图像处理方法及装置
文献发布时间:2023-06-19 11:32:36
技术领域
本申请涉及数据技术领域,具体涉及一种图像处理方法及装置。
背景技术
图形处理器(英语:Graphics Processing Unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
现有的GPU处理图像的信令传输较慢,无法满足图像快速处理的要求。
发明内容
本申请实施例提供了一种图像处理方法及装置,其具有图像处理速度快的优点。
第一方面,本申请实施例提供一种图像处理方法,所述方法应用于电子设备,其中,所述方法包括:
电子设备获取待处理的图像数据,通用处理器将该图像数据发送至GPU;
GPU将图像数据存储在该存储单元,控制单元生成该图像数据的多个计算指令,控制单元确定当前行的m个计算单元对应的m个计算指令的计算标识是否相同,若确定计算标识相同且计算数据的大小也相同,将m个计算指令合并成合并指令,将该合并指令发送至计算单元;
计算单元接收合并指令后,依据该合并指令中的转发次数γ从存储单元提取出计算数据,依据该合并指令的计算标识对该计算数据执行计算的计算结果,将该转发次数γ加1后转发给相邻的计算单元;
GPU将计算结果发送至通用处理器,通用处理器依据计算结果确定图像处理结果。
第二方面,提供一种图像处理装置,所述图像处理装置应用于电子设备,其中,所述装置包括:
获取单元,用于获取待处理的图像数据;
通用处理器,用于将该图像数据发送至GPU;
GPU,用于将图像数据存储在该存储单元,控制单元生成该图像数据的多个计算指令,控制单元确定当前行的m个计算单元对应的m个计算指令的计算标识是否相同,若确定计算标识相同且计算数据的大小也相同,将m个计算指令合并成合并指令,将该合并指令发送至计算单元;计算单元接收合并指令后,依据该合并指令中的转发次数γ从存储单元提取出计算数据,依据该合并指令的计算标识对该计算数据执行计算的计算结果,将该转发次数γ加1后转发给相邻的计算单元;GPU将计算结果发送至通用处理器;
通用处理器,用于依据计算结果确定图像处理结果。
第三方面,提供一种计算机可读存储介质,其存储用于电子数据交换的程序,其中,所述程序使得终端执行第一方面的方法
实施本申请实施例,具有如下有益效果:
可以看出,本申请的技术方案的控制单元在确定当前行(例如第一行或第二行)的m个计算指令标识相同且计算数据大小也相同时,将m个计算指令合并,这样对于前列的计算指令,只用转发一次合并指令即可,无需进行多次的转发,这样提高了计算指令的传输效率,提高了图像处理的速度,增加了用户体验度。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是一种电子设备的结构示意图。
图2是本申请实施例提供的一种GPU结构示意图。
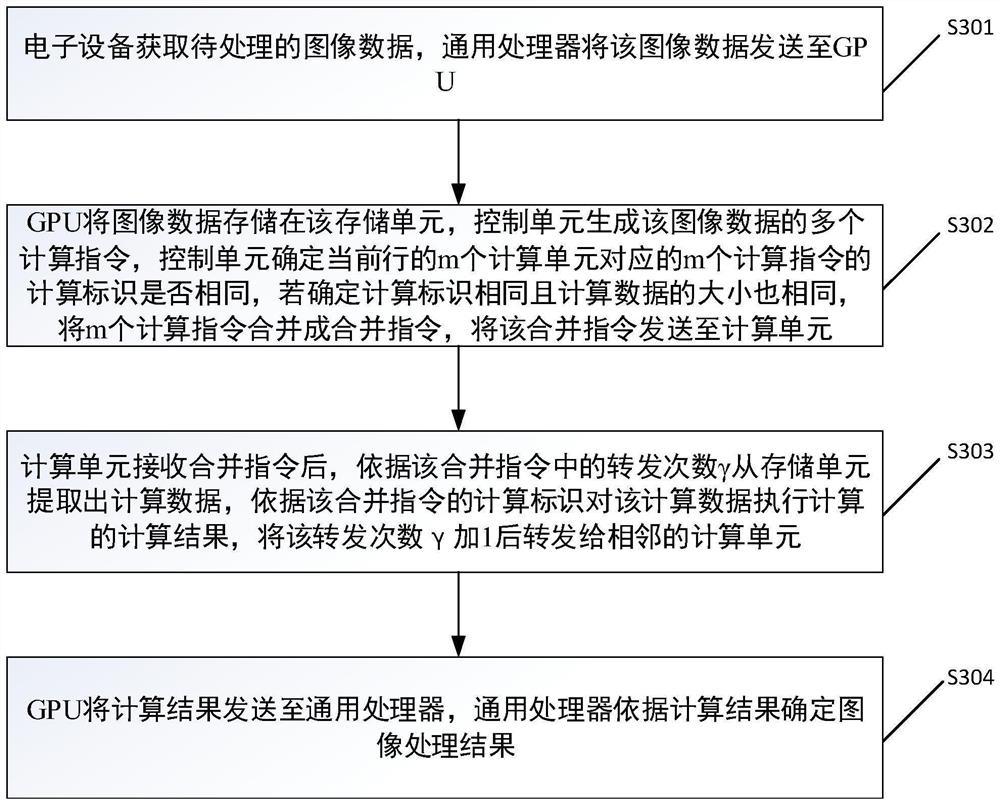
图3为本申请提供的图像处理方法的流程示意图。
图4为本申请提供的GPU另一结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本申请的说明书和权利要求书及所述附图中的术语“第一”、“第二”、“第三”和“第四”等是用于区别不同对象,而不是用于描述特定顺序。此外,术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
在本文中提及“实施例”意味着,结合实施例描述的特定特征、结果或特性可以包含在本申请的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
参阅图1,图1提供了一种电子设备,该电子设备具体可以包括:处理器、存储器、摄像头和显示屏,上述部件可以通过总线连接,也可以通过其他方式连接,本申请并不限制上述连接的具体方式。在实际应用中,上述电子设备具体可以为智能手机、个人计算机、服务器、平板电脑等等。
