图像处理装置、显示系统、记录介质以及图像处理方法
文献发布时间:2023-06-19 11:21:00
技术领域
本公开涉及图像处理装置、显示系统、记录介质以及图像处理方法。
背景技术
已知一种用户能够任意观看可从自身以外观看的景象的技术(例如参照专利文献1)。在该技术中,从他人、汽车等移动体的每一个所佩戴(穿戴)/安装的多个拍摄装置中指定期望的拍摄装置,将与由所指定的拍摄装置拍摄到的图像数据对应的图像显示于用户佩戴的显示装置。
现有技术文献
专利文献1:日本特开2008-154192号公报
发明内容
发明所要解决的问题
然而,在上述的专利文献1所述的技术中,只不过是一位用户在观看由其他移动体佩戴/安装的拍摄装置所拍摄到的景象。因此,在上述的专利文献1的技术中,存在如下问题:在想要与其他用户共享相同的景象的情况下,由于无法视觉确认其他用户的姿态,因而无法获得与其他用户的一体感(协调统一的感觉、整体感),缺少像现实世界那样的热烈气氛。
本公开是鉴于上述问题而做出的,目的在于提供能够使在用户彼此之间获得一体感的图像处理装置、显示系统、程序以及图像处理方法。
用于解决问题的技术方案
为了解决上述的问题并达成目的,本公开涉及的图像处理装置具备具有硬件的处理器,所述处理器,在佩戴能够与该处理器通信的第1可穿戴设备的第1佩戴者和佩戴能够与该处理器通信的第2可穿戴设备的第2佩戴者中的某一方的佩戴者搭乘移动体、另一方的佩戴者虚拟地搭乘所述移动体的情况下,生成以所述一方的佩戴者的视角观察所述另一方的佩戴者虚拟地搭乘在所述移动体内的状态所得的第1虚拟图像,该第1虚拟图像反映出所述另一方的佩戴者的行为;将所述第1虚拟图像向所述一方的佩戴者佩戴的可穿戴设备输出。
另外,在本公开涉及的图像处理装置中,所述处理器,生成以所述另一方的佩戴者的视角观察所述一方的佩戴者搭乘于所述移动体内的状态所得的第2虚拟图像,该第2虚拟图像反映出所述一方的佩戴者的行为并且虚拟地表示出所述移动体的外部空间;将所述第2虚拟图像向所述另一方的佩戴者佩戴的可穿戴设备输出。
据此,处理器将第2虚拟图像向虚拟地搭乘移动体的第2佩戴者佩戴的第2可穿戴设备输出,由此,第2佩戴者即使没有实际地一同乘坐于移动体,也能够虚拟地体验搭乘于移动体,因此能够使在用户彼此之间获得一体感。
另外也可以为,所述处理器,基于所述一方的佩戴者的行为,判定所述一方的佩戴者是否在所述移动体内朝着所述另一方的佩戴者虚拟地就座的方向;在判定为所述一方的佩戴者在所述移动体内朝着所述另一方的佩戴者虚拟地就座的方向的情况下,生成所述第1虚拟图像。
据此,处理器在第1佩戴者在移动体内朝着第2佩戴者虚拟地就座的方向的情况下生成第1虚拟图像,因此能够专心进行移动体的驾驶。
另外也可以为,所述处理器,取得用于识别所述一方的佩戴者的第1识别信息、用于识别所述另一方的佩戴者的第2识别信息和所述移动体的当前的位置信息;从记录行动历史记录信息的行动历史记录数据库,取得基于所述位置信息、所述第1识别信息和所述第2识别信息的所述行动历史记录信息,所述行动历史记录信息是将与所述第1识别信息关联的所述一方的佩戴者的行动历史记录、与所述第2识别信息关联的所述另一方的佩戴者的行动历史记录、和拍摄所述一方的佩戴者和所述另一方的佩戴者各自在过去到访的地方所得到的拍摄图像或者视频(动态图像)相关联的信息;基于所述行动历史记录信息,生成使用在所述移动体的当前位置处所述一方的佩戴者和所述另一方的佩戴者中的至少一方拍摄到的所述拍摄图像或者所述视频表示了所述移动体的外部空间中的一部分的所述第1虚拟图像和所述第2虚拟图像中的每一个。
据此,处理器生成使用行动历史记录信息所包含的拍摄图像或者视频表示了移动体的外部空间的一部分的第1虚拟图像和第2虚拟图像中的每一个,因此第1佩戴者和第2佩戴者能够就经历过的过去的回忆进行交谈。
另外也可以为,所述处理器,取得所述移动体的当前的位置信息和所述一方的佩戴者或者所述另一方的佩戴者发出的语音的语音数据;基于所述语音数据,判定是否所述一方的佩戴者和所述另一方的佩戴者中有一方发出了与地标(landmark)相关联的名称;在判定为所述一方的佩戴者和所述另一方的佩戴者中的一方发出了所述名称的情况下,从记录将表示地图上的地标的位置和名称的地标位置信息、与当前和过去的映现地标的地标图像相关联的地标信息的地标数据库,取得基于所述位置信息与所述一方的佩戴者和所述另一方的佩戴者中的一方发出的所述名称的、当前和过去的至少一方的所述地标图像;生成使用当前和过去的至少一方的所述地标图像表示了所述移动体的外部空间的一部分的所述第1虚拟图像和所述第2虚拟图像中的每一个。
据此,处理器生成使用当前和过去的至少一方的地标图像表示了移动体的外部空间的一部分的第1虚拟图像和第2虚拟图像中的每一个,因此第1佩戴者和第2佩戴者能够就经历过的过去的回忆进行交谈。
另外也可以为,所述处理器,在从所述另一方的佩戴者佩戴的可穿戴设备输入了指示生成在所述一方的佩戴者的驾驶操作中关注的关注区域的图像的指示信号的情况下,基于所述指示信号、所述移动体的内部空间的空间信息、和所述一方的佩戴者的行为,生成虚拟地表示出所述关注区域内的所述一方的佩戴者的驾驶操作的第3虚拟图像;将所述第3虚拟图像代替所述第2虚拟图像向所述另一方的佩戴者佩戴的可穿戴设备输出。
据此,处理器基于指示生成在第1佩戴者的驾驶操作中关注的关注区域的图像的指示信号、移动体的内部空间的空间信息以及第1佩戴者的行为,生成虚拟地表示出在第1佩戴者的驾驶操作中关注的关注区域内的第1佩戴者的驾驶操作的第3虚拟图像,并将第3虚拟图像向第2可穿戴设备输出,因此第2佩戴者能够直观地掌握第1佩戴者的驾驶操作。
另外也可以为,有多个所述第2佩戴者,所述处理器,从多个所述第2佩戴者中决定代表者;生成所述代表者虚拟地搭乘在所述移动体内的所述第1虚拟图像;在从所述代表者佩戴的所述第2可穿戴设备输入了所述指示信号的情况下,生成所述第3虚拟图像。
据此,处理器生成从多个第2佩戴者中决定的代表者虚拟地搭乘在移动体内的第1虚拟图像,因此,能够使在第1佩戴者与代表者之间获得一体感,此外,多个第2佩戴者能够直观地掌握第1佩戴者的驾驶操作。
另外也可以为,所述处理器,判定所述另一方的佩戴者是否搭乘于与所述移动体不同的另一移动体;在所述另一方的佩戴者搭乘于与所述移动体不同的另一移动体的情况下,取得所述移动体和所述另一移动体各自作为目标的目的地;判定所述移动体和所述另一移动体各自的所述目的地是否相同;在所述移动体和所述另一移动体各自的所述目的地相同的情况下,将所述第1虚拟图像向所述一方的佩戴者佩戴的可穿戴设备输出,并且将所述第2虚拟图像向所述另一方的佩戴者佩戴的可穿戴设备输出。
据此,处理器在第1佩戴者搭乘的移动体和第2佩戴者搭乘的其他移动体各自的目的地相同的情况下,将第1虚拟图像向第1佩戴者佩戴的第1可穿戴设备输出,并且将第2虚拟图像向第2佩戴者佩戴的第2可穿戴设备输出,因此,即使在移动时是分别的,也能够一边使在用户彼此之间获得一体感、一边移动。
另外也可以为,所述处理器,取得所述移动体和所述另一移动体各自的当前位置;基于所述移动体和所述另一移动体各自的当前位置,在所述另一移动体比所述移动体接近于所述目的地的情况下,将所述第1虚拟图像代替所述第2虚拟图像向所述另一方的佩戴者佩戴的可穿戴设备输出,并且将所述第2虚拟图像代替所述第1虚拟图像向所述一方的佩戴者佩戴的可穿戴设备输出。
据此,处理器在第2佩戴者搭乘的另一移动体比第1佩戴者搭乘的移动体接近于目的地的情况下,将第1虚拟图像代替第2虚拟图像向第2佩戴者佩戴的第2可穿戴设备输出,并且将第2虚拟图像代替第1虚拟图像向第1佩戴者佩戴的第1可穿戴设备输出,因此能够使在用户彼此间共享朝向目的地的虚拟的赛车体验。
另外也可以为,所述处理器,判定所述另一方的佩戴者是否搭乘于与所述移动体不同的另一移动体;在判定为所述另一方的佩戴者搭乘于与所述移动体不同的另一移动体的情况下,判定所述另一移动体是否连结于所述移动体;在判定为所述另一移动体连结于所述移动体的情况下,将所述第2虚拟图像向所述另一方的佩戴者佩戴的可穿戴设备输出。
据此,处理器在判定为有其他移动体连结于移动体的情况下,将第2虚拟图像向搭乘与移动体连结的其他移动体的第2佩戴者佩戴的第2可穿戴设备输出,所以搭乘移动体的搭乘者能够一边作为带路人模拟地引导搭乘其他移动体的搭乘者一边移动,因此能够使在用户彼此之间获得一体感。
另外也可以为,所述第1虚拟图像是以虚拟形象(avatar)或者全息图(hologram)虚拟地表示出所述另一方的佩戴者的图像,所述第2虚拟图像是以虚拟形象或者全息图虚拟地表示出所述一方的佩戴者的图像。
据此,即使不是真实的图像,由于显示虚拟形象或者全息图,因此也能够使在用户彼此之间虚拟地获得一体感。
另外也可以为,所述第1可穿戴设备具备检测所述第1佩戴者的行为的第1行为传感器,所述第2可穿戴设备具备检测所述第2佩戴者的行为的第2行为传感器,所述处理器取得所述第1行为传感器的检测结果和所述第2行为传感器的检测结果。
据此,处理器基于由第1行为传感器和第2行为传感器各自检测出的检测结果,生成第1虚拟图像或者第2虚拟图像,因此,能够真实地表现第1佩戴者和第2佩戴者的行为。
另外也可以为,所述移动体具备通过拍摄内部空间而生成图像数据的影像传感器,所述处理器,取得所述影像传感器所生成的所述图像数据;基于所述图像数据检测所述第1佩戴者的行为;基于所述第1佩戴者的行为生成所述第2虚拟图像。
据此,处理器基于由影像传感器生成的图像数据,检测第1佩戴者的行为,并基于该检测结果生成第2虚拟图像,因此能够真实地表现第2虚拟图像中的第1佩戴者的行为。
另外也可以为,所述移动体具备通过拍摄内部空间和外部空间而生成图像数据的影像传感器,所述处理器,取得所述影像传感器所生成的所述图像数据作为所述移动体的内部空间的空间信息;基于所述空间信息生成所述第1虚拟图像和所述第2虚拟图像。
