数据拷贝方法及系统
文献发布时间:2024-05-31 01:29:11
技术领域
本公开涉及属于数据拷贝技术领域,具体涉及一种高效的数据拷贝方法及系统。
背景技术
在很多应用场景中都会涉及到数据的拷贝,拷贝的数据块并不总是一维的一段连续内存,也可能是高维上的一个数据块。比如pad op,要将输入张量(tensor)拷贝到输出张量(tensor)上,数据块在输出tensor中内存上并不连续,这时一维(1d)的memcpy就不能满足要求,就会涉及到n维(nd)内存拷贝。CUDA中提供了cudaMemcpy2D、cudaMemcpy3D用于2D、3D的数据块拷贝,但是对于更高的维度,需要手动实现,并且实际测试发现cudaMemcpy3D效率并不高。因此,本申请针对数据拷贝中数据块不连续以及高纬度数据拷贝的情形下,数据拷贝效率低下的问题,提出一种高效有效的数据拷贝方法。
发明内容
有鉴于此,本申请提供一种用于深度学习的数据拷贝方法以及数据拷贝系统,能够在深度学习的数据拷贝中,优化计算过程,提高拷贝效率,提升运算速度。
本申请的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本申请的实践而习得。
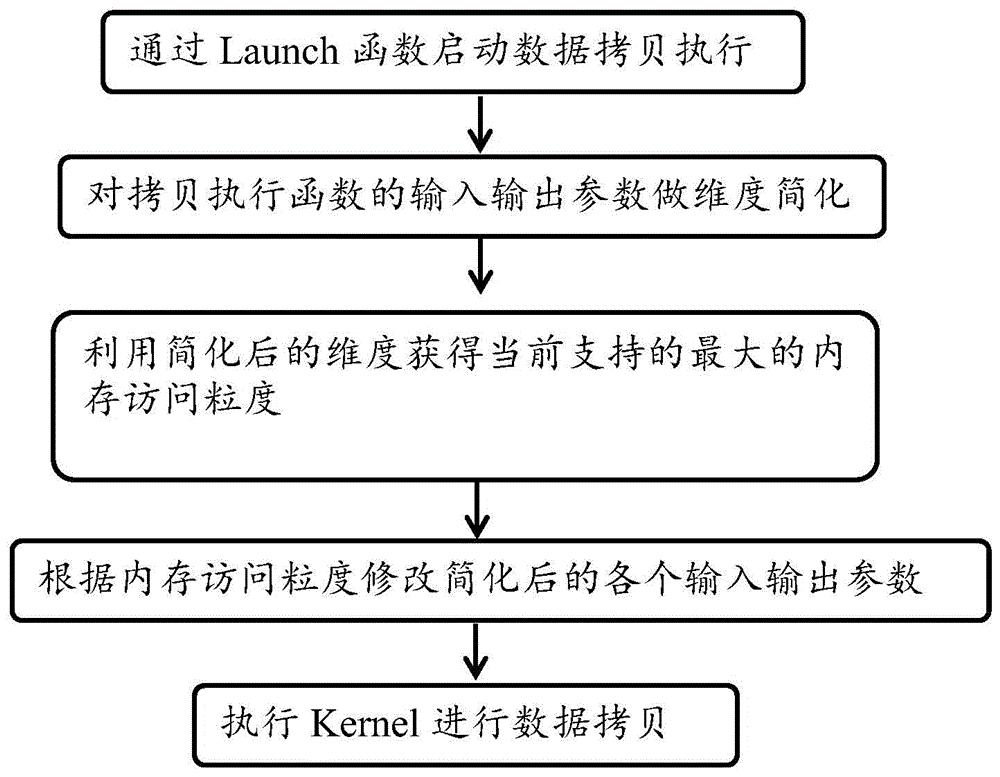
根据本申请的一方面,提出一种高效的数据拷贝方法,其包含:步骤1.通过Launch函数启动数据拷贝执行函数,执行函数至少包含输入参数以及输出参数;步骤2.按照预设规则对输入输出参数做维度简化;步骤3.利用简化后的维度获得当前支持的最大的内存访问粒度(movement_size);步骤4.根据内存访问粒度修改简化后的各个输入输出参数;以及步骤5.依据简化后的参数传入实际执行CopyNd操作的CPU/GPU Kernel中进行数据拷贝。
根据本公开的数据拷贝方法,其特征在于,在步骤2中,如果某个维度上输入和输出的长度相同,且在这个维度上拷贝的是全部的数据,则该维度就可以合并到前一个维度中去。
根据本公开的数据拷贝方法,其特征在于,在步骤3中,获得最大的内存访问粒度,包括:输入输出的最后一个维度可以被内存访问粒度整除,输入输出的最后一维拷贝数据的起始位置可以被内存访问粒度整除,最后一维拷贝的大小可以被内存访问粒度整除,且源数据(src)和目的数据(dst)指针地址对齐内存访问粒度。
根据本公开的数据拷贝方法,其特征在于,在步骤5中,数据拷贝CopyNdKernel对每个要拷贝类型为
typename std::aligned_storage
根据本公开的另一个方面,提供了一种高效的数据拷贝系统,包括:拷贝启动模块,通过Launch函数启动数据拷贝执行函数,执行函数至少包含输入参数以及输出参数;输入输出参数维度简化模块,按照预设规则对输输出参数做维度简化;内存访问粒度计算模块,利用简化后的维度获得当前支持的最大的内存访问粒度movement_size;参数调整适应模块,根据movement_size修改简化后的各个输入输出参数;以及执行拷贝模块,依据简化后的参数传入实际执行CopyNd操作的CPU/GPU Kernel中进行数据拷贝。
根据本公开的数据拷贝系统,其特征在于,所述输入输出参数维度简化模块的在进行简化时,如果某个维度上输入和输出的长度相同,且在这个维度上拷贝的是全部的数据,则该维度就可以合并到前一个维度中去。
根据本公开的数据拷贝系统,其特征在于,内存访问粒度计算模块在获得最大的内存访问粒度movement_size时,通过输入输出的最后一个维度可以被movement_size整除,输入输出的最后一维拷贝数据的起始位置可以被movement_size整除,最后一维拷贝的size可以被movement_size整除,且src和dst指针地址对齐movement_size。
根据本公开的数据拷贝系统,其特征在于,执行拷贝模块中的数据拷贝CopyNdKernel对每个要拷贝类型为
typename std::aligned_storage
根据本申请的一方面,提出一种电子设备,该电子设备包括:一个或多个处理器;存储装置,用于存储一个或多个程序;当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现如上文的方法。
根据本申请的一方面,提出一种计算机可读介质,其上存储有计算机程序,该程序被处理器执行时实现如上文中的方法。
