一种卷积神经网络训练硬件加速器
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于人工智能中边缘学习和计算领域,涉及卷积神经网络硬件友好的量化方案和加速器架构,尤其涉及一种卷积神经网络训练硬件加速器。
背景技术
近年来,卷积神经网络(Convolutional Neural Networks, CNN)技术在人工智能领域得到了广泛应用,如目标检测、目标识别、图像分类、指纹识别、语音唤醒等。这些技术的实现一般需要两步:第一,收集大量与任务相关的数据集发送到云端,建立CNN模型,在云端的图形处理单元(Graphics Processing Unit, GPU)上对CNN模型进行训练、迭代及优化,直至模型收敛;第二,将已收敛的CNN算法进行硬件电路实现,并嵌入到终端设备中。用户在使用终端设备时无需优化CNN算法,仅执行CNN的推理功能便可精准地实现检测或分类等任务。然而,伴随着任务复杂度提升、终端设备与云端的环境差异导致的模型精度渐低、以及用户隐私数据泄露等现象的频发,这种实现方式已不能满足用户的需求。一种可行的措施是让用户能够使用终端设备在设备现场完成CNN模型的再训练和优化工作,避免用户上传隐私数据或者上传对环境敏感的数据。不同于CNN推理计算,CNN训练期间涉及极其庞大的数据运算和内存访问,且对数据精度要求极高,以此来保证CNN算法能够收敛。例如,在GPU上训练CNN时,数据都以32位浮点数据存储并参与计算,以此来保证数据精度。但是,浮点数的乘除法计算需要消耗大量的硬件资源,而体积和能量都十分受限的终端设备很难支持这种大存储量、高复杂度的计算。因此,CNN模型量化训练算法一时成为了学术界和工业界研究的课题,将高位宽的浮点数量化为低位宽的定点数,旨在降低CNN训练的硬件成本,使其被部署在终端设备上成为可能。
现场可编程门阵列(Field Programmable Gate Array,FPGA)具备开发周期短,并行计算,功耗低等优点,现有的CNN加速器多基于FPGA实现,但多数仅支持CNN的推理计算。在少有的CNN训练加速器中,支持的CNN模型相对简单,参数量较小,且模型精度和收敛速度有待提升。
发明内容
本发明所要解决的技术问题是针对背景技术中提到的需求和不足,提供一种卷积神经网络训练硬件加速器。
本发明为解决上述技术问题采用了以下技术方案:
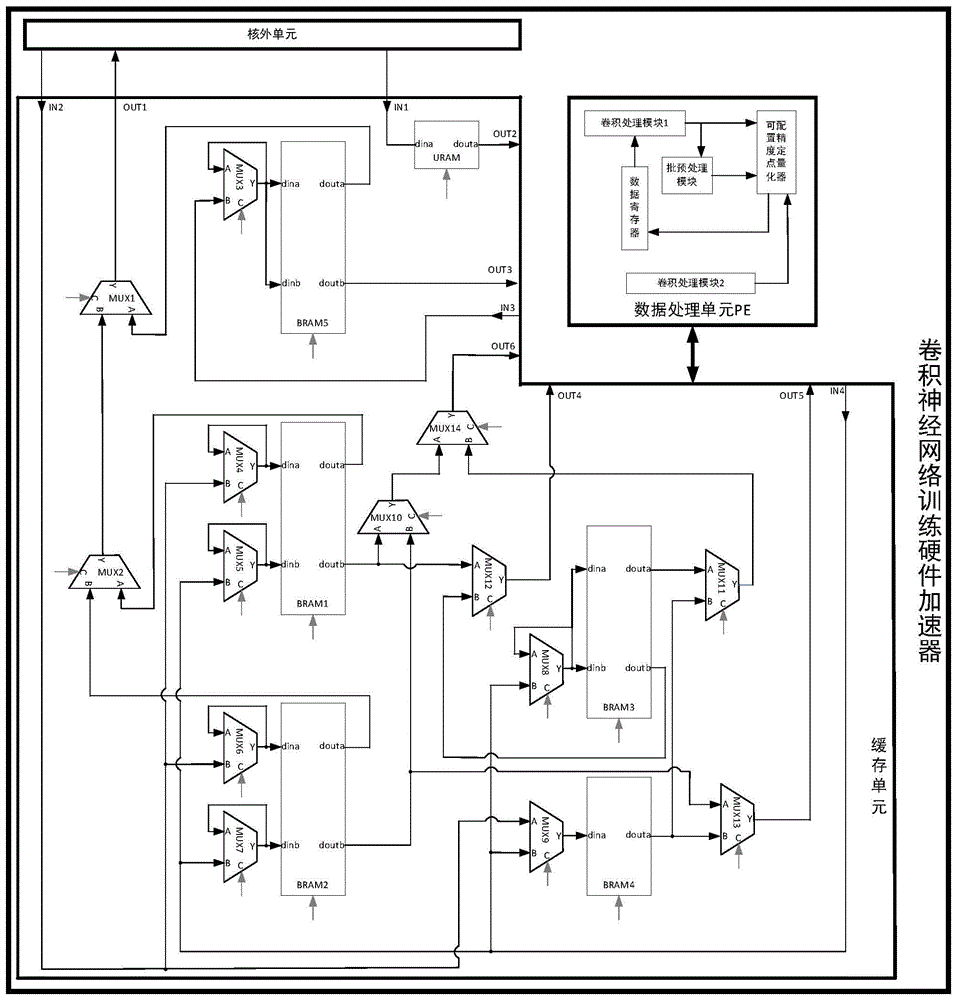
一种卷积神经网络训练硬件加速器,包括核外单元、缓存单元和数据处理单元;
所述核外单元用于存储信息,输出网络各层可学习参数、网络各层特征值到所述缓存单元,接收所述缓存单元输出的可学习参数的梯度、网络各层特征值并实现可学习参数的更新;
所述缓存单元包括第一至第五BRAM、URAM、第一至第十四2选1数据选择器,其中,第一、第二、第三、第五BRAM采用真双口配置,第四BRAM和URAM采用简单双口配置;
所述第一至第十四2选1数据选择器均包含第一输入端、第二输入端、第三输入端和输出端,选择端为低电平时输出端输出第一输入端的数据,选择端为高电平时输出端输出第二输入端的数据;
所述第一、第二、第三、第四、第五BRAM的dina端分别和第四、第六、第八、第九、第三2选1数据选择器的输出端对应相连,第一、第二、第三、第五BRAM的dinb端分别和第五、第七、第八、第三2选1数据选择器的输出端对应相连,第一BRAM的douta端、第二BRAM的douta端分别和所述第二2选1数据选择器的第一输入端、第二输入端对应相连,第一BRAM的doutb端分别和第十、第十二2选1数据选择器的第一输入端相连,第二BRAM的doutb端分别和第十2选1数据选择器的第二输入端、第十三2选1数据选择器的第一输入端相连;
