视频文本跨模态检索方法、装置、存储介质和设备
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及机器学习技术领域,尤其涉及一种视频文本跨模态检索方法、装置、存储介质和设备。
背景技术
随着移动设备的智能化、便携化以及在线视频平台的蓬勃发展,大量的互联网用户选择通过视频媒介进行信息的共享和传播。在这一趋势下,当前广泛使用的基于文本标题的视频检索方式存在人工标注成本高昂且效率低下,同时文本标题无法对视频中的语义内容全面涵盖等问题,难以有效满足日益增长的海量视频数据管理和分析需求。
视频文本跨模态检索旨在通过语义内容的表征相似性完成实现。具体而言,该检索范式允许查询输入和候选对象为视频和文本其中一种模态数据,将视频和文本进行向量化表示后,计算跨模态向量相似度并排序实现对另一模态数据的检索。由于视频文本跨模态检索是在视频内容理解的基础上实现的语义内容检索,极大的解放了繁重的人工标注劳动,有效的提高了海量视频的智能处理能力。同时该检索方式拓宽了查询输入的模态限制,解决了基于文本标题的视频检索方式中只能使用文本作为查询输入的局限性,满足了用户个性化的检索需求。
现有的关于视频文本跨模态检索的方法主要分为两类。第一类方法将视频和文本均表示为单一特征向量,通过直接计算单一特征向量间的余弦相似度完成检索。然而此类方法将视频和文本表示为紧致的固定维度向量,难以进行关于语义的细粒度特征匹配,降低了检索准确率。第二类方法将视频和文本表示为序列化的帧特征和词特征,通过注意力机制对序列化的帧特征间的余弦相似度加权得到最终结果。但是此类方法忽略了视频和文本关于语义内容在空间和时间维度上的表征方式差异,无法构建与之适应的特征匹配策略,成为了提高检索准确率的瓶颈。
发明内容
本发明提供的视频文本跨模态检索方法、装置、存储介质和设备,通过挖掘视频和文本关于语义内容表征方式的差异性,提高的了视频文本跨模态检索过程中的细粒度、强可解释性和高准确率。
第一方面,本发明实施例提供一种视频文本跨模态检索方法,所述方法包括:
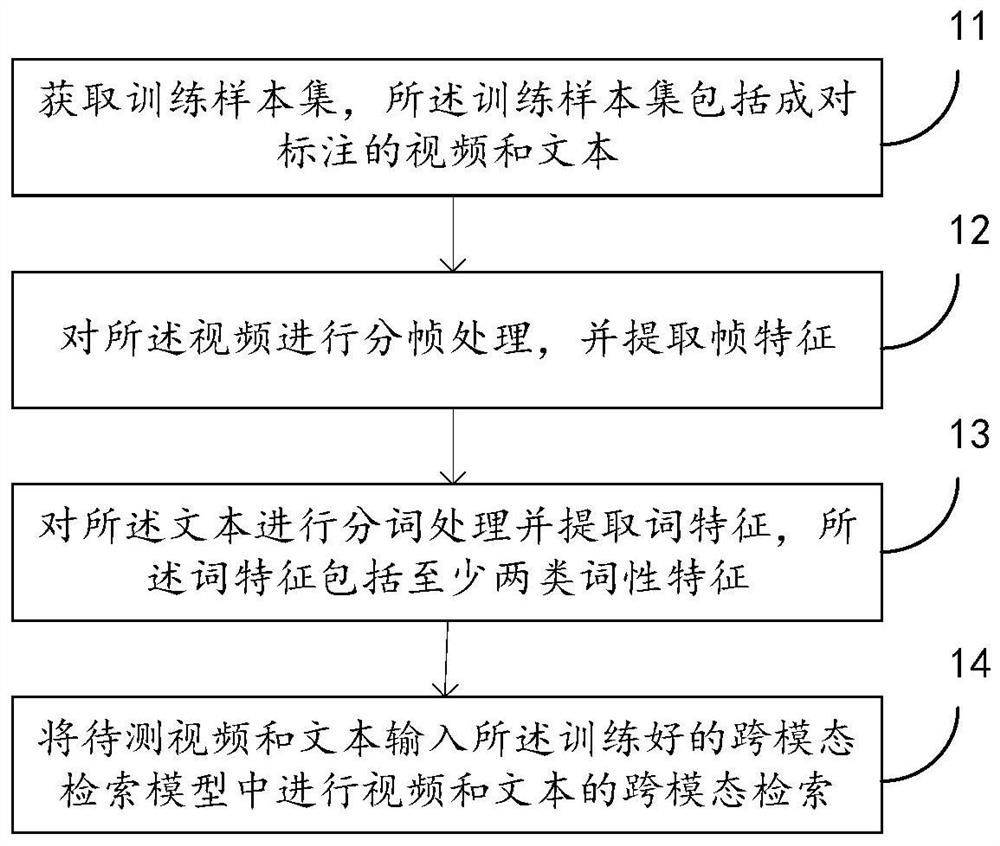
获取训练样本集,所述训练样本集包括成对标注的视频和文本;
对所述视频进行分帧处理,并提取帧特征;
对所述文本进行分词处理并提取词特征,所述词特征包括至少两类词性特征;
利用所述帧特征和至少两种词性特征对预训练的跨模态检索模型进行训练,获得训练好的跨模态检索模型;
将待测视频和文本输入所述训练好的跨模态检索模型中进行视频和文本的跨模态检索。
进一步地,对所述视频进行分帧处理并提取帧特征包括:
利用分帧工具依次对每一段视频进行分帧处理,获得帧序列,将所述帧序列均匀划分为时长相等的预设段,提取每段的第一帧,获得预设帧;
运用卷积神经网络ResNet提取所述预设帧的帧特征。
进一步地,对所述文本进行分词处理并提取词特征,所述词特征包括至少两种词性特征包括:
利用分词工具依次对每一条文本进行分词;
利用Simple-bert语义角色标注工具对每个词的词性进行分类;
利用全局词频统计词表征工具和门控循环单元词特征提取工具提取词特征,所述词特征包括至少两类种词性特征。
进一步地,所述词性特征包括第一词性特征和第二词性特征,所述利用所述帧特征和至少两种词性特征对预训练的跨模态检索模型进行训练,获得训练好的跨模态检索模型包括:
将所述帧特征与所述第一词性特征进行空间维度特征匹配,获得空间维度特征匹配结果;
计算所有帧特征之间的帧间特征关联度,及第一词性特征和第二词性特征之间的词性间特征关联度,将所述帧间特征关联度与所述词性间特征关联度进行时间维度特征匹配,获得时间维度特征匹配结果;