据此,处理器取得由影像传感器生成的图像数据作为与移动体的内部空间和外部空间有关的空间信息,因此能够真实地表现第1虚拟图像或者第2虚拟图像。
另外也可以为,所述第1可穿戴设备具备能够向所述一方的佩戴者投影所述第1虚拟图像的投影部,所述第2可穿戴设备具备能够显示图像的显示监视器,所述处理器,使所述投影部投影所述第1虚拟图像;使所述显示监视器显示所述第2虚拟图像。
据此,处理器使投影部投影第1虚拟图像,使显示监视器显示第2虚拟图像,因此能够真实地表现第1虚拟图像或者第2虚拟图像。
另外,本公开涉及的图像处理装置是搭载于移动体的图像处理装置,具备具有硬件的处理器,所述处理器,在佩戴能够与该处理器通信的第1可穿戴设备的第1佩戴者和佩戴能够与该处理器通信的第2可穿戴设备的第2佩戴者中的某一方的佩戴者搭乘所述移动体、另一方的佩戴者虚拟地搭乘所述移动体的情况下,生成以一方的佩戴者的视角观察另一方的佩戴者虚拟地搭乘在移动体内的状态所得的第1虚拟图像,该第1虚拟图像反映出所述另一方的佩戴者的行为;将所述第1虚拟图像向所述一方的佩戴者佩戴的可穿戴设备输出。
另外,本公开涉及的图像处理装置是能够供搭乘移动体的第1佩戴者佩戴的第1可穿戴设备所具备的图像处理装置,具备:具有硬件的处理器;以及能够向所述第1佩戴者投影图像的投影部,所述处理器,在所述第1佩戴者搭乘所述移动体、佩戴第2可穿戴设备的第2佩戴者虚拟地搭乘所述移动体的情况下,生成以所述第1佩戴者的视角观察所述第2佩戴者虚拟地搭乘在所述移动体内的状态所得的第1虚拟图像,该第1虚拟图像反映出所述第2佩戴者的行为;使所述投影部投影所述第1虚拟图像。
另外,本公开涉及的图像处理装置是能够供虚拟地搭乘移动体的第2佩戴者佩戴的第2可穿戴设备所具备的图像处理装置,具备:具有硬件的处理器;以及能够显示图像的显示监视器,所述处理器,生成以第2佩戴者的视角观察第1佩戴者搭乘在所述移动体内的状态所得的第2虚拟图像,该第2虚拟图像反映出所述第1佩戴者的行为并且虚拟地表示出所述移动体的外部空间;使所述显示监视器显示所述第2虚拟图像。
另外,本公开涉及的图像处理装置具备具有硬件的处理器,所述处理器,在佩戴能够与该处理器通信的第1可穿戴设备的第1佩戴者和佩戴能够与该处理器通信的第2可穿戴设备的第2佩戴者中的某一方的佩戴者搭乘移动体、另一方的佩戴者虚拟地搭乘所述移动体的情况下,生成以所述另一方的佩戴者的视角观察所述一方的佩戴者搭乘于所述移动体内的状态所得的第2虚拟图像,该第2虚拟图像反映出所述一方的佩戴者的行为并且虚拟地表示出所述移动体的外部空间;将所述第2虚拟图像向所述另一方的佩戴者佩戴的可穿戴设备输出。
另外,本公开涉及的显示系统具备:移动体;能够供搭乘所述移动体的第1佩戴者佩戴的第1可穿戴设备;能够供虚拟地搭乘所述移动体的第2佩戴者佩戴的第2可穿戴设备;以及能够与所述移动体、所述第1可穿戴设备和所述第2可穿戴设备中的每一个进行通信的服务器,所述服务器具备具有硬件的处理器,所述处理器,在所述第1佩戴者和所述第2佩戴者中的某一方的佩戴者搭乘所述移动体、另一方的佩戴者虚拟地搭乘所述移动体的情况下,生成第1虚拟图像和第2虚拟图像,所述第1虚拟图像是以所述一方的佩戴者的视角观察所述另一方的佩戴者虚拟地搭乘在所述移动体内的状态所得的虚拟图像,是反映出所述另一方的佩戴者的行为的虚拟图像,所述第2虚拟图像是以所述另一方的佩戴者的视角观察所述一方的佩戴者搭乘于所述移动体内的状态所得的虚拟图像,是反映出所述一方的佩戴者的行为并且虚拟地表示出所述移动体的外部空间的虚拟图像;将所述第1虚拟图像向所述一方的佩戴者佩戴的可穿戴设备输出;将所述第2虚拟图像向所述另一方的佩戴者佩戴的可穿戴设备输出。
另外,本公开涉及的程序是使具备具有硬件的处理器的图像处理装置执行的程序,其使所述处理器,在佩戴能够与该处理器通信的第1可穿戴设备的第1佩戴者和佩戴能够与该处理器通信的第2可穿戴设备的第2佩戴者中的某一方的佩戴者搭乘移动体、另一方的佩戴者虚拟地搭乘所述移动体的情况下,生成以所述一方的佩戴者的视角观察所述另一方的佩戴者虚拟地搭乘在所述移动体内的状态所得的第1虚拟图像,该第1虚拟图像反映出所述另一方的佩戴者的行为;将所述第1虚拟图像向所述一方的佩戴者佩戴的可穿戴设备输出。
另外,本公开涉及的程序是使具备具有硬件的处理器的图像处理装置执行的程序,其使所述处理器,在佩戴能够与该处理器通信的第1可穿戴设备的第1佩戴者和佩戴能够与该处理器通信的第2可穿戴设备的第2佩戴者中的某一方的佩戴者搭乘移动体、另一方的佩戴者虚拟地搭乘所述移动体的情况下,生成以所述另一方的佩戴者的视角观察所述一方的佩戴者搭乘于所述移动体内的状态所得的第2虚拟图像,该第2虚拟图像反映出所述一方的佩戴者的行为并且虚拟地表示出所述移动体的外部空间;将所述第2虚拟图像向所述另一方的佩戴者佩戴的可穿戴设备输出。
另外,本公开涉及的图像处理方法是具备具有硬件的处理器的图像处理装置执行的图像处理方法,包括:在佩戴能够与所述处理器通信的第1可穿戴设备的第1佩戴者和佩戴能够与所述处理器通信的第2可穿戴设备的第2佩戴者中的某一方的佩戴者搭乘移动体、另一方的佩戴者虚拟地搭乘所述移动体的情况下,生成以所述一方的佩戴者的视角观察所述另一方的佩戴者虚拟地搭乘在所述移动体内的状态所得的第1虚拟图像,该第1虚拟图像反映出所述另一方的佩戴者的行为;将所述第1虚拟图像向所述一方的佩戴者佩戴的可穿戴设备输出。
另外,本公开涉及的图像处理方法是具备具有硬件的处理器的图像处理装置执行的图像处理方法,包括:在佩戴能够与该处理器通信的第1可穿戴设备的第1佩戴者和佩戴能够与该处理器通信的第2可穿戴设备的第2佩戴者中的某一方的佩戴者搭乘移动体、另一方的佩戴者虚拟地搭乘所述移动体的情况下,生成以所述另一方的佩戴者的视角观察所述一方的佩戴者搭乘于所述移动体内的状态所得的第2虚拟图像,该第2虚拟图像反映出所述一方的佩戴者的行为并且虚拟地表示出所述移动体的外部空间;将所述第2虚拟图像向所述另一方的佩戴者佩戴的可穿戴设备输出。
发明效果
根据本公开,在佩戴第2可穿戴设备的第2佩戴者虚拟地搭乘移动体的情况下,处理器生成以第1佩戴者的视角观察第2佩戴者虚拟地搭乘在移动体内的状态所得的、反映出第2佩戴者的行为的第1虚拟图像,并将该第1虚拟图像向第1可穿戴设备输出,因此取得能够使在用户彼此之间获得一体感这一效果。
附图说明
图1是表示实施方式1涉及的显示系统的概略构成的示意图。
图2是表示实施方式1涉及的驾驶辅助装置的功能结构的框图。
图3是表示实施方式1涉及的第1可穿戴设备的概略构成的图。
图4是表示实施方式1涉及的第1可穿戴设备的功能结构的框图。
图5是表示实施方式1涉及的第2可穿戴设备的概略构成的图。
图6是表示实施方式1涉及的第2可穿戴设备的功能结构的框图。
图7是表示实施方式1涉及的服务器的功能结构的框图。
图8是表示实施方式1涉及的服务器所执行的处理的概要的流程图。
图9是示意性地表示实施方式1涉及的生成部所生成的第1虚拟图像的一例的图。
图10是示意性地表示实施方式1涉及的生成部所生成的第2虚拟图像的一例的图。
图11是示意性地表示实施方式1涉及的生成部所生成的第2虚拟图像的另一例的图。
图12是示意性地表示实施方式1涉及的生成部所生成的第2虚拟图像的另一例的图。
图13是示意性地表示实施方式1涉及的生成部所生成的第2虚拟图像的另一例的图。
图14是示意性地表示实施方式1涉及的生成部所生成的第2虚拟图像的另一例的图。
图15是表示实施方式2涉及的服务器的功能结构的框图。
图16是表示实施方式2涉及的服务器所执行的处理的概要的流程图。
图17是示意性地表示实施方式2涉及的生成部所生成的第3虚拟图像的一例的图。
图18是表示实施方式3涉及的服务器所执行的处理的概要的流程图。
图19是示意性地表示目的地相同的多个移动体的当前位置的图。
图20是表示实施方式4涉及的服务器所执行的处理的概要的流程图。
图21是示意性地表示排头车辆和与排头车辆连结的连结车辆的状况的图。
图22是表示实施方式5涉及的驾驶辅助装置的功能结构的框图。
图23是表示实施方式6涉及的第1可穿戴设备的功能结构的框图。
图24是表示其他实施方式涉及的可穿戴设备的概略构成的图。
图25是表示其他实施方式涉及的可穿戴设备的概略构成的图。
图26是表示其他实施方式涉及的可穿戴设备的概略构成的图。
图27是表示其他实施方式涉及的可穿戴设备的概略构成的图。
标号说明
1显示系统;2、2A、2B移动体;2E排头车辆;2F连结车辆;10、10A驾驶辅助装置;11、31、41拍摄装置;12、33、45视线传感器;16、43语音输入装置;17汽车导航(仪);18、37、48、51通信部;19、19A ECU(电子控制单元);30、30A第1可穿戴设备;32、42行为传感器;34投影部;35GPS传感器;36、46佩戴传感器;38、38A第1控制部;39镜片部;40第2可穿戴设备;44、173a显示部;47操作部;49第2控制部;50、50A服务器;52、172地图数据库;53用户信息数据库;54行动历史记录信息数据库;55地标信息数据库;56记录部;57、57A服务器控制部;60网络;100A、100B、100C、100D可穿戴设备;561程序记录部;571取得部;572判定部;573生成部;574输出控制部;575决定部;U1驾驶员(第1佩戴者);U2同乘者(第2佩戴者);U100使用者。
具体实施方式
以下,基于附图,对本公开的实施方式进行详细说明。此外,本公开并非由以下的实施方式限定。另外,以下对同一部分赋予同一标号进行说明。
(实施方式1)
〔显示系统的构成〕
图1是表示实施方式1涉及的显示系统的概略构成的示意图。图1所示的显示系统1具备搭载于移动体2的驾驶辅助装置10、第1佩戴者U1所佩戴的第1可穿戴设备30、和第2佩戴者U2所佩戴的第2可穿戴设备40。再者,显示系统1还具备服务器50,服务器50经由网络60与驾驶辅助装置10、第1可穿戴设备30和第2可穿戴设备40中的每一个进行通信。