所述第三BRAM的douta端和所述第十一2选1数据选择器的第一输入端相连,第三BRAM的doutb端和所述第十二2选1数据选择器的第二输入端相连;
所述第四BRAM的douta端分别和所述第十一2选1数据选择器的第二输入端、第十三2选1数据选择器的第二输入端相连;
所述第五BRAM的douta端和所述第一2选1数据选择器的第一输入端相连,第五BRAM的doutb端作为缓存单元的第三输出端;
所述URAM的dina端作为缓存单元的第一输入端,URAM的douta端作为缓存单元的第二输出端;
所述第二2选1数据选择器的输出端和第一2选1数据选择器的第二输入端相连,第一2选1数据选择器的输出端作为缓存单元的第一输出端;
所述第三至第八2选1数据选择器的输出端均和其第一输入端相连;
所述第三2选1数据选择器的第二输入端作为缓存单元的第三输入端;
所述第四、第六、第九2选1数据选择器的第一输入端并联,作为缓存单元的第二输入端,第五、第七、第八、第九2选1数据选择器的第二输入端并联后作为缓存单元的第四输入端;
所述第十四2选1数据选择器的第一输入端、第二输入端分别和第十、第十一2选1数据选择器的输出端对应相连;
所述第十二、第十三、第十四2选1数据选择器的输出端分别作为缓存单元的第四、第五、第六输出端;
所述缓存单元在前向传播中从核外单元接收网络第一层的输入特征值并写入第一BRAM,从数据处理单元接收网络最后一层到的输入特征值并写入第四BRAM,从数据处理单元接收中间层的输入特征值并交替写入第二BRAM和第一BRAM,并从第一BRAM和第二BRAM中交替读出,输出到核外单元;缓存单元在反向传播中从数据处理单元接收起始误差和各层的传出误差并交替写入第三BRAM和第一BRAM,从第三BRAM的douta端和doutb端读出的传入误差输出到数据处理单元,分别用于计算传出误差和可学习参数的梯度,从核外单元接收网络中间层的输入特征值交替写入第二BRAM和第四BRAM,并从第四BRAM和第二BRAM中交替读出,输出到数据处理单元,用于计算可学习参数梯度,从数据处理单元接收网络各层可学习参数的梯度,写入第五BRAM,并从第五BRAM中读出,输出到核外单元;
所述缓存单元第一输入端接收所述核外单元的网络各层可学习参数,第二输入端接收所述核外单元的网络各层特征值,第三输入端接收所述数据处理单元计算的网络各层可学习参数的梯度,第四输入端接收所述数据处理单元计算的网络各层特征值和误差,第一输出端输出网络各层的特征值和可学习参数的梯度到所述核外单元,第二输出端输出网络各层可学习参数到所述数据处理单元,第三输出端输出批归一化层的可学习参数梯度到所述数据处理单元,第四输出端输出网络各层误差到所述数据处理单元,第五输出端输出网络各层特征值到所述数据处理单元,第六输出端输出网络各层特征值和误差到所述数据处理单元;
所述数据处理单元包括,第一至第二卷积处理模块、可配置精度定点量化器、批预处理模块和数据寄存器;
所述可配置精度定点量化器用于对收到的网络各层特征值和误差数据、网络各层可学习参数的梯度分别进行定点量化后输出到缓存单元,对收到的均值和归一化系数进行定点量化后输出到数据寄存器;
所述批预处理模块用于根据收到的批归一化层的输入特征值数据计算均值和归一化系数并输出到所述可配置精度定点量化器;
所述数据寄存器用于将收到的定点量化后的均值和归一化系数寄存,并输出到第一卷积处理模块;