对所述空间维度特征匹配结果和所述时间维度特征匹配结果进行融合,获得联合空间时间维度特征匹配结果;
将所述联合空间时间维度特征匹配结果作为正则项与对比排序损失函数进行数学运算获得损失函数;
利用反向梯度传播法对所述预训练的视频文本跨模态模型的参数进行训练,直至所述损失函数实现收敛。
进一步地,获取训练样本集之后,对所述视频进行分帧处理,并提取帧特征之前,所述方法还包括:
获取验证样本集;
将所述训练数据集中的视频和文本分别写入到以视频和文本序列号名称作为查询键的字典文件中。
进一步地,对各所述字典文件中序列号名称对应的视频进行分帧处理,各所述字典文件中序列号名称对应的文本进行分词处理。
进一步地,所述损失函数实现收敛后,所述方法还包括:
将所述验证样本集中的每一段视频输入所述训练好的跨模态检索模型中;
计算所述训练好的跨模态检索模型搜索到的前预设数目个搜索结果中出现正确样本占验证样本集中总样本数的比例,得到第一检索准确率结果;
将所述第一检索准确率结果与仅利用对比排序损失函数作为损失函数进行训练的跨模态检索模型时获取的第二检索准确率结果进行性能增益的判定;
当所述第一检索准确率结果与所述第二检索准确率结果相比存在性能增益时,确定跨模态检索模型训练正确。
第二方面,本发明提供了一种视频文本跨模态检索装置,所述装置包括:
获取模块,用于获取训练样本集,所述训练样本集包括成对标注的视频和文本;
帧特征提取模块,用于对所述视频进行分帧处理,并提取帧特征;
词特征提取模块,用于对所述文本进行分词处理并提取词特征,所述词特征包括至少两类词性特征;
训练模块,用于利用所述帧特征和至少两种词性特征对预训练的跨模态检索模型进行训练,获得训练好的跨模态检索模型;
检索模块,用于将待测视频和文本输入所述训练好的跨模态检索模型中进行视频和文本的跨模态检索。
第三方面,本发明提供了一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行第一方面所述的方法。
第四方面,本发明提供了一种设备,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行第一方面所述的方法。
本发明提供的技术方案,通过提取视频分帧处理后的帧特征以及文本分词后的词特征,利用帧特征和词特征对构建的视频文本跨模态检索模型进行训练,获得训练好的跨模态检索模型。由此,在对预训练的视频文本跨模态模型训练的过程中充分考虑了视频和文本两种异构模态数据关于语义内容表征方式的差异性,并将该特性体现在视频文本跨模态特征匹配当中,细化了视频文本跨模态特征匹配粒度,增强了视频文本跨模态特征匹配过程的可解释性,提高了视频文本跨模态检索的准确率。
附图说明
图1是本发明实施例提供的一种视频文本跨模态检索的方法的流程图;
图2是本发明实施例提供的视频文本跨模态检索方法中步骤12的实现流程图;
图3是本发明实施例提供的视频文本跨模态检索方法中步骤13的实现流程图;
图4是本发明实施例提供的视频文本跨模态检索方法中步骤14的实现流程图;
图5是本发明另一实施例提供的视频文本跨模态检索方法的流程图;
图6是本发明另一实施例中步骤28的实现方法流程图;
图7是本发明实施例提供的视频文本跨模态检索装置的结构示意图;
图8是本发明实施例提供的另一种视频文本跨模态检索装置的结构示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,显然,所描述的实施例仅仅是本发明一部份实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
