自适应局部一致概念分解的多视图聚类算法
文献发布时间:2023-06-19 09:54:18
技术领域
本发明涉及多视图聚类算法领域。特别是涉及到自适应局部一致概念分解的多视图聚类算法。
背景技术
聚类是机器学习和数据挖掘中一项重要的无监督学习任务,用来处理未知领域的数据结构分类,是进一步机器学习的基础。传统的聚类方法在处理单视图数据及的聚类时能够取得很好的结果。但是在许多实际应用中,多视图数据广泛的应用于诸多科学领域,如机器学习、计算机视觉和数据挖掘,比如,在视觉数据中,图像可以用不同的属性进行描述,比如SIFT和HOG;在网络中,web页面可以用文本、图像和视频来描述。由于数据的不同属性之间彼此互补,因此合理融合数据所有视图的算法能大大提升算法的聚类性能。大量的多视图聚类算法应运而生。这些算法粗略的分为三大类,第一类,这类算法对数据的每个视图进行聚类,然后对所有视图的聚类结果进行融合得到最终的聚类结果。第二类,这类算法在聚类过程中对视图进行融合,聚类的结果即为最终结果。第三类,这类算法将多个视图首先整合为一个统一的视图,然后在这个基础上使用标准聚类算法。
近年来,随着机器学习技术的广泛应用,越来越多的技术已经成功地应用于降维和传统的数据聚类,如矩阵分解、图形模型和流形学习等。
非负矩阵分解作为一种矩阵分解技术,已经被应用到数据聚类中,并取得了令人印象深刻的结果。例如,Xu等人提出了一种非负矩阵分解方法,它以一种易于解释的方式对数据矩阵进行因子分解,并在文档聚类中显示出优越的性能。然而,NMF侧重于分析元素为非负的数据矩阵,在某些变换的空间,如再生核Hilbert空间(RKHS)中不能有效地进行分析。为了解决这个问题,人们提出了概念分解(CF)。CF将每个数据点建模为簇中心的线性组合,将每个簇建模为数据点的线性组合;因此,CF可以应用于任何数据空间。尽管CF已经取得了一些成功,但它未能充分利用局部的几何结构信息。流形学习作为机器学习的另一种流行技术,在数据降维和传统的数据聚类中取得了显著的效果。在流形学习中,人们试图找到一个光滑的低维流形嵌入高维向量空间基于一组数据点。获取数据点局部不变特性的一种常用方法是构造相应的拉普拉斯图。将拉普拉斯图与CF相结合,提出了一种改进的局部一致概念分解(LCCF),它不仅克服了NMF的局限性,而且很好地保留了原始数据点的局部结构信息,从而大大提高了CF的性能。
然而,上述满足单个视图数据聚类的方法可能对多聚类任务无效。随着多视图聚类的发展,人们提出了多种方法来扩展上述技术,即矩阵分解和流形学习。Liu等人提出了multiNMF,解决了NMF和多视图聚类之间的差距。虽然multiNMF已经被证明能产生更好的聚类结果,但它在某些变换的空间,如再生核Hilbert空间中不能有效地发挥作用。此外,multiNMF不能保留原始数据空间的局部几何结构。Wang等人通过概念分解(MVCC)提出了有效的多视图数据聚类(MVCC),该方法考虑了每个视图的局部几何结构,可以在任何空间执行。然而,在该算法中,多个视图被正则化为一个共同的共识,当视图是异构的且质量变化很大时,这可能会降低聚类性能。
发明内容
为了解决上述存在问题。本发明提供自适应局部一致概念分解的多视图聚类算法。对MVCC的刚性约束进行松弛,使用每一对视图施加相似性约束,优于单视图LCCF,也优于约束太过于严格的multiNMF和MVCC算法。为达此目的:
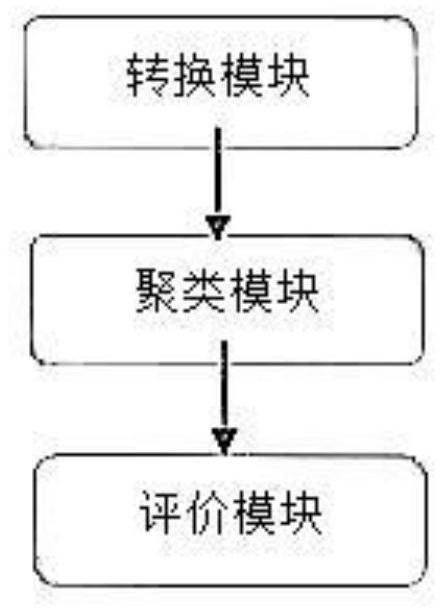
本发明提供自适应局部一致概念分解的多视图聚类算法,由转换模块、聚类模块和评价模块组成;
所述转换模块用于对原始数据矩阵进行处理,通过对原始数据矩阵作分解,将数据转换到低维空间,得到既有邻域保持又有两两不同视图的约束保持的原始数据在低维空间的近似表达;
令多视图数据集合的数据矩阵为
1)初始化:
所述转换模块初始化具体步骤如下:
(a)构造第一个正则器,由数据的视图一致性约束,将任意视图两两融合为一个视图,定义如下:
其中,n
(b)构造每一个视图的p-邻域图,对第v个视图,其p-邻域图的顶点由该视图的所有数据点组成,边上的权重定义如下:
(c)构造第二个正则器,用于在低维空间保持数据的局部几何结构特性,其定义如下:
其中,D
(d)由此得到ALCCF的目标函数为:
s.t.U
其中θ
2)求解ALCCF的优化问题;
s.t.U
首先,对目标函数O做等价变形
其中,Tr(·)表示迹函数,K=X
