基于特征融合和改进卷积神经网络的轧制声音分类方法
文献发布时间:2024-01-17 01:17:49
技术领域
本发明涉及深度学习应用技术领域,特别涉及基于特征融合和改进卷积神经网络的轧制声音分类方法,用于轧制现场声音分类。
背景技术
在轧制现场通常伴随着钢板掉落、人声、设备运行声、环境噪声等多类型声音,这些声学数据中包含了海量的可研究信息,因此对轧制现场声音进行精准识别分类具有非常重要的现实意义。
目前,深度学习的发展在钢厂图像方面的应用较为迅速,如利用对抗生成网络GAN提升样本数量和质量、基于图像分割的皮带跑偏检测以及钢板的缺陷检测等。然而,面对部分工艺流程存在水汽、环境昏暗等影响,难以采集到相关的视频图像信息,这也使钢厂某些工艺流程依赖于听力,同时基于声音信号的相关研究也成为了工业智能领域发展的热点技术。
在视觉领域发展的基础上,根据音频特点提取相应的特征,生成图片特征作为网络的输入,有不少研究数据证明已经取得较好的成果,但针对钢厂轧制现场的应用,现有技术无法精准分类相似度高且背景音复杂的声音对象,其模型应用效果无法统一,难以在实际工作中得到应用,并且研究相对较少。本发明在四个特征中突出了音频的特点,有效降低了类别间的相似度和音频内容的复杂度,进而提高轧制环境声音分类准确率。
发明内容
针对上述技术问题,本发明提供一种基于特征融合和改进卷积神经网络模型的轧制声音分类方法,该方法融合多种不同的音频特征作为网络的输入,以VGG-16卷积神经网络模型为基础进行改进;本发明提供的方法在特征和模型两方面同步改进,进而提高轧制环境声音分类准确率;在基于声音信号的钢厂环境监测、设备状态以及故障检测等方面有着广泛的应用前景。
本发明采用的技术方案:
基于特征融合和改进卷积神经网络的轧制声音分类方法,所述轧制声音分类方法包括下列步骤:
(1)数据预处理:采集轧制现场声音数据并进行数据清理、迭代标记、数据格式统一化及数据增样操作;
(2)构建多通道特征数据集:对步骤(1)中预处理后的音频数据提取若干种音频特征图,进行特征通道融合,生成多通道特征图;并采用深度学习数据增强方法对所述多通道特征图进行数据量扩充,构建获得多通道特征数据集;
(3)改进及训练卷积神经网络模型:构建获得改进的VGG卷积神经网络分类模型,将步骤(2)中获得的所述多通道特征数据集输入到所述改进的VGG卷积神经网络分类模型中,迭代训练,进而得到分类网络模型;
(4)输出分类结果:向步骤(3)中获得的所述分类网络模型中输入新采集的源数据,输出模型分类准确率和类别判定结果。
进一步地,步骤(1)中,所述数据清理包括:清除音频数据中无声音频数据,以及清除音频数据中音频文件大小为0字节的空文件;
进一步地,所述数据格式统一化包括:裁剪音频数据,使音频数据时间长度统一,并以统一格式,保存。
进一步地,步骤(1)中,所述迭代标记包括:根据轧制现场声音采集点位来迭代标记数据类别;
迭代标记的数据类别包括:钢板剪切声音、钢板掉落声音、钢板输出声音、现场水雾声声音、板坯传动声音、咬钢声。
进一步地,步骤(1)中,所述数据增样包括:随机选择同一轧制现场声音采集点位的音频A和音频B两条音频,截取音频A中的片段随机替换音频B中相同时长的片段,生成新的音频数据C,完成数据增样。
进一步地,步骤(2)具体为:
对步骤(1)中预处理后音频数据进行音频特征提取,并进行数据标准化处理;其中,使用以下方法处理音频信号以提取特征:梅尔频率倒谱系数(MFCC)、色谱图、宽带语谱图和窄带语谱图;
将提取的特征堆叠在一起进行特征通道融合,每个特征均为224维,生成多通道特征图,作为卷积神经网络的输入,多通道特征图输入尺寸统一为224*224*n(n为通道数),以此为网络创建一个n通道输入特征图;