根据本申请的数据拷贝及系统,通过在深度学习的计算过程中,针对拷贝的数据块高于一维需要手动拷贝或待拷贝数据存储于不连续存储内存拷贝效率低下的问题,提出一种高效有效的数据拷贝方法。具体通过对输入输出拷贝参数维度合并简化,使得多维度的数据在各自维度上进行合并,压缩了待拷贝数据的维度,另外通过简化后的维度寻找优化内存访问粒度movement_size,最后将适应性简化后的参数作为拷贝参数执行数据拷贝。本申请的数据拷贝技术方案可以大幅度提升了数据拷贝的效率,方法性能远超过传统cudaMemcpy的性能及pytorch中copy操作的性能。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性的,并不能限制本申请。
附图说明
通过参照附图详细描述其示例实施例,本申请的上述和其它目标、特征及优点将变得更加显而易见。下面描述的附图仅仅是本申请的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1根据一示例性实施例示出的一种用于深度学习的数据拷贝方法流程图;
图2根据一示例性实施例示出的一种用于深度学习的数据拷贝方法中输入输出参数维度简化示意图;
图3根据一示例性实施例示出的一种用于深度学习的数据拷贝方法中内存访问粒度简化输入输出参数的示意图;
图4根据一示例性实施例示出的一种用于深度学习的数据拷贝方法中进行维度压缩简化的比较示意图。
具体实施方式
现在将参考附图更全面地描述示例实施例。然而,示例实施例能够以多种形式实施,且不应被理解为限于在此阐述的实施例;相反,提供这些实施例使得本申请将全面和完整,并将示例实施例的构思全面地传达给本领域的技术人员。在图中相同的附图标记表示相同或类似的部分,因而将省略对它们的重复描述。
此外,所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施例中。在下面的描述中,提供许多具体细节从而给出对本申请的实施例的充分理解。然而,本领域技术人员将意识到,可以实践本申请的技术方案而没有特定细节中的一个或更多,或者可以采用其它的方法、组元、装置、步骤等。在其它情况下,不详细示出或描述公知方法、装置、实现或者操作以避免模糊本申请的各方面。
附图中所示的方框图仅仅是功能实体,不一定必须与物理上独立的实体相对应。即,可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。
附图中所示的流程图仅是示例性说明,不是必须包括所有的内容和操作/步骤,也不是必须按所描述的顺序执行。例如,有的操作/步骤还可以分解,而有的操作/步骤可以合并或部分合并,因此实际执行的顺序有可能根据实际情况改变。
应理解,虽然本文中可能使用术语第一、第二、第三等来描述各种组件,但这些组件不应受这些术语限制。这些术语乃用以区分一组件与另一组件。因此,下文论述的第一组件可称为第二组件而不偏离本申请概念的教示。如本文中所使用,术语“及/或”包括相关联的列出项目中的任一个及一或多者的所有组合。
本领域技术人员可以理解,附图只是示例实施例的示意图,附图中的模块或流程并不一定是实施本申请所必须的,因此不能用于限制本申请的保护范围。
下面结合附图对本发明作进一步详细描述:
结合附图1,本申请高效数据拷贝方法是通过以下技术方案实现的:
步骤1.通过Launch函数启动数据拷贝执行函数。具体通过Launch函数启动数据拷贝CopyNd Primitive。
Launch函数的接口定义为:
void Launch(StreamContext*stream_ctx,DataType data_type,size_tnum_dims,void*dst,
const int64_t*dst_dims,const int64_t*dst_pos,const void*src,
const int64_t*src_dims,const int64_t*src_pos,
const int64_t*extent);
其中data_type代表数据类型,num_dims代表数据维度,dst_dims、dst_pos、src_dims、src_pos、extent等度均为num_dims大小,dst_dims代表输出tensor的ndims维里每一维的维度,dst_pos代表拷贝数据ndims维里每一维的起始位置,extent代表ndims维里每一维度要拷贝的数据个数。
