一种基于术中多维因素的全麻病人体温预测方法及装置
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于人工智能技术领域,具体涉及一种基于术中多维因素的全麻病人体温预测方法及装置。
背景技术
体温是重要的生命体征。体温维持对人体各项机能正常运转至关重要。已有研究显示:术中有50%~70%的病人会出现低体温(术中低体温是指体温在手术中的任何时间点小于36℃)。全身麻醉下实施手术的病人由于麻醉剂对机体温度调节的影响、术中大量输注低温液体和机体长时间暴露于相对低温环境等原因,常发生术中低体温。低体温一方面可以降低机体代谢率、减少耗氧量、增加组织器官对缺血和缺氧的耐受力;另一方面也可导致多种并发症,如麻醉药物代谢减慢引起药物中毒、寒战、心律失常、凝血机制障碍、酸碱平衡紊乱以及发生麻醉苏醒延迟等,最终影响手术安全性和预后。因此,术中全麻病人体温的预测具有重要意义。
现有术中全麻病人体温预测的方法,一般是先确定影响病人体温的因素,搜集历史数据,建立以这些因素为自变量、以病人体温为因变量的函数模型,基于所述历史数据对模型参数进行学习得到体温预测模型,利用得到的体温预测模型对术中全麻病人体温进行预测。这种方法的优点是简单可行,存在的问题是预测精度不是很理想,有时很难满足临床要求。
发明内容
为了解决现有技术中存在的上述问题,本发明提供一种基于术中多维因素的全麻病人体温预测方法及装置。
为了实现上述目的,本发明采用以下技术方案。
第一方面,本发明提供一种基于术中多维因素的全麻病人体温预测方法,包括以下步骤:
基于临床经验和历史数据分析,确定影响术中全麻病人体温的多维度因素,并基于所述因素确定对体温影响最显著的特征数据;
基于人工神经网络构建以所述特征数据为输入、以体温为输出的体温预测模型;
利用历史数据对所述体温预测模型进行训练,利用训练好的模型对术中全麻病人的体温进行预测。
进一步地,所述方法还包括:若预测体温低于36.0℃,则为低体温。
进一步地,影响术中全麻病人体温的因素包括:病人年龄,病人性别,病人体质指数;总输液量,总输血量,总出量,麻醉时长,手术时长;麻醉师级别,医护水平;手术室温,手术室湿度。
进一步地,所述基于所述因素确定对体温影响最显著的特征,具体包括:
将每种因素量化,分别计算量化后每种因素的统计量,所述统计量包括最大值、最小值、中值、平均值、方差和均方差;
将每种因素的不同统计量以及同种因素的不同统计量的任意组合分别作为一种特征数据;
基于相关性对所述特征数据进行筛选,得到对体温影响最显著的特征数据。
更进一步地,所述基于相关性对所述特征数据进行筛选,具体包括:
计算任意一个特征数据与体温的相关系数,并对所述特征数据按照相关系数从大到小的顺序排序;
删除相关系数小于第一阈值的特征数据;
计算剩余的特征数据中任意两个特征数据之间的相关系数,对于相关系数大于第二阈值的两个特征数据,删除排序靠后的一个特征数据,使任意两个特征数据之间的相关系数均不大于第二阈值,得到筛选后的特征数据。
进一步地,采用径向基函数神经网络构建体温预测模型。
更进一步地,采用遗传算法对径向基函数神经网络的参数进行优化,方法如下:
数据归一化:确定训练样本并对样本数据进行归一化处理;
染色体编码:采用实数编码对径向基函数神经网络的数据中心c
种群初始化:最佳初始种群规模的取值范围为20~70;
构造适应度函数:适应度函数的表达式为:
式中,F
选择运算:采用轮盘赌法选择种群中适应度大的个体,将种群中每个个体适应度分配到一个赌盘中,适应度值与在赌盘中所占面积成比例,通过转动赌盘指针来选择个体;第i个个体被选中的概率为:
