一种基于单目相机的车载手势交互方法及系统
文献发布时间:2024-01-17 01:26:37
技术领域
本发明涉及车载人机交互和手势识别技术领域,具体涉及一种基于单目相机的车载手势交互方法及系统。
背景技术
人机交互是一种研究人与计算机之间的信息交换的技术,此技术涉及信息科学、智能科学等多个不同领域,引导着21世纪信息与计算机研究的热门方向。近年来,随着人工智能及其相关领域的发展,人机交互方式也正朝着更自然、更普遍的方向发展,迫切需要使用自然的动作而不是传统专用的输入设备和控制系统与虚拟环境中的数字内容进行交互,人机交互方式正在从过去的以计算机为中心向以用户为中心变革。而人手作为人体最灵活的器官在人机交互领域扮演着极为重要的角色。
虽然基于手势的人机交互技术有着重要的研究与应用价值,但是作为一项新型的技术领域,还存在许多有待解决的问题,例如手部位置的准确识别与分割、手指在自遮挡情况下的准确识别等。目前,手势交互领域常用的解决方案有:借助可穿戴设备获取手的姿势及空间位置信息、通过深度相机或双目相机获取手的深度信息进行手势交互、采用手势识别模型对某些特定手势进行识别。
但是上述解决方案仍旧存在一些问题,如采用可穿戴设备方案的发明专利申请公开文献《基于可穿戴设备的数据交互方法、装置、设备及介质》(CN 115840506 A)采用可穿戴设备对设定空间范围内的终端设备以及手掌进行检测与识别,并在可穿戴设备中生成用户手掌对应的虚拟手,在虚拟手的目标手势与预设交互手势匹配的情况下,进行可穿戴设备与终端设备之间的数据交互。这种方法需要用户佩戴特定的设备才能进行手势交互,使得在日常使用以及应用场景上存在很大的局限性,繁琐的穿戴过程也为手势交互带来了诸多不便,并没有体现出手势交互的便捷性;此外可穿戴设备造价高昂,难以进行大范围普及。
采用双目相机方案的发明专利申请公开文献《一种基于Leapmotion传感器的车载手势识别系统》(CN 115620397 A)利用双目摄像头采集用户的手势图像,生成对应的三维手势模型并获取采集对象的手势数据信息,之后将提取的手势信息与手势训练库进行匹配输出匹配后的控制信号来进行手势交互。此方案使用双目相机获取手势的三维信息,这一过程需要较高的算力资源;另外目前主流的深度相机识别范围为0.5-5m,存在较大的识别盲区;并且Leapmotion深度相机成本较高,不适合大面积应用。
采用手势识别模型方案的发明专利申请公开文献如:《一种座舱内手势交互方法及装置》(CN 115424356 A)将座舱内的实时图像输入手势识别模型,获得手势识别模型输出的第一手势类别检测结果和第一位置类别检测结果,依据第一座舱位置上第一手势对应的控制指令控制座舱内的设备。此方案使用手势识别模型获取手势类别及其对应的控制指令,简单地将手势与控制指令进行匹配,但并未获取手势的三维空间信息,手势交互的功能过多依赖手势识别模型中的数据库,这使得手势交互的拓展性受到很大的限制,适应性不足,存在新增手势时需要较大的改造成本。
如今在深度学习算法的加持下,通过单个摄像头也可实现手势追踪与三维姿态估计,摆脱了可穿戴设备和高昂的深度相机设备的限制,手势交互不仅仅局限于某一特定场景或单一功能,车载设备手势控制、车机手势交互、手语识别等功能都能在一台设备上实现,另外不仅在2D空间,在手势姿态估计的加持下,在车上进行3D AR游戏与交互等都将成为可能。
发明内容