以pad op为例,假设数据类型为float,输形状为(10,3,16,16),假设要在后两维前后各pad 2,得到输出形状为(10、3、20、20)。则调用时传的各个参数如下:
data_type=kFloat
num_dims=4
dst=dst_tensor->mut_dptr()
dst_dims=(10,3,20,20)
dst_pos=(0,0,2,2)
src=src_tensor->dptr()
src_dims=(10,3,16,16)
src_pos=(0,0,0,0)
extent=(10,3,16,16)。
在调用primitive的Launch方法后,我们首先会对输入的各个参数进行维度合并和简化,再利用简化的维度及指针计算支持的最高访存粒度movement size,得到movementsize后,后续的访存操作的基本单位就是movement size,而传入的各个参数是基于数据类型data_type的,因此需要对各个维度做修改以适应movement size的粒度。前述操作都完成后,由输入参数得到simplified_num_dims、simplified_dst_dims、simplified_dst_pos、simplified_src_dims、simplified_src_pos及simplified_extent,再利用简化参数Launch kernel。因此,在步骤2中,对输入输出参数做维度简化。
输入的维度参数有src_dims、src_pos,输出的维度参数有dst_dims、dst_pos,关于拷贝的维度参数是extent。在一些情况下,CopyNd可以进行输入输出拷贝参数维度简化。简化的方法是,如果某个维度上输入和输出的长度相同,且在这个维度上拷贝的是全部的数据,那么这个维度就可以合并到前一个维度上去。
举例而言,如附图2的(a)中,设src_dims为(10,40),dst_dims为(20,40),src_pos为(0,0),dst_pos为(5,0),extent为(10,40)。其中在第二个维度上输入输出维度相同,都是40,因此拷贝的是这个维度上完整的数据,因此这个维度就可以合并到前一个维度,从而,维度可以缩减为:num_dims:1,数据简化后成为,src_dims:(400,)dst_dims(800,),src_pos(0,)dst_pos(200,)extent为(400,)。因此,在进行拷贝时,就可以如附图2的(b)中所示,进行一维的拷贝。在实现时,将当前(或后一)维度合并到前一个维度的具体的判断条件是:
(dst_dims[i]==src_dims[i])&&(src_pos[i]==0)&&(dst_pos[i]==0)&&(dst_dims[i]==extent[i])。
在基于简化条件进行合并后,可以在步骤3中,利用简化后的维度获得当前支持的最大的movement_size。
由于向量化内存操作可以提高带宽利用率,提升性能,为此,可以尽可能将多个元素合并到一起进行向量化读写,在做完输入输出拷贝参数维度合并简化后,从大到小遍历16B、8B、4B、2B、1B,寻找满足条件的内存访问粒度(movement_size)。粒度越大性能越好。因此寻找最优访问粒度过程是,判断输入输出的最后一个维度是否可以被movement_size整除。如果输入输出的最后一维拷贝数据的起始位置可以被movement_size整除,则最后一维拷贝的size可以被movement_size整除,因此src和dst指针地址对齐movement_size。
因此,按照上述方式,如附图2的(b)中所示,简化后的各个维度为src_dims:(400,)dst_dims(800,),src_pos(0,)dst_pos(200,)extent为(400,),若数据类型为float,每个float是4B大小,最后,一维上src的大小为1600B,dst大小为3200B,src_pos大小为0,dst_pos大小为800,extent大小为1600,都可以被16B整除,若src和dst的指针地址对齐16B,就可以得到movement_size=16。
随后,在会的最大movement_size之后,在步骤4中,根据所获得的最大movement_size修改简化后的各个输入输出参数。具体而言,在步骤3得到movement_size后,修改原来的输入输出拷贝参数以适应movement_size的粒度,得到简化后的参数simplified_num_dims、simplified_dst_dims、simplified_dst_pos、simplified_src_dims、simplified_src_pos及simplified_extent。图3显示了根据movement_size修改简化后的各个输入输出参数具体示例。
