一种转换未知说话人语音的方法和系统
文献发布时间:2024-01-17 01:18:42
技术领域
本发明涉及语音合成技术领域,具体涉及一种转换未知说话人语音的方法和系统。
背景技术
在现有的语音转换方法中,大量的语音转换方式采用解耦合的方法提取说话人特征和文本特征,但是最终合成的语音并不能拥有很好的自然度和相似度;因此,使用基于语音特征提取模型和语音合成模型的语音转换方法可以更加有效的生成转换的语音;语音特征提取模型通过输入的语音提取文本特征,在链接上经过语音合成模型训练的目标说话人声音,重构出目标梅尔频谱(声学特征),将目标梅尔频谱送入语音合成的声码器模型,获取目标语音。
但上述基于语音特征提取模型和语音合成模型的语音转换方法想要获取新的说话人转换声音时,存在需要获取大量的数据进行训练的缺陷。
发明内容
针对上述问题,本发明的一个目的是提供一种转换未知说话人语音的方法,该方法采用少量未知说话人语音数据,通过微小变化语音合成模型参数转换出未知说话人声音;该方法以说话人高维特征作为条件去调控在自适应后验编码器、自适应编码器和自适应流解码器内部的文本特征,从而达到更快,更好的适应说话人音色的技术效果。
本发明的第二个目的是提供一种转换未知说话人语音的系统。
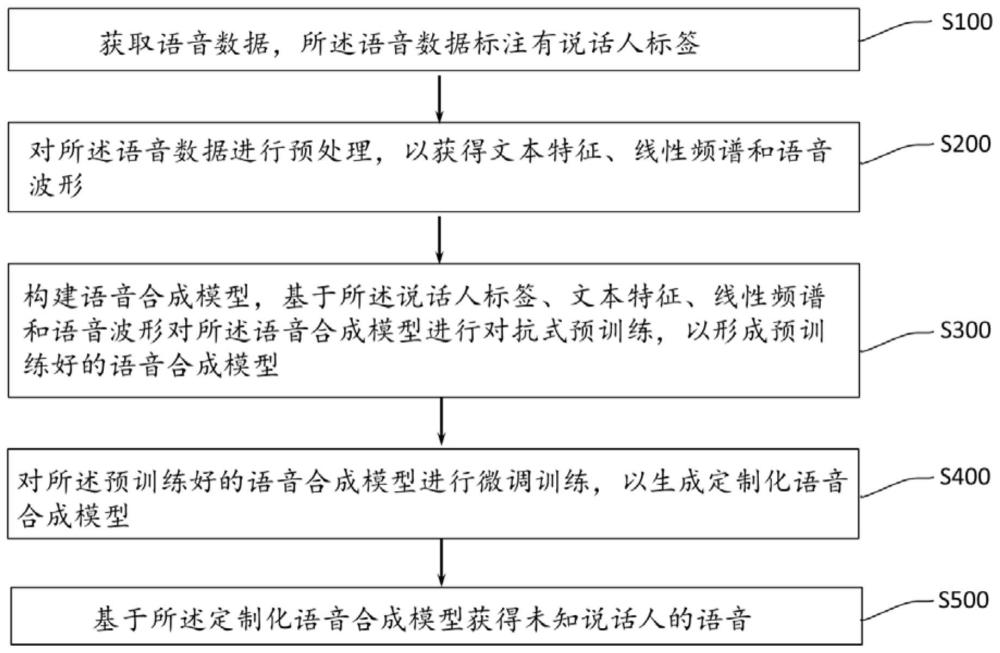
本发明所采用的第一个技术方案是:一种转换未知说话人语音的方法,包括以下步骤:
S100:获取语音数据,所述语音数据标注有说话人标签;
S200:对所述语音数据进行预处理,以获得文本特征、线性频谱和语音波形;
S300:构建语音合成模型,基于所述说话人标签、文本特征、线性频谱和语音波形对所述语音合成模型进行对抗式预训练,以形成预训练好的语音合成模型;
S400:对所述预训练好的语音合成模型进行微调训练,以生成定制化语音合成模型;
S500:基于所述定制化语音合成模型获得未知说话人的语音。
优选地,所述步骤S200包括以下子步骤:
S210:采用文本特征提取器提取每条语音数据的文本特征;
S220:对每条语音数据进行预加重、分帧、加窗、短时傅立叶变换处理,从而获取线性频谱;
S230:每条语音数据用离散点的形式存储,即形成语音波形。
优选地,所述步骤S300中的语音合成模型包括声学模型、声码器和说话人特征表,所述声学模型包括自适应编码器、自适应流解码器、自适应后验编码器、波形生成器和鉴别器。
优选地,所述自适应编码器由4个AFT模块堆叠而成,所述AFT模块依次包括1个自适应注意力模块、1个卷积网络、1个残差连接和1个CLN层。
优选地,所述自适应流解码器和所述自适应后验编码器都是由AFlow模块构成的,所述AFlow模块包括自适应仿射耦合层;所述自适应仿射耦合层是通过在仿射耦合层预测参数的网络中加入了CLN层得到的。
优选地,所述波形生成器和所述鉴别器采用了HiFi-GAN声码器的架构;所述鉴别器包括多周期鉴别器和多尺度鉴别器。
优选地,所述步骤S300中的对抗式预训练包括以下子步骤:
S310:基于所述说话人标签查询说话人特征表,从而生成说话人特征;
S320:将所述文本特征和说话人特征输入自适应编码器,以生成先验的均值和方差;
S330:将所述线性频谱和说话人特征输入自适应后验编码器,以生成后验的均值和方差;生成高斯噪声,基于所述后验的均值、方差以及高斯噪声,获得后验特征;
S340:将所述后验特征输入自适应流解码器,经过编码获得后验流特征;