本发明要解决的技术问题为针对车载环境下现有技术中存在的手势交互应用场景有限、交互系统拓展性不足、图像采集设备造价高昂等问题,提供一种采用普通单目相机实现手势估计与手势交互的方法及装置,该方法实现了更加准确高效的手势交互,降低了手势交互设备成本;另外渲染不同的的手势图像增加了手势交互的拓展性,降低手势交互功能的更新成本。
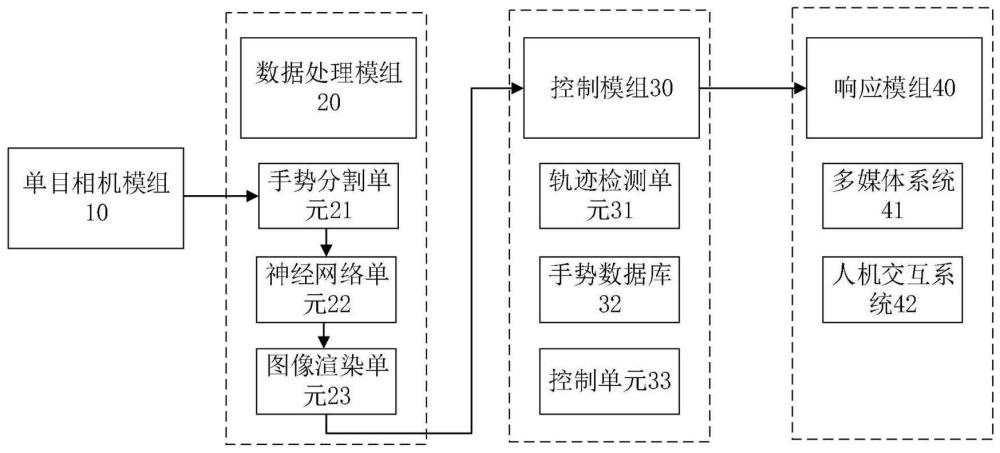
本发明的目的是这样实现的。本发明提供了一种基于单目相机的车载手势交互系统,包括单目相机模组、数据处理模组、控制模组和响应模组;
所述数据处理模组包括依次单向连接的手势分割单元、神经网络单元和图像渲染单元;所述手势分割单元包括差帧提取器、肤色检测器和手势分割及背景归一化算法模块,其中,差帧提取器和肤色检测器分别与手势分割及背景归一化算法模块单向连接;所述神经网络单元包括依次单向连接的特征提取网络、2D检测器和3D检测器,此外,特征提取网络与3D检测器单向连接;所述图像渲染单元包括依次单向连接的模型拟合器和图像渲染器,其中,模型拟合器中预存有参数化手模型,所述3D检测器中预存有卷积神经网络;
所述控制模组包括轨迹检测单元、手势数据库和控制单元,所述轨迹检测单元和手势数据库分别和控制单元单向连接,所述轨迹检测单元预存有帧间差分法和手势三维空间运动轨迹检测算法,所述手势数据库预存有与多种应用场景对应的多种手势数据集;
所述单目相机模组用于采集图像,单目相机模组分别与差帧提取器、肤色检测器单向连接;
所述图像渲染器分别与轨迹检测单元、手势数据库单向连接,所述控制单元与响应模组单向连接。
优选地,所述单目相机模组为1920×1080分辨率的广角RGB相机,安装于车辆中控车机屏幕靠近主驾驶位置。
优选地,所述响应模组包括多媒体系统和人机交互系统。
优选地,所述手势数据库里的数据为预先存储的手势图像,且包括以下三种:预存手势深度图、预存手势二维图和预存手势三维重建模型,所述手势数据集根据其应用场景分别预存有以上三种中的任意一种手势图像或者任意二种以上的手势图像。
本发明还提供了一种基于单目相机的车载手势交互方法,该交互方法应用于车辆的手势交互与控制,包括以下步骤:
步骤1,单目相机模组采集RGB图像,并将其分别传输给手势分割单元中的差帧提取器和肤色检测器;
步骤2,所述差帧提取器提取RGB图像中发生运动的区域,并传输给手势分割及背景归一化算法模块,所述肤色检测器同步提取RGB图像中的肤色区域,并传输给手势分割及背景归一化算法模块;
所述手势分割及背景归一化算法模块根据预定程序首先将发生运动的区域和肤色区域合成为手势区域,然后对该手势区域进行分割得到手势分割图,再对手势分割图背景进行归一化处理,得到背景归一化的手势分割图,并将背景归一化的手势分割图传送给神经网络单元中的特征提取网络;
步骤3,特征提取网络首先对背景归一化的手势分割图进行手部特征提取,并将提取的结果记为特征图;其次将特征图送入2D检测器得到手部的关键点热图;然后再将关键点热图和特征图一同送入3D检测器,通过预存的卷积神经网络回归出手部的3D关键点位置图,并将该3D关键点位置图传输给图像渲染单元的模型拟合器;所述3D关键点位置图包含手部21个关键点的三维空间位置信息;
步骤4,模型拟合器将预存的参数化手模型与步骤3得到的3D关键点位置图进行拟合,得到手势三维重建模型,图像渲染器在手势三维重建模型的基础上渲染出相机视角的手势深度图和手势二维图,然后将其中的手势深度图传送给控制模组中的轨迹监测单元,将手势深度图、手势二维图、手势三维重建模型一同传输给控制模组中的手势数据库;
