一种基于增量的多源数据采集方法、系统及设备
文献发布时间:2024-01-17 01:15:20
技术领域
本发明涉及数据采集技术领域,特别是涉及一种基于增量的多源数据采集方法、系统及设备。
背景技术
伴随着大数据时代来临,越来越多样化的数据进入视野,要想使这些海量数据被更好的使用,数据分析是其中不可避免的一个环节,然而数据分析和数据生产之间还存在更为重要的一个流程,那就是数据采集(Extract-Transform-Load,ETL)。ETL用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。对于中大型企业尤其是互联网企业和金融企业,当其面对庞大的底层数据和不同数据源的数据时,首先需要保证贴源层数据和原系统数据的一致性,其次在保证一致性的前提下通过技术手段或者数据处理方式以保障数据采集的效率和服务器间的稳定性。目前现有的技术方案,主要是通过以下两种方式进行数据采集:
一是大数据平台向外部提供一套标准化的JDBC或ODBC等接口,其中JDBC表示Java数据库连接,是一种应用程序编程接口,即API;ODBC是开放式数据库连接,与JDBC一样,ODBC也是一个API接口,充当客户端应用程序和服务器端数据库之间的接口。大数据平台可通过上述API接口完成实时或非实时的数据采集与存储工作。对于大数据平台提供统一API接口进行数据采集的方式,存在以下缺点:一是任何数据源都需要基于标准API接口进行开发;二是接口开发所消耗人力和物力资源较大;三是可延展性较差,对于新开发的业务,需对之前开发的接口进行改造;四是对于海量数据采集的性能较低。
二是系统日志采集方式,通过读取数据库日志信息或监控数据源上数据变化以实现数据采集,但通过读取数据库日志的方式实现数据采集时需通过配置表的方式,将数据源端属性信息与大数据平台进行关联。通过读取数据库逻辑日志的数据采集方式,存在以下缺点:一是实时监控数据源庞大数据量变化难度较大;二是容易产生日志丢失情况,相对稳定性较差;三是通过系统日志的采集方式效率较低;四是日志存储对于内存占用较大,长时间使用易产生较多内存碎片;此方式人工运维成本较高,对于新增数据源、表和字段都需调整数据采集平台配置信息。
发明内容
本发明的目的是提供一种基于增量的多源数据采集方法、系统及设备,对多种数据源的海量数据实现高效采集。
为实现上述目的,本发明提供了如下方案:
第一方面,本发明提供一种基于增量的多源数据采集方法,包括:
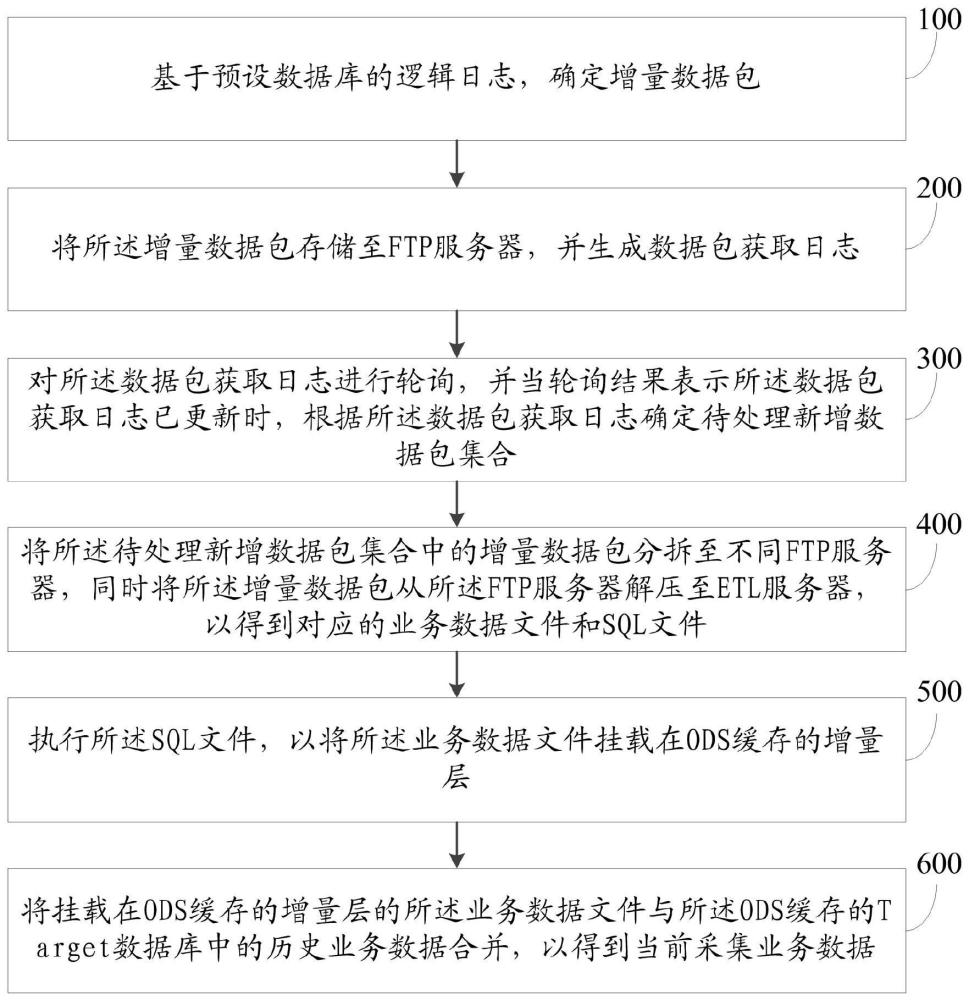
基于预设数据库的逻辑日志,确定增量数据包;所述预设数据库中存储有多平台的保险业务源数据;
将所述增量数据包存储至FTP服务器,并生成数据包获取日志;
对所述数据包获取日志进行轮询,并当轮询结果表示所述数据包获取日志已更新时,根据所述数据包获取日志确定待处理新增数据包集合;
将所述待处理新增数据包集合中的增量数据包分拆至不同FTP服务器,同时将所述增量数据包从所述FTP服务器解压至ETL服务器,以得到对应的业务数据文件和SQL文件;
执行所述SQL文件,以将所述业务数据文件挂载在ODS缓存的增量层;