此外,在以下的说明中,作为移动体2,以汽车为例进行说明,但不限定于此,也可以是摩托车、无人机、飞机、船舶以及火车等。再者,以下,将第1佩戴者U1作为搭乘移动体2而驾驶移动体2的驾驶员(以下称为“驾驶员U1”)、将第2佩戴者U2作为使用第2可穿戴设备40而虚拟地搭乘移动体2的同乘者(以下称为“同乘者U2”)来说明。
〔驾驶辅助装置的构成〕
首先,对驾驶辅助装置10的功能结构进行说明。图2是表示驾驶辅助装置10的功能结构的框图。
图2所示的驾驶辅助装置10搭载于移动体2,与搭载于该移动体2的其他ECU(Electronic Control Unit)协同工作,并且辅助移动体2内的驾驶员进行驾驶时的操作。驾驶辅助装置10具备拍摄装置11、视线传感器12、车速传感器13、开关(open/close)传感器14、座椅(seat)传感器15、语音输入装置16、汽车导航17、通信部18以及ECU19。
在移动体2的外部设置有多个拍摄装置11。例如,至少在移动体2的前方、后方和两侧方这4处设置拍摄装置11以使得拍摄视场角成为360°。再者,在移动体2的内部设置有多个拍摄装置11。在ECU19的控制下,拍摄装置11通过拍摄移动体2的外部空间和内部空间的各空间来生成映现外部空间和内部空间的图像数据,并将该图像数据向ECU19输出。拍摄装置11构成为包括光学系统以及CCD(Charge Coupled Device,电荷耦合器件)或者CMOS(Complementary Metal Oxide Semiconductor,互补金属氧化物半导体)等图像传感器,光学系统构成为包括一个或多个透镜,图像传感器通过对该光学系统所成像的被摄体图像进行受光而生成图像数据。
视线传感器12检测包括搭乘于移动体2的驾驶员U1的视线和视网膜的视线信息,将该检测出的视线信息向ECU19输出。视线传感器12构成为包括光学系统、CCD或者CMOS、存储器以及具有CPU(Central Processingd Unit,中央处理单元)和/或GPU(GraphicsProcessing Unit,图形处理单元)等硬件的处理器。视线传感器12例如使用周知的模板匹配(Template Matching),检测驾驶员U1的眼睛的不动的部分(例如内眼角)作为基准点,并且检测眼睛的活动的部分(例如虹膜)作为动点。而且,视线传感器12基于基准点与动点的位置关系,检测驾驶员U1的视线,并将该检测结果向ECU19输出。再者,视线传感器12还检测驾驶员U1的视网膜,并将该检测结果向ECU19输出。
此外,在实施方式1中,由可见光摄像头(camera)构成视线传感器12而检测驾驶员U1的视线,但无需限定于此,也可以利用红外摄像头检测驾驶员U1的视线。在由红外摄像头构成视线传感器12的情况下,由红外LED(Light Emitting Diode)等对驾驶员U1照射红外光,从通过由红外摄像头拍摄驾驶员U1所生成的图像数据检测基准点(例如角膜反射)以及动点(例如瞳孔),并基于该基准点与动点的位置关系,检测驾驶员U1的视线。
车速传感器13检测移动体2在行驶时的车速,并将该检测结果向ECU19输出。
开关传感器14检测使用者进出的门的开关,并将该检测结果向ECU19输出。开关传感器14例如构成为包括按键开关(push switch)等。
座椅传感器15检测相对于各座位的就座的状态,并将该检测结果向ECU19输出。座椅传感器15构成为包括配置在设置于移动体2的各座位的座面下面的荷重检测装置或者压力传感器等。
语音输入装置16受理驾驶员U1的语音的输入,将与受理到的语音相应的语音数据向ECU19输出。语音输入装置16构成为包括麦克风、将该麦克风受理到的语音转换为语音数据的A/D转换电路以及将语音数据放大(增幅)的放大电路。
汽车导航17具有GPS(Global Positioning System)传感器171、地图数据库172以及报知装置173。
GPS传感器171接收来自多个GPS卫星和发送天线的信号,基于接收到的信号计算移动体2的位置。GPS传感器171构成为包括GPS接收传感器等。此外,也可以通过搭载多个GPS传感器171来谋求提高移动体2的定位精度。
地图数据库172存储各种地图数据。地图数据库172使用HDD(Hard Disk Drive,硬盘驱动器)、SSD(Solid State Drive,固态硬盘)等记录介质构成。
报知装置173具有显示图像、影像和文字信息的显示部173a以及产生语音、警报等声音的语音输出部173b。显示部173a构成为包括液晶、有机EL等的显示器。语音输出部173b构成为包括扬声器等。
这样构成的汽车导航17通过将由GPS传感器171取得的移动体2的当前位置与地图数据库172存储的地图数据重叠,利用显示部173a和语音输出部173b将包含移动体2当前正在行驶的道路以及到目的地的路径等的信息报知给驾驶员U1。
通信部18在ECU19的控制下,遵照预定的通信标准,与各种设备进行通信。具体而言,在ECU19的控制下,通信部18向搭乘于移动体2的驾驶员U1所佩戴的第1可穿戴设备30或者其他移动体2发送各种信息,并且从第1可穿戴设备30或者其他移动体2接收各种信息。在此,所谓预定的通信标准,例如是4G、5G、Wi-Fi(Wireless Fidelity)(注册商标)和Bluetooth(注册商标)中的任一方。通信部18构成为包括能够进行无线通信的通信模块。
ECU19对构成驾驶辅助装置10的各部分的工作(动作)进行控制。ECU19构成为包括存储器以及具有CPU等硬件的处理器。
〔第1可穿戴设备的构成〕
接着,对第1可穿戴设备30的构成进行说明。图3是表示第1可穿戴设备30的概略构成的图。图4是表示第1可穿戴设备30的功能结构的框图。
图3以及图4所示的第1可穿戴设备30是用于进行所谓的AR(Augmented Reality,增强现实)的AR眼镜,在驾驶员U1的视野范围内虚拟地显示图像、影像以及文字信息等。第1可穿戴设备30具备拍摄装置31、行为传感器32、视线传感器33、投影部34、GPS传感器35、佩戴传感器36、通信部37以及第1控制部38。
如图3所示,多个拍摄装置31设置于第1可穿戴设备30。在第1控制部38的控制下,拍摄装置31通过拍摄驾驶员U1的视线的前方而生成图像数据,并将该图像数据向第1控制部38输出。拍摄装置31构成为包括由一个或多个透镜构成的光学系统以及CCD和/或CMOS等图像传感器。
行为传感器32检测与佩戴了第1可穿戴设备30的驾驶员U1的行为有关的行为信息,并将该检测结果向第1控制部38输出。具体而言,行为传感器32检测第1可穿戴设备30上产生的角速度和加速度作为行为信息,并将该检测结果向第1控制部38输出。再者,行为传感器32还通过检测地磁而检测绝对方向作为行为信息,并将该检测结果向第1控制部38输出。行为传感器32构成为包括三轴陀螺仪传感器、三轴加速度传感器以及三轴地磁传感器(电子罗盘)。
视线传感器33检测佩戴了第1可穿戴设备30的驾驶员U1的视线的方向,并将该检测结果向第1控制部38输出。视线传感器33构成为包括光学系统、CCD或者CMOS等图像传感器、存储器以及具有CPU等硬件的处理器。视线传感器33例如使用周知的模板匹配,检测驾驶员U1的眼睛的不动的部分(例如内眼角)作为基准点,并且检测眼睛的活动的部分(例如虹膜)作为动点。而且,视线传感器33基于基准点与动点的位置关系,检测驾驶员U1的视线的方向。
投影部34在第1控制部38的控制下,将图像、影像以及文字信息向佩戴了第1可穿戴设备30的驾驶员U1的视网膜进行投影。投影部34构成为包括照射RGB的各色的激光的RGB激光束发射器、反射激光的MEMS镜、和将从MEMS镜反射了的激光向驾驶员U1的视网膜投影的反射镜等。此外,投影部34也可以是在第1控制部38的控制下通过将图像、影像以及文字信息投影到第1可穿戴设备30的镜片部39从而进行显示的单元。
GPS传感器35接收来自多个GPS卫星的信号,基于接收到的信号计算与第1可穿戴设备30的位置有关的位置信息,并将计算出的位置信息向第1控制部38输出。GPS传感器35构成为包括GPS接收传感器等。
佩戴传感器36检测驾驶员U1的佩戴状态,并将该检测结果向第1控制部38输出。佩戴传感器36构成为包括检测驾驶员U1佩戴了第1可穿戴设备30时的压力的压力传感器、和检测驾驶员U1的体温、脉搏、脑电波、血压以及发汗状态等生命体征信息的生命体征传感器等。
通信部37在第1控制部38的控制下,经由网络60,遵照预定的通信标准而向驾驶辅助装置10或者服务器50发送各种信息,并且从驾驶辅助装置10或者服务器50接收各种信息。通信部37构成为包括能够进行无线通信的通信模块。
第1控制部38对构成第1可穿戴设备30的各部分的工作进行控制。第1控制部38构成为包括存储器以及具有CPU等硬件的处理器。第1控制部38基于视线传感器33检测出的驾驶员U1的视线信息以及行为传感器32检测出的行为信息,使投影部34在驾驶员U1的视野范围内输出经由网络60从后述的服务器50输入的第1虚拟图像。此外,关于第1虚拟图像的详情,将会在后面进行说明。
〔第2可穿戴设备的构成〕
接着,对第2可穿戴设备40的构成进行说明。图5是表示第2可穿戴设备40的概略构成的图。图6是表示第2可穿戴设备40的功能结构的框图。
图5以及图6所示的第2可穿戴设备40是用于所谓的MR(Mixed Reality,混合现实)或者VR(Virtual Reality,虚拟现实)的HMD(Head Mounted Display,头戴式显示器)。第2可穿戴设备40向同乘者U2显示对虚拟世界(数字空间)重叠现实世界而得到的能够立体观测的图像、影像以及文字信息等。第2可穿戴设备40具备拍摄装置41、行为传感器42、语音输入装置43、显示部44、视线传感器45、佩戴传感器46、操作部47、通信部48以及第2控制部49。