如图3所示,数据类型为4B大小的float,若采用movement_size=16,相当于将每4个float元素合并成一个元素进行读写操作,相应的,修改后的各个维度变成:src_dims:(100,)dst_dims(200,),src_pos(0,)dst_pos(50,)extent为(200,),元素类型为std::aligned_storage
最后,在修改了拷贝粒度参数之后,在步骤5中,基于修改后的简化参数,执行Kernel以进行数据拷贝。具体而言,依据步骤5中简化后的参数simplified_num_dims、simplified_dst_dims、simplified_dst_pos、simplified_src_dims、simplified_src_pos及simplified_extent,及最的访存粒度movement_size,并将这些参数传入实际执行CopyNd操作的CPU/GPU Kernel中。
具体而言,CopyNdKernel执行时,对每个要拷贝的数据,元素类型为typenamestd::aligned_storage
图3双显示了这种简化参数后的一个实例的拷贝过程。例如,数据类型为4B大小的float,若采用movement_size=16,相当于将每4个float元素合并成一个元素进行读写操作。修改后的各个维度变成:src_dims:(100,)dst_dims(200,),src_pos(0,)dst_pos(50,)extent为(200,)。
元素类型为std::aligned_storage
在如上所述的步骤的整个计算过程中,会涉及多次偏移量和高维索引的互相转换,为了简化计算,借助申请人(OneFlow)的中的工具类NdIndexOffsetHelper来实现。定义CopyNdKernelParams作为CopyNdKernel的传入参数,CopyNdKernelParams的定义如下:
template
struct CopyNdKernelParams{
NdIndexOffsetHelper
NdIndexOffsetHelper
NdIndexOffsetHelper
IndexType dst_pos[num_dims];
IndexType src_pos[num_dims];
IndexType count{};
const void*src{};
void*dst{};
};
需要指出的是,其中src_index_helper由src_dims构造,用于src的offset和index互相转换,dst_index_helper由dst_dims构造,用于dst的offset和index互相转换,copy_index_helper由extent构造,用于每个拷贝元素的offset和index的互相转换,count代表拷贝元素个数。
此外,CopyNdKernelParams的构造需要IndexType和num_dims模板参数,CopyNdKernel执行需要movement_size模板参数来获得数据类型,在此过程中需要先做三次Dispatch,第一次根据简化的num_dims静态派发ndim模板参数,第二次根据求得的movement_size静态派发movement_size模板参数,第三次根据拷贝数据量静态派发IndexType,IndexType是索引的数据类型,在坐标换算中不同类型的开销不一样,int64_t的开销比int32_t大,因此如果count小与于int32_t的数据范围,则采用int32_t作为IndexType。
需要指出的是,本申请针对的问题就是内存不连续,不能将拷贝数据看做一维向量,不能使用memcpy的高维数据拷贝问题。使用高维数据拷贝本身就是解决内存不连续的拷贝问题。图4所示的灰色部分内容表示要拷贝的数据,第一个在空间中是连续的,所以可以使用copy 1d,第二个和第三个的内存在空间中是不连续的,分别需要使用copy 2d和copy3d。因此,本公开的方法相比现有技术的优点在于维度压缩简化,对于一些情况下,虽然用户传num_dims维,但是通过维度压缩条件判断可以简化成更低的维度,则可以简化问题。因此,可以使用更大的内存访问粒度movement_size,而不是原始的data_type的size,可以提升数据拷贝的效率。