利用深度学习数据增强方法对生成的所述多通道特征图进行数据量扩充,构建获得多通道特征数据集;基于整个数据集数据的大小,将所述多通道特征数据集按比例随机分为训练集和测试集。
进一步地,在提取获得MFCC的过程中,选用矩形窗函数对每一帧信号进行加窗处理,以避免频谱泄露;
在提取获得色度频率的过程中,相邻窗之间的距离设为512;
在提取获得宽带语谱图的过程中,通过设置48000Hz的语音采样率,FFT长度设为1024,并取20-40个数据点的窗长以及10-80个数据点帧移,选用汉明窗函数;
在提取获得窄带语谱图的过程中,设置语音采样率为48000Hz,取窗长为200-400个数据点,帧移为100-160个数据点,选用汉明窗函数。
进一步地,步骤(2)中,所述深度学习数据增强方法包括亮度增强、网格掩码和注入噪声;通过将亮度增强和所述网格掩码作为主方法,对每张多通道特征图进行亮度增强和网格掩码操作,然后注入随机噪声。
进一步地,步骤(3)中,构建改进的VGG卷积神经网络分类模型,具体包括:
以VGG-16卷积神经网络作为基础结构,对卷积池化层和分类层进行改进;
对卷积池化层的改进包括:对于源VGG-16卷积神经网络结构中的三层512个卷积核的池化层,采用随机池化代替最大池化,以减少计算量同时提高网络的泛化能力;
对分类层的改进包括:将源VGG-16卷积神经网络结构中的三层全连接层替换为全局平均池化层和注意力机制模块,以减少网络参数、优化网络以及提升网络的分类精度。
进一步地,将步骤(2)中获得的所述多通道特征数据集输入到所述改进的VGG卷积神经网络分类模型中,迭代训练,得到分类网络模型的方法具体包括:
步骤(2)中获得的所述多通道特征数据集输入到改进的VGG-16卷积网络模型中迭代训练,直到模型分类准确率达到饱和状态,即模型准确率达到最大值,不再提升,得到最优的模型参数,保存此时的分类网络,得到所述分类网络模型。
本发明有益技术效果:
(1)本发明提供的基于特征融合和改进卷积神经网络模型的轧制声音分类方法,弥补了钢厂轧制基于语音信号分类领域研究的空白。
(2)本发明所述方法中提出的多通道特征相对于单特征,结合不同特征为网络提供了更多可区分的特征和互补的特征表示,以提高分类的准确性和模型的性能;并且在源数据集基础上采用了深度学习数据增强方法,构建了一个新的小规模基准数据集,有效解决网络过拟合的问题。
(3)本发明提供的方法在网络模型方面,包含卷积池化层和分类层的改进;相对于源VGG-16卷积神经网络结构,将三层512个卷积核的池化层由随机池化代替最大池化,减少了计算量的同时也提高了网络的泛化能力;在分类层,将源模型中的三层全连接层替换为全局平均池化层和注意力机制模块,大幅度减少网络参数,优化网络的同时提升网络的分类精度。
附图说明
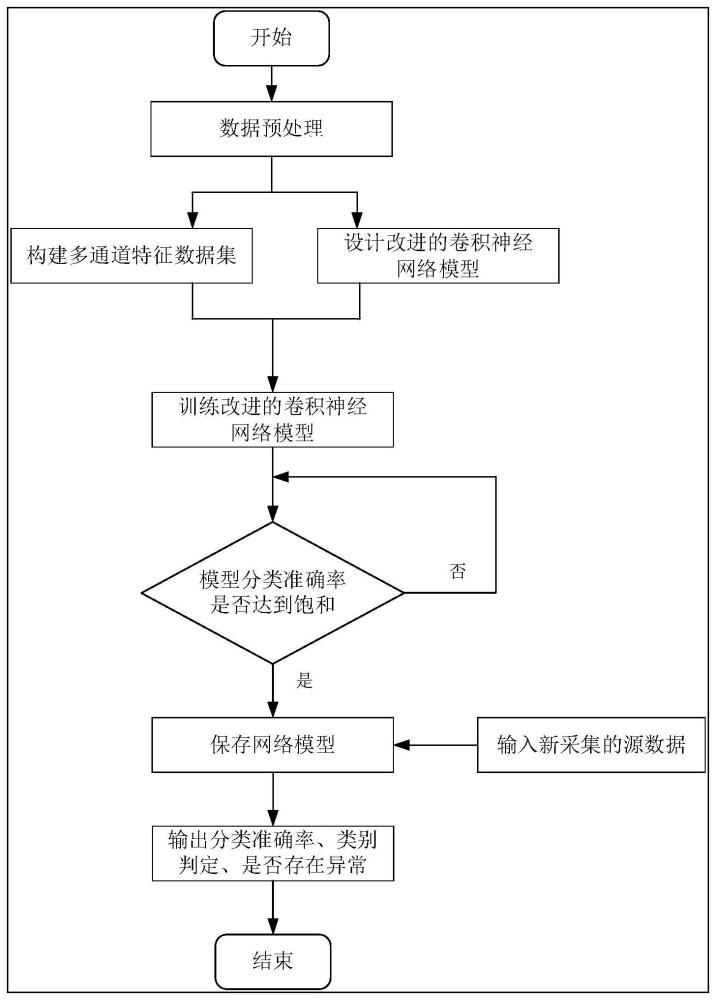
图1为本发明实施例中一种基于特征融合和改进卷积神经网络模型的轧制声音分类方法整体设计流程图;
图2为本发明实施例中数据预处理和多通道特征数据集构建设计框图;
图3为本发明实施例中改进VGG卷积神经网络模型的网络结构图;
图4为本发明实施例中改进VGG卷积神经网络分类层的结构图;
图5为本发明实施例多通道特征图可视化效果图。
具体实施方式
为更进一步阐述本发明为实现预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明的具体实施方式、结构、特征及其功效,详细说明如后。
在视觉领域发展的基础上,根据音频特点提取相应的特征,生成图片特征作为网络的输入,有不少研究数据证明已经取得较好的成果,但针对钢厂轧制现场的应用,其模型应用效果无法统一,难以在实际工作中得到应用,并且研究相对较少。