所述第一卷积处理模块用于,在网络前向传播中,接收网络各层特征值和可学习参数、批归一化层的均值和归一化系数完成网络各层前向传播的计算,输出网络各层特征值到所述可配置精度定点量化器,输出批归一化层的输入特征值到所述批预处理模块,在网络反向传播中,根据接收到的网络各层误差和可学习参数、批归一化层的可学习参数的梯度和归一化系数计算网络各层的传出误差并输出到所述可配置精度定点量化器;
所述第二卷积处理模块用于根据接收到的网络各层误差、特征值数据,计算网络各层可学习参数的梯度并输出到所述可配置精度定点量化器。
作为本发明一种卷积神经网络训练硬件加速器进一步的优化方案,所述第一至第四BRAM的数据位宽是K1*(B*ci*q)bit,所述第五BRAM的数据位宽是K2*(ci*ci*q),所述URAM的数据位宽是K3*(ci*co*p)bit,B是并行的输入图片数,ci和co分别是并行的卷积输入和输出通道数,q是单个特征值或者激活值的位宽,p是可学习参数的位宽,K1、K2、K3均为预设的正整数。
作为本发明一种卷积神经网络训练硬件加速器进一步的优化方案,所述第一卷积处理模块执行卷积层计算时,以co个卷积输出通道为基本单位,优先遍历输出特征的行和列,其次遍历卷积输出通道。
本发明采用上述技术方案,具有以下增益:
本发明采用的可配置精度的定点量化器,实现全定点计算的训练方案,并根据训练过程中各个层的数据分布范围合理配置各层的量化精度。相比于块浮点或线性量化,定点量化的实现方案不需要设计最值统计模块、能够适用于各种概率分布的数据,硬件实现友好,计算高效,确保模型收敛;
本发明对CNN各层在前向传播和反向传播中的运算进行剖析,对批归一化层、Softmax层的数据流进行了针对性的优化设计,使其便于硬件部署,提高了训练加速器的计算效率;
本发明综合考虑模型参数维度分布和硬件资源,设计了互相支持的卷积并行度和缓存方案,能够最大化数据复用程度,最小化数据搬运次数,且加速器核不存在计算空闲,提供了一种高效且低功耗的片上训练加速器设计的解决方案。
附图说明
图1是本发明公开的训练硬件加速器核结构图;
图2是本发明公开的缓存单元内数据存储方式的示意图;
图3是本发明公开的训练过程中的数据流图。
实施方式
下面结合附图对本发明的技术方案做进一步的详细说明。
本发明可以以许多不同的形式实现,而不应当认为限于这里所述的实施例。相反,提供这些实施例以便使本公开透彻且完整,并且将向本领域技术人员充分表达本发明的范围。在附图中,为了清楚起见放大了组件。
应当理解,尽管这里可以使用术语第一、第二、第三等描述各个元件、组件和/或部分,但这些元件、组件和/或部分不受这些术语限制。这些术语仅仅用于将元件、组件和/或部分相互区分开来。因此,下面讨论的第一元件、组件和/或部分在不背离本发明教学的前提下可以成为第二元件、组件或部分。
如图1所示,本发明公开了一种卷积神经网络训练硬件加速器,包括核外单元、缓存单元和数据处理单元;
所述核外单元用于存储信息,输出网络各层可学习参数、网络各层特征值到所述缓存单元,接收所述缓存单元输出的可学习参数的梯度、网络各层特征值并实现可学习参数的更新;
所述缓存单元包括第一至第五BRAM、URAM、第一至第十四2选1数据选择器,其中,第一、第二、第三、第五BRAM采用真双口配置,第四BRAM和URAM采用简单双口配置;
所述第一至第十四2选1数据选择器均包含第一输入端、第二输入端、第三输入端和输出端,选择端为低电平时输出端输出第一输入端的数据,选择端为高电平时输出端输出第二输入端的数据;