为满足视频文本跨模态检索高准确率的要求,本发明实施例可以利用视频分帧处理后提取的帧特征,文本分词后的至少两类词性特征对构建的预训练的视频文本跨模态模型进行训练,在对预训练的视频文本跨模态模型训练的过程中充分考虑了视频和文本两种异构模态数据关于语义内容表征方式的差异性,并将该特性体现在视频文本跨模态特征匹配当中,细化了视频文本跨模态特征匹配粒度,增强了视频文本跨模态特征匹配过程的可解释性,提高了视频文本跨模态检索的准确率。
参见图1,图1是本发明实施例提供的一种视频文本跨模态检索的方法的流程图,该方法包括如下步骤。
步骤11、获取训练样本集,所述训练样本集包括成对标注的视频和文本。
在本实施例中,可以使用大量和视频文本跨模态检索相关的训练样本集来训练视频文本跨模态检索模型,通过视频文本跨模态检索模型在训练样本集上的误差不断迭代训练模型,得到对训练样本集拟合合理的视频文本跨模态检索模型,再将训练好的视频文本跨模态检索模型应用到实际的视频文本跨模态检索过程中。在实际应用过程中,视频文本跨模态检索模型在待测视频和文本上预测结果误差越小,说明视频文本跨模态检索模型的训练越精确。
在本实施例中,可以获取训练样本集,训练样本集包括成对标注的视频和文本。在另一些实施例中,为了防止过拟合,可以将数据集划分为训练样本集、验证样本集和测试样本集,其中,训练样本集用于训练视频文本跨模态检索模型,验证样本集用于评估视频文本跨模态检索模型预测的好坏以及调整参数,测试样本集用于测试已经训练好的视频文本跨模态检索模型的推广能力。
以MSR-VTT数据集为例,假设MSR-VTT数据集共包含10000个视频,每个视频标注20条文本,训练数据集合T包含6573个视频,验证数据集合V 包含497个视频,测试数据集合U包含2990个视频。
步骤12、对所述视频进行分帧处理,并提取帧特征。
在本步骤中,可以利用分帧工具对每一个视频进行分帧处理,获得按时间顺序排序的帧序列,将帧序列划分为时常相等的多段,提取每段的第一帧,获得预设帧。之后提取选取的预设帧的帧特征。
步骤S13、对所述文本进行分词处理并提取词特征,所述词特征包括至少两类词性特征。
在本步骤中,可以构建视频文本跨模态检索模型,将获取的帧特征和至少两类词性特征输入构建的预训练的视频文本跨模态检索模型中,利用损失函数对预训练的视频文本跨模态检索模型的参数进行调整优化。
具体地,可以计算帧特征与名词特征之间的时间维度特征匹配结果,获得空间维度特征匹配结果,再计算帧间关联特征及动名词间关联特征,计算帧间关联特征和动名词间关联特征的时间维度匹配特征,获得时间维度特征匹配结果,最后对空间维度特征匹配结果和时间维度特征匹配结果进行融合,获得联合空间时间维度特征匹配结果,将所述联合空间时间维度特征匹配结果作为正则项与对比排序损失函数进行数学运算获得损失函数,利用反向梯度传播法对所述预训练的视频文本跨模态模型的参数进行训练,直至所述损失函数的收敛程度最小。
步骤14、将待测视频和文本输入所述训练好的跨模态检索模型中进行视频和文本的跨模态检索。
在本步骤中,将待测视频和文本输入所述训练好的跨模态检索模型中进行视频和文本的跨模态检索结果。
优选的,如图2所示,图2是本发明实施例提供的视频文本跨模态检索方法中步骤12的实现流程图,步骤12可通过以下步骤实现:
步骤S121,利用分帧工具依次对每一段视频进行分帧处理,获得帧序列,将所述帧序列均匀划分为时长相等的预设段,提取每段的第一帧,获得预设帧。
例如,可以利用OpenCV分帧工具依次对单个视频进行分帧,将分帧结果均匀划分为时长相等的n=30段,提取每段的第一帧,共得到30帧。
步骤S122、运用卷积神经网络ResNet提取所述预设帧的帧特征。