本发明提供的基于特征融合和改进卷积神经网络模型的轧制声音分类方法实施例,在特征和模型两方面同步改进,进而提高轧制环境声音分类准确率。本实施例基于Tensorflow框架和Pycharm开发环境:Tensorflow对Python有很好的语言支持,支持CPU和GPU等硬件,并且支持多种模型和算法。目前,Tensorflow被广泛的应用于文本处理、语音识别和图像识别等多项机器学习和深度学习的领域。
本实施例提供一种基于特征融合和改进卷积神经网络模型的轧制声音分类方法,如图1-图2所示,所述轧制声音分类方法包括下列步骤:
(1)数据预处理:采集轧制现场声音数据并进行数据清理、迭代标记、数据格式统一化及数据增样操作;
(2)构建多通道特征数据集:对步骤(1)中预处理后的音频数据提取若干种音频特征图,进行特征通道融合,生成多通道特征图;并采用深度学习数据增强方法对所述多通道特征图进行数据量扩充,构建获得多通道特征数据集;
(3)改进及训练卷积神经网络模型:构建获得改进的VGG卷积神经网络分类模型,将步骤(2)中获得的所述多通道特征数据集输入到所述改进的VGG卷积神经网络分类模型中,迭代训练,进而得到分类网络模型;
(4)输出分类结果:向步骤(3)中获得的所述分类网络模型中输入新采集的源数据,输出模型分类准确率和类别判定结果。
本发明提供的轧制声音分类方法采用特征融合和数据增强技术构建多通道特征数据集,并通过迭代训练改进的卷积神经网络模型对模型参数不断进行更新,得到最终分类网络;本发明在特征和模型两方面同步改进,进而提高轧制环境声音分类准确率。
在本实施例中,步骤(1)中,所述数据清理包括:清除音频数据中无声音频数据,以及清除音频数据中音频文件大小为0字节的空文件;
所述数据格式统一化包括:裁剪音频数据,使音频数据时间长度统一(具体地,可以同一裁剪为5s或其他时长),并以统一格式(具体地,本实施例中采用.wav格式)保存。
在本实施例步骤(1)中,所述迭代标记包括:根据轧制现场声音采集点位来迭代标记数据类别;
迭代标记的数据类别包括:钢板剪切声音、钢板掉落声音、钢板输出声音、现场水雾声声音、板坯传动声音、咬钢声。优选地,每类数据包括200条数据;
在本实施例步骤(1)中,所述数据增样包括:随机选择同一轧制现场声音采集点位的音频A和音频B两条音频,截取音频A中的片段随机替换音频B相同时长的片段,生成新的音频数据C,完成数据增样。
具体地,数据增样过程如下:在同一类别文件夹(在同一轧制现场声音采集点位采集)中,随机选择两条音频A和B,截取数据A中的2s片段随机替换数据B中2s时长的片段,生成新的音频数据C;每类数据迭代100次,数据增样后,每类别包含300条数据。
在本实施例步骤(2)具体为:
对步骤(1)中预处理后音频数据进行音频特征提取,并进行数据标准化处理;其中,使用以下方法处理音频信号以提取特征:梅尔频率倒谱系数(MFCC)、色谱图、宽带语谱图和窄带语谱图;
将提取的特征堆叠在一起进行特征通道融合,每个特征均为224维,生成多通道特征图(本实施例中为四通道输入),作为卷积神经网络的输入,多通道特征图输入尺寸统一为224*224*n(n为通道数,本实施例中n=4),以此为网络创建一个n通道输入特征图;
利用深度学习数据增强方法对生成的所述多通道特征图进行数据量扩充,构建获得多通道特征数据集;并基于整个数据集数据的大小,将所述多通道特征数据集按比例随机分为训练集和测试集。
在本实施例中,在提取获得MFCC的过程中,选用矩形窗函数对每一帧信号进行加窗处理,以避免频谱泄露;
在提取获得色度频率的过程中,相邻窗之间的距离设为512;
