一种基于信号时域特征的深度学习声源定位方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属声源定位技术领域,尤其是一种基于信号时域特征的深度学习声源定位方法。
背景技术
基于麦克风阵列的声源定位技术被广泛应用于工业及军事领域,主要定位算法分为广义互相关延时估计法、高分辨空间谱估计法以及波束形成法。目前主流的算法为波束形成算法,利用信号到达各阵元的产生的相位差异,将各阵元采集来的信号进行加权求和形成波束,通过搜索声源的可能位置来引导该波束,修改权值使得传声器阵列的输出信号功率最大,功率最大位置即声源所在位置。
但在实际使用过程中,由于算法原理限制,波束形成算法具有不可突破的物理极限。主要分为两方面:1、定位时需提前假定阵列面到定位面的距离,当声源远离或靠近定位面超过一定距离,产生定位误差,因此存在一定程度的工程应用限制。2、由于采用波束扫描的方式进行定位,当波束扫描至非声源位置时,产生旁瓣效应,旁瓣效应过大导致声源位置不清晰。
同时,随着人工智能的发展,深度学习方法为解决传统算法的缺陷提供了新思路。传统的多层感知机神经元的全连接模型,输入为二维特征时,需要先将原始数据转化为一维处理,导致原始数据间所隐藏的关联信息丢失,同时全连接模型参数量过大。而卷积神经网络利用参数共享的原理,与传统的多层感知机全连接层相比,使得前向传播函数实现起来更高效,同时大幅度降低了参数数量,可以最大程度保存二维或三维输入的原始特征。《一种基于卷积神经网络CNN的声源定位方法》(CN107703486A)以相位变换加权广义互相关函数作为输入,采用贝叶斯决策来构建判决式决定测试样本的类别,提高了混响及噪声环境下的定位精度。《一种利用传声器阵列的语音声源定位方法》(CN110838303A)以对数化功率谱及时-频点分布图为输入,信号到达角度为输出,采用与真实角度差小于5°为定位准确的评估标准,相比于传统的SRP-PHAT算法,将混响及噪声下定位精度提高了约50%。《基于均匀设计和自组织特征映射神经网络 的声源定位方法》(CN111239685A)对局部空间区域进行网格点划分,采用欧式距离法比较输入量与竞争层中的神经元对应的权值的相似性,获得声源稀疏位置,最终实现声源的精确定位,由于稀疏化的网格处理方法,使得声源定位精度取决于网格密度,因此提高了混叠声源定位中的空间分辨率。以上方法在提高混叠定位中空间分辨率、噪声及混响条件下的定位精度等方面取得了一定程度的进展,但此类方法依赖于某一基础信号处理算法,如:互相关、短时傅里叶变换等,且定位区域限于二维平面或局部三维空间。
对解决波束形成算法中旁瓣效应问题,尚不存在一种高效的解决方法。
发明内容
本发明的目的在于克服现有技术的不足,提出一种基于信号时域特征的深度学习声源定位方法,以时域信号作为输入特征,采用球坐标系下的空间定位模型,实现了全方位空间定位同时极大程度的削弱了旁瓣效应。
本发明解决其技术问题是采取以下技术方案实现的:
一种基于信号时域特征的深度学习声源定位方法,包括以下步骤:
步骤1、采用网格化方法离散声源位置信息并量化为仅包含0、1二值输出特征
步骤2、通过预设声源位置信息计算四元麦克风阵列接收的时域信号;
步骤3、采用时域信号切割重构方法截取长度为
步骤4、基于优化后的卷积神经网络对输入特征
步骤5、重复步骤1至步骤4对神经网络参数进行优化,通过优化参数的神经网络对位置未知的声源发出的时域信号进行位置预测。
而且,所述步骤1的具体是实现方法为:对不同声源位置信息中半径
其中,
对二维平面特征矩阵进行重组,得出仅有0、1二值的一维声源位置特征向量:
其中,
而且,所述步骤3的具体是实现方法为:对四个麦克风接收到的时域信号进行