在本步骤中,可以利用残差网络(Residual Network,ResNet)帧特征提取工具获取帧特征
优选的,如图3所示,图3是本发明实施例提供的视频文本跨模态检索方法中步骤13的实现流程图,步骤13对每个文本进行分词处理并提取词特征,可以通过以下步骤来实现:
S131、利用分词工具依次对每一条文本进行分词。
例如,可以利用NLTK分词工具依次对字典文件中的单条文本进行分词,共得到m词,m的取值视实际单条文本中包含的词数而定。
S132、利用Simple-bert语义角色标注工具对每个词的词性进行分类。
可以利用Simple-bert语义角色标注工具对词性进行分类,判断其属于名词或者动词,并获得动词与名词间对应依存关联邻接矩阵R。
S133、利用全局词频统计词表征工具和门控循环单元词特征提取工具提取词特征,所述词特征包括至少两类种词性特征。
在本步骤中,先后利用全局词频统计(Global Vectors for WordRepresentation,GloVe)词表征工具和门控循环单元(Gated Recurrent Units, GRUs)词特征提取工具获取词特征
优选的,如图4所示,图4是本发明实施例提供的视频文本跨模态检索方法中步骤14的实现流程图。步骤S14对所述利用所述帧特征和至少两种词性特征对预训练的跨模态检索模型进行训练,获得训练好的跨模态检索模型可通过以下步骤实现:
S141、将所述帧特征与所述第一词性特征进行空间维度特征匹配,获得空间维度特征匹配结果。
以两类词性特征,且第一词性特征为名词特征,第二词性特征为动词特征为例进行说明。
在本步骤中,按照如下公式对帧特征与名词特征进行空间维度特征匹配:
其中T
通过计算帧特征与所述第一词性特征进行空间维度特征匹配,获得空间维度特征匹配结果,该匹配过程以搜索最佳空间维度特征匹配策略,获取所有帧特征与名词特征的联合最小匹配距离D
S142、计算所有帧特征之间的帧间特征关联度,及第一词性特征和第二词性特征之间的词性间特征关联度,将所述帧间特征关联度与所述词性间特征关联度进行时间维度特征匹配,获得时间维度特征匹配结果。
在本步骤中,按照如下公式计算帧间特征关联c
c
按照如下公式计算将所述帧间关联特征与所述词性间关联特征进行时间维度特征匹配:
其中,T
L(v
该匹配过程以搜索最佳时间维度特征匹配策略,获取所有帧间特征关联与动名词间特征关联的联合最小匹配距离D
S143、对所述空间维度特征匹配结果和所述时间维度特征匹配结果进行融合,获得联合空间时间维度特征匹配结果。
在本步骤中,按照如下公式融合空间维度特征匹配结果和时间维度特征匹配结果,构建联合空间时间维度特征匹配结果:
其中,T
该匹配过程以搜索最佳联合空间时间维度特征匹配策略,获取最小匹配距离D
S144、将所述联合空间时间维度特征匹配结果作为正则项与对比排序损失函数进行数学运算获得损失函数。
在本步骤中,将所述联合空间时间维度特征匹配结果作为正则项与对比排序损失函数进行加和运算获得损失函数。损失函数的表达公式如下式:
L=L
其中,β为优化正则项的约束参数,L
其中,S(V,S)表示帧特征与词特征之间的相似度,
S145、利用反向梯度传播法对所述预训练的跨模态模型的参数进行训练,直至所述损失函数的实现收敛。
在本步骤中,当获得损失函数以后,将帧特征及动词特征和名词特征输入预训练的跨模态检索模型中,利用反向传播法对预训练的跨模态检索模型进行训练,使得损失函数的收敛程度最小。通过损失函数能够预测实际值与测量值之间的差异。损失函数值越小,说明预测输出和实际结果之间的差值越小,也说明构建的模型越好。训练跨模态检索模型的过程,就是不断通过训练数据进行预测,不断调整预测输出与实际输出的差异,使损失值最小的过程。
