上采样,恢复到原有尺寸。并采用1×1卷积层减小通道数后与此模块输入的特征图进行通道维度上的堆叠,起到残差连接的效果,最后再通过3×3卷积进一步对特征细化、融合。
如图3所示,细节优化模块使网络模型更好地获取局部信息,从而增强图像的细节特征。特征图输入到细节优化模块后进行近邻上采样,使图像的高度和宽度都变为原来的2倍。接着通过1×1卷积层降低通道数,减少后续算力的开销。再通过步长为2的3×3卷积层,将特征图尺寸变化到原来大小。最后用3×3卷积层在改变通道数的同时,进一步细化微小的特征。本发明的细节优化模块不仅提高了网络模型提取局部特征的能力,还在整个过程中保证了较高的计算效率。
本发明中对于图像增强任务,采用了多任务头,其中一个主任务头负责相同尺寸的训练监督,利于图像细节上的重建。另一个辅助任务头在采用步长为2的3×3卷积核缩小特征图后,对H/2,W/2尺寸的图像进行监督,H、W为特征图的高度和宽度。通过设置多任务头能够增强卷积核的感受野,获取更多的区域信息进行反馈,在梯度的反向传播中,有利于模型更好地优化。
为了更好的对图像进行细节上的增强,针对图像细节增强困难的问题,采用MSE损失进行像素层面的衡量,并用L1损失对VGG模型提取的图像语义信息进行评估。其中,VGG模型是深度学习领域的经典模型,经常被用于提取图像的特征信息。此外,考虑到图像不同区域的亮度、对比度等信息的差异,采用分块ssim损失函数进行衡量。上述三个函数共同组成一个任务的损失函数。网络模型训练的损失函数的总体数学表达式为:
L
L
其中,L
具体实施时,根据下式计算均方误差损失:
其中,B为批次大小,C为通道数,H和W分别为图像的高度和宽度,out
具体实施时,根据下式计算VGG损失:
其中,M表示在VGG模型中提取的特征数量,VGG(out
具体实施时,根据下式计算SSIM损失:
其中,x和y分别表示两个输入图像,μ
将本发明的网络模型和WaterNet、U-shaped Transformer、Shallow-Uwnet、DeepWaveNet模型进行对比实验。对比实验的模型都采用adam优化器。针对实际环境下,边缘计算设备算力有限,且对图像处理的高实时性要求,本实验将batchsize设置为1,最大的学习率为0.0002,共训练100轮,其中前五轮采用warmup逐渐增大学习率,之后使用余弦退火学习率逐步降低至1e-5。模型使用pytorch框架,在RTX3090,Intel(R)Xeon(R)CPU E5-2678v3的服务器上训练。通过在EUVP三个子数据上进行对比实验,来说明本发明网络模型的优越性。特别地,考虑到U-shaped Transformer的训练参数远远大于其他模型,因此对U-shaped Transformer采用其官方推荐的最大学习率0.0005,其他训练参数保持不变。对比实验结果如表1所示。
表1对比实验
从表1可以看出,本发明的网络模型在EUVP三个子数据集上的PSNR和SSIM指标同时达到最优,并且明显领先其他模型,证明了其的优越性,以及对不同特征数据的强大拟合能力。
本发明的网络模型的一个显著特点是其能够部署在嵌入式设备上。该网络模型采用参数量仅为0.21MB的卷积神经网络,具有较低的计算复杂性和内存占用。实验进一步地通过TensorRT用FP16精度,在Jetson Orin Nano开发板上进行部署,并提供了不同版本的模型在batch size为1条件下的FPS测试结果。模型的输入和输出大小都是256×256。如表2所示为模型部署测试结果。
表2模型部署测试
表2展现不同版本网络模型的性能。模型采用的模块越复杂,模型的参数量和计算量都会增加,在性能提升的同时,帧率会有一定下降。从实验结果看出,本发明的网络模型最高能够达到52FPS的推理能力,而且在精度上优于现有的先进模型完全可以在较高的精度下,满足边缘计算设备实时检测的需求,降低了模型的部署成本。其他的模型则面向对图像质量要求较高的场景设计,并同样能满足绝大多数应用场景的实时处理需求。
当前用于水下图像增强的传统物理模型和基于视觉先验的方法都无法良好地适应不同的水下环境,其效果受环境光照和噪声的影响极大,且对超参数有着较大的依赖。现实应用环境中,就对模型的泛化能力提出了较高的要求。本发明的水下实时图像则增强网络能够从大量水下图像数据中学习特定于水下环境的特征和模式,从而能够更好地适应光线衰减、散射等问题,并自动调整图像增强参数,实现更准确的图像恢复。水下机器人操作和水下资源勘探等任务对于需要快速反馈和决策提出了极高的要求。但当前提出的深度学习模型参数量和计算量过大,不利于模型在嵌入式设备上的部署。本发明的网络模型采用的水下实时增强网络,利用极少的参数量就能够良好地满足实时性的需求。
以上所述仅为本发明的较佳实施例,并不用以限制本发明的思想,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种氢溴酸沃替西汀杂质的制备方法
- 一种沃替西汀α晶型的制备方法
- 一种氢溴酸沃替西汀杂质的合成方法
- 一种低杂质含量的沃替西汀合成方法