S350:将所述后验特征输入波形生成器,以生成预测语音波形;将所述预测语音波形和所述语音波形输入鉴别器,以获得鉴别结果;
S360:将所述鉴别结果、后验流特征、先验的均值和方差进行损失计算,并更新语音合成模型参数,从而实现语音合成模型的抗式预训练。
优选地,所述步骤S400包括:
获取未知说话人语音,冻结预训练好的语音合成模型中除CLN层权重和说话人特征表以外的所有权重,对未知说话人的说话人特征进行随机初始化,重复上述预训练步骤,对预训练好的语音合成模型进行微调训练,从而形成定制化语音合成模型。
优选地,所述步骤S500包括:
输入待转换语音和相应的说话人标签,待转换语音通过文本特征提取器提取文本特征;相应的说话人标签通过说话人特征表被映射为说话人特征;
将所述文本特征和说话人特征输入定制化语音合成模型中的自适应编码器,以生成先验的均值和方差;生成高斯噪声,将先验的均值和方差、高斯噪声输入定制化语音合成模型中的自适应流解码器,经过编码后再输入至定制化语音合成模型中的波形生成器,从而生成语音波形,即转换为未知说话人的语音。
本发明所采用的第二个技术方案是:一种转换未知说话人语音的系统,包括数据获取模块、预处理模块、预训练模块、微调训练模块和语音转换模块:
所述数据获取模块用于获取语音数据,所述语音数据标注有说话人标签;
所述预处理模块用于对所述语音数据进行预处理,以获得文本特征、线性频谱和语音波形;
所述预训练模块用于构建语音合成模型,基于所述文本特征、线性频谱和语音波形对所述语音合成模型进行对抗式预训练,以形成预训练好的语音合成模型;
所述微调训练模块用于对所述预训练好的语音合成模型进行微调训练,以生成定制化语音合成模型;
所述语音转换模块用于基于所述定制化语音合成模型获得未知说话人的语音。
上述技术方案的有益效果:
(1)本发明公开的一种转换未知说话人语音的方法采用少量未知说话人语音数据,通过微小变化语音合成模型参数转换出未知说话人声音;该方法以说话人高维特征作为条件去调控在自适应后验编码器、自适应编码器和自适应流解码器内部的文本特征,从而达到更快,更好的适应说话人音色的技术效果。
附图说明
图1为本发明的一个实施例提供的一种转换未知说话人语音的方法的流程示意图;
图2为本发明的一个实施例提供的一种转换未知说话人语音的方法的流程框图;
图3为本发明一个实施例提供的语音合成模型的架构图;
图4为本发明一个实施例提供的AFT的结构示意图;
图5为本发明一个实施例提供的AFlow模块的结构示意图;
图6为本发明一个实施例提供的自适应仿射耦合层的结构示意图;
图7为本发明一个实施例提供的基于定制化语音合成模型获得未知说话人的语音的流程示意图;
图8为本发明的一个实施例提供的一种转换未知说话人语音的系统的结构示意图。
具体实施方式
下面结合附图和实施例对本发明的实施方式作进一步详细描述。以下实施例的详细描述和附图用于示例性地说明本发明的原理,但不能用来限制本发明的范围,即本发明不限于所描述的优选实施例,本发明的范围由权利要求书限定。
在本发明的描述中,需要说明的是,除非另有说明,“多个”的含义是两个或两个以上;术语“第一”“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性;对于本领域的普通技术人员而言,可视具体情况理解上述术语在本发明中的具体含义。
实施例一
如图1和图2所示,本发明的一个实施例提供了一种转换未知说话人语音的方法,包括以下步骤:
S100:获取语音数据,所述语音数据标注有说话人标签;