式中,P
交叉运算:采用算数交叉法进行交叉运算,将个体g
式中,α为比例因子,0<α<1;
交叉概率P
/>
式中,f
变异运算:在种群内随机选择个体,将选择个体的染色体某些位置基因中以一定的概率P
式中,f为变异个体的适应度值,P
若满足预设收敛条件或超出最大迭代次数,则停止;否则,转染色体编码步骤重复执行迭代过程。
第二方面,本发明提供一种基于术中多维因素的全麻病人体温预测装置,包括:
因素确定模块,用于基于临床经验和历史数据分析,确定影响术中全麻病人体温的多维度因素,并基于所述因素确定对体温影响最显著的特征数据;
模型构建模块,用于基于人工神经网络构建以所述特征数据为输入、以体温为输出的体温预测模型;
体温预测模块,用于利用历史数据对所述体温预测模型进行训练,利用训练好的模型对术中全麻病人的体温进行预测。
进一步地,所述装置还包括低体温预测模块,用于预测低体温,若预测体温低于36.0℃,则为低体温。
进一步地,影响术中全麻病人体温的因素包括:病人年龄,病人性别,病人体质指数;总输液量,总输血量,总出量,麻醉时长,手术时长;麻醉师级别,医护水平;手术室温,手术室湿度。
进一步地,所述基于所述因素确定对体温影响最显著的特征,具体包括:
将每种因素量化,分别计算量化后每种因素的统计量,所述统计量包括最大值、最小值、中值、平均值、方差和均方差;
将每种因素的不同统计量以及同种因素的不同统计量的任意组合分别作为一种特征数据;
基于相关性对所述特征数据进行筛选,得到对体温影响最显著的特征数据。
进一步地,所述基于相关性对所述特征数据进行筛选,具体包括:
计算任意一个特征数据与体温的相关系数,并对所述特征数据按照相关系数从大到小的顺序排序;
删除相关系数小于第一阈值的特征数据;
计算剩余的特征数据中任意两个特征数据之间的相关系数,对于相关系数大于第二阈值的两个特征数据,删除排序靠后的一个特征数据,使任意两个特征数据之间的相关系数均不大于第二阈值,得到筛选后的特征数据。
进一步地,采用径向基函数神经网络构建体温预测模型。
更进一步地,采用遗传算法对径向基函数神经网络的参数进行优化,方法如下:
数据归一化:确定训练样本并对样本数据进行归一化处理;
染色体编码:采用实数编码对径向基函数神经网络的数据中心c
种群初始化:最佳初始种群规模的取值范围为20~70;
构造适应度函数:适应度函数的表达式为:
式中,F
选择运算:采用轮盘赌法选择种群中适应度大的个体,将种群中每个个体适应度分配到一个赌盘中,适应度值与在赌盘中所占面积成比例,通过转动赌盘指针来选择个体;第i个个体被选中的概率为:
式中,P
交叉运算:采用算数交叉法进行交叉运算,将个体g
式中,α为比例因子,0<α<1;
交叉概率P
式中,f
变异运算:在种群内随机选择个体,将选择个体的染色体某些位置基因中以一定的概率P
式中,f为变异个体的适应度值,P
若满足预设收敛条件或超出最大迭代次数,则停止;否则,转染色体编码步骤重复执行迭代过程。
与现有技术相比,本发明具有以下有益效果。
本发明通过基于临床经验和历史数据分析,确定影响术中全麻病人体温的多维度因素,并基于所述因素确定对体温影响最显著的特征数据,基于人工神经网络构建以所述特征数据为输入、以体温为输出的体温预测模型,利用历史数据对所述体温预测模型进行训练,利用训练好的模型对术中全麻病人的体温进行预测,实现了术中全麻病人的体温预测。本发明通过基于人工神经网络构建以对体温影响最显著的特征数据为输入、以体温为输出的体温预测模型,并利用训练好的模型进行体温预测,提高了体温预测精度。
附图说明
图1为本发明实施例一种基于术中多维因素的全麻病人体温预测方法的流程图。