如图5所示,多个拍摄装置41设置于第2可穿戴设备40。在第2控制部49的控制下,拍摄装置41通过拍摄同乘者U2的视线的前方而生成具有视差的两个图像数据,并将该图像数据向第2控制部49输出。拍摄装置41构成为包括由一个或多个透镜构成的光学系统以及CCD和/或CMOS等图像传感器。
行为传感器42检测与佩戴了第2可穿戴设备40的同乘者U2的行为有关的行为信息,并将该检测结果向第2控制部49输出。具体而言,行为传感器42检测第2可穿戴设备40上产生的角速度和加速度作为行为信息,并将该检测结果向第2控制部49输出。再者,行为传感器42还通过检测地磁而检测绝对方向作为行为信息,并将该检测结果向第2控制部49输出。行为传感器42构成为包括三轴陀螺仪传感器、三轴加速度传感器以及三轴地磁传感器。
语音输入装置43受理同乘者U2的语音的输入,将与受理到的语音相应的语音数据向第2控制部49输出。语音输入装置43构成为包括麦克风、将该麦克风受理到的语音转换为语音数据的A/D转换电路以及将语音数据放大的放大电路。
显示部44在第2控制部49的控制下,显示可立体观测的图像、影像以及文字信息等。显示部44构成为包括具有预定的视差的左右一对显示面板等。作为显示面板,使用液晶或者有机EL(Electro Luminescence,电致发光)等的面板构成。
视线传感器45检测作为第2可穿戴设备40的佩戴者的同乘者U2的视线的方向,并将该检测结果向第2控制部49输出。视线传感器45构成为包括光学系统、CCD或者CMOS等图像传感器、存储器以及具有CPU等硬件的处理器。视线传感器45例如使用周知的模板匹配,检测同乘者U2的眼睛的不动的部分作为基准点,并且检测眼睛的活动的部分作为动点。而且,视线传感器45基于基准点与动点的位置关系,检测同乘者U2的视线的方向。
佩戴传感器46检测同乘者U2的佩戴状态,并将该检测结果向第2控制部49输出。佩戴传感器46构成为包括压力传感器、和检测用户的体温、脉搏、脑电波、血压以及发汗状态等生命体征信息的生命体征传感器等。
操作部47受理同乘者U2的操作输入,并将与受理到的操作相应的信号向第2控制部49输出。操作部47构成为包括按钮(button)、开关(switch)、飞梭旋钮(jog dial)、触摸面板等。
通信部48在第2控制部49的控制下,经由网络60,遵照预定的通信标准而向服务器50发送各种信息,并且从服务器50接收各种信息。通信部48构成为包括能够进行无线通信的通信模块。
第2控制部49对构成第2可穿戴设备40的各部分的工作进行控制。第2控制部49构成为包括存储器以及具有CPU等硬件的处理器。第2控制部49使显示部44显示经由网络60从后述的服务器50输入的第2虚拟图像。此外,关于第2虚拟图像的详情,将会在后面进行说明。
〔服务器的构成〕
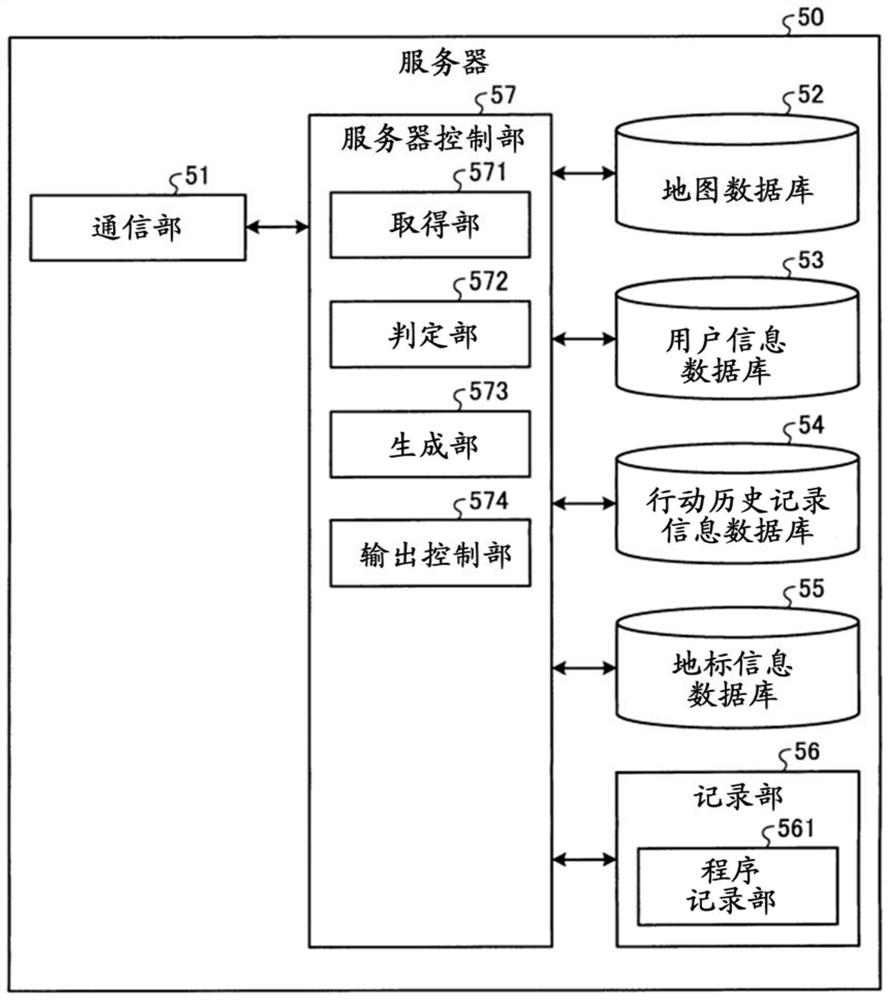
接着,对服务器50的构成进行说明。图7是表示服务器50的功能结构的框图。
图7所示的服务器50具备通信部51、地图数据库52(以下称为“地图DB52”)、用户信息数据库53(以下称为“用户信息DB53”)、行动历史记录信息数据库54(以下称为“行动历史记录信息DB54”)、地标信息数据库55(以下称为“地标信息DB55”)、记录部56以及服务器控制部57。
通信部51在服务器控制部57的控制下,经由网络60,遵照预定的通信标准而与驾驶辅助装置10、第1可穿戴设备30以及第2可穿戴设备40双方向地进行通信。通信部51构成为包括能够进行通信的通信模块等。
地图DB52记录多个地图数据。地图DB52使用HDD或SSD等构成。
用户信息DB53将用于识别多个佩戴者中的每一个的识别信息、多个佩戴者中的每一个的生物体信息、和与多个佩戴者中的每一个关联的虚拟形象图像或者全息图图像相关联地进行记录。具体而言,用户信息DB53将用于识别移动体2的驾驶员U1的第1识别信息、驾驶员U1的生物体信息、和与驾驶员U1的第1识别信息关联的虚拟形象图像或者全息图图像相关联地进行记录。在此,生物体信息指的是虹膜、声纹以及指纹。用户信息DB53使用HDD或SSD等构成。另外,用户信息DB53将用于识别同乘者U2的第2识别信息、同乘者U2的生物体信息、和与同乘者U2的第2识别信息关联的虚拟形象图像或者全息图图像相关联地进行记录。
行动历史记录信息DB54记录行动历史记录信息,行动历史记录信息是将与第1识别信息关联的驾驶员U1的行动历史记录、与同乘者U2的识别信息关联的行动历史记录、和拍摄驾驶员U1以及同乘者U2各自在过去到访的地方所得到的拍摄图像或者视频相关联得到的信息。行动历史记录信息DB54使用HDD或SSD等构成。
地标信息DB55将地图、表示多个地标中的每一个在地图上的位置及名称的地标位置信息、和多个地标中的每一个的当前及过去中的至少一方的地标图像相关联地进行记录。地标信息DB55使用HDD或SSD等构成。
记录部56使用易失性存储器和非易失性存储器等构成。记录部56具有程序记录部561,程序记录部561记录服务器50执行的各种程序。
服务器控制部57构成为包括存储器以及具有CPU等硬件的处理器。服务器控制部57控制构成服务器50的各部分。服务器控制部57具有取得部571、判定部572、生成部573以及输出控制部574。此外,在实施方式1中,服务器控制部57作为图像处理装置而发挥功能。
取得部571经由通信部51以及网络60,从移动体2的驾驶辅助装置10、第1可穿戴设备30以及第2可穿戴设备40中的每一个取得各种信息。具体而言,取得部571取得驾驶员U1和同乘者U2各自的行为信息、生命体征信息、驾驶员U1的第1识别信息以及同乘者U2的第2识别信息。
判定部572基于取得部571取得的驾驶员U1的行为信息,判定驾驶员U1在移动体2内是否朝着同乘者U2虚拟地就座的方向。另外,判定部572判定是否从驾驶辅助装置10的语音输入装置16以及第2可穿戴设备40的语音输入装置43中的至少一方输入了语音数据。
生成部573使用取得部571所取得的移动体2的空间信息、和由第1可穿戴设备30的视线传感器33检测出的驾驶员U1的视线信息,生成第1虚拟图像,第1虚拟图像是以驾驶员U1的视角观察同乘者U2虚拟地搭乘于移动体2的状态所得的虚拟图像,是反映出同乘者U2的行为的虚拟图像。另外,生成部573使用取得部571所取得的移动体2的空间信息、和由第2可穿戴设备40的视线传感器45检测出的同乘者U2的视线信息,生成第2虚拟图像,第2虚拟图像是以同乘者U2的视角观察驾驶员U1搭乘于移动体2内的状态所得的虚拟图像,是反映出驾驶员U1的行为并且虚拟地表示出移动体2的外部空间的虚拟图像。此外,生成部573所生成的第1虚拟图像以及第2虚拟图像的详情后述。
输出控制部574经由网络60以及通信部51将由生成部573所生成的第1虚拟图像向第1可穿戴设备30输出。再者,输出控制部574经由网络60以及通信部51将由生成部573所生成的第2虚拟图像向第2可穿戴设备40输出。
〔服务器执行的处理〕
接着,对服务器50所执行的处理进行说明。图8是表示服务器50所执行的处理的概要的流程图。
如图8所示,首先,取得部571取得第1可穿戴设备30的位置信息、第2可穿戴设备40的位置信息以及移动体2的位置信息(步骤S101)。
接下来,判定部572基于取得部571取得的第1可穿戴设备30的位置信息以及移动体2的位置信息,判定驾驶员U1是否搭乘于移动体2(步骤S102)。此外,判定部572除了第1可穿戴设备30的位置信息以及移动体2的位置信息以外,也可以基于驾驶辅助装置10的开关传感器14的检测结果以及座椅传感器15的检测结果,判定驾驶员U1是否搭乘于移动体2。在由判定部572判定为驾驶员U1搭乘于移动体2的情况下(步骤S102:是),服务器50移至后述的步骤S103。相对于此,在由判定部572判定为驾驶员U1没有搭乘于移动体2的情况下(步骤S102:否),服务器50结束本处理。
在步骤S103中,判定部572判定是否从第2可穿戴设备40的操作部47输入了同乘者U2请求虚拟地搭乘移动体2的请求信号。在由判定部572判定为从第2可穿戴设备40输入了同乘者U2要虚拟地搭乘移动体2的请求信号的情况下(步骤S103:是),服务器50移至后述的步骤S104。相对于此,在由判定部572判定为没有从第2可穿戴设备40输入同乘者U2要虚拟地搭乘移动体2的请求信号的情况下(步骤S103:否),服务器50结束本处理。
在步骤S104中,取得部571取得与移动体2的内部空间以及外部空间有关的空间信息。具体而言,取得部571经由网络60以及通信部51,取得移动体2的拍摄装置11通过拍摄移动体2的内部所生成的图像数据作为与内部空间有关的空间信息。再者,取得部571取得移动体2的拍摄装置11通过拍摄移动体2的外部空间所生成的图像数据作为与外部空间有关的空间信息。此外,取得部571虽然取得了移动体2的拍摄装置11所生成的图像数据作为与外部空间有关的空间信息,但无需限定于此,例如也可以基于移动体2的位置信息,从地图数据库52记录的地图数据取得移动体2的当前位置的周边的图像数据作为与外部空间有关的空间信息。
接下来,取得部571取得驾驶员U1和同乘者U2各自的行为信息、生命体征信息以及识别信息(步骤S105)。具体而言,取得部571经由网络60以及通信部51取得第1可穿戴设备30的行为传感器32检测出的行为信息和佩戴传感器36检测出的生命体征信息。再者,取得部571取得第1可穿戴设备30的视线传感器33检测出的驾驶员U1的视线信息作为识别驾驶员U1的第1识别信息。另外,取得部571经由网络60以及通信部51取得第2可穿戴设备40的行为传感器42检测出的行为信息和佩戴传感器46检测出的生命体征信息。再者,取得部571取得第2可穿戴设备40的视线传感器45检测出的同乘者的视线信息作为同乘者U2的第2识别信息。