将挂载在ODS缓存的增量层的所述业务数据文件与所述ODS缓存的Target数据库中的历史业务数据合并,以得到当前采集业务数据。
可选地,所述数据包获取日志以Proclog表的形式存储。
可选地,对所述数据包获取日志进行轮询,具体包括:
采用Celery调度,按照预设间隔时间对所述数据包获取日志进行扫描。
可选地,执行所述SQL文件的步骤之前,方法还包括:
将所述SQL文件中的回车、换行符、空格、特殊字符和null值剔除,并将所述SQL文件中的语句调整为适合PG库创建外部表的SQL语句。
可选地,根据所述数据包获取日志确定待处理新增数据包集合,具体包括:
获取数据仓库中保险业务源数据的本地存储日志;
对比所述本地存储日志与所述数据包获取日志,以确定待处理新增数据包集合。
可选地,将挂载在ODS缓存的增量层的所述业务数据文件与所述ODS缓存的Target数据库中的历史业务数据合并,以得到当前采集业务数据,具体包括:
将所述ODS缓存的Target数据库中的历史业务数据并发卸载为历史数据文件;
依据相同表名,将所述历史数据文件与挂载在ODS缓存的增量层的所述业务数据文件合并,以得到初始合并文件;
对所述初始合并文件进行数据清洗,以得到当前采集业务数据。
可选地,方法还包括:
将所述当前采集业务数据转载至所述数据仓库,并更新所述本地存储日志。
第二方面,本发明提供一种基于增量的多源数据采集系统,包括:
增量数据获取模块,用于基于预设数据库的逻辑日志,确定增量数据包;所述预设数据库中存储有多平台的保险业务源数据;
日志生成模块,用于将所述增量数据包存储至FTP服务器,并生成数据包获取日志;
待处理数据包确定模块,用于对所述数据包获取日志进行轮询,并当轮询结果表示所述数据包获取日志已更新时,根据所述数据包获取日志确定待处理新增数据包集合;
数据并行处理模块,用于将所述待处理新增数据包集合中的增量数据包分拆至不同FTP服务器,同时将所述增量数据包从所述FTP服务器解压至ETL服务器,以得到对应的业务数据文件和SQL文件;
业务数据挂载模块,用于执行所述SQL文件,以将所述业务数据文件挂载在ODS缓存的增量层;
当前采集业务数据确定模块,用于将挂载在ODS缓存的增量层的所述业务数据文件与所述ODS缓存的Target数据库中的历史业务数据合并,以得到当前采集业务数据。
第三方面,本发明提供一种电子设备,所述电子设备包括存储器和处理器;
所述存储器用于存储计算机程序,所述处理器用于运行所述计算机程序以执行基于增量的多源数据采集方法。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明公开一种基于增量的多源数据采集方法、系统及设备,基于预设数据库的逻辑日志确定增量数据包,其中预设数据库中存储有多平台的保险业务源数据,可知增量数据包为从多数据源中获取得到增量数据。将增量数据包存储至FTP服务器并生成数据包获取日志,对数据包获取日志进行轮询,并当轮询结果表示数据包获取日志已更新时,确定待处理新增数据包集合;然后将待处理新增数据包集合中的增量数据包分拆至不同FTP服务器,以实现并发抽取数据;同时将增量数据包从FTP服务器解压至ETL服务器得到对应的业务数据文件和SQL文件,进而实现多进程的高并发数据解压;然后执行SQL文件以将业务数据文件挂载在ODS缓存的增量层,从而得到实际的新增业务数据,即增量数据;将挂载在ODS缓存的增量层的业务数据文件与ODS缓存的Target数据库中的历史业务数据合并以得到当前采集业务数据。