一种基于多注意力联合多级特征的行人再识别方法
文献发布时间:2023-06-19 09:27:35
技术领域
本发明涉及计算机视觉领域,具体涉及一种基于多注意力联合多级特征的行人再识别方法。
行人重识别是计算机视觉领域非常热门的一个研究课题,他可以被视为图像检索的一个子问题。行人重识别的目标就是给定一个监控行人图像,来检索跨设备的情况下该行人的其他图像。当前行人重识别主要分成两种大类方法,一种是传统的方法,主要依赖于手工特征;另外一种是使用深度学习的方法来进行求解。传统的方法因为主要依赖于手工特征,其不能很好的适应数据量很大的一个复杂的环境。近几年来,随着深度学习的发展,大量基于深度学习的行人重识别方法被提出,大大提高了行人重识别的准确性。本发明针对该问题开发了轻量级的基于结合压缩激励模块的紧密连接卷积神经网络的图像分类方法。紧密连接卷积神经网络将当前层前所有层的输出作为输入,实现了特征重用以及提高了参数的效率,使得该模型仅仅使用了少量的参数就可以获得很好的性能。压缩激励模块显示的建模通道之间的相互依赖关系,自适应的重新校准通道方向的特征响应,实现了特征选择,有选择的强调信息特征,并抑制无用的特征。将二者结合,大大提高了卷积神经网络的性能。
社会公共安全一直是社会治安的重要组成部分,其中行人视频监控技术作为其重要的途径近年来得到了高速的发展。由于视频监控设备质量的不断提高以及成本的持续下降,监控视频已经覆盖了城市公共场所的各个角落。随着监控视频的持续应用和建设,他在震慑犯罪,维持社会治安稳定的实践过程中起着很重要的影响,而行人视频也被用于刑事侦查,并且起到了巨大的作用。由于摄像头数量极大,同时各个公共场所的背景的复杂性,光纤,遮挡等一系列的问题是的传统的通过人工对视频进行检查有点余力不足。因此采用计算机视觉为主导的方式去解决视频监控领域带来的问题成为了该领域的热点问题。
行人重识别是指利用计算机视觉技术,即给定一个监控行人图像,检索跨设备下该行人的其他图像。行人重识别可以应用到监控,行为能力理解,异常检测,刑事侦查等方面中。
早期的行人重识别最早可以追溯到跨摄像头多目标跟踪(Multi-target multi-camera tracking,MTMC tracking),在05年,就有文章主要探讨了在跨摄像头系统中,当目标行人在某个相机视野中丢失后如何将其轨迹在其他相机视野下再次关联起来的问题,该文章创造性的提出了如何提取行人特征以及如何进行相似性度量等行人重识别的核心问题。因此,行人重识别也被研究员们从MTMC跟踪问题里抽取出来,作为一个独立的研究课题。郑良博士提出一个行人重识别系统可以看作是行人检测以及行人重识别的结合,随着深度学习的发展,行人检测技术已经逐渐成熟,目前大部分的数据集直接将检测出来的行人图像作为训练集和测试集。
当前,行人重识别已经广泛应用于多个场景下。由于在监控视频中,相机的角度分辨率等问题存在无法获得高质量的人脸图片。因此,在人脸识别技术失效的情况下,行人重识别技术就成了非常重要的替代品技术。
发明内容