此外,取得部571也可以沿时间序列取得移动体2的拍摄装置11生成的映现驾驶员U1的图像数据。在该情况下,服务器控制部57也可以针对时间序列的图像数据,通过使用周知的光流(optical flow)的物体检测处理、图像处理等来检测驾驶员U1的行为信息。再者,服务器控制部57也可以针对与图像数据对应的图像,使用周知的模板匹配来检测驾驶员U1的面部(人脸),将该面部检测为第1识别信息。
之后,判定部572判定是否从驾驶辅助装置10的语音输入装置16和第2可穿戴设备40的语音输入装置43中的至少一方输入了语音数据(步骤S106)。在由判定部572判定为输入了语音数据的情况下(步骤S106:是),服务器50移至后述的步骤S113。相对于此,在由判定部572判定为没有输入语音数据的情况下(步骤S106:否),服务器50移至后述的步骤S107。
在步骤S107中,判定部572基于取得部571取得的驾驶员U1的行为信息,判定驾驶员U1在移动体2内是否朝着同乘者U2虚拟地就座的方向。在由判定部572判定为驾驶员U1在移动体2内朝着同乘者U2虚拟地就座的方向的情况下(步骤S107:是),服务器50移至后述的步骤S108。相对于此,在由判定部572判定为驾驶员U1在移动体2内没有朝着同乘者U2虚拟地就座的方向的情况下(步骤S107:否),服务器50移至后述的步骤S111。
在步骤S108中,生成部573生成第1虚拟图像以及第2虚拟图像。具体而言,生成部573使用取得部571所取得的空间信息和由第1可穿戴设备30的视线传感器33检测出的作为驾驶员U1的第1识别信息的视线信息,生成以驾驶员U1的视角观察同乘者U2虚拟地搭乘于移动体2的状态所得的、反映出同乘者U2的行为信息的第1虚拟图像。再者,生成部573使用取得部571所取得的空间信息和由第2可穿戴设备40的视线传感器45检测出的作为同乘者U2的第2识别信息的视线信息,生成以同乘者U2的视角观察在移动体2的内部空间搭乘有驾驶员U1的状态所得的、反映出驾驶员U1的行为信息并且虚拟地表示出移动体2的外部空间的第2虚拟图像。在步骤S108之后,服务器50移至后述的步骤S109。
在此,对生成部573生成的第1虚拟图像以及第2虚拟图像的各自的详情进行说明。
首先,对生成部573生成的第1虚拟图像的详情进行说明。图9是示意性地表示生成部573所生成的第1虚拟图像的一例的图。
如图9所示,生成部573从用户信息DB53取得与由取得部571所取得的第2识别信息相应的同乘者U2的虚拟形象图像。而且,生成部573使用虚拟形象图像、在上述的步骤S104中取得部571所取得的空间信息、和由第1可穿戴设备30的视线传感器33检测出的驾驶员U1的视线信息,生成以驾驶员U1的视角观察同乘者U2虚拟地搭乘于移动体2的状态所得的第1虚拟图像P1。在该情况下,生成部573生成反映出取得部571所取得的同乘者U2的行为信息的第1虚拟图像P1。例如,如图9所示,生成部573在由判定部572判定为驾驶员U1面朝着副驾驶位的情况下,生成能够从驾驶员U1的视角虚拟地视觉确认的第1虚拟图像P1。在该情况下,生成部573生成映现作为进一步虚拟地反映出同乘者U2的动作以及表情等行为信息的虚拟形象的同乘者U2的第1虚拟图像P1。此时,生成部573也可以将取得部571所取得的同乘者U2的生命体征信息反映于作为虚拟形象的同乘者U2。例如,生成部573也可以基于同乘者U2的生命体征信息,生成反映出作为虚拟形象的同乘者U2的气色等的第1虚拟图像P1。
接着,对生成部573生成的第2虚拟图像的详情进行说明。图10是示意性地表示生成部573所生成的第2虚拟图像的一例的图。
如图10所示,生成部573从用户信息数据库53取得与由取得部571所取得的第1识别信息相应的驾驶员U1的虚拟形象图像。而且,生成部573使用虚拟形象图像、在上述的步骤S104中取得部571所取得的空间信息、和由第2可穿戴设备40的视线传感器45检测出的同乘者U2的视线信息,生成以同乘者U2的视角观察在移动体2的内部空间搭乘有驾驶员U1的状态所得的、虚拟地表示出移动体2的外部空间的第2虚拟图像P2。在该情况下,生成部573生成反映出取得部571所取得的驾驶员U1的行为信息的第2虚拟图像P2。例如如图10所示,生成部573在由判定部572判定为同乘者U2的面部朝着移动体2的前柱21的情况下,生成作为虚拟形象像的驾驶员U1手握方向盘22的第2虚拟图像P2、即从同乘者U2的视角观察到的第2虚拟图像P2。再者,在第2虚拟图像P2中,表示出移动体2的内部空间以及移动体2外面的景色、即外部空间。此外,生成部573也可以将取得部571所取得的驾驶员U1的生命体征信息反映于作为虚拟形象的驾驶员U1。例如,生成部573也可以基于驾驶员U1的生命体征信息,生成反映出作为虚拟形象的驾驶员U1的气色等的第2虚拟图像P2。
另外,生成部573也可以使用取得部571从行动历史记录信息DB54取得的基于移动体2的位置信息、第1识别信息以及第2识别信息的行动历史记录信息,生成第1虚拟图像以及第2虚拟图像。
图11是示意性地表示生成部573所生成的第2虚拟图像的另一例的图。图12是示意性地表示生成部573所生成的第2虚拟图像的另一例的图。此外,以下对生成部573生成第2虚拟图像的情况进行说明。
如图11所示,生成部573生成使用以下信息表示了移动体2的外部空间的一部分的第2虚拟图像P10:取得部571基于移动体2的位置信息、第1识别信息以及第2识别信息而取得的行动历史记录信息中包含的拍摄驾驶员U1和同乘者U2各自在过去到访过的地方所得到的拍摄图像或者视频;虚拟形象图像;和空间信息。例如,生成部573生成以驾驶员U1和同乘者U2中的一方在过去到访移动体2的当前位置时拍摄到的拍摄图像或者视频表示了移动体2的外部空间的一部分的第2虚拟图像P10。由此,驾驶员U1和同乘者U2能够一边虚拟地一同乘坐移动体2,一边彼此对想起的回忆共享怀念之情并进行交谈。
再者,如图12所示,生成部573也可以生成反映出移动体2周边的当前位置的天气的第2虚拟图像P11。在该情况下,例如如图12所示,生成部573在移动体2周边的天气为下雨的情况下,也可以在将移动体2的外部空间的一部分用驾驶员U1和同乘者U2过去到访时拍摄到的拍摄图像或者视频表示了的区域重叠雨(下雨的动画和/或影像)而生成第2虚拟图像P11。由此,驾驶员U1和同乘者U2能够从将过去到访时的回忆与当前的移动体2周边的实时的状况虚拟地重叠出的状况中得到乐趣,因此,同乘者U2即使没有实际搭乘于移动体2,也能够与驾驶员U1享受实时的兜风(驾车旅行)的乐趣。
此外,在图11以及图12中,生成部573以驾驶员U1和同乘者U2过去到访移动体2的当前位置时拍摄到的拍摄图像或者视频表示了移动体2的外部空间的一部分,但不限定于此。例如,生成部573也可以生成在表示移动体2的当前的外部空间的图像上的一部分显示区域上重叠了驾驶员U1和同乘者U2过去到访移动体2的当前位置时拍摄到的拍摄图像或者视频所得到的第2虚拟图像。
回到图8,继续进行对步骤S109及其之后的说明。
在步骤S109中,输出控制部574经由网络60以及通信部51,将生成部573生成的第1虚拟图像P1向第1可穿戴设备30输出,并且将生成部573生成的第2虚拟图像P2向第2可穿戴设备40输出。由此,即使在驾驶员U1和同乘者U2彼此相距一段距离的情况下,用户彼此之间也能够获得一体感。再者,驾驶员U1和同乘者U2各自即使在同乘者U2无法与驾驶员U1一起通过移动体2进行兜风的状况下也能够一起享受在相同的移动体2内的空间内虚拟的兜风的乐趣。
接下来,在从第1可穿戴设备30或者第2可穿戴设备40输入了指示结束的指示信号的情况下(步骤S110:是),服务器50结束本处理。相对于此,在没有从第1可穿戴设备30或者第2可穿戴设备40输入指示结束的指示信号的情况下(步骤S110:否),服务器50返回至上述的步骤S104。
在步骤S111中,生成部573生成第2虚拟图像。具体而言,生成部573使用在上述的步骤S104中取得部571所取得的空间信息,生成以同乘者U2的视角观察在移动体2的内部空间搭乘有驾驶员U1的状态所得的、虚拟地表示出移动体2的外部空间的第2虚拟图像P2。
接下来,输出控制部574将生成部573生成的第2虚拟图像向第2可穿戴设备40输出(步骤S112)。在步骤S112之后,服务器50移至步骤S110。
在步骤S113中,判定部572基于从驾驶辅助装置10的语音输入装置16输入的语音数据,判定驾驶员U1或者同乘者U2是否说出了地标的名称。具体而言,判定部572通过对从驾驶辅助装置10的语音输入装置16输入的语音数据进行周知的语音解析处理,判定驾驶员U1或者同乘者U2是否说出了地标的名称。在由判定部572判定为驾驶员U1或者同乘者U2说出了地标的名称的情况下(步骤S113:是),服务器50移至后述的步骤S114。相对于此,在由判定部572判定为驾驶员U1或者同乘者U2没有说出地标的名称的情况下(步骤S113:否),服务器50移至步骤S107。
在步骤S114中,取得部571基于移动体2的位置信息以及驾驶员U1或者同乘者U2说出的地标的名称,从地标信息DB55取得当前和过去中的至少一方的地标图像。
接下来,生成部573生成使用当前和过去中的至少一方的地标图像表示了移动体2的外部空间的一部分的第1虚拟图像以及第2虚拟图像(步骤S115)。具体而言,生成部573生成使用取得部571所取得的虚拟形象图像、移动体2的空间信息以及当前和过去中的至少一方的地标图像表示了移动体2的外部空间的一部分的第1虚拟图像以及第2虚拟图像。