上述处理器具体可以包括:通用处理器和图像处理器GPU。
如图2所示,上述GPU可以包括:存储单元201、n个控制单元202、m*n个计算单元203,其中,m*n个计算单元203呈矩阵排列,n个控制单元202分别与矩阵排列的第一列的n个计算单元连接,存储单元201具有m个IO(输入输出)接口,该m个IO接口分别与最后一行的m个计算单元连接,m*n个计算单元203中每个计算单元均与相邻的计算单元连接(包含上下相邻以及左右相邻)。
对于如图2所示的GPU结构,对于计算信令,其传输的方式基于计算单元之间转发,这样基于m*n个计算单元的计算信令后面的计算单元的计算信令需要很多计算单元转发,这样对于矩阵排列第一列的n个计算单元来说信令转发的开销很大,因为此行所有的计算信令均需要转发一次,增加了计算信令的开销。
上述m、n均为大于等于6的整数,且m≥n。
为了减少计算信令转发的开销,参阅图3,图3提供了一种图像处理方法,该方法在如图1所示的电子设备内执行,该方法如图3所示,包括如下步骤:
步骤S301、电子设备获取待处理的图像数据,通用处理器将该图像数据发送至GPU;
步骤S302、GPU将图像数据存储在该存储单元,控制单元生成该图像数据的多个计算指令,控制单元确定当前行的m个计算单元对应的m个计算指令的计算标识是否相同,若确定计算标识相同且计算数据的大小(即存储单元的数据长度)也相同,将m个计算指令合并成合并指令,将该合并指令发送至计算单元;
上述计算标识具体可以为运算的标识,例如乘法运算可以为1000,加法运算可以为0100等等,当然还可以为其他的标识。
上述合并指令的结构如表1所示,具体可以包括:合并指令标识(可以为1个比特,例如1标识合并指令,0标识普通指令)、计算标识(可以为4个比特),转发次数γ(可以为8个比特)、合并指令首地址(可以为32比特,即首地址1)、计算数据长度(可以为32比特,即计算数据在存储单元所占用的存储长度值,例如占用1M(兆)比特,即长度1)、计算结果存储首地址(可以为32比特,首地址2),计算结果长度(可以为32比特,即长度2)。
上述将计算指令合并成合并指令的方式具体可以为,提取m个计算指令中第一计算单元对应的第一计算指令的计算标识、首地址1、长度1、首地址2和长度2作为合并指令的计算标识、首地址1、长度1、首地址2和长度2,如下表所示,在对应的位置插入转发次数以及合并指令标识。
表1:合并指令结构:
需要说明的是,上述合并指令结构的比特位的配置可以由用户实际配置,上述表1中仅仅为了示例的说明,并不限定每个位置中包含的比特数量。
步骤S303、计算单元接收合并指令后,依据该合并指令中的转发次数γ从存储单元提取出计算数据,依据该合并指令的计算标识对该计算数据执行计算的计算结果,将该转发次数γ加1后转发给相邻的计算单元;
步骤S304、GPU将计算结果发送至通用处理器,通用处理器依据计算结果确定图像处理结果。
上述步骤S304依据计算结果确定图形处理结果的方式可以采用通过的处理方式,这里不再赘述。
本申请的技术方案的控制单元在确定当前行(例如第一行或第二行)的m个计算指令标识相同且计算数据大小也相同时,将m个计算指令合并,这样对于前列的计算指令,只用转发一次合并指令即可,无需进行多次的转发,这样提高了计算指令的传输效率,提高了图像处理的速度,增加了用户体验度。
在一种可选的方案中,依据该合并指令中的转发次数γ从存储单元提取出计算数据具体可以包括:
计算指令依据下述公式1计算得到本次计算的首地址;
首地址i=首地址1+γ*x;公式1
其中,x为计算数据长度;首地址i为本次计算指令的计算数据的首地址。
计算单元从存储单元提取首地址i之后的x个比特的数据确定为计算数据。
对应的,上述计算结果的长度也可以通过类似公式1计算得到。