在提取获得宽带语谱图的过程中,通过设置48000Hz的语音采样率,FFT长度设为1024,并取20-40个数据点的窗长以及10-80个数据点帧移,选用汉明窗函数;
在提取获得窄带语谱图的过程中,设置语音采样率为48000Hz,取窗长为200-400个数据点,帧移为100-160个数据点,选用汉明窗函数。
图5显示了从音频信号中提取的多通道特征的图形表示,在同一时间点,每个特征值对音频信号的表达不同,以突出类别的特征,简化特征复杂性,降低类之间的相似性。例如,宽带语谱图中的竖线对应振幅的快速变化,窄带语谱图中的水平线代表谐波。
在本实施例中,步骤(2)中,所述深度学习数据增强方法包括亮度增强、网格掩码和注入噪声;通过将亮度增强和所述网格掩码作为主方法,对每张多通道特征图进行亮度增强和网格掩码操作,然后注入随机噪声;扩充后数据集总计3600张特征图。具体地,在本实施例中,多通道特征数据集按7:3比例随机分为训练集和测试集。
在本实施例中,构建改进的卷积神经网络模型,包括:以VGG-16卷积神经网络作为基础结构,对卷积池化层和分类层进行改进;
对卷积池化层的改进包括:对于源VGG-16卷积神经网络结构中的三层512个卷积核的池化层,采用随机池化代替最大池化,以减少计算量同时提高网络的泛化能力;
对分类层的改进包括:将源VGG-16卷积神经网络结构中的三层全连接层替换为全局平均池化层和注意力机制模块,以减少网络参数、优化网络以及提升网络的分类精度。
构建改进的卷积神经网络模型的方法具体包括:
S31:如图3所示,以VGG-16网络作为基础结构;在改进的VGG-16卷积神经网络网络中,将所述多通道特征图经过3*3卷积核计算后,通过ReLU激活函数进入池化层;
输入的所述多通道特征图经过两次64个卷积核的卷积后通过最大池化层连接两次128个卷积核卷积;两次128个卷积核的卷积通过最大池化层连接两次256个卷积核的卷积;剩下两次三个512个卷积核的卷积通过随机池化层进行连接;
S32:构建改进的分类层模块,如图4所示,改进的核心部分是将三层全连接层替换成全局平均池化层和注意力机制模块,把注意力函数的输出结果输入到Softmax中进行运算,得到对应的注意力权重;将注意力权重的加权和作为注意力汇聚的输出;获得改进的VGG-16卷积网络模型。
在本实施例中,将步骤(2)中获得的所述多通道特征训练和测试数据集输入到所述改进的VGG卷积神经网络分类模型中,迭代训练,得到分类网络模型的方法具体包括:
步骤(2)中获得的所述多通道特征训练和测试数据集输入到改进的VGG-16卷积网络模型中迭代训练,直到模型训练/测试分类准确率达到饱和状态,即模型准确率达到最大值,不再提升,得到最优的模型参数,保存此时的分类网络,得到所述分类网络模型。
具体地,如图1所示,步骤(4)中,轧制声音分类方法输出分类结果包括:将新采集的轧制现场声音数据不进行任何数据处理步骤,输入保存的声音分类网络中,输出模型分类准确率,并根据准确率判断声音所属类别。
基于上述的轧制声音分类方法,由于声音数据均来源于轧制现场,因此该方法的适用范围仅为轧制现场。根据实际运用领域的需要,采用不同领域的声学数据,该特征和网络设计方法可推广到任何场景问题上。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭示如上,然而并非用以限定本发明,任何本领域技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容做出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简介修改、等同变化与修饰,均仍属于本发明技术方案的范围内。