如图5所示,图5是本发明另一实施例提供的视频文本跨模态检索方法的流程图,所述方法可包括以下步骤:
步骤21、获取训练样本集、验证样本集和测试样本集,所述训练样本集包括成对标注的视频和文本。
在本步骤中,MSR-VTT数据集共包含10000个视频,每个视频标注20 条文本,训练数据集合T包含6573个视频,验证数据集合V包含497个视频,测试数据集合U包含2990个视频。
步骤22、将所述训练数据集中的视频和文本分别写入到以视频和文本序列号名称作为查询键的字典文件中。
以文件命名规则R关于视频字典为video_id1(id1=1,2…6573),关于文本字典为text_id2(id2=1,2,…,131460)。
步骤23、对各所述字典文件中序列号名称对应的视频进行分帧处理,并提取帧特征,对各所述字典文件中序列号名称对应的文本进行分词处理并提取词特征,所述词特征包括名词特征和动词特征。
利用OpenCV分帧工具依次对字典文件中的单个视频进行分帧,将分帧结果均匀划分为时长相等的n=30段,提取每段的第一帧,共得到30帧。利用NLTK分词工具依次对字典文件中的单条文本进行分词,共得到m词,m 的取值视实际单条文本中包含的词数而定。
利用Simple-bert语义角色标注工具对词性进行分类,判断其属于名词或者动词,并获得动词与名词间对应依存关联邻接矩阵R;
利用残差网络(Residual Network,ResNet)帧特征提取工具获取帧特征
步骤24、将所述帧特征与所述第一词性特征进行空间维度特征匹配,获得空间维度特征匹配结果。
步骤25、计算所有帧特征之间的帧间特征关联度,及第一词性特征和第二词性特征之间的词性间特征关联度,将所述帧间特征关联度与所述词性间特征关联度进行时间维度特征匹配,获得时间维度特征匹配结果。
步骤26、对所述空间维度特征匹配结果和所述时间维度特征匹配结果进行融合,获得联合空间时间维度特征匹配结果。
步骤27、将所述联合空间时间维度特征匹配结果作为正则项与对比排序损失函数进行数学运算获得损失函数。
在本实施例中,步骤24至步骤27可参照上述实施例中的步骤141至步骤144进行理解,此处不再赘述。
步骤28、利用反向梯度传播法对所述预训练的视频文本跨模态模型的参数进行训练,直至所述损失函数实现收敛,并利用验证样本集集进行准确率判定,当准确率达到预设标准时获得训练好的跨模态检索模型。
在本步骤中,当利用反向梯度传播法对所述预训练的视频文本跨模态模型的参数进行训练,直至所述损失函数实现收敛之后,利用验证样本集进行准确率判定。
具体地,如图6所示,图6是本发明另一实施例中步骤28的实现方法流程图,利用验证样本集进行准确率判断可通过以下步骤实现:
步骤281、将所述验证样本集中的每一段视频输入所述训练好的跨模态检索模型中。
步骤282、计算所述训练好的跨模态检索模型搜索到的前预设数目个搜索结果中出现正确样本占验证样本集中总样本数的比例,得到第一检索准确率结果。
步骤283、将所述第一检索准确率结果与仅利用对比排序损失函数作为损失函数进行训练的跨模态检索模型时获取的第二检索准确率结果进行性能增益的判定。
步骤284、当所述第一检索准确率结果与所述第二检索准确率结果相比存在性能增益时,确定跨模态检索模型训练正确。
步骤29、依次逐条将测试样本集中的视频和文本输入训练好的跨模态检索模型中,得到检索准确率结果。
在本步骤中,依次逐条读取测试样本集中的视频和文本,加载至训练好的跨模态检索模型中,进行检索准确率测试,得到检索准确率结果。
由此,本发明提供的技术方案,充分考虑了视频和文本两种异构模态数据关于语义内容表征方式的差异性,并将该特性体现在视频文本跨模态特征匹配当中,细化了视频文本跨模态特征匹配粒度,增强了视频文本跨模态特征匹配过程的可解释性,提高了视频文本跨模态检索的准确率。