接着,令
分别求L对U
使用Karush-Kuhn-Tucker条件conditions
利用迭代公式求解U
所述聚类模块用投影模块得到的原始数据在低维空间的近似矩阵V,利用kmeans进行聚类;
所述评价模块利用三种评价指标:精确度、互信息以及F1-score对所得的聚类结果评价。
作为本发明进一步改进,所述评价模块聚类结果评价具体如此:
第一个评价指标精确度:对数据点d
其中,n是数据集的数据总数,函数map(l
AC的值在0~1之间,值越大说明结果越好;
第二个评价指标MI(C,C'),其定义如下:
其中,p(c
其中,H(C)和H(C')分别是C和C'的熵,NMI值在0~1之间,值越大说明结果越好;
第三个评价指标F1-score,定义如下:
其中,p是精度,即分类结果的正确率,r是召回率,即被正确判定的正例占总的正例的概率,F1-score是精度和召回率的调和平均,其值在0~1之间,值越大说明结果越好。
本发明提出了自适应局部一致概念分解的多视图聚类算法。本申请对MVCC的刚性约束进行松弛,使用每一对视图施加相似性约束。具体的做法是在概念分解框架中引入了两个正则化器:一个是几何正则化器,它通过构造最近邻图对数据空间的几何信息进行编码,另一个用于从两个互补的视图中学习系数矩阵。有了这两种正则化器,ALCCF在处理多视图数据时,不仅可以学习到更好的低维表示,能够捕捉到内在的几何结构,而且对存在噪声的多视图数据更为鲁棒。
附图说明
图1为本发明的虚拟系统框架图。
具体实施方式
下面具体实施方式对本发明作进一步详细描述:
本发明提供自适应局部一致概念分解的多视图聚类算法。对MVCC的刚性约束进行松弛,使用每一对视图施加相似性约束,优于单视图LCCF,也优于约束太过于严格的multiNMF和MVCC算法。
下面对本发明的实例作详细说明:本实例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和过程,但本发明的保护范围不限于下述的实例。
本发明虚拟系统框架图如图1所示在BBCSport数据集的子集BBCSport2_544上进行测试,改子集由544个文档组成,共有5个分组,每个文件有2个视图,用5个主题标签中的一个进行标注。
1、转换模块:
转换模块主要对原始数据矩阵进行处理,通过对原始数据矩阵作分解,将数据转换到低维空间,得到既有邻域保持又有两两不同视图的约束保持的原始数据在低维空间的近似表达。令多视图数据集合的数据矩阵为
1)初始化。
(a)构造第一个正则器:
其中,n
(b)构造每一个视图的p-邻域图。对第v个视图,其p-邻域图的顶点由该视图的所有数据点组成,边上的权重定义如下
(c)构造第二个正则器:
其中,D
(d)由此得到ALCCF的目标函数为:
s.t.U
其中θ
2)求解ALCCF的优化问题:
s.t.U
得到U
利用迭代公式求解U
2.聚类模块
聚类模块主要用投影模块得到的原始数据在低维空间的近似矩阵V,利用kmeans算法进行聚类。
3.评价模块
利用三种评价指标:精确度(accuracy,AC)、互信息(mutual information,MI)以及F1-score对所得的聚类结果评价。
第一个评价指标精确度(accuracy,AC):对数据点d
其中,n是数据集的数据总数,函数map(l
第二个评价指标MI(C,C'),其定义如下:
其中,p(c
其中,H(C)和H(C')分别是C和C'的熵。
第三个评价指标F1-score,定义如下:
其中,p是精度(分类结果的正确率),r是召回率(被正确判定的正例占总的正例的概率)。
本发明的效果可以通过如下实验验证:
表1给出了BBCSport2_544数据子集在下的聚类结果。为了使我们的实验效果一目了然,本实验提出的方法与LCCF,multiNMF以及MVCC算法在相同的数据集上做比较。
表1 LCCF,multiNMF,MVCC和本发明方法的聚类性能对比
通过实验结果我们可以看出,本实验优于单视图LCCF,也优于约束太过于严格的multiNMF和MVCC算法。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作任何其他形式的限制,而依据本发明的技术实质所作的任何修改或等同变化,仍属于本发明所要求保护的范围。
- 自适应局部一致概念分解的多视图聚类算法
- 基于局部约束自适应邻域自表示流形概念分解的聚类方法