图2为遗传算法流程图。
图3为本发明实施例一种基于术中多维因素的全麻病人体温预测装置的方框图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚、明白,以下结合附图及具体实施方式对本发明作进一步说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
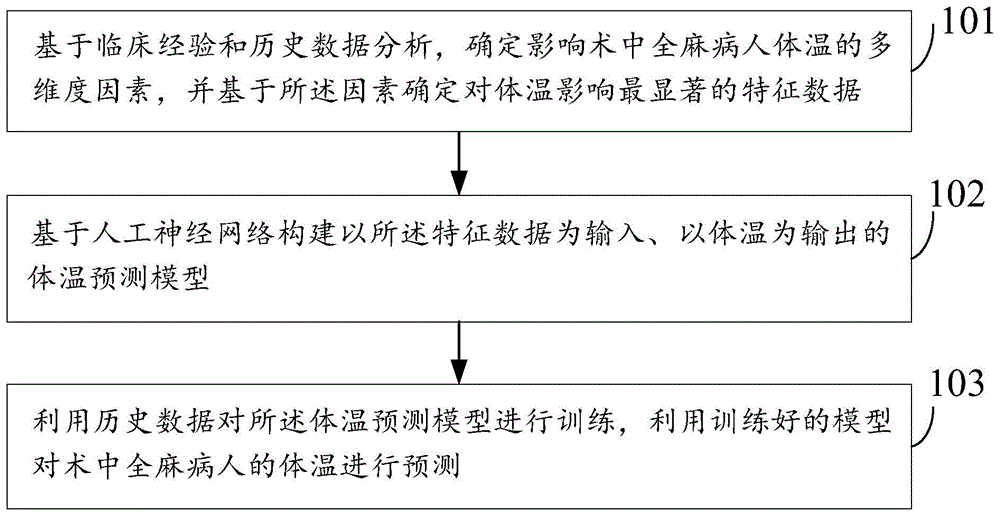
图1为本发明实施例一种基于术中多维因素的全麻病人体温预测方法的流程图,包括以下步骤:
步骤101,基于临床经验和历史数据分析,确定影响术中全麻病人体温的多维度因素,并基于所述因素确定对体温影响最显著的特征数据;
步骤102,基于人工神经网络构建以所述特征数据为输入、以体温为输出的体温预测模型;
步骤103,利用历史数据对所述体温预测模型进行训练,利用训练好的模型对术中全麻病人的体温进行预测。
本实施例中,步骤101主要用于确定对体温影响最显著的特征数据。本实施例是通过建立体温预测模型对术中全麻病人体温进行预测,因此模型的预测精度至关重要。模型结构是影响模型预测精度的重要因素,除此之外,模型输入变量的选取对模型精度也至关重要。要想获得高精度的预测模型,模型的输出相对输入的变化应很敏感,输入很小的改变就能引起输出明显的变化,也就是输入变量对输出的影响应很显著。本实施例确定对体温影响最显著的特征数据,就是为了确定体温预测模型的输入变量(以所述特征数据为模型的输入)。本实施例先基于临床经验以及通过对历史数据分析,确定影响术中全麻病人体温的因素,然后基于这些因素确定对体温影响最显著的特征数据。一般是先将这些因素量化,然后对这些量化后的数据进行整合、筛选,得到对体温影响最显著的特征数据。为了避免遗漏对体温影响较显著的因素,在确定影响因素时可不考虑影响大小,只要有影响就行,也就是说应获得尽量多的影响因素;而且应尽量从多个维度获取影响因素,比如,病人本身情况(年龄、性别、体质、术前体温、紧张程度等),手术室内环境(温湿度),麻醉情况(麻醉时长、麻醉师级别),医护水平(医生、护士水平)等。
本实施例中,步骤102主要用于建立基于体温预测模型。本实施例以上一步确定的对体温影响最显著的特征数据为输入变量、以体温为输出构建体温预测模型,选取人工神经网络作为模型结构。人工神经网络也常直接简称为神经网络或类神经网络,是从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。神经网络具有自学习功能,可以充分逼近任意复杂的非线性关系,因此可以达到很高的预测精度。能够用作预测模型的神经网络结构很多,比如最常见的BP(Back Propagation,BP)神经网络,这是一种反向传播的神经网络,模型训练时通过误差反向传播,不断修正网络的权值和阈值,进而使误差下降提高预测精度。BP神经网络具有很高的非线性映射能力和较强的泛化能力,被广泛应用于智能控制、数据处理、模式识别、预测估计等领域。本实施例对具体的神经网络结构不作限定,后面的实施例将给出一种具体的神经网络结构。
本实施例中,步骤103主要用于通过利用历史数据进行模型训练得到体温预测模型。步骤102只是确定了模型的输入输出变量和模型结构,还需要通过模型训练确定模型参数。模型训练好后,将各个输入变量的数据输入训练好的模型,模型即可输出体温,从而实现对术中麻醉病人体温的预测。模型训练的关键是基于历史数据建立训练数据集。下面给出获取历史数据方法的一种具体实例。