所述第一、第二、第三、第四、第五BRAM的dina端分别和第四、第六、第八、第九、第三2选1数据选择器的输出端对应相连,第一、第二、第三、第五BRAM的dinb端分别和第五、第七、第八、第三2选1数据选择器的输出端对应相连,第一BRAM的douta端、第二BRAM的douta端分别和所述第二2选1数据选择器的第一输入端、第二输入端对应相连,第一BRAM的doutb端分别和第十、第十二2选1数据选择器的第一输入端相连,第二BRAM的doutb端分别和第十2选1数据选择器的第二输入端、第十三2选1数据选择器的第一输入端相连;
所述第三BRAM的douta端和所述第十一2选1数据选择器的第一输入端相连,第三BRAM的doutb端和所述第十二2选1数据选择器的第二输入端相连;
所述第四BRAM的douta端分别和所述第十一2选1数据选择器的第二输入端、第十三2选1数据选择器的第二输入端相连;
所述第五BRAM的douta端和所述第一2选1数据选择器的第一输入端相连,第五BRAM的doutb端作为缓存单元的第三输出端;
所述URAM的dina端作为缓存单元的第一输入端,URAM的douta端作为缓存单元的第二输出端;
所述第二2选1数据选择器的输出端和第一2选1数据选择器的第二输入端相连,第一2选1数据选择器的输出端作为缓存单元的第一输出端;
所述第三至第八2选1数据选择器的输出端均和其第一输入端相连;
所述第三2选1数据选择器的第二输入端作为缓存单元的第三输入端;
所述第四、第六、第九2选1数据选择器的第一输入端并联,作为缓存单元的第二输入端,第五、第七、第八、第九2选1数据选择器的第二输入端并联后作为缓存单元的第四输入端;
所述第十四2选1数据选择器的第一输入端、第二输入端分别和第十、第十一2选1数据选择器的输出端对应相连;
所述第十二、第十三、第十四2选1数据选择器的输出端分别作为缓存单元的第四、第五、第六输出端;
所述缓存单元在前向传播中从核外单元接收网络第一层的输入特征值并写入第一BRAM,从数据处理单元接收网络最后一层到的输入特征值并写入第四BRAM,从数据处理单元接收中间层的输入特征值并交替写入第二BRAM和第一BRAM,并从第一BRAM和第二BRAM中交替读出,输出到核外单元;缓存单元在反向传播中从数据处理单元接收起始误差和各层的传出误差并交替写入第三BRAM和第一BRAM,从第三BRAM的douta端和doutb端读出的传入误差输出到数据处理单元,分别用于计算传出误差和可学习参数的梯度,从核外单元接收网络中间层的输入特征值交替写入第二BRAM和第四BRAM,并从第四BRAM和第二BRAM中交替读出,输出到数据处理单元,用于计算可学习参数梯度,从数据处理单元接收网络各层可学习参数的梯度,写入第五BRAM,并从第五BRAM中读出,输出到核外单元;
所述缓存单元第一输入端接收所述核外单元的网络各层可学习参数,第二输入端接收所述核外单元的网络各层特征值,第三输入端接收所述数据处理单元计算的网络各层可学习参数的梯度,第四输入端接收所述数据处理单元计算的网络各层特征值和误差,第一输出端输出网络各层的特征值和可学习参数的梯度到所述核外单元,第二输出端输出网络各层可学习参数到所述数据处理单元,第三输出端输出批归一化层的可学习参数梯度到所述数据处理单元,第四输出端输出网络各层误差到所述数据处理单元,第五输出端输出网络各层特征值到所述数据处理单元,第六输出端输出网络各层特征值和误差到所述数据处理单元;
所述数据处理单元包括,第一至第二卷积处理模块、可配置精度定点量化器、批预处理模块和数据寄存器;
所述可配置精度定点量化器用于对收到的网络各层特征值和误差数据、网络各层可学习参数的梯度分别进行定点量化后输出到缓存单元,对收到的均值和归一化系数进行定点量化后输出到数据寄存器;