而且,所述步骤4中卷积神经网络包括3个二维卷积层、1个最大池化层、1个平滑层和1个全连接层;卷积层对时域信息特征执行离散卷积运算,在执行卷积前对特征进行零填充操作,同时增加网络的非线性拟合能力,使用RELU非线性激活函数对每个卷积层的输出特征激活,使用Adam优化器进行优化。
本发明的优点和积极效果是:
1、本发明通过时域信号切割重构方法计算得到输入特征
2、本发明不依赖于任何基础信号处理方法,直接以时域信号作为网络的输入特征,保留了信号原始特征信息且减少了运算量。
3、本发明以0、1为标定值对三维空间中的声源位置信息进行标定,同时以标定后声源空间位置特征矩阵作为网络的输出,经测试,此种标定方式对削弱旁瓣效应具有显著效果。
4、本发明采用球坐标系下的空间定位模型,对不同半径下的空间球面进行网格划分,不同于局部空间定位模型,可实现全方位的精准定位。
附图说明
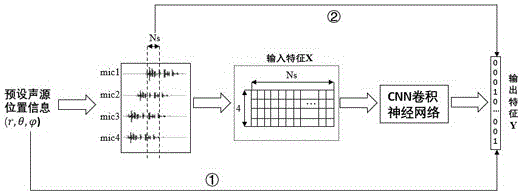
图1是本发明中基于信号时域特征的深度学习定位算法流程图;
图2是本发明的阵列定位模型示意图;
图3是本发明中优化后的卷积神经网络模型示意图;
图4是本发明中神经网络训练前后模型预测效果及标签值示意图;
图5是本发明中不同半径下的声源定位效果展示图。
具体实施方式
以下结合附图对本发明做进一步详述。
一种基于信号时域特征的深度学习声源定位方法,如图1所示,包括以下步骤:
步骤1、采用网格化方法离散声源位置信息
本步骤采用三维空间位置特征降维处理及表示方法,以球坐标系为定位模型,对不同半径下的空间球面进行网格化离散并转化为0、1矩阵(存在声源为1、不存在为0),再对不同半径下的声源位置特征进行矩阵求和运算,将三维空间位置特征转化为二维位置特征,从而达到三维空间位置特征降维处理目的,同时以0、1标定的输出特征可极大程度的削弱旁瓣效应。
本步骤的具体实现方法为:对不同声源位置信息坐标
其中,
对二维平面特征矩阵进行重组,得出仅有0、1二值的一维声源位置特征向量:
其中,
步骤2、通过预设声源位置信息
步骤3、采用时域信号切割重构方法截取长度为
四个麦克风所接收到的是包含时延差信息的四组时域信号。对四个麦克风接收到的时域信号进行
步骤4、基于优化后的卷积神经网络对输入特征
步骤5、重复步骤1至步骤4对神经网络参数进行优化,通过优化参数的神经网络对位置未知的声源发出的时域信号进行位置预测。
根据上述一种基于信号时域特征的深度学习声源定位方法,采用如图2所示的阵列定位模型进行计算,采用的阵列定位模型为边长为1m的正四面体麦克风阵列模型及球坐标系下(半径
如图4和图5所示,以单频正弦加噪信号为例,本发明采用的采样频率为25.6kHz,截取长度
如图3所示,卷积神经网络模型由6层构成:3个二维卷积层(Conv2D)、1个最大池化层(Maxpooling2D)、1个平滑层(Flatten)和1个全连接层(Dense)。卷积层对时域信息特征执行离散卷积运算。在执行卷积前对特征进行零填充(padding)操作,保证输出特征与输入特征维度一致。由于RELU激活函数的非线性性质,可以增加网络的非线性拟合能力,因此使用RELU函数对每个卷积层的输出特征激活。使用Adam优化器,学习率为0.0001,训练批量大小为32。迭代次数为50。
如图4所示为模型训练前后的声源定位结果及标签值,其中横轴为方向角
如图5所示为不同距离下的声源定位结果,基于本发明预测的声源位置与声源真实位置完全一致,非声源位置像素值小于0.2,与声源位置形成的主瓣相比,旁瓣效应极低。且三个测试样本中声源位置到阵列距离不固定,突破了传统平面阵列到定位平面为固定值的假设。
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。