同时,本发明实施例提出了一种新的端到端可训练的神经网络正则化跨模态检索模型,该跨模态检索模型同时联合了空间和时间两个维度进行特征匹配。首先利用帧特征与名词特征进行空间维度特征匹配,之后利用帧间特征关联与动名词间特征关联进行时间维度特征匹配,最后将空间时间维度特征匹配有效融合实现可用于视频文本跨模态检索的联合空间时间维度特征匹配,并构建成正则项与现有对比排序损失函数进行联合训练。本发明可有效利用视频文本中的显著关键信息,提高视频文本跨模态检索的准确率。
相应的,本发明实施例还提供一种视频文本跨模态检索装置,参见图7,图7是本发明实施例提供的视频文本跨模态检索装置的结构示意图,所述装置包括:
获取模块31,用于获取训练样本集,所述训练样本集包括成对标注的视频和文本;
帧特征提取模块32,用于对所述视频进行分帧处理,并提取帧特征;
词特征提取模块33,用于对所述文本进行分词处理并提取词特征,所述词特征包括至少两类词性特征;
训练模块34,用于利用所述帧特征和至少两种词性特征对预训练的跨模态检索模型进行训练,获得训练好的跨模态检索模型;
检索模块35,用于将待测视频和文本输入所述训练好的跨模态检索模型中进行视频和文本的跨模态检索。
进一步的,所述帧特征提取模块32可包括以下单元:
分帧单元321,用于利用分帧工具依次对每一段视频进行分帧处理,获得帧序列,将所述帧序列均匀划分为时长相等的预设段,提取每段的第一帧,获得预设帧。
帧特征提取单元,用于运用卷积神经网络ResNet提取所述预设帧的帧特征。
进一步的,词特征提取模块33可包括以下单元:
分词单元331,用于利用分词工具依次对每一条文本进行分词;
分类单元332,用于利用Simple-bert语义角色标注工具对每个词的词性进行分类;
词特征提取单元333,用于利用全局词频统计词表征工具和门控循环单元词特征提取工具提取词特征,所述词特征包括至少两类种词性特征。
进一步的,所述词性特征包括第一词性特征和第二词性特征,训练模块 34可包括以下单元:
空间维度特征匹配单元341,用于将所述帧特征与所述第一词性特征进行空间维度特征匹配,获得空间维度特征匹配结果;
时间维度特征匹配单元342,用于计算所有帧特征之间的帧间特征关联度,及第一词性特征和第二词性特征之间的词性间特征关联度,将所述帧间特征关联度与所述词性间特征关联度进行时间维度特征匹配,获得时间维度特征匹配结果;
联合空间时间维度特征匹配单元343,用于对所述空间维度特征匹配结果和所述时间维度特征匹配结果进行融合,获得联合空间时间维度特征匹配结果;
损失函数单元344,用于将所述联合空间时间维度特征匹配结果作为正则项与对比排序损失函数进行数学运算获得损失函数;
训练单元345,用于利用反向梯度传播法对所述预训练的视频文本跨模态模型的参数进行训练,直至所述损失函数实现收敛。
相应的,本发明实施例还提供另一种视频文本跨模态检索装置,参见图8,图8是本发明实施例提供的另一种视频文本跨模态检索装置的结构示意图,所述装置包括:
获取模块41,用于获取训练样本集、验证样本集和测试样本集,所述训练样本集包括成对标注的视频和文本。
字典模块42,用于将所述训练数据集中的视频和文本分别写入到以视频和文本序列号名称作为查询键的字典文件中。
特征提取模块43,用于对各所述字典文件中序列号名称对应的视频进行分帧处理,并提取帧特征,对各所述字典文件中序列号名称对应的文本进行分词处理并提取词特征,所述词特征包括名词特征和动词特征。
空间维度特征匹配模块44,用于将所述帧特征与所述第一词性特征进行空间维度特征匹配,获得空间维度特征匹配结果。