所述批预处理模块用于根据收到的批归一化层的输入特征值数据计算均值和归一化系数并输出到所述可配置精度定点量化器;
所述数据寄存器用于将收到的定点量化后的均值和归一化系数寄存,并输出到第一卷积处理模块;
所述第一卷积处理模块用于,在网络前向传播中,接收网络各层特征值和可学习参数、批归一化层的均值和归一化系数完成网络各层前向传播的计算,输出网络各层特征值到所述可配置精度定点量化器,输出批归一化层的输入特征值到所述批预处理模块,在网络反向传播中,根据接收到的网络各层误差和可学习参数、批归一化层的可学习参数的梯度和归一化系数计算网络各层的传出误差并输出到所述可配置精度定点量化器;
所述第二卷积处理模块用于根据接收到的网络各层误差、特征值数据,计算网络各层可学习参数的梯度并输出到所述可配置精度定点量化器。
作为本发明一种卷积神经网络训练硬件加速器进一步的优化方案,所述第一至第四BRAM的数据位宽是K1*(B*ci*q)bit,所述第五BRAM的数据位宽是K2*(ci*ci*q),所述URAM的数据位宽是K3*(ci*co*p)bit,B是并行的输入图片数,ci和co分别是并行的卷积输入和输出通道数,q是单个特征值或者激活值的位宽,p是可学习参数的位宽,K1、K2、K3均为预设的正整数。
作为本发明一种卷积神经网络训练硬件加速器进一步的优化方案,所述第一卷积处理模块执行卷积层计算时,以co个卷积输出通道为基本单位,优先遍历输出特征的行和列,其次遍历卷积输出通道。
下面本发明以如下参数配置具体阐述实施方式,配置如下:卷积神经网络的输入通道取值集合为{3,64,128,256},特征值尺寸取值集合为{32,16,8,4},8张图片并行计算、4个卷积输入通道并行计算、16个卷积输出通道并行计算,可配置精度量化器实现16bit定点量化,全连接层实现10分类,K1、K2、K3均取值为1,具体实施方式如下:
图2展示了特征值、误差在BRAM中的缓存方式,以及参数在URAM中的缓存方式。URAM的单个地址单元内支持缓存4个卷积输入通道、16个卷积输出通道,共64个通道的数据,每个数据使用2Byte表示,共128Byte,URAM的深度应能确保缓存网络中所有的可学习参数。对于卷积层四维的权重数据,在URAM中的缓存方式是,以4个卷积输入通道和16个卷积输出通道为基本单位,优先排列卷积输入通道,其次排列卷积输出通道,最后排列卷积核的行和列,对于64*3*3*3的权重数据,3*3的卷积核共计9位置,单个位置上卷积输入通道排列1次,卷积输出通道排列4次,共占据URAM的4个深度,9个位置共占据URAM的36个深度;对于批归一化层的一维的权重和偏置数据,在URAM中的缓存方式是单个地址单元内缓存相同通道数的权重和偏置,即存放32个通道的权重和32个通道的偏置,对于64个通道的批归一化层,共占据URAM的2个深度;对于全连接层的二维权重和一维偏置数据,在URAM中的缓存方式是权重和偏置在不同的地址单元中存储,且对于权重数据,单个地址单元内,以4输入通道为基本单位,优先排列输出通道,对于4096*10的全连接层权重数据,单个地址单元内存放4个输入通道,10个输出通道,输入通道排列1024次,共占用URAM的1024个深度,偏置占URAM的1个深度。
第一至第四BRAM的单个地址单元内存放8张图片、4个输入通道,共32个通道的数据,每个数据使用2Byte表示,共64Byte。每一个BRAM的深度能够缓存网络中任意一层的特征值。对于卷积层和批归一化层的四维特征值或者误差,在BRAM中的缓存方式是,以8张图、4个卷积输入通道为基本单位,优先排列卷积输入通道,其次排列特征值或者误差的行和列,对于8*3*32*32的特征图,卷积输入通道排列1次,特征值的行和列排列1024次,共占据BRAM的1024个深度。