图13是示意性地表示生成部573所生成的第2虚拟图像的另一例的图。图14是示意性地表示生成部573所生成的第2虚拟图像的另一例的图。
如图13所示,生成部573使用取得部571所取得的当前和过去中的至少一方的地标图像、移动体2的位置信息、虚拟形象图像以及空间信息,生成在移动体2的外部空间的一部分映现过去的地标M1的第2虚拟图像P12。例如,如图13所示,生成部573生成在移动体2的当前位置的外部空间虚拟地表示了过去的地标M1的第2虚拟图像P12。由此,驾驶员U1和同乘者U2能够一起对彼此想起的地标的回忆共享怀念之情。
此外,如图14所示,生成部573也可以使用取得部571所取得的当前的地标图像、移动体2的位置信息、虚拟形象图像以及空间信息,生成在时间上从过去的地标M1向当前的地标M2变化的第2虚拟图像P13(图13→图14)。由此,驾驶员U1和同乘者U2能够一起对彼此想起的地标的回忆共享怀念之情,还能够就过去到当前的地标M2进行交谈。
回到图8,继续进行对步骤S116及其之后的说明。
在步骤S116中,输出控制部574将生成部573生成的第1虚拟图像向第1可穿戴设备30输出,并且将生成部573生成的第2虚拟图像向第2可穿戴设备40输出。在步骤S116之后,服务器50移至步骤S110。
根据以上说明的实施方式1,输出控制部574将由生成部573生成的以驾驶员U1的视角观察同乘者U2虚拟地搭乘在移动体2内的状态所得的、反映出同乘者U2的行为的第1虚拟图像向第1可穿戴设备30输出,因此,能够使在用户彼此之间获得一体感。
另外,根据实施方式1,输出控制部574将由生成部573生成的以同乘者U2的视角观察驾驶员U1搭乘于移动体2的状态所得的、反映出驾驶员U1的行为并且虚拟地表示出移动体2的外部空间的第2虚拟图像向同乘者U2佩戴的第2可穿戴设备40输出,由此,同乘者U2即使没有实际地一同乘坐于移动体2,也能够虚拟地体验搭乘于移动体2,因此能够使在用户彼此之间获得一体感。
另外,根据实施方式1,在驾驶员U1在移动体2内朝着同乘者U2虚拟地就座的方向的情况下,生成部573生成第1虚拟图像,因此驾驶员U1能够专心驾驶移动体2。
另外,根据实施方式1,生成部573生成使用取得部571基于移动体2的位置信息、第1识别信息和第2识别信息所取得的行动历史记录信息中包含的拍摄驾驶员U1和同乘者U2各自在过去到访的地方所得到的拍摄图像或者视频、虚拟形象图像以及空间信息表示了移动体2的外部空间的一部分的第2虚拟图像,因此,驾驶员U1和同乘者U2能够就各自经历的过去的回忆进行交谈。
另外,根据实施方式1,生成部573生成使用取得部571所取得的虚拟形象图像、移动体2的空间信息以及当前和过去的至少一方的地标图像表示了移动体2的外部空间的一部分的第1虚拟图像以及第2虚拟图像,因此,驾驶员U1和同乘者U2能够就各自经历的过去的回忆进行交谈。
另外,根据实施方式1,生成部573以虚拟形象或者全息图虚拟地表示第1虚拟图像中包含的同乘者U2,以虚拟形象或者全息图虚拟地表示第2虚拟图像中包含的驾驶员U1,所以,即使不是真实的图像,由于显示虚拟形象或者全息图,因此也能够使在用户彼此之间虚拟地获得一体感。
另外,根据实施方式1,生成部573基于由第1可穿戴设备30的行为传感器32以及第2可穿戴设备40的行为传感器42各自检测出的检测结果,生成第1虚拟图像或者第2虚拟图像,因此能够真实地表现驾驶员U1以及同乘者U2的行为。
另外,根据实施方式1,生成部573基于由拍摄装置11生成的图像数据,检测驾驶员U1的行为,并基于该检测结果生成第2虚拟图像,因此能够真实地表现第2虚拟图像中的驾驶员U1的行为。
另外,根据实施方式1,生成部573使用由取得部571作为与移动体2的内部空间以及外部空间有关的空间信息所取得的移动体2的拍摄装置11生成的图像数据,生成第1虚拟图像或者第2虚拟图像,因此能够真实地表现移动体2的内部空间或者外部空间。
此外,在实施方式1中,同乘者U2就座于移动体2的副驾驶位,但无需限定于此,同乘者U2也可以虚拟地就座于所期望的座位。在该情况下,生成部573基于从第2可穿戴设备40的操作部47输入的指定移动体2的座位的指定信号,生成以驾驶员U1的视角观察同乘者U2虚拟地就座于所期望的座位的状态所得的第1虚拟图像即可。
(实施方式2)
接着,对实施方式2进行说明。在上述的实施方式1中,虚拟地搭乘移动体的同乘者为一人,而在实施方式2中,多个同乘者虚拟地搭乘移动体。以下,先对实施方式2涉及的服务器的构成进行说明,之后对服务器所执行的处理进行说明。此外,对于与上述的实施方式1涉及的显示系统1相同的构成赋予同一标号并省略详细的说明。
〔服务器的构成〕
图15是表示实施方式2涉及的服务器的功能结构的框图。图15所示的服务器50A具备服务器控制部57A以取代上述的实施方式1涉及的服务器控制部57。
服务器控制部57A构成为包括存储器以及具有CPU等硬件的处理器。除了上述的实施方式1涉及的服务器控制部57的构成以外,服务器控制部57A还具备决定部575。
决定部575基于从多个第2可穿戴设备40中的每一个发送来的请求信号,从多个同乘者U2中决定代表者。
〔服务器的处理〕
接着,对服务器50A所执行的处理进行说明。图16是表示服务器50A所执行的处理的概要的流程图。
如图16所示,首先,取得部571取得各佩戴者的位置信息以及移动体2的位置信息(步骤S201)。具体而言,取得部571取得第1可穿戴设备30的位置信息、多个同乘者U2的每一个所佩戴的多个第2可穿戴设备40的位置信息以及移动体2的位置信息。
接下来,判定部572基于第1可穿戴设备30的位置信息以及移动体2的位置信息,判定驾驶员U1是否搭乘于移动体2(步骤S202)。在由判定部572判定为驾驶员U1搭乘于移动体2的情况下(步骤S202:是),服务器50A移至后述的步骤S203。相对于此,在由判定部572判定为驾驶员U1没有搭乘于移动体2的情况下(步骤S202:否),服务器50A结束本处理。
在步骤S203中,判定部572判定是否从多个同乘者U2的每一个佩戴的第2可穿戴设备40输入了请求虚拟地搭乘移动体2的请求信号。在此,所谓多个同乘者U2,至少为两人以上。在由判定部572判定为从多个同乘者U2的每一个佩戴的第2可穿戴设备40输入了请求虚拟地搭乘移动体2的请求信号的情况下(步骤S203:是),服务器50A移至后述的步骤S204。相对于此,在由判定部572判定为没有从多个同乘者U2的每一个佩戴的第2可穿戴设备40输入请求虚拟地搭乘移动体2的请求信号的情况下(步骤S203:否),服务器50A结束本处理。
在步骤S204中,判定部572判定是否从多个同乘者U2的每一个佩戴的第2可穿戴设备40输入了决定同乘者U2的代表者的决定信号。在由判定部572判定为输入了决定信号的情况下(步骤S204:是),服务器50A移至后述的步骤S205。相对于此,在由判定部572判定为没有输入决定信号的情况下(步骤S204:否),服务器50A移至后述的步骤S206。
在步骤S205中,基于从多个第2可穿戴设备40的每一个发送来的请求信号,从多个同乘者U2中决定代表者。步骤S205之后,服务器50A移至步骤S208。
在步骤S206中,判定部572判定从经由多个第2可穿戴设备40的每一个输入了请求信号起是否经过了预定时间。例如,判定部572判定从经由多个第2可穿戴设备40的每一个输入了请求信号起是否经过了60秒。在由判定部572判定为经过了预定时间的情况下(步骤S206:是),服务器50A移至后述的步骤S207。相对于此,在由判定部572判定为没有经过预定时间的情况下(步骤S206:否),服务器50A返回至上述的步骤S204。
在步骤S207中,决定部575将多个同乘者U2中的佩戴着最早发送了请求信号的第2可穿戴设备40的同乘者U2决定为代表者。在步骤S207之后,服务器50A移至步骤S208。
接下来,取得部571取得与移动体2的内部空间以及外部空间有关的空间信息(步骤S208)。
之后,取得部571取得驾驶员U1和多个同乘者U2的行为信息、生命体征信息以及识别信息(步骤S209)。此外,取得部571虽然取得了多个同乘者的行为信息、生命体征信息以及识别信息,但也可以仅取得代表者的行为信息、生命体征信息以及识别信息。
接下来,生成部573生成第1虚拟图像(步骤S210)。具体而言,生成部573生成以驾驶员U1的视角观察作为同乘者U2的代表者虚拟地搭乘于移动体2的状态所得的、反映出代表者的行为信息的第1虚拟图像(例如参照上述的图9)。
之后,判定部572判定是否从代表者佩戴的第2可穿戴设备40的操作部47输入了指示生成在各同乘者U2的第2可穿戴设备40中显示的、在驾驶员U1的驾驶操作中关注的关注区域的图像的指示信号(步骤S211)。在由判定部572判定为从代表者佩戴的第2可穿戴设备40输入了指示信号的情况下(步骤S211:是),服务器50A移至后述的步骤S212。相对于此,在由判定部572判定为没有从代表者佩戴的第2可穿戴设备40输入指示信号的情况下(步骤S211:否),服务器50A移至后述的步骤S216。
在步骤S212中,生成部573生成与从代表者佩戴的第2可穿戴设备40的操作部47输入的指示生成在各同乘者U2的第2可穿戴设备40中显示的、在驾驶员U1的驾驶操作中关注的关注区域的图像的指示信号的第3虚拟图像。
图17是示意性地表示生成部573所生成的第3虚拟图像的一例的图。对从代表者佩戴的第2可穿戴设备40的操作部47输入的指示信号指定了驾驶员U1的加速踏板操作作为要关注的关注区域的情况进行说明。在该情况下,如图17所示,生成部573生成关注并放大了由驾驶员U1作出的加速踏板的操作部分的第3虚拟图像P21,第3虚拟图像P21反映出驾驶员U1的操作。由此,各同乘者U2能够实时地虚拟地观察驾驶员U1的操作技术。再者,各同乘者U2还能够模拟地体会驾驶员U1的操作技术。在步骤S212之后,服务器50A移至后述的步骤S213。