针对上述问题,本发明提供了一种基于多注意力联合多级特征的行人再识别方法,其融合了卷积神经网络高层次的语义特征与低层次的一些特征,并且对融合后的特征进行注意力加权的操作后进行分块重组的步骤;特征被分块重组后,其可以在不同的尺度上进行匹配,并且通过设计的新型分类器来获取图像的最后特征表达用于行人重识别的识别任务
本发明的技术方案是:一种基于多注意力联合多级特征的行人再识别方法,具体步骤包括如下:
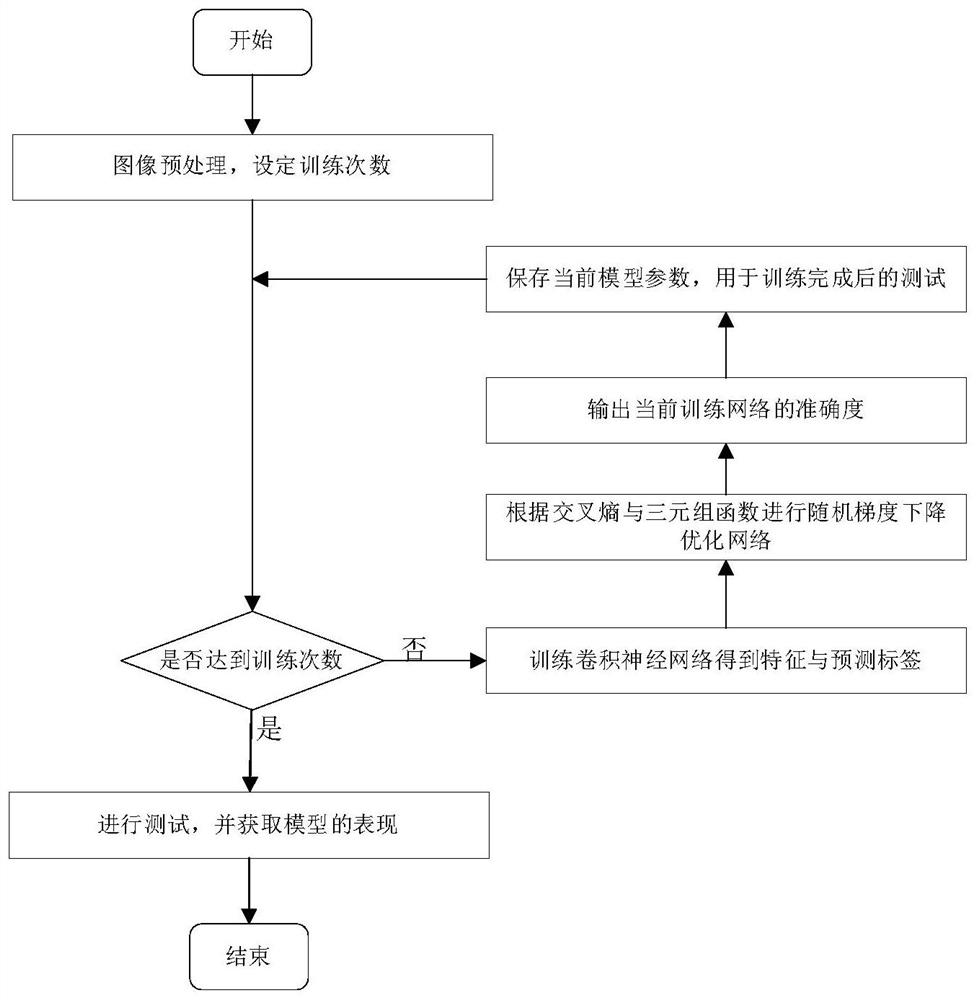
步骤(1.1)、图片预处理和设定训练次数:将行人重识别数据集划分为训练集和测试集,首先将训练集及测试集中的原始图片缩放到固定尺寸,再对缩放后的训练集中的图片进行数据增强操作,然后将经过数据增强后的训练集中的图片与经过缩放后的测试集中的图片转换为张量,从而完成图片预处理;同时设定网络训练次数用于控制网络训练的止停;
其中,所述图片预处理包括随机擦除、颜色抖动及各种仿射变换;
步骤(1.2)、判断是否达到最大训练次数,如是,则停止训练,找出所记录的最高准确度及对应的模型参数作为卷积神经网络模型的最终参数,然后对测试集进行测试,得到测试结果,即得到最佳的卷积神经网络模型;如否,则执行步骤(1.3)、(1.4)及(1.5);
步骤(1.3)、通过训练卷积神经网络模型得到特征与预测标签:将经过预处理后训练集的张量输入至卷积神经网络模型中,经过卷积池化操作后,输出张量最终的特征,并计算张量属于各个类别的概率,将其记为预测标签;
步骤(1.4)、根据损失函数对网络参数进行更新:计算预测标签与真实标签的交叉熵损失,并根据网络输出的张量特征计算三元组损失,最后根据这两个损失函数计算卷积神经网络参数的梯度,再运用随机梯度下降法更新网络参数;
步骤(1.5)、每训练10次输出一次当前卷积神经网络模型的准确度并保存当前模型参数,将其用于训练完成后的测试,进入步骤(1.2),再次判断是否达到最大训练次数。
进一步的,在步骤(1.1)中,所述图片预处理的具体方法是:
首先将训练集和测试集中原始图片缩放到固定尺寸384*128,再对缩放后的训练集中的图片执行下述数据增强操作:
(1.1.1)、水平随机翻转以扩大数据集;
(1.1.2)、随机擦除增强网络的鲁棒性;然后将经过数据增强后的训练集中的图片和经过缩放后的测试集的图片转化为张量,最后使用通道均值和标准差对张量进行标准化,再将张量归一化到0到1之间,其操作过程如下式所述:
式中,μ表示图片的均值,X表示图片张量,σ表示标准方差,max表示图片张量的最大值,min表示图片张量的最小值,X
进一步的,在所述步骤(1.2)中,所述用于测试卷积神经网络模型的具体步骤是:将测试集的张量输入更新过的卷积神经网络模型中,得到测试图片的预测标签,并和真实的图片标签进行对比,计算并且记录卷积神经网络模型的预测准确度,保存卷积神经网络模型参数。
进一步的,在所述步骤(1.3)中,将经过预处理后训练集的张量输入至卷积神经网络模型中,经过卷积池化操作后,输出张量最终的特征的具体操作步骤如下:
(1.2.1)、通过重组的特征经过池化得到一维向量,
(1.2.2)、使用卷积层,和relu层进行降维,得到最后的特征向量。