第五BRAM的单个地址单元内存放16个通道的数据,共32Byte。对于卷积层和全连接层的反向传播,数据处理单元分别加载特征值及误差的8张图和4个卷积通道进行计算,得到4通道*4通道的权重,然后写入第五BRAM中;对于批归一化层的反向传播,单次计算得到4个通道的权重梯度和偏置梯度,共8个通道,将2次计算的结果写入第五BRAM;第五BRAM的深度应能够缓存任意一个批归一化层的梯度,示例中权重和偏置的最大通道数均是256,单个地址单元存放8个通道,最少需32个深度,由于Xilinx的BRAM特性,用最少的BRAM36Kbit实现32Byte的存储位宽,其最大可用深度是512,固可设第五BRAM的深度为512。在某一层的反向传播期间,当第五BRAM的可用深度不足时,将其内数据输出到核外单元内的存储器备份。
图3展示了训练过程中的数据流图,具体实施步骤如下:
步骤一:将MUX4的C端置为高电平,将8张训练集的数据按图2中的排列方式通过第一BRAM的dina端口写入BRAM1中,同时,将所有的可学习参数写入URAM中。
步骤二:将MUX10、MUX14的C端均置为低电平,将BRAM1的特征图通过doutb口送入PE中的卷积处理模块1,同时,将URAM中卷积层权重送入PE中的卷积处理模块1,开始执行卷积计算,将MUX7的C端置为高电平,卷积结果通过第二BRAM的dinb口写入BRAM2中。此外,在卷积计算期间,PE中的批预处理模块会统计卷积输出的均值和方差,并根据方差计算归一化系数,直至第一个卷积层计算结束。
步骤三:将MUX1和MUX2的C端均置为高电平,将BRAM2中的数据通过douta口送到核外单元DDR,同时,将MUX10的C端置为高电平,将MUX14的C端置为低电平,将BRAM2中的数据通过doutb口送入PE,进行批归一化层中的归一化计算,将MUX5的C端置为高电平,通过dinb口将归一化结果写入BRAM1,直至完成所有数据的归一化计算。
步骤四:将MUX1的C端置为高电平,MUX2的C端置为低电平,将BRAM1中的数据通过douta口送到核外单元DDR,同时,将MUX10和MUX14的C端均置为低电平,将BRAM1中的数据通过doutb口送入PE,将URAM中批归一化层的权重和偏置送入PE,同时参与计算的还有PE中统计得到的均值和归一化系数,进行批归一化层中的校准计算,即批归一化层的输出,将MUX7的C端置为高电平,通过dinb口将批归一化层的输出送入BRAM2,直至批归一化层计算结束。
步骤五:此后基于BRAM1和BRAM2交替缓存策略,重复步骤二到步骤四的工作,继续执行卷积层和批归一化层的计算,其中,ReLU激活层是嵌入在批归一化层中,由控制模块根据网络结构产生ReLU计算的使能,决定是否执行ReLU计算。当开始倒数第二网络层的计算时,将MUX9的C端置为高电平,通过dina口将数据写入BRAM4中,其内数据作为网络最后一个全连接层的输入特征。
步骤六:将MUX13的C端置为高电平,通过douta将BRAM4中的输入特征送入PE,同时加载URAM中相应的权重和偏置,开始执行全连接层的计算,将MUX5的C端置为高电平,通过dinb口将计算结果写入BRAM1,直至全连接层结束。
步骤七:将MUX10、MUX14的C端均置为低电平,将BRAM1的数据送入PE中的卷积处理模块1,执行Softmax函数计算,其输出再与8张图片各自对应的标签进行起始误差计算,将MUX8的C端置为高电平,通过dinb将起始误差写入BRAM3。