研究对象选取2018年1月1日~2018年12月31日在某医院采取基础保温措施的9155例全身麻醉手术病人作为研究对象。纳入标准:接受全身麻醉手术;术中有体温监测数据且体温>30℃;年龄>18岁。纳入的病人中术中发生低体温的病人1420例,未发生低体温的病人7736例。将1420例体温30℃~<36℃的病人视为术中发生低体温,纳入低体温组,将7736例体温≥36℃的病人视为正常低体温,纳入正常组。采取以下方法进行体温及术中低体温发生影响因素记录:每台麻醉监护仪均配有定期校准、检测精准的体温探头。病人行麻醉诱导并插入气管插管后,将体温探头置入病人鼻咽部,手术结束后拔除探头。期间麻醉师需点击记录麻醉开始时间、手术开始时间、手术结束时间,且所有体温数据及术中关键数据都会记录在手术麻醉系统中。收集从麻醉开始且体温描绘开始后整个监测期间手术麻醉系统中记录的大于30℃的体温数据。从医院手术麻醉系统中影响体温的多给因素的关键数据,如病人性别、病人年龄、输液量、麻醉时长、手术时长等。剔除无效、记录不实数据,如食管癌根治术出血量为0mL;剔除有缺失数据的病人数据,如手术麻醉系统无出入量等记录;剔除逻辑核查有误数据,如描述的总出量为1000mL,但实际出量合计值为800mL等;手术麻醉系统中记录的麻醉时间小于手术时间的数据。
作为一可选实施例,所述方法还包括:若预测体温低于36.0℃,则为低体温。
本实施例给出了预测低体温的一种技术方案。术中低体温有很多不良影响。低体温一方面可以降低机体代谢率、减少耗氧量、增加组织器官对缺血和缺氧的耐受力;另一方面也可导致多种并发症,如麻醉药物代谢减慢引起药物中毒、寒战、心律失常、凝血机制障碍、酸碱平衡紊乱以及发生麻醉苏醒延迟等,最终影响手术安全性和预后。因此,术中全麻病人低体温预测非常重要。为此,本实施例给出了基于预测体温识别低体温的一种技术方案,如果体温低于36.0℃,则判定为低体温。
作为一可选实施例,影响术中全麻病人体温的因素包括:病人年龄,病人性别,病人体质指数;总输液量,总输血量,总出量,麻醉时长,手术时长;麻醉师级别,医护水平;手术室温,手术室湿度。
本实施例给出了几种常用的影响术中全麻病人体温的因素。本实施例从多个维度给出了影响体温的因素。例如,病人自身因素,包括病人年龄、病人性别、病人体质指数等;手术相关情况,包括总输液量,总输血量,总出量,麻醉时长,手术时长等;医护情况,包括麻醉师级别,医护水平等;环境参数,包括手术室温,手术室湿度。值得说明的是,本实施例只是给出了一种较佳的实施例,并不否定和排斥其它可行的实施方式,比如其它维度因素和相同维度的其它因素等。
作为一可选实施例,所述基于所述因素确定对体温影响最显著的特征,具体包括:
将每种因素量化,分别计算量化后每种因素的统计量,所述统计量包括最大值、最小值、中值、平均值、方差和均方差;
将每种因素的不同统计量以及同种因素的不同统计量的任意组合分别作为一种特征数据;
基于相关性对所述特征数据进行筛选,得到对体温影响最显著的特征数据。
本实施例给出了确定对体温影响最显著的特征的一种技术方案。本实施例是通过对已确定的各种体温影响因素进行整合和筛选,确定对体温影响最显著的特征数据。
由于很多影响因素是用量化数据表示,比如性别、医护水平等,因此需要先对每种因素进行量化,将它们转换为特征数据,比如将性别“男”、“女”分别量化为1、2。对于本来就有量化特征的因素,如年龄25岁,可以将其直接用作特征数据,也可以经放大或缩小或归一化后用作特征数据。