进一步的,在所述步骤(1.4)中,将预测标签和图片本身包含的类别标签进行对比,运用三元组损失和交叉熵损失作为网络的损失函数;在行人重识别中,类别标签交叉熵损失定义为:
式中,N
其中,所述三元组损失的具体操作步骤如下:给定三个样本I,Ip,In,其中I,Ip为相同ID的样本,I,In为不同ID的样本;三元组损失被定义为:
式中,δ为为超参数,表示正例样本对间距和负例样本对间距之间应当满足的差值;N
故,整个网络的总损失为:
式中,N为计算id损失的数量,M为计算三元组损失的数量;
计算卷积神经网络参数θ
式中,L(θ
本发明的有益效果是:本发明引入了多注意力联合多级特征的行人在识别方法,并使用新型的特征分类器构成了行人在识别的模型。多注意力联合多级特征的行人在识别的卷积神经网络通过融合了高层特征与低层特征所包含的多样化的语义信息,通过对这些语义信息的重构,重组,经过一个从重新设计的分类器,获取到最后的特征表达。并且我们通过一种自适应的注意力网络,实现了对高低层次特征的信息选择,这样在训练过程中,可以有选择的获取更具有判别性的特征,并且抑制无用的特征。这样的一些手段结合,大大的提高了行人在识别的准确率。
附图说明
图1是本发明的结构流程图;
图2是本发明的网络结构实例图。
具体实施方式
为了更清楚地说明本发明的技术方案,下面结合附图对本发明的技术方案做进一步的详细说明:
如图所述;一种基于多注意力联合多级特征的行人再识别方法,具体步骤包括如下:
步骤(1.1)、图片预处理和设定训练次数:将行人重识别数据集划分为训练集和测试集两部分,每张图片都含有一个类别标签(ID),首先将训练集及测试集中的原始图片缩放到固定尺寸,再对缩放后的训练集中的图片进行数据增强操作,然后将经过数据增强后的训练集中的图片与经过缩放后的测试集中的图片转换为张量,从而完成图片预处理;同时设定网络训练次数用于控制网络训练的止停;
其中,所述图片预处理包括随机擦除、颜色抖动及各种仿射变换;
步骤(1.2)、判断是否达到最大训练次数,如是,则停止训练,找出所记录的最高准确度及对应的模型参数作为卷积神经网络模型的最终参数,然后对测试集进行测试,得到测试结果,即得到最佳的卷积神经网络模型;如否,则执行步骤(1.3)、(1.4)及(1.5);
步骤(1.3)、通过训练卷积神经网络模型得到特征与预测标签:将经过预处理后训练集的张量输入至卷积神经网络模型中,经过卷积池化操作后,输出张量最终的特征,并计算张量属于各个类别的概率,将其记为预测标签;
步骤(1.4)、根据损失函数对网络参数进行更新:计算预测标签与真实标签的交叉熵损失,并根据网络输出的张量特征计算三元组损失,最后根据这两个损失函数计算卷积神经网络参数的梯度,再运用随机梯度下降法更新网络参数;
步骤(1.5)、每训练10次输出一次当前卷积神经网络模型的准确度并保存当前模型参数,将其用于训练完成后的测试,进入步骤(1.2),再次判断是否达到最大训练次数。
进一步的,在步骤(1.1)中,所述图片预处理的具体方法是:
首先将训练集和测试集中原始图片缩放到固定尺寸384*128,再对缩放后的训练集中的图片执行下述数据增强操作:
(1.1.1)、水平随机翻转以扩大数据集;