步骤八:将MUX11的C端置为低电平,MUX14的C端置为高电平,通过douta将BRAM3中的数据送入PE中的卷积处理模块1,将URAM中全连接层的参数送入PE中的卷积处理模块1,计算全连接层的传出误差,将MUX5的C端置为高电平,通过dinb将误差写入BRAM1,同时,将MUX12和MUX13的C端均置为高电平,分别将起始误差数据和全连接层的输入特征数据送入PE中的卷积处理模块2,进行参数梯度计算,将MUX3的C端置为高电平,将参数梯度写入BRAM5。此外,将MUX6的C端置为高电平,从核外单元传入下游相邻的批归一化层的归一化值,通过dina写入BRAM2中,以便开启下游相邻的批归一化层的反向传播计算。
步骤九:批归一化层的反向传播同样分两步计算,首先,将MUX10、MUX14的C端均置为低电平、通过doutb将BRAM1中的误差送入PE,将MUX13的C端置为低电平,通过doutb将BRAM2中的归一化值送入PE,计算批归一化层的参数梯度,结果写入BRAM5。在批归一化层的参数梯度计算结束后,开始计算批归一化层的传出误差,除了需要BRAM1中的误差、URAM中的权重参数外,还需要PE中的归一化系数、BRAM5中批归一化层的参数梯度,完成传出误差的计算,将MUX8的C端置为高电平,传出误差写入BRAM3中。在此期间,将MUX9的C端置为低电平,加载核外单元DDR中下游一层的特征值数据,通过dina写入BRAM4中。
步骤十:将MUX11的C端置为低电平,MUX14的C端置为高电平,通过douta将BRAM3中的数据送入PE中的卷积处理模块1,从URAM中加载卷积层的权重,并送入PE的卷积处理模块1计算卷积层的传出误差,将MUX5的C端置为高电平,通过dinb将传出误差写入BRAM1,同时,将MUX12和MUX13的C端均置为高电平,从BRAM3的doutb加载传入误差,从BRAM4的douta加载特征值到PE中的卷积处理模块2,计算卷积层的权重梯度,结果写入BRAM5,在此期间,从核外单元DDR加载下游层的输入特征值到BRAM1,为下游的参数梯度计算做准备。
步骤十一:误差数据基于BRAM1和BRAM3实现交替缓存,特征值数据基于BRAM2和BRAM4实现交替缓存,重复步骤九和步骤十,依次交替完成批归一化层和卷积层的反向传播,直至网络的反向传播计算结束。
在反向传播期间,BRAM5实现梯度的缓存,当BRAM5中的有效数据深度达到设定阈值时,将MUX1的C端置为低电平,将其内数据按产生顺序备份到核外单元的DDR。在反向传播计算结束后,由核外单元逻辑实现参数的更新,然后再次重复步骤一到步骤十一,直至训练结束。
至此,训练加速器的具体实施方式已介绍完毕。本发明公开的训练加速器实现了全定点的量化训练方案,优化了数据缓存,在一次前向传播和反向传播中,仅需要从核外单元中的 DDR加载一次参数,最大化了数据复用程度,对批归一化层、Softmax层以及卷积过程中的填充值检测跳过逻辑进行了具体优化,提高了训练计算效率。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 反应腔室及半导体加工设备
- 内衬组件、反应腔室及半导体加工设备
- 一种晶片支撑结构、预热腔室和半导体处理设备
- 用于在单一处理腔室中从半导体膜去除氧化物和碳的设备和方法
- 半导体工艺腔室及其形成方法、半导体工艺装置
- 一种反应腔室、反应腔室的控制方法及半导体加工设备
- 一种反应腔室、反应腔室的控制方法及半导体加工设备