本发明将多源业务数据拆分至不同FTP服务器以及ETL服务器,降低单一服务器处理数据的压力;同时通过多线程包括多进程的高并发数据抽取、解压处理以及最后的数据合并处理,实现对于海量数据的高效采集。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明基于增量的多源数据采集方法的流程示意图;
图2为本发明基于增量的多源数据采集方法的具体实例示意图;
图3为本发明基于增量的多源数据采集方法的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供一种基于增量的多源数据采集方法、系统及设备,具备高性能,高扩展等特性,可以为超大规模数据采集提供通用处理能力。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
实施例一
如图1所示,本发明提出一种基于增量的多源数据采集方法,包括:
步骤100,基于预设数据库的逻辑日志,确定增量数据包;所述预设数据库中存储有多平台的保险业务源数据。所述保险业务源数据包括保险业业务系统数据以及系统内部相关系统业务数据;所述保险业业务系统数据包括对应的承保、理赔、车险、非车险、农险、普惠金融等业务保单数据;所述系统内部相关系统业务数据包括对应的产品信息、员工信息、客户信息等。
具体地,通过IIE数据采集工具实时监控数据库逻辑日志,每30分钟将IIE数据采集工具处理后得到的增量数据,按机构和实例打包,得到tar增量数据包。其中,机构指保险业务源数据的采集平台,可按所处省、市进行划分;实例指业务系统数据库中具体的表,可按具体保险业务源(如承保、理赔、收付费、财务等)和表名进行拆分。
步骤200,将所述增量数据包存储至FTP服务器,并生成数据包获取日志。具体地,将tar增量数据包放至FTP服务器,同时依据IIE数据采集工具处理增量数据采集时的文件数量、文件名称以及数据采集时间等基础信息,生成或更新数据包获取日志。
在一个具体实例中,所述数据包获取日志以Proclog表的形式存储。
步骤300,对所述数据包获取日志进行轮询,并当轮询结果表示所述数据包获取日志已更新时,根据所述数据包获取日志确定待处理新增数据包集合;
其中,对所述数据包获取日志进行轮询,具体包括:数据仓库采用Celery调度,按照预设间隔时间对所述数据包获取日志进行扫描。在一个具体实际应用中,所述预设间隔时间为5分钟。
其中,根据所述数据包获取日志确定待处理新增数据包集合,具体包括:1)获取数据仓库中保险业务源数据的本地存储日志;2)对比所述本地存储日志与所述数据包获取日志,以确定待处理新增数据包集合;所述待处理新增数据包集合中包括有本地存储日志中所没有记载的新增数据包。
步骤400,将所述待处理新增数据包集合中的增量数据包分拆至不同FTP服务器,同时将所述增量数据包从所述FTP服务器解压至ETL服务器,以得到对应的业务数据文件和SQL文件。
