一种基于域-不变特征的元-知识微调方法及平台
文献发布时间:2023-06-19 09:54:18
技术领域
本发明属于语言模型压缩领域,尤其涉及一种基于域-不变特征的元-知识微调方法及平台。
背景技术
预训练神经语言模型通过在特定任务的训练集上微调提升了多种自然语言处理任务的性能。在微调阶段,已有的面向下游任务的预训练语言模型的压缩方法是在下游任务特定数据集上进行微调,训练所得的压缩模型的效果受限于该类任务的特定数据集。
发明内容
本发明的目的在于针对现有技术的不足,提供一种基于域-不变特征的元-知识微调方法及平台。本发明引入基于域-不变特征的元-知识,从不同数据集对应的不同域中学习同一类任务的共同域特征,以获得高度可转移的域-不变知识;经过元-知识微调后,模型可以针对同一类任务的不同域进行微调,具有更好的参数初始化能力和较高的泛化能力,最终可以压缩出同一类任务通用的架构。
本发明的目的是通过以下技术方案实现的:一种基于域-不变特征的元-知识微调方法,包括以下几个阶段:
第一阶段,构建对抗域分类器:利用元-知识微调添加对抗域分类器来优化下游任务;为了驱动某一类分类器可以区分不同域的类别,构建一种对抗域分类器,根据对抗机器学习理论,需要最大化损失函数,使得域分类器无法预测真实的域标签;为了使最小化互换域损失函数时,对抗域分类器的预测概率趋于预测错误域的标签,提出分类器预测直接互换域的标签,最小化互换域的损失函数,使得学习所得的特征是与域无关的;
第二阶段,构建输入特征:输入特征由词嵌入表示和域嵌入表示组成;
第三阶段,学习域-不变特征:基于对抗域分类器构建域损坏目标函数,即分类器预测直接互换域的标签;将真实域的域嵌入表示输入分类器,确保即使在分类器从真实域的域嵌入表示学得真实域信息的情况下,它仍然只能生成经过损坏的输出;通过这种方式,强制BERT的词嵌入表示隐藏揭示任何域信息,保证输入文本的特征的域-不变性。
进一步地,所述第一阶段,构建对抗域分类器,具体为:
步骤1.1:定义对抗域分类器;考虑两个不同域
其中,
步骤1.2:构建基于互换域的对抗域分类器;针对对抗域分类器,根据对抗机器学习理论,需要最大化损失函数
其中,仅强制分类器将输入文本
进一步地,所述第二阶段,构建输入特征,具体为:
步骤2.1:获取词嵌入表示:词嵌入表示
其中,
步骤2.2:获取域嵌入表示:域嵌入表示
步骤2.3:输入特征为
进一步地,所述第三阶段中,构建域损坏目标函数
一种上述基于域-不变特征的元-知识微调方法的平台,包括以下组件:
数据加载组件:用于获取预训练语言模型的训练样本,所述训练样本是满足监督学习任务的有标签的文本样本;
自动压缩组件:用于将预训练语言模型自动压缩,包括预训练语言模型和元-知识微调模块;
元-知识微调模块是在所述自动压缩组件生成的预训练语言模型上构建下游任务网络,利用域-不变特征的元-知识对下游任务场景进行微调,输出最终微调好的学生模型,即登陆用户需求的包含下游任务的预训练语言模型压缩模型;将所述压缩模型输出到指定的容器,可供所述登陆用户下载,并在所述平台的输出压缩模型的页面呈现压缩前后模型大小的对比信息;
推理组件:登陆用户从所述平台获取预训练压缩模型,用户利用所述自动压缩组件输出的压缩模型在实际场景的数据集上对登陆用户上传的自然语言处理下游任务的新数据进行推理;并在所述平台的压缩模型推理页面呈现压缩前后推理速度的对比信息。
本发明的有益效果如下:
第一,本发明研究基于域-不变特征的通用语言模型的元-知识微调方法:基于域-不变特征的学习。该面向下游同类任务的预训练语言模型的元-知识微调为下游同类任务不同数据集的域-不变特征学习提供方法,微调所得的具有域-不变特征的压缩模型适用于同类任务的不同数据集。在预训练语言模型压缩架构输出的预训练网络基础上,通过基于域-不变特征的元-知识微调网络对下游任务进行微调,由此得到与数据集无关的同类下游任务语言模型的通用压缩架构;
第二,本发明提出学习同类任务不同数据集上高度可转移的共有知识,即域-不变特征。引入域-不变特征,微调网络集中学得同类任务不同数据集对应的不同域上的共同域特征,提升了同类任务通用语言模型的参数初始化能力和泛化能力,最终,获得同类下游任务语言模型的通用压缩架构;
第三,本发明所述的基于域-不变特征的通用语言模型的元-知识微调平台,生成面向同类任务语言模型的通用架构,充分利用已微调好的模型架构提高下游同类任务的压缩效率,并且可将大规模自然语言处理模型部署在内存小、资源受限等端侧设备,推动了通用深度语言模型在工业界的落地进程。
附图说明
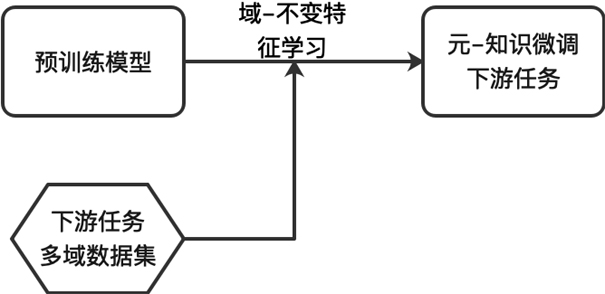