录制若干个说话人的语音数据,每个说话人录制足够多的语音数据(例如300-400句话,每句话时长大约5~6秒),作为训练数据集;每句话作为一条语音数据,同时标注有说话人标签,例如是说话人编号或索引;说话人的数量可以根据需要确定,例如设定为22个说话人。
S200:对所述语音数据进行预处理,以获得文本特征、线性频谱和语音波形;
S210:采用文本特征提取器提取每条语音数据的文本特征;
对于训练数据集中的每条语音数据,利用文本特征提取器提取每条语音数据的文本特征,该文本特征提取器可以是任何合适的无监督或有监督的语音表征学习模型,例如HuBERT、Wav2vec等。
S220:对每条语音数据进行预加重、分帧、加窗、短时傅立叶变换处理,从而获取线性频谱;
将每条语音数据经过预加重、分帧、加窗、短时傅立叶变换的处理后获取线性频谱,语音数据处理的相关参数例如表1所示,但并不限于此,也可以根据实际情况做适当调整。
表1音频参数
S230:基于每条语音数据以及获得的文本特征、线性频谱生成文本特征-线性频谱-语音波形的数据对。
每条语音数据在计算机中是用离散点的形式存储,即语音波形就是语音数据。
S300:构建语音合成模型(即语音合成模块),基于说话人标签、文本特征、线性频谱和语音波形对所述语音合成模型进行对抗式预训练,以形成预训练好的语音合成模型;
(1)构建语音合成模型;
如图3所示,语音合成模型包括声学模型和声码器,声学模型包括自适应编码器(AFT*4)、自适应流解码器(AFlow*4)、自适应后验编码器(AFlow*1)、波形生成器(HiFi-GANgenerator)和鉴别器(HiFi-GAN discriminator);
语音合成模型还包括说话人特征表,说话人特征表包括256个隐藏单元。
如图4所示,自适应编码器由4个adaptive forward transform(AFT)模块堆叠而成,AFT结构依次包括1个内部都为256隐藏单元的自适应注意力(adaptive-self-attention,ASA)模块、1个2层的1维卷积网络、1个残差连接和1个256隐藏单元的CLN层;其中,隐藏单元都为1024,核大小分别为3和9,步长都为1;ReLU激活函数是用在ASA模块内部和2层的卷积网络内部。
自适应流解码器和自适应后验编码器都是使用Adaptive Flow(AFlow)模块构成的,自适应流解码器使用了4个AFlow模块堆叠,而自适应后验编码器使用1个AFlow模块构成;如图5所示,AFlow模块包括自适应仿射耦合层(Adaptive affline coupling layer);仿射耦合层(Affline coupling layer)是传统的流模块,自适应仿射耦合层是在其预测参数的网络中加入了CLN层,其具体结构如图6所示,input输入为1个行数为hidden_num,列数为length的矩阵,Input_a和input_b就是从维度层面把这个矩阵分为了两个部分;Input_a采用了该矩阵的上半部分(即hidden_num/2通道数),input_b采用了另外一部分;concat为拼接函数,即拼接回形状【hidden_num,length】;例如hidden_num表示特征数比如=128,length表示输入序列的长度比如=27,即input为1个128*27的矩阵。
波形生成器和鉴别器采取了HiFi-GAN声码器的架构,相比较于HiFi-GAN采用mel频谱作为输入,本发明采用隐变量Z作为输入特征,该隐变量Z在训练阶段由自适应后验编码器生成,而在测试及实际运行阶段,其由自适应流解码器得出;