在一个具体实际应用中,将待处理新增数据包集合中的增量数据包依据不同表名、通过Celery调度拆分到多个FTP服务器上;每个FTP服务器每天可支持15张表同时进行数据抽取。其中,不同表名是指增量数据包中存储有保险业务源数据的数据表的名称。而将增量数据包拆分至不同的多个FTP服务器能够实现多线程处理任务。同时,根据多家省级机构多进程地对多个增量数据包,分别从对应的FTP服务器解压至ETL服务器,对应得到1个数据文件和1个SQL(StructuredQueryLanguage,结构化查询语言)文件,从而实现多线程包含多进程的高并发数据抽取、解压过程。
执行步骤500的步骤之前,方法还包括:清洗SQL文件。具体地,将所述SQL文件中的回车、换行符、空格、特殊字符和null值剔除,并将所述SQL文件中的语句调整为适合PG库(postgrel数据库)创建外部表的SQL语句。
步骤500,执行所述SQL文件,以将所述业务数据文件挂载在ODS(OperationalDataStore,临时存储数据运营层)缓存的增量层。具体地,执行经过清洗后的SQL语句,至此,所有业务数据文件已挂载在ODS缓存的增量层。
步骤600,将挂载在ODS缓存的增量层的所述业务数据文件与所述ODS缓存的Target数据库中的历史业务数据合并,以得到当前采集业务数据。
步骤600,具体包括:1)将所述ODS缓存的Target数据库中的历史业务数据并发卸载为历史数据文件;2)依据相同表名,将所述历史数据文件与挂载在ODS缓存的增量层的所述业务数据文件合并,以得到初始合并文件;3)对所述初始合并文件进行数据清洗,以得到当前采集业务数据。
在一个具体实际应用中,在每天的固定时间(比如凌晨1点或凌晨2点),将前一天存储在ODS缓存的Target数据库中的历史业务数据,按照机构和表名并发卸载为历史数据文件;在ETL服务器上将表名相同的历史数据文件与业务数据文件合并,在合并的过程中进行数据清洗,剔除掉回车和换行符。
优选地,方法还包括:将所述当前采集业务数据转载至所述数据仓库,并更新所述本地存储日志。
在一个具体实际应用中,本发明应用分布式架构,基于RPC(RemoteProcedureCall)远程调用,通过celery将数据抽取任务分发到不同服务器上以并发抽取数据,从而达到系统模块拆分的目的;使用接口通信,降低系统模块之间的耦合度。本发明基于上述架构,将采集到的不同业务对应的表拆分到不同ETL服务器,降低单一服务器处理数据的压力。
上文中的分布式主要是高并发抽取数据,采用二级并发的方式,同时抽取多张表,每张表同时并发抽取所有机构的数据,来提升数据采集的抽取效率。其中,高并发说的是以表为单位,再通过省级机构来拆分数据文件进行抽取,多进程包含多线程。
本发明采用分层思想,将数据采集、清洗、装载、转换、以及对多集群数据推送,拆分成独立模块,通过修改配置,来实现多个集群的对接,以及指定表的推送。
本发明中设置多台ETL服务器备份,当某台ETL服务器异常,通过修改配置,可随时切换至其他ETL服务器继续工作,保证数据推送的及时性。
本发明还可通过业务主键比对、计算金额比对以及多渠道验证,保证数据的准确性。另外,本发明全部为线性逻辑,可通过修改配置横向扩展,对接多集群。本发明通过FTP并行将数据文件装载至不同集群的数据表中。