时间维度特征匹配模块45,用于计算所有帧特征之间的帧间特征关联度,及第一词性特征和第二词性特征之间的词性间特征关联度,将所述帧间特征关联度与所述词性间特征关联度进行时间维度特征匹配,获得时间维度特征匹配结果。
联合空间时间维度特征匹配模块46,用于对所述空间维度特征匹配结果和所述时间维度特征匹配结果进行融合,获得联合空间时间维度特征匹配结果。
损失函数计算模块47,用于将所述联合空间时间维度特征匹配结果作为正则项与对比排序损失函数进行数学运算获得损失函数。
训练验证模块48,用于利用反向梯度传播法对所述预训练的视频文本跨模态模型的参数进行训练,直至所述损失函数实现收敛,并利用验证样本集集进行准确率判定,当准确率达到预设标准时获得训练好的跨模态检索模型。
测试模块49,用于依次逐条将测试样本集中的视频和文本输入训练好的跨模态检索模型中,得到检索准确率结果。
进一步的,训练验证模块48可包括:
输入单元481,用于将所述验证样本集中的每一段视频输入所述训练好的跨模态检索模型中。
第一检索模块482,用于计算所述训练好的跨模态检索模型搜索到的前预设数目个搜索结果中出现正确样本占验证样本集中总样本数的比例,得到第一检索准确率结果。
增益判断单元483,用于将所述第一检索准确率结果与仅利用对比排序损失函数作为损失函数进行训练的跨模态检索模型时获取的第二检索准确率结果进行性能增益的判定。
比较单元484,用于当所述第一检索准确率结果与所述第二检索准确率结果相比存在性能增益时,确定跨模态检索模型训练正确。
由此,本发明提供的技术方案,充分考虑了视频和文本两种异构模态数据关于语义内容表征方式的差异性,并将该特性体现在视频文本跨模态特征匹配当中,细化了视频文本跨模态特征匹配粒度,增强了视频文本跨模态特征匹配过程的可解释性,提高了视频文本跨模态检索的准确率。
同时,本发明实施例提出了一种新的端到端可训练的神经网络正则化跨模态检索模型,该跨模态检索模型同时联合了空间和时间两个维度进行特征匹配。首先利用帧特征与名词特征进行空间维度特征匹配,之后利用帧间特征关联与动名词间特征关联进行时间维度特征匹配,最后将空间时间维度特征匹配有效融合实现可用于视频文本跨模态检索的联合空间时间维度特征匹配,并构建成正则项与现有对比排序损失函数进行联合训练。本发明可有效利用视频文本中的显著关键信息,提高视频文本跨模态检索的准确率。
需要说明的是,本发明实施例中的视频文本跨模态检索装置与上述方法属于相同的发明构思,未在本装置中详述的技术细节可参见前面对方法的相关描述,在此不再赘述。
此外,本发明实施例还提供一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行前面所述的方法。
本发明实施例还提供一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行前面所述的方法。
本领域普通技术人员可以理解上述方法中的全部或部分步骤可通过程序来指令相关硬件(例如处理器)完成,所述程序可以存储于计算机可读存储介质中,如只读存储器、磁盘或光盘等。可选地,上述实施例的全部或部分步骤也可以使用一个或多个集成电路来实现。相应地,上述实施例中的每个模块/单元可以采用硬件的形式实现,例如通过集成电路来实现其相应功能,也可以采用软件功能模块的形式实现,例如通过处理器执行存储于存储器中的程序/指令来实现其相应功能。本发明不限制于任何特定形式的硬件和软件的结合。
虽然本发明所揭露的实施方式如上,但所述的内容仅为便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。