将影响因素量化处理后,就可以对这些影响因素进行整合了。先计算每种因素量化数据的统计量,如最大值、最小值、方差等。为了能够得到尽量多和新的特征数据,不但可以将这些统计量作为新的特征数据,还可以将它们的任意组合作为新的特征数据。所述组合可以是任意两个或多个统计量之间的各种运算操作,如相加减、加减乘除混合运算,也可以是拼接等。事实表明,很多整合后的特征数据比整合前的原统计量对输出的影响更显著,这一点可通过计算这些特征数据与输出数据的相关性得到验证——整合后的特征数据与输出数据的相关性大于整合前的原统计量与输出数据的相关性。
最后,对整合前、后的特征数据进行筛选,得到对体温影响最显著的特征数据。本实施例基于相关性对特征数据进行筛选,保留与输出数据相关性最强的几个特征数据作为对体温影响最显著的特征数据。后面的实施例将给出一种具体的筛选方法。
作为一可选实施例,所述基于相关性对所述特征数据进行筛选,具体包括:
计算任意一个特征数据与体温的相关系数,并对所述特征数据按照相关系数从大到小的顺序排序;
删除相关系数小于第一阈值的特征数据;
计算剩余的特征数据中任意两个特征数据之间的相关系数,对于相关系数大于第二阈值的两个特征数据,删除排序靠后的一个特征数据,使任意两个特征数据之间的相关系数均不大于第二阈值,得到筛选后的特征数据。
本实施例给出了基于相关性对特征数据进行筛选的一种技术方案。进行特征数据筛选是为了确定预测模型的最有效的输入变量。最有效的输入变量应是与体温相关性最强的几种特征数据。因此,首先计算每种特征数据与体温的相关系数,并按照从大到小的顺序对它们排序。然后删除相关系数小于第一阈值的特征数据,得到与体温相关性最强(排在最前面)的几个特征数据。但是这样筛选后得到的特征数据的数量可能不是最少,其中有些特征数据之间的相关性可能比较强,这些相关性较强的特征数据对体温的影响近似相同或重复,如果将它们都作为输入变量同样会影响模型的效能(复杂度和精度),应只保留相关性较强的特征中的一个。为此,再计算第一次筛选后得到的特征数据的任意两个之间的相关系数,删除相关系数大于第二阈值的两个特征中排序靠后的一个特征数据。
作为一可选实施例,采用径向基函数神经网络构建体温预测模型。
本实施例给出了体温预测模型的一种神经网络结构。本实施例的预测模型采用径向基函数神经网络(Redial Basis Function,RBF)结构。RBF神经网络是由J.Moody和C.Darken在20世纪80年代提出的一种前馈神经网络,是以函数逼近为基础的神经网络,它具有收敛速度快、构造简单以及很强的非线性逼近能力等特点,能够以任意精度逼近任意函数,受到各领域研究人员的广泛关注,被广泛应用于信息预测、自动化控制、数据分类及模式识别等众多研究领域。RBF神经网络包括输入层、隐含层和输出层。输入层主要用于将接收的信号传至隐含层;隐含层由众多神经元组成,为整个RBF神经网络的核心,神经元根据实际问题选取不同的径向基函数,主要用于从低维空间将输入向量映射到高维特征空间中,向量从低维不可分变为在高维空间线性可分。径向基函数就是RBF神经网络隐含层的核函数,其函数图像关于径向对称。径向基函数的选取是影响RBF预测性能的主要因素,因此需要根据实际问题进行选取对应的径向基函数。由于Gaussian函数具有对称性、光滑性及解析力强等优点,因此是最常用的基函数。其表达式为:
式中,x为输入向量,c
因为RBF隐含层到输出层是线性变换,则第k个神经元输出y
式中,R
作为一可选实施例,采用遗传算法对径向基函数神经网络的参数进行优化,方法如下:
数据归一化:确定训练样本并对样本数据进行归一化处理;
染色体编码:采用实数编码对径向基函数神经网络的数据中心c
种群初始化:最佳初始种群规模的取值范围为20~70;
构造适应度函数:适应度函数的表达式为:
式中,F