步骤5,轨迹监测单元在步骤4得到的多张连续手势深度图上使用预存的帧间差分法获取手部根关键点的三维空间位移信息,得到手势三维空间运动轨迹;手势数据库将步骤4得到的手势深度图、手势二维图和手势三维重建模型与其对应的手势数据集中的图像进行匹配,得到手势特征所代表的标签信息;
所述控制单元结合手势特征所代表的标签信息和手势三维空间运动轨迹,生成控制指令并传输给响应模;
步骤6,响应模组对控制指令进行响应,实现人机交互。
与现有技术比较,本发明的有益效果包括:
1、采用多模式的手势分割算法对图像中的手掌部分进行裁剪分割,并将手掌背景归一化,避免杂乱背景对手势估计的影响,提高手部关键点估计的准确度。
2.利用神经网络从单目相机中准确获得手部关键点的三维空间位置信息,不依赖精密且价格高昂的深度相机和可穿戴设备,降低了手势交互设备成本。
3.利用参数化手模型重建出手势三维重建模型能够有效避免在以往的手势识别算法中因为手部的自遮挡或深度图像缺失等带来的识别失败问题,在手势三维重建模型中渲染出的手势深度图和手势二维图相比传统方法拥有更高的质量,且避免了手势背景图像带来的影响,提高手势识别的精准度。
4.相比于传统的手势识别和手势交互方法的特定手势只能代表一种指定含义,估计的手部关键点的三维空间位置信息拥有更高的手势信息维度,不同的手势也能在手势交互过程中包含更多的信息,例如在手势识别中难以分辨的手指弯曲不同角度以及手掌平移不同距离的情形。
5.通过将三种手势图像信息与对应的手势数据库进行匹配,实现不同的人机交互功能,如手语翻译、AR游戏、车载设备控制等。在有新增手势时仅需要添加对应的手势数据集,具有较大的升级成本优势。
附图说明
图1为本发明交互系统的整体结构框图;
图2为本发明实施例中数据处理模组结构框图;
图3为本发明实施例中控制模组结构框图。
具体实施方式
以下结合实施例及附图,对本发明作进一步详细的描述。
图1为本发明交互系统的整体结构框图,图2为本发明实施例中数据处理模组结构框图,图3为本发明实施例中控制模组结构框图。由图1-图3可见,本发明提供了一种基于单目相机的车载手势交互系统,包括单目相机模组10、数据处理模组20、控制模组30和响应模组40。
所述数据处理模组20包括依次单向连接的手势分割单元21、神经网络单元22和图像渲染单元23;所述手势分割单元21包括差帧提取器211、肤色检测器212和手势分割及背景归一化算法模块213,其中,差帧提取器211和肤色检测器212分别与手势分割及背景归一化算法模块213单向连接;所述神经网络单元22包括依次单向连接的特征提取网络221、2D检测器222和3D检测器223,此外,特征提取网络221与3D检测器223单向连接;所述图像渲染单元23包括依次单向连接的模型拟合器231和图像渲染器232,其中,模型拟合器231中预存有参数化手模型,所述3D检测器223中预存有卷积神经网络。
所述控制模组30包括轨迹检测单元31、手势数据库32和控制单元33,所述轨迹检测单元31和手势数据库32分别和控制单元33单向连接,所述轨迹检测单元31预存有帧间差分法和手势三维空间运动轨迹检测算法,所述手势数据库32预存有与多种应用场景对应的多种手势数据集。
所述单目相机模组10用于采集图像,单目相机模组10分别与差帧提取器211、肤色检测器212单向连接。
所述图像渲染器232分别与轨迹检测单元31、手势数据库32单向连接,所述控制单元33与响应模组40单向连接。
在本实施例中,所述单目相机模组10为1920×1080分辨率的广角RGB相机,安装于车辆中控车机屏幕靠近主驾驶位置。