鉴别器(HiFi-GAN discriminator)包括多周期鉴别器Multi-PeriodDiscriminator(MPD)和多尺度鉴别器Multi-Scale Discriminator(MSD);其中多周期鉴别器根据周期[2,3,5,7,11]可以有5个不同的鉴别器,因此鉴别器一共有6个鉴别器;其中包括5个不同周期的鉴别器以及1个多尺度鉴别器;鉴别器将预测语音波形和语音波形并行的送入这6个鉴别器,并获得对应的结果,然后进行损失计算;本发明通过输入预测语音波形和语音波形,通过鉴别器来判断该对象是否为真,或为假。
MSD多尺度鉴别器拥有6层1维卷积和leakyRelu()激活函数,其参数如下所示:
Conv1d(channels=16,kernal_size=15,stride=1)
leakyRelu()
Conv1d(channels=64,kernal_size=41,stride=4)
leakyRelu()
Conv1d(channels=256,kernal_size=41,stride=4)
leakyRelu()
Conv1d(channels=1024,kernal_size=41,stride=4)
leakyRelu()
Conv1d(channels=1024,kernal_size=41,stride=4)
leakyRelu()
Conv1d(channels=1024,kernal_size=5,stride=1)
leakyRelu()
每经过一层Conv1d,便经过1次leakyRelu()激活函数。
MPD多周期鉴别器的模型结构是完全一致的,但是其输入从1维的波形序列变换为2维的矩阵,变换方法可以是将1维波形变为分别以[2,3,5,7,11]个点为一组的矩阵;
MPD的结构则不再是1维卷积,而是2维卷积,一共有5层2维卷积和对应的leaky_Relu()激活函数,其参数如下所示:
Conv2d(channel=32,kernal_size=(5,1),stride=(3,1))
leakyRelu()
Conv2d(channel=128,kernal_size=(5,1),stride=(3,1))
leakyRelu()
Conv2d(channel=512,kernal_size=(5,1),stride=(3,1))
leakyRelu()
Conv2d(channel=1024,kernal_size=(5,1),stride=(3,1))
leakyRelu()
Conv2d(channel=1024,kernal_size=(5,1),stride=(3,1))
leakyRelu()。
(2)基于说话人标签、文本特征、线性频谱和语音波形对所述语音合成模型进行对抗式预训练,包括:
S310:基于说话人标签查询说话人特征表,从而生成说话人特征S;
S320:将文本特征和说话人特征输入自适应编码器,以生成先验的均值和方差;
S330:将线性频谱和说话人特征输入自适应后验编码器,以生成后验的均值和方差;生成高斯噪声,基于后验的均值、方差以及高斯噪声,获得后验特征;所述高斯噪声是通过相关函数生成的,相关函数例如为0均值1方差的torch.randn函数;
S340:将后验特征输入自适应流解码器,经过编码获得后验流特征;
S350:将后验特征输入波形生成器,以生成预测语音波形;将预测语音波形和语音波形输入鉴别器,以获得鉴别结果;