可选的,参阅图4,上述矩阵排列的m*n个单元包括普通区域301、信令转发区域302、数据转发区域303和复合转发区域304;其中,普通区域301仅包括计算单元203,信令转发区域302包括:计算单元和信令转发单元(将一个或多个计算单元替换成信令转发单元);数据转发区域303包括:计算单元和数据转发单元(将一个或多个计算单元替换成数据转发单元),复合转发区域304包括:计算单元和复合转发单元(将一个或多个计算单元替换成复合转发单元);上述方法还可以包括:
控制单元确定计算信令为非合并指令时,获取该计算指令的设备标识,依据该设备标识确定计算单元位置,若该计算单元的位置属于信令转发区域时,将该计算信令发送至信令转发单元,信令转发单元将该计算信令转发给该设备标识对应的计算单元。
计算信令的格式如表2所示:
其中,计算标识可以为计算指令的算术运算标识(例如乘法运算标识等等)设备标识为计算单元的标识,用于识别矩阵阵列中具体哪个计算单元,该首地址1为计算数据在存储单元的首地址,长度1为计算数据在存储单元的长度,首地址2为计算结果在在存储单元的首地址,长度2为计算结果在存储单元的长度。
类似的,若该计算单元的位置属于复合转发区域时,将该计算信令发送至复合转发单元,复合转发单元将该计算信令转发给该设备标识对应的计算单元。
此种方案减少了计算信令的转发过程,提高了计算信令的转发效率。
对应的,参见图4,信令转发区域302、数据转发区域303和复合转发区域304中的信令转发单元、数据转发单元、复合转发单元均如图4所示的3*3阵列的中心位置,且信令转发单元、数据转发单元、复合转发单元分别与周围的计算单元连接。
该信令转发单元与控制单元直接连接,用于转发计算信令,该数据转发单元与存储单元的IO接口(该IO接口可以为新增加的IO接口,不属于m个IO接口)直接连接(上述直接连接表示两个单元之间无其他单元),用于转发数据,复合转发单元分别与控制单元以及存储单元的IO接口直接连接,用于转发计算信令或数据。
此种方法能够减少计算信令的转发次数。针对计算信令提高图像的处理速度。
本申请还提供一种图像处理装置,所述图像处理装置应用于电子设备,其中,所述装置包括:
获取单元,用于获取待处理的图像数据;
通用处理器,用于将该图像数据发送至GPU;
GPU,用于将图像数据存储在该存储单元,控制单元生成该图像数据的多个计算指令,控制单元确定当前行的m个计算单元对应的m个计算指令的计算标识是否相同,若确定计算标识相同且计算数据的大小也相同,将m个计算指令合并成合并指令,将该合并指令发送至计算单元;计算单元接收合并指令后,依据该合并指令中的转发次数γ从存储单元提取出计算数据,依据该合并指令的计算标识对该计算数据执行计算的计算结果,将该转发次数γ加1后转发给相邻的计算单元;GPU将计算结果发送至通用处理器;
通用处理器,用于依据计算结果确定图像处理结果。
上述GPU、通用处理器还可以执行如图3所示实施例的细化步骤或可选方案,这里不再赘述。
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本申请并不受所描述的动作顺序的限制,因为依据本申请,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于可选实施例,所涉及的动作和模块并不一定是本申请所必须的。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
以上对本申请实施例进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。
- 信息处理装置、信息处理方法、控制装置、控制系统、控制方法、断层合成图像捕获装置、X射线成像装置、图像处理装置、图像处理系统、图像处理方法和计算机程序
- 图像处理装置和图像处理方法、图像处理方法的程序、以及具有记录在其上的图像处理方法的程序的记录介质