选择运算:采用轮盘赌法选择种群中适应度大的个体,将种群中每个个体适应度分配到一个赌盘中,适应度值与在赌盘中所占面积成比例,通过转动赌盘指针来选择个体;第i个个体被选中的概率为:
式中,P
交叉运算:采用算数交叉法进行交叉运算,将个体g
式中,α为比例因子,0<α<1;
交叉概率P
式中,f
变异运算:在种群内随机选择个体,将选择个体的染色体某些位置基因中以一定的概率P
式中,f为变异个体的适应度值,P
若满足预设收敛条件或超出最大迭代次数,则停止;否则,转染色体编码步骤重复执行迭代过程。
本实施例给出了对预测网络模型进行改进的一种技术方案。RBF神经网络的三个参数(数据中心c
图3为本发明实施例一种基于术中多维因素的全麻病人体温预测装置的组成示意图,所述装置包括:
因素确定模块11,用于基于临床经验和历史数据分析,确定影响术中全麻病人体温的多维度因素,并基于所述因素确定对体温影响最显著的特征数据;
模型构建模块12,用于基于人工神经网络构建以所述特征数据为输入、以体温为输出的体温预测模型;
体温预测模块13,用于利用历史数据对所述体温预测模型进行训练,利用训练好的模型对术中全麻病人的体温进行预测。
本实施例的装置,可以用于执行图1所示方法实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。后面的实施例也是如此,均不再展开说明。
作为一可选实施例,所述装置还包括低体温预测模块,用于预测低体温,若预测体温低于36.0℃,则为低体温。
作为一可选实施例,影响术中全麻病人体温的因素包括:病人年龄,病人性别,病人体质指数;总输液量,总输血量,总出量,麻醉时长,手术时长;麻醉师级别,医护水平;手术室温,手术室湿度。
作为一可选实施例,所述基于所述因素确定对体温影响最显著的特征,具体包括:
将每种因素量化,分别计算量化后每种因素的统计量,所述统计量包括最大值、最小值、中值、平均值、方差和均方差;
将每种因素的不同统计量以及同种因素的不同统计量的任意组合分别作为一种特征数据;
基于相关性对所述特征数据进行筛选,得到对体温影响最显著的特征数据。
作为一可选实施例,所述基于相关性对所述特征数据进行筛选,具体包括:
计算任意一个特征数据与体温的相关系数,并对所述特征数据按照相关系数从大到小的顺序排序;
删除相关系数小于第一阈值的特征数据;
计算剩余的特征数据中任意两个特征数据之间的相关系数,对于相关系数大于第二阈值的两个特征数据,删除排序靠后的一个特征数据,使任意两个特征数据之间的相关系数均不大于第二阈值,得到筛选后的特征数据。
作为一可选实施例,采用径向基函数神经网络构建体温预测模型。
作为一可选实施例,采用遗传算法对径向基函数神经网络的参数进行优化,方法如下:
数据归一化:确定训练样本并对样本数据进行归一化处理;
染色体编码:采用实数编码对径向基函数神经网络的数据中心c
种群初始化:最佳初始种群规模的取值范围为20~70;
构造适应度函数:适应度函数的表达式为:
式中,F
选择运算:采用轮盘赌法选择种群中适应度大的个体,将种群中每个个体适应度分配到一个赌盘中,适应度值与在赌盘中所占面积成比例,通过转动赌盘指针来选择个体;第i个个体被选中的概率为:
式中,P
交叉运算:采用算数交叉法进行交叉运算,将个体g
式中,α为比例因子,0<α<1;
交叉概率P
式中,f
变异运算:在种群内随机选择个体,将选择个体的染色体某些位置基因中以一定的概率P
式中,f为变异个体的适应度值,P
若满足预设收敛条件或超出最大迭代次数,则停止;否则,转染色体编码步骤重复执行迭代过程。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。