S360:将鉴别结果、后验流特征、先验的均值和方差进行损失计算,并基于损失更新语音合成模型参数,从而实现语音合成模型的抗式预训练。
预训练阶段本发明采用batch_size=32,使用AdamW优化器,参数为betas:[0.8,0.99],eps=1e-9(10的-9次方);对于波形生成器G和鉴别器D,本发明使用两个优化器,并进行对抗式(GAN)训练步骤;上述步骤6)中所用到的数据,有一部分给鉴别器D的损失函数Loss(D)用,一部分给波形生成器G的损失函数Loss(G)用,即通过语音合成模块里鉴别器D的损失函数Loss(D)先优化一次鉴别器,再通过波形生成器G的损失函数Loss(G)优化一次生成器G,每一个step都由这两个small step完成;初试学习率为lr=2e-4,迭代训练300epochs;其中,由于模型训练的时候梯度回传的特性,虽然Loss(G)是给波形生成器用的,但是更新参数的时候会更新所有在它下面模块(即语音合成模型里除了所有鉴别器以外的模块)的参数,Loss(D)通过技术手段只更新鉴别器本身。
S400:对预训练好的语音合成模型进行微调训练,以生成定制化语音合成模型;
获取10-20条未知说话人语音,冻结预训练好的语音合成模型中除CLN层权重和说话人特征表以外的所有权重,对未知说话人的说话人特征进行随机初始化,重复上述预训练步骤,对预训练好的语音合成模型进行微调(soft-HuBERT保持不动);经过2000step的微调,形成定制化语音合成模型。
进一步的,在一个实施例中,对定制化语音合成模型进行测试;
选取10-20个本地说话人,进行测试;从语音质量(MOS)以及语音说话人相似度(SMOS)两方面来主观评价;选用国际标准的5分打分制,从0到5依次是:
非常差:情感与目标情感完全不贴切,情感表现力极差;
很差:情感与目标情感基本贴切,情感表现力极差;
中等:情感与目标情感较贴切,情感表现力较好;
良好:情感与目标情感较贴切,情感表现力充分;
优秀:情感与目标情感贴切,情感表现力突出;每0.5分为1个间隔。
测试结果如表2所示;
表2定制化语音合成模型的测试数据
S500:基于定制化语音合成模型获得未知说话人的语音。
如图7所示,输入一条待转换语音和相应的说话人索引(即目标说话人标签),待转换语音通过文本特征提取器提取文本特征;相应的目标说话人索引通过说话人特征表被映射为说话人特征;
将文本特征和说话人特征输入定制化语音合成模型中的自适应编码器,以生成先验的均值和方差;生成高斯噪声,将先验的均值和方差、高斯噪声输入自适应流解码器,经过编码后再输入至波形生成器,从而生成语音波形,语音波形即为未知说话人的语音。
实施例二
如图8所示,本发明的一个实施例提供了一种转换未知说话人语音的系统,包括数据获取模块、预处理模块、预训练模块、微调训练模块和语音转换模块:
所述数据获取模块用于获取语音数据,所述语音数据标注有说话人标签;
所述预处理模块用于对所述语音数据进行预处理,以获得文本特征、线性频谱和语音波形;
所述预训练模块用于构建语音合成模型,基于所述文本特征、线性频谱和语音波形对所述语音合成模型进行对抗式预训练,以形成预训练好的语音合成模型;
所述微调训练模块用于对所述预训练好的语音合成模型进行微调训练,以生成定制化语音合成模型;
所述语音转换模块用于基于所述定制化语音合成模型获得未知说话人的语音。
在本申请所提供的实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。