在本实施例中,所述响应模组40包括包括多媒体系统41和人机交互系统42。
在本实施例中,所述手势数据库32里的数据为预先存储的手势图像,且包括以下三种:预存手势深度图、预存手势二维图和预存手势三维重建模型,所述手势数据集根据其应用场景分别预存有以上三种中的任意一种手势图像或者任意二种以上的手势图像。
在本实施例中,所述手势交互的应用场景包括:手语翻译、车载多媒体系统控制、虚拟现实交互和车载设备控制,所述车载设备控制包括车窗玻璃控制、车载空调控制、座椅调节等。例如车载多媒体系统控制场景对应的手势数据集中包含预存手势深度图和预存手势二维图,而虚拟现实交互场景对应的手势数据集仅包含预存手势三维重建模型。
本发明还提供了一种基于单目相机的车载手势交互方法,包括以下步骤:
步骤1,单目相机模组10采集RGB图像,并将其分别传输给手势分割单元21中的差帧提取器211和肤色检测器212;
步骤2,所述差帧提取器211提取RGB图像中发生运动的区域,并传输给手势分割及背景归一化算法模块213,所述肤色检测器212同步提取RGB图像中的肤色区域,并传输给手势分割及背景归一化算法模块213;
所述手势分割及背景归一化算法模块213根据预定程序首先将发生运动的区域和肤色区域合成为手势区域,然后对该手势区域进行分割得到手势分割图,再对手势分割图背景进行归一化处理,得到背景归一化的手势分割图,并将背景归一化的手势分割图传送给神经网络单元22中的特征提取网络221;
步骤3,特征提取网络221首先对背景归一化的手势分割图进行手部特征提取,并将提取的结果记为特征图;其次将特征图送入2D检测器222得到手部的关键点热图;然后再将关键点热图和特征图一同送入3D检测器223,通过预存的卷积神经网络回归出手部的3D关键点位置图,并将该3D关键点位置图传输给图像渲染单元23的模型拟合器231;所述3D关键点位置图包含手部21个关键点的三维空间位置信息;
步骤4,模型拟合器231将预存的参数化手模型与步骤3得到的3D关键点位置图进行拟合,得到手势三维重建模型,图像渲染器232在手势三维重建模型的基础上渲染出相机视角的手势深度图和手势二维图,然后将其中的手势深度图传送给控制模组30中的轨迹监测单元31,将手势深度图、手势二维图、手势三维重建模型一同传输给控制模组30中的手势数据库32;
步骤5,轨迹监测单元31在步骤4得到的多张连续手势深度图上使用预存的帧间差分法获取手部根关键点的三维空间位移信息,得到手势三维空间运动轨迹;手势数据库32将步骤4得到的手势深度图、手势二维图和手势三维重建模型与其对应的手势数据集中的图像进行匹配,得到手势特征所代表的标签信息;
所述控制单元33结合手势特征所代表的标签信息和手势三维空间运动轨迹,生成控制指令并传输给响应模组40;
步骤6,响应模组40对控制指令进行响应,实现人机交互。
综上所述,本发明一种基于单目相机的车载手势交互方法及装置得以实现,在神经网络的加持下采用普通单目相机估计出手部的三维姿态,降低了手势交互装置的配置成本;多模式手势分割算法减少了外界的噪音干扰,提升手部关键点估计过程的鲁棒性;通过手势估计得到的手势三维重建模型可以解决手势遮挡问题,同时渲染出的手势深度图相比深度相机直接采集的深度图像,减小了背景的影响,避免深度缺失或深度图像空洞对手势识别带来的影响;通过将三种手势图像信息与不同的手势数据集进行匹配,实现相应的人机交互功能,拓宽手势交互的应用场景,并且在有新增手势时只需要添加对应的手势数据集,具有较大的升级成本优势,支持更加多样化的手势交互功能。