除此之外,本申请还提供了与上述高效的数据拷贝方法功能模块对应的拷贝系统。还提供了实现其发明目的的计算设备以及计算机可读存储介质,其特征在于,包括处理器和存储器,所述存储器存储有能够被所述处理器执行以实现上述数据拷贝方法。所述计算机可执行指令在被处理器调用和执行时,计算机可执行指令促使处理器实现上述数据拷贝方法。相应计算机设备以及可读存储介质的具体实现手段均为现有技术,在此不做赘述。
通过以上的实施方式的描述,本领域的技术人员易于理解,这里描述的示例实施方式可以通过软件实现,也可以通过软件结合必要的硬件的方式来实现。因此,根据本申请实施方式的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中或网络上,包括若干指令以使得一台计算设备(可以是个人计算机、服务器、或者网络设备等)执行根据本申请实施方式的上述方法。
所述软件产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以为但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。
所述计算机可读存储介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。可读存储介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。可读存储介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、有线、光缆、RF等等,或者上述的任意合适的组合。
可以以一种或多种程序设计语言的任意组合来编写用于执行本申请操作的程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如Java、C++等,还包括常规的过程式程序设计语言—诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(LAN)或广域网(WAN),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
上述计算机可读介质承载有一个或者多个程序,当上述一个或者多个程序被一个该设备执行时,使得该计算机可读介质实现如下功能:在深度学习的计算过程中,获取维度变换指令,所述维度变换指令包括待进行维度变换的初始数据和维度变换函数;在满足合并条件时,将所述初始数据中的维度进行合并处理,生成合并数据;在所述维度变换函数为Permute函数时,基于第一优化策略确定元素访问粒度并对Permute函数进行优化处理,生成优化后的Permute函数;基于优化后的Permute函数以所述元素访问粒度对所述合并数据进行维度变换以进行深度学习计算。在所述维度变换函数为Transpose函数时,基于第二优化策略对所述合并数据和Transpose函数进行优化处理,生成优化数据和优化后的Transpose函数;基于优化后的Transpose函数对所述优化数据进行维度变换以进行深度学习计算。
本领域技术人员可以理解上述各模块可以按照实施例的描述分布于装置中,也可以进行相应变化唯一不同于本实施例的一个或多个装置中。上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块。
通过以上的实施例的描述,本领域的技术人员易于理解,这里描述的示例实施例可以通过软件实现,也可以通过软件结合必要的硬件的方式来实现。因此,根据本申请实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中或网络上,包括若干指令以使得一台计算设备(可以是个人计算机、服务器、移动终端、或者网络设备等)执行根据本申请实施例的方法。
以上具体地示出和描述了本申请的示例性实施例。应可理解的是,本申请不限于这里描述的详细结构、设置方式或实现方法;相反,本申请意图涵盖包含在所附权利要求的精神和范围内的各种修改和等效设置。
- 一种用于电视系统的不同USB设备间数据拷贝方法
- 一种用于验证特定DNA片段拷贝数变异的引物设计方法、引物、试剂盒、方法和系统
- 数据拷贝系统、数据拷贝设备及数据拷贝方法
- 数据拷贝系统、数据拷贝设备、数据拷贝方法及记录介质