回到图16,继续进行对步骤S213及其之后的说明。
在步骤S213中,生成部573使用取得部571所取得的移动体2的空间信息,生成以代表者的视角观察驾驶员U1搭乘于移动体内的状态所得的第2虚拟图像,第2虚拟图像反映出驾驶员U1的行为并且虚拟地表示出移动体2的外部空间。
接下来,输出控制部574将由生成部573生成的第1虚拟图像向驾驶员U1佩戴的第1可穿戴设备30输出,将由生成部573生成的第2虚拟图像向代表者佩戴的第2可穿戴设备40输出,并且将由生成部573生成的第3虚拟图像向除代表者以外的各同乘者U2佩戴的第2可穿戴设备40输出(步骤S214)。此外,输出控制部574虽然将由生成部573生成的第2虚拟图像向代表者佩戴的第2可穿戴设备40进行输出,但也可以取代第2虚拟图像而将由生成部573生成的第3虚拟图像向代表者佩戴的第2可穿戴设备40输出。在该情况下,输出控制部574只要根据从代表者佩戴的第2可穿戴设备40输入的指示信号,将第2虚拟图像和第3虚拟图像中的至少一个向代表者佩戴的第2可穿戴设备40输出即可。
此外,在生成部573生成了与指示生成在驾驶员U1的驾驶操作中关注的关注区域的图像的指示信号相应的第3虚拟图像的情况下,输出控制部574也可以将驾驶员U1以及代表者发出的语音数据向其他同乘者U2佩戴的第2可穿戴设备40输出。再者,输出控制部574也可以针对其他同乘者U2佩戴的第2可穿戴设备40,将驾驶员U1以及代表者发出的语音数据转换为文字数据,将该文字数据重叠于第2虚拟图像,并向各同乘者U2佩戴的第2可穿戴设备40输出。由此,各同乘者U2通过利用文字或者语音确认由代表者对驾驶员U1的操作的解说,从而比仅有图像时更能够掌握驾驶员U1的操作技术。
另外,输出控制部574在除了代表者以及驾驶员U1以外其他同乘者U2发出语音的情况下也可以将与该同乘者U2发出的语音对应的语音数据或者文字数据向各同乘者U2佩戴的第2可穿戴设备40以及驾驶员U1佩戴的第1可穿戴设备30输出。由此,代表者以及各同乘者U2能够一边观察第2虚拟图像,一边对移动体2的操作虚拟地进行提问和回答,因此更能够掌握驾驶员U1的操作内容。
之后,在从搭乘者佩戴的第1可穿戴设备30或者代表者佩戴的第2可穿戴设备40输入了指示结束的指示信号的情况下(步骤S215:是),服务器50A结束本处理。相对于此,在没有从搭乘者佩戴的第1可穿戴设备30或者代表者佩戴的第2可穿戴设备40输入指示结束的指示信号的情况下(步骤S215:否),服务器50A返回至上述的步骤S208。
在步骤S216中,生成部573生成第2虚拟图像(参照上述的图10)。
接下来,输出控制部574将由生成部573生成的第1虚拟图像向驾驶员U1佩戴的第1可穿戴设备30输出,并且将由生成部573生成的第2虚拟图像向代表者及各同乘者U2佩戴的第2可穿戴设备40输出(步骤S217)。
根据以上说明的实施方式2,生成部573基于从第2可穿戴设备40输入的指示生成在驾驶员U1的驾驶操作中关注的关注区域的图像的指示信号、移动体2的内部空间的空间信息以及驾驶员U1的行为,生成第3虚拟图像,并将第3虚拟图像向各同乘者U2佩戴的第2可穿戴设备40输出,因此各同乘者U2能够直观地掌握驾驶员U1的驾驶操作。
另外,根据实施方式2,生成部573生成了以驾驶员U1的视角观察代表者虚拟地搭乘于移动体2的状态所得的第1虚拟图像,因此能够使驾驶员U1与代表者之间获得一体感。
此外,在实施方式2中,生成部573生成了以驾驶员U1的视角观察代表者虚拟地搭乘于移动体2的状态所得的,反映出代表者的行为信息的第1虚拟图像,但无需限定于此,例如,也可以生成多个同乘者U2虚拟地就座于移动体2的第1虚拟图像。在该情况下,生成部573生成多个同乘者的每一个按从多个第2可穿戴设备40的每一个输入的请求信号的先后顺序依次虚拟地就座于副驾驶位至后部座位的第1虚拟图像。由此,能够进一步增强一体感。
(实施方式3)
接着,对实施方式3进行说明。在上述的实施方式1、2中,移动体为一台,而在实施方式3中,在多个移动体的每一个中搭乘有驾驶员。再者,实施方式3涉及的服务器与上述的实施方式1涉及的服务器50具有相同的构成,服务器执行的处理不同。以下,对实施方式3涉及的服务器所执行的处理进行说明。此外,对于与上述的实施方式1涉及的显示系统1相同的构成赋予同一标号并省略详细的说明。
〔服务器的处理〕
图18是表示实施方式3涉及的服务器50所执行的处理的概要的流程图。
如图18所示,首先,取得部571取得各佩戴者的位置信息(步骤S301)。具体而言,取得部571取得第1可穿戴设备30的位置信息、第2可穿戴设备40的位置信息以及多个移动体2的每一个的位置信息(步骤S301)。
接下来,判定部572基于驾驶员U1佩戴的第1可穿戴设备30的位置信息、同乘者U2佩戴的第2可穿戴设备40的位置信息以及多个移动体2的每一个的位置信息,判定驾驶员U1和同乘者U2是否搭乘于互不相同的移动体2(步骤S302)。在由判定部572判定为驾驶员U1和同乘者U2搭乘于互不相同的移动体2的情况下(步骤S302:是),服务器50移至后述的步骤S303。相对于此,在由判定部572判定为驾驶员U1和同乘者U2没有搭乘于互不相同的移动体2的情况下(步骤S302:否),服务器50结束本处理。
在步骤S303中,取得部571取得多个移动体2的每一个由汽车导航17设定的目的地。
接下来,判定部572基于多个移动体2的每一个的目的地,判定是否有多个目的地相同的移动体2(步骤S304)。在由判定部572判定为有多个目的地相同的移动体2的情况下(步骤S304:是),服务器50移至后述的步骤S305。相对于此,在由判定部572判定为没有多个目的地相同的移动体2的情况下(步骤S304:否),服务器50结束本处理。
在步骤S305中,判定部572基于目的地相同的多个移动体2的每一个的位置信息,判定离目的地最近的移动体2。
图19是示意性地表示目的地相同的多个移动体2的当前位置的图。此外,在图19中,将互不相同的两个移动体2记作移动体2A和移动体2B。再者,将移动体2A和移动体2B各自的当前位置到目的地Q1的距离记作D1和D2(距离D1<距离D2)。此外,在图19中,为了简化说明,对两台移动体2进行说明,但无需限定台数,只要为两台以上即可。再者,以下,为了简化说明,设为佩戴第1可穿戴设备30的驾驶员U1搭乘于移动体2A、佩戴第2可穿戴设备40的同乘者U2搭乘于移动体2B来进行说明。
如图19所示,判定部572基于目的地Q1相同的移动体2A和移动体2B的位置信息,判定离目的地Q1最近的移动体2。在图19所示的情况下,判定部572将移动体2A判定为离目的地Q1最近的移动体2。
回到图18,继续进行对步骤S306及其之后的说明。
在步骤S306中,取得部571经由网络60以及通信部51取得离目的地最近的移动体2A的空间信息。
接下来,取得部571从第2可穿戴设备40取得作为目的地相同的同乘者U2的驾驶员的行为信息(步骤S307)。
之后,生成部573生成第1虚拟图像以及第2虚拟图像(步骤S308)。具体而言,生成部573生成以驾驶员U1的视角观察移动体2B的同乘者U2虚拟地搭乘于离目的地最近的移动体2A的状态所得的第1虚拟图像,且第1虚拟图像反映出同乘者U2的行为。再者,生成部573生成以同乘者U2的视角观察驾驶员U1虚拟地搭乘于离目的地最近的移动体2A的状态所得的第2虚拟图像,且第2虚拟图像反映出驾驶员U1的行为信息并且表示了离目的地最近的移动体2A的外部空间。
接下来,输出控制部574将生成部573生成的第1虚拟图像向搭乘于离目的地最近的移动体2A的驾驶员U1佩戴的第1可穿戴设备30输出,并且,将第2虚拟图像向搭乘于目的地相同的移动体2B的同乘者U2佩戴的第2可穿戴设备40输出(步骤S309)。
之后,在所有移动体2到达目的地的情况下(步骤S310:是),服务器50结束本处理。相对于此,在并非所有的移动体2都到达了目的地的情况下(步骤S310:否),服务器50返回至上述的步骤S305。
根据以上说明的实施方式3,输出控制部574在移动体2和其他移动体2各自的目的地相同的情况下,将第1虚拟图像向驾驶员U1佩戴的第1可穿戴设备30输出,并且将第2虚拟图像向搭乘于其他移动体2的同乘者U2佩戴的第2可穿戴设备40输出,因此,即使在移动时是分别的移动体2,也能够一边使在用户彼此之间获得一体感、一边移动。
另外,根据实施方式3,输出控制部574向搭乘于离目的地最近的移动体2的驾驶员U1佩戴的第1可穿戴设备30输出第1虚拟图像,并且向除此以外的同乘者U2佩戴的第2可穿戴设备40输出第2虚拟图像,因此,能够使在用户彼此间共享朝向目的地的虚拟的赛车体验。
此外,在实施方式3中,设为佩戴第1可穿戴设备30的驾驶员U1搭乘于离目的地最近的移动体2A、佩戴第2可穿戴设备40的同乘者U2搭乘于移动体2B,但在根据交通状况而变为移动体2B比移动体2A更接近于目的地的情况下,生成部573也可以生成以同乘者U2的视角观察驾驶员U1虚拟地搭乘于移动体2B的状态所得的第1虚拟图像,并且生成以驾驶员U1的视角观察同乘者U2搭乘于移动体2B的状态所得的第2虚拟图像。在该情况下,输出控制部574将第1虚拟图像向第2可穿戴设备40输出,将第2虚拟图像向第1可穿戴设备30输出。由此,能够使用户彼此间共享朝向目的地的虚拟的赛车体验。
(实施方式4)
接着,对实施方式4进行说明。在上述的实施方式3中,多个移动体各自从互不相同的地方向目的地移动,而在实施方式4中,多个移动体通过连结而进行移动。另外,实施方式4涉及的服务器与上述的实施方式1涉及的服务器50具有相同的构成,执行的处理不同。以下,对实施方式4涉及的服务器所执行的处理进行说明。此外,对于与上述的实施方式1涉及的显示系统1相同的构成赋予同一标号并省略详细的说明。