(1.1.2)、随机擦除增强网络的鲁棒性;然后将经过数据增强后的训练集中的图片和经过缩放后的测试集的图片转化为张量,最后使用通道均值和标准差对张量进行标准化,再将张量归一化到0到1之间,其操作过程如下式所述:
式中,μ表示图片的均值,X表示图片张量,σ表示标准方差,max表示图片张量的最大值,min表示图片张量的最小值,X
进一步的,在所述步骤(1.2)中,所述用于测试卷积神经网络模型的具体步骤是:将测试集的张量输入更新过的卷积神经网络模型中,得到测试图片的预测标签,并和真实的图片标签进行对比,计算并且记录卷积神经网络模型的预测准确度,保存卷积神经网络模型参数;
另外,这个卷积神经网络模型有四个阶段,每个阶段的分辨率是前一个阶段的一半。每个阶段包含多个卷积层,在相同分辨率的特征映射上操作。在每个阶段的最后,特征图被向下采样并输入到下一层。
在每个阶段结束时获取该阶段的特征映射,并且使用全局平均池化及改善的RPP结构进行特征的抽取,最后所有的特征将被统一连接成新的特征向量映射。
按照PCB结构中的分块策略,将上一模块中得到的特征映射进行分块,接着按照顺序进行特征重组。根据设计,整个网络在这个阶段将会有21个输出。这些输出将会被采取相同的操作。
进一步的,在所述步骤(1.3)中,将经过预处理后训练集的张量输入至卷积神经网络模型中,经过卷积池化操作后,输出张量最终的特征的具体操作步骤如下:
(1.2.1)、通过重组的特征经过池化得到一维向量,
(1.2.2)、使用卷积层,和relu层进行降维,得到最后的特征向量。
进一步的,在所述步骤(1.4)中,将预测标签和图片本身包含的类别标签进行对比,运用三元组损失和交叉熵损失作为网络的损失函数;在行人重识别中,类别标签交叉熵损失定义为:
式中,N
其中,所述三元组损失的具体操作步骤如下:给定三个样本I,Ip,In,其中I,Ip为相同ID的样本,I,In为不同ID的样本;三元组损失被定义为:
式中,δ为为超参数,表示正例样本对间距和负例样本对间距之间应当满足的差值;N
故,整个网络的总损失为:
式中,N为计算id损失的数量,M为计算三元组损失的数量;
计算卷积神经网络参数θ
式中,L(θ
具体实施例:在某高校公开的Market-1501数据集上进行实验测试,该数据集于夏天拍摄,在2015年构建并公开,包括由6个摄像头(其中5个高清摄像头和1个低清摄像头)拍摄到的1501个行人、32668个检测到的行人矩形框。每个行人至少由2个摄像头捕获到,并且在一个摄像头下可能具有多张图像。训练集有751个行人,包含12936张图像;测试集有750个行人,包含19732张图像;
实验结果rank-1达到了94.74%,mAP达到了85.09,从而验证了我们设计的网络模型(见附图2)的有效性。
最后,应当理解的是,本发明中所述实施例仅用以说明本发明实施例的原则;其他的变形也可能属于本发明的范围;因此,作为示例而非限制,本发明实施例的替代配置可视为与本发明的教导一致;相应地,本发明的实施例不限于本发明明确介绍和描述的实施例。
- 一种基于多注意力联合多级特征的行人再识别方法
- 一种基于深度学习的多级特征提取网络行人再识别方法