优选地,本发明提供个性化数据采集流程,针对不同数据库和采集工具采取不同的数据采集逻辑以确保数据采集效率。
在一个具体实例中,如图2所示,基于增量的多源数据采集方法具体包括以下步骤:
1)IIE软件通过分析逻辑日志,提取增量数据,每0.5个小时形成tar包。
2)IIE软件将tar包放到FTP服务器上,并将tar包信息插到proclog表。
3)ETL系统每5分钟轮询proclog表,获得最新信息,分发任务到FTP服务器的工作队列,将最新tar包取到ETL服务器中。
4)ETL系统将tar包解压,将数据通过外部文件的形式挂载到ODS缓存的增量层。
5)ETL服务器将增量层数据合并到target数据库,并对每条数据打上序列号。
6)每日T+1时,ETL系统读取主驱动表,分发任务到工作队列,去ODS缓存的target数据库,将各个表的增量数据卸下至ETL服务器。
7)ETL系统将数据加载至ODS层SDATA库中,以实现基于增量的多源数据采集。
实施例二
如图3所示,为了实现实施例一中的技术方案,本实施例提供一种基于增量的多源数据采集系统,包括:
增量数据获取模块101,用于基于预设数据库的逻辑日志,确定增量数据包;所述预设数据库中存储有多平台的保险业务源数据。
日志生成模块201,用于将所述增量数据包存储至FTP服务器,并生成数据包获取日志。
待处理数据包确定模块301,用于对所述数据包获取日志进行轮询,并当轮询结果表示所述数据包获取日志已更新时,根据所述数据包获取日志确定待处理新增数据包集合。
数据并行处理模块401,用于将所述待处理新增数据包集合中的增量数据包分拆至不同FTP服务器,同时将所述增量数据包从所述FTP服务器解压至ETL服务器,以得到对应的业务数据文件和SQL文件。
业务数据挂载模块501,用于执行所述SQL文件,以将所述业务数据文件挂载在ODS缓存的增量层。
当前采集业务数据确定模块601,用于将挂载在ODS缓存的增量层的所述业务数据文件与所述ODS缓存的Target数据库中的历史业务数据合并,以得到当前采集业务数据。
实施例三
本实施例提供一种电子设备,所述电子设备包括存储器和处理器;所述存储器用于存储计算机程序,所述处理器用于运行所述计算机程序以执行实施例一所述的基于增量的多源数据采集方法。
可选地,所述电子设备为服务器。
另外,本实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序;所述计算机程序被处理器执行时实现实施例一所述的基于增量的多源数据采集方法的步骤。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种数据采集系统和可穿戴设备数据采集、建模的方法
- 一种基于卷积神经网络的移动设备源识别方法及系统
- 一种确定计量设备的计量累计值处于增量为负状态的方法及系统
- 一种确定计量设备的计量累计值处于增量为零状态的方法及系统
- 一种计量设备的计量累计值增量过大异常状态判断方法及系统
- 一种基于源库不停机的异构数据库增量同步方法及系统
- 一种基于源库不停机的异构数据库增量同步方法及系统