〔服务器的处理〕
图20是表示实施方式4涉及的服务器50所执行的处理的概要的流程图。
如图20所示,首先,判定部572经由网络60以及通信部51,判定是否有其他移动体2(以下称为“连结车辆”)连结于搭乘者搭乘的移动体2(步骤S401)。在由判定部572判定为连结车辆连结于移动体2的情况下(步骤S401:是),服务器50移至后述的步骤S402。相对于此,在由判定部572判定为没有连结车辆连结于移动体2的情况下(步骤S401:否),服务器50结束本处理。
图21是示意性地表示移动体2和与移动体2连结的连结车辆的状况的图。此外,在图21中,将排头的移动体2记作排头车辆2E,将与排头车辆2E连结的移动体2记作连结车辆2F。此外,以下设为佩戴第1可穿戴设备30的驾驶员U1搭乘于排头车辆2E、佩戴第2可穿戴设备40的同乘者U2搭乘于连结车辆2F来进行说明。
如图21所示,判定部572经由网络60以及通信部51,判定是否从排头车辆2E输入了表示排头车辆2E通过与连结车辆2F进行车车间通信而对排头车辆2E连结了连结车辆2F这一情况的信息。此外,判定部572也可以经由网络60以及通信部51,基于排头车辆2E的位置信息和连结车辆2F的位置信息,判定排头车辆2E与连结车辆2F是否进行了连结。
回到图20,继续进行对步骤S402及其之后的说明。
在步骤S402中,取得部571取得队列的排头即排头车辆2E的空间信息。
接下来,取得部571从搭乘于排头车辆2E和连结车辆2F的各车辆的搭乘者佩戴的可穿戴设备取得各搭乘者的行为信息(步骤S403)。
之后,生成部573生成第1虚拟图像以及第2虚拟图像(步骤S404)。具体而言,生成部573生成以驾驶员U1的视角观察连结车辆2F的同乘者U2虚拟地搭乘于排头车辆2E的状态所得的第1虚拟图像,且第1虚拟图像反映出连结车辆2F的同乘者U2的行为。再者,生成部573生成以同乘者U2的视角观察排头车辆2E的驾驶员U1搭乘于排头车辆2E的状态所得的第2虚拟图像,且第2虚拟图像反映出驾驶员U1的行为并且虚拟地表示出排头车辆2E的外部空间。
接下来,输出控制部574经由网络60以及通信部51,向排头车辆2E的驾驶员U1佩戴的第1可穿戴设备30输出第1虚拟图像(步骤S405),向连结车辆2F的同乘者U2佩戴的第2可穿戴设备40输出第2虚拟图像(步骤S406)。
之后,在通过将连结于排头车辆2E的连结车辆2F分离开(断开连接)而结束的情况下(步骤S407:是),服务器50结束本处理。相对于此,在连结于排头车辆2E的连结车辆2F没有分离开的情况下(步骤S407:否),服务器50返回至上述的步骤S401。
根据以上说明的实施方式4,在由判定部572判定为排头车辆2E连结有连结车辆2F的情况下,输出控制部574将由生成部573生成的第2虚拟图像向搭乘与排头车辆2E连结的连结车辆2F的同乘者U2佩戴的第2可穿戴设备40输出,将第1虚拟图像向搭乘排头车辆2E的驾驶员U1佩戴的第1可穿戴设备30输出,所以,搭乘于排头车辆2E的驾驶员U1能够一边作为带路人对搭乘连结车辆2F的同乘者U2进行引导一边移动,因此能够使在用户彼此之间获得一体感。
此外,在实施方式4中,由判定部572判定了排头车辆2E与连结车辆2F是否被连结,但不需要排头车辆2E与连结车辆2F在物理上相连结,例如也可以判定排头车辆2E和连结车辆2F是否保持着一定的距离而在进行队列行驶。即,判定部572也可以判定排头车辆2E和连结车辆2F是否保持着一定的距离在进行队列行驶。在该情况下,判定部572也可以经由网络60以及通信部51,基于排头车辆2E的位置信息以及目的地、和连结车辆2F的位置信息以及目的地,判定排头车辆2E和连结车辆2F是否在进行队列行驶。具体而言,判定部572在排头车辆2E和连结车辆2F的目的地相同、且基于排头车辆2E的位置信息和连结车辆2F的位置信息的距离为一定的距离的情况下,判定为排头车辆2E和连结车辆2F在进行队列行驶。例如,判定部572在排头车辆2E和连结车辆2F的目的地相同、且排头车辆2E和连结车辆2F各自在以60千米每小时的速度行驶的情况下,当排头车辆2E与连结车辆2F的距离在45千米以内时,判定为排头车辆2E和连结车辆2F在进行队列行驶。当然,判定部572也可以判定是否从排头车辆2E输入了表示排头车辆2E与连结车辆2F进行车车间通信从而排头车辆2E和连结车辆2F进行队列行驶这一情况的信息。在该情况下,输出控制部574在由判定部572判定为排头车辆2E和连结车辆2F在进行队列行驶时,将由生成部573生成的第2虚拟图像向搭乘于在对排头车辆2E进行跟随行驶的连结车辆2F的同乘者U2佩戴的第2可穿戴设备40输出,将第1虚拟图像向搭乘于排头车辆2E的驾驶员U1佩戴的第1可穿戴设备30输出。由此,即使排头车辆2E和连结车辆2F没有连结,而在进行队列行驶的情况下,搭乘于排头车辆2E的驾驶员U1也能够一边作为带路人对搭乘于连结车辆2F的同乘者U2进行引导一边移动,因此能够使在用户彼此之间获得一体感。
(实施方式5)
接着,对实施方式5进行说明。在上述的实施方式1~4中,服务器的服务器控制部作为图像处理装置而发挥功能,而在实施方式5中,搭载于移动体的驾驶辅助装置作为图像处理装置而发挥功能,向第1可穿戴设备发送第1虚拟图像,以及向第2可穿戴设备发送第2虚拟图像。以下,对实施方式5涉及的驾驶辅助装置的构成进行说明。此外,对于与上述的实施方式1~4涉及的显示系统1相同的构成赋予同一标号并省略详细的说明。
〔驾驶辅助装置的构成〕
图22是表示实施方式5涉及的驾驶辅助装置的功能结构的框图。图22所示的驾驶辅助装置10A具备ECU19A以取代上述的实施方式1涉及的驾驶辅助装置10的ECU19。
ECU19A构成为包括存储器以及具有CPU、GPU、FPGA、DSP和ASIC等中的任意硬件的处理器。ECU19A具备上述的取得部571、判定部572、生成部573以及输出控制部574。此外,在实施方式5中,ECU19A作为图像处理装置的处理器而发挥功能。
根据以上说明的实施方式5,输出控制部574将由生成部573生成的第1虚拟图像向第1可穿戴设备30输出,因此,能够使在用户彼此之间获得一体感。
(实施方式6)
接着,对实施方式6进行说明。在实施方式6中,第1可穿戴设备作为图像处理装置而发挥功能。以下,对实施方式6涉及的第1可穿戴设备的构成进行说明。此外,对于与上述的实施方式1~4涉及的显示系统1相同的构成赋予同一标号并省略详细的说明。
〔第1可穿戴设备的构成〕
图23是表示实施方式6涉及的第1可穿戴设备的功能结构的框图。图23所示的第1可穿戴设备30A具备第1控制部38A以取代上述的实施方式1涉及的第1控制部38。
第1控制部38A构成为包括存储器以及具有CPU、GPU、FPGA、DSP和ASIC等中的任意硬件的处理器。第1控制部38A具备上述的取得部571、判定部572、生成部573以及输出控制部574。此外,在实施方式6中,第1控制部38A作为图像处理装置的处理器而发挥功能。
根据以上说明的实施方式6,输出控制部574将第1虚拟图像向第1可穿戴设备30输出,因此,能够使在用户彼此之间获得一体感。
此外,在上述的实施方式6中,第1可穿戴设备30A的第1控制部38A具备上述的取得部571、判定部572、生成部573以及输出控制部574,但是例如也可以对第2可穿戴设备40的第2控制部49设置上述的取得部571、判定部572、生成部573以及输出控制部574的功能。
(其他实施方式)
在实施方式1~6中,对使用了使用者可佩戴的眼镜式的可穿戴设备的例子进行了说明,但无需限定于此,而能够应用于各式各样的可穿戴设备。例如即使是如图24所示那样具有拍摄功能的隐形眼镜式的可穿戴设备100A,也能够应用。再者,即使是如图25的可穿戴设备100B或者图26的脑内芯片式的可穿戴设备100C那样直接向使用者U100的大脑进行传达的装置,也能够应用。此外,也可以如图27的可穿戴设备100D那样构成为具备护目镜的头盔形状。在该情况下,可穿戴设备100D也可以是将图像投影并显示于护目镜的设备。
另外,在实施方式1~6中,第1可穿戴设备通过向搭乘者(驾驶员)的视网膜投影而使其对图像进行视觉确认,但是例如也可以为在眼镜等的镜片投影并显示图像。
另外,在实施方式1~6中,可以将上述的“部”改称为“电路”等。例如,第1控制部可以改称为第1控制电路。
另外,使实施方式1~6涉及的驾驶辅助装置、第1可穿戴设备、第2可穿戴设备以及服务器执行的程序以可安装的形式或者可执行的形式的文件数据的方式记录于CD-ROM、软盘(FD)、CD-R、DVD(Digital Versatile Disk)、USB介质、快闪存储器等计算机可读取的记录介质来提供。
另外,使实施方式1~6涉及的驾驶辅助装置、第1可穿戴设备、第2可穿戴设备以及服务器执行的程序也可以构成为保存在连接于互联网等网络的计算机上并通过经由网络下载来提供。
此外,在本说明书中的流程图的说明中,使用“首先”、“之后”、“接下来”等表达明确表示了步骤间的处理的前后关系,但为了实施本实施方式所需的处理的顺序并非由这些表达唯一确定。即,在本说明书中记载的流程图中的处理的顺序可以在没有矛盾的范围内变更。
以上,基于附图详细说明了本申请的若干个实施方式,但它们仅为例示,可以以本公开的栏中记载的技术方案为主,按基于本领域技术人员的知识施以各种变形、改良所得到的各种方式实施本公开。
进一步的效果和变形例能够由本领域技术人员容易地导出。本公开的更大范围的技术方案并不限定于如上所述表达且记述的特定的详细内容以及代表性的实施方式。因此,能够不脱离由权利要求及其等同物定义的总括性的发明的概念精神或者范围地进行各种各样的变更。
- 图像处理装置、图像处理方法、图像处理装置用程序、记录介质、以及图像显示装置
- 图像处理装置、显示系统、记录介质以及图像处理方法