图1是基于域-不变特征的通用语言模型的元-知识微调方法示意图。
具体实施方式
本发明在预训练语言模型的通用压缩架构基础上公开了一种基于域-不变特征的通用语言模型的元-知识微调方法及平台。该面向下游任务的预训练语言模型的微调方法是在下游任务跨域数据集上进行微调,所得的压缩模型的效果适应于同类任务不同域的数据场景。
如图1所示,本发明设计一种元-知识微调学习方法:基于域-不变特征的学习方法。本发明学习同类任务不同数据集上高度可转移的共有知识,即域-不变特征。引入域-不变特征,微调网络集中学得同类任务不同数据集对应的不同域上的共同域特征,快速适应任何不同的域。域-不变特征的学习提升了同类任务通用语言模型的参数初始化能力和泛化能力,最终微调得到同类下游任务语言模型的通用压缩架构。在元-知识微调网络中,本发明设计域-不变特征的损失函数,学习与域无关的通用知识,即最小化一个域-不变特征的学习目标来驱动语言模型具有域-不变特征的编码能力。
本发明一种基于域-不变特征的元-知识微调方法具体包括以下步骤:
步骤一:构建对抗域分类器。利用元-知识微调添加对抗域分类器来优化下游任务。为了驱动某一类分类器可以区分不同域的类别,构建一种对抗域分类器,根据对抗机器学习理论,需要最大化损失函数,使得域分类器无法预测真实的域标签。为了使最小化互换域损失函数时,对抗域分类器的预测概率总是趋于预测错误域的标签,如将
步骤(1.1):定义对抗域分类器。考虑两个不同域
其中,
步骤(1.2):构建基于互换域的对抗域分类器。针对上述对抗域分类器,根据对抗 机器学习理论,需要最大化损失
步骤二:构建输入特征。输入特征包含词嵌入表示
步骤(2.1):获取词嵌入表示:考虑到BERT中的Transformer编码器神经架构,令
其中,
步骤(2.2):获取域嵌入表示:学习输入实例
步骤三:基于域-不变特征的元-知识微调网络。构建域损坏目标函数:
其中,
本发明一种基于域-不变特征的元-知识微调方法的平台,包括以下组件:
数据加载组件:用于获取预训练语言模型的训练样本,所述训练样本是满足监督学习任务的有标签的文本样本。
自动压缩组件:用于将预训练语言模型自动压缩,包括预训练语言模型和元-知识微调模块。
元-知识微调模块是在所述自动压缩组件生成的预训练语言模型上构建下游任务网络,利用域-不变特征的元-知识对下游任务场景进行微调,输出最终微调好的学生模型,即登陆用户需求的包含下游任务的预训练语言模型压缩模型;将所述压缩模型输出到指定的容器,可供所述登陆用户下载,并在所述平台的输出压缩模型的页面呈现压缩前后模型大小的对比信息。
推理组件:登陆用户从所述平台获取预训练压缩模型,用户利用所述自动压缩组件输出的压缩模型在实际场景的数据集上对登陆用户上传的自然语言处理下游任务的新数据进行推理;并在所述平台的压缩模型推理页面呈现压缩前后推理速度的对比信息。
下面将以智能客服应用场景中的自然语言推断任务对本发明的技术方案做进一步的详细描述。
智能客服场景中的自然语言推断任务,通常是用户给出一对句子,智能客服判断两个句子语义是相近,矛盾,还是中立。 由于也是分类问题,也被称为句子对分类问题。MNLI数据集提供了来自智能客服应用领域的训练示例,目的就是推断两个句子是意思相近,矛盾,还是无关的。通过所述平台的数据加载组件获取登陆用户上传的自然语言推断任务的BERT模型和智能客服应用领域的MNLI数据集。
通过所述平台的自动压缩组件,生成BERT预训练语言模型。
通过所述平台加载自动压缩组件生成的BERT预训练模型,在所述生成的预训练模型上构建自然语言推断任务的模型。
基于所述自动压缩组件的元-知识微调模块所得的学生模型进行微调,在预训练语言模型基础上构建智能客服场景中的自然语言推断任务的模型,利用典型性分数的元-知识对下游任务场景进行微调,输出最终微调好的学生模型,即登陆用户需求的包含自然语言推断任务的预训练语言模型压缩模型。
将所述压缩模型输出到指定的容器,可供所述登陆用户下载,从训练数据中随机采样了每个领域数据的5%、10%、20%的数据进行元-知识微调。并在所述平台的输出压缩模型的页面呈现微调前后模型精度的对比信息。如下表1所示。
表1:自然语言推断任务BERT模型元-知识微调前后对比信息
从表1可知,通过所述平台的推理组件,利用所述平台输出的压缩模型对登陆用户上传的智能客服场景中的自然语言推断任务的MNLI测试集数据进行推理,并在所述平台的压缩模型推理页面呈现元-知识微调后比元-知识微调前推理精度在电话、政府、旅游、小说领域分别提升了2.1%、1.4%、2.3%、2.6%、2.4%。
- 一种基于域-不变特征的元-知识微调方法及平台
- 一种基于域-不变特征的元-知识微调方法及平台