一种开放世界未知类识别的目标检测方法
文献发布时间:2024-01-17 01:26:37
技术领域
本发明属于图像数据识别领域,具体涉及一种开放世界未知类识别的目标检测方法。
背景技术
目标检测深度学习加速了目标检测研究的进展, 模型的任务是识别和定位图像中的目标。所有现有的方法都是在一个重要假设下工作的,即所有要检测的类在训练阶段都是可用的。当放宽这一假设时,出现了两个具有挑战性的场景:1)测试图像可能包含来自未知类的目标,这些目标应该被分类为未知,2) 当有关这些已识别未知项的信息(标签)可用时,模型应该能够增量地学习新类,把这个问题称为开放世界目标检测。
目前开放世界目标检测方法在实现过程中,虽然识别出了未知类别,但是归统一的未知类,但是未知类别是多种多样的,实际上并不是同一个类别,这会导致产生副作用,且对未知类的分类存在巨大商业价值,例如,在机器人和自动驾驶汽车的实际应用中需要探索未知环境,并针对不同的未知类别采取不同的策略。
目前开放世界目标检测方法在实现过程中,如现有专利文献CN115797706A公开了目标检测方法、目标检测模型训练方法及相关装置,虽然识别出了未知类别,且归为一类,但是未知类别是多种多样的,实际上并不是同一个类别,这会导致产生副作用。
发明内容
本发明旨在解决上述问题,即不仅能够在开放世界环境下检测未知物体和有关这些已识别未知物体的信息(标签)可用时逐渐学习认知新的未知物体,而且能够优化未知类的识别,实现了开放环境下对未知类别的检测,减少了人工标注的成本,提高了开放世界下目标检测精度。
本发明的目的至少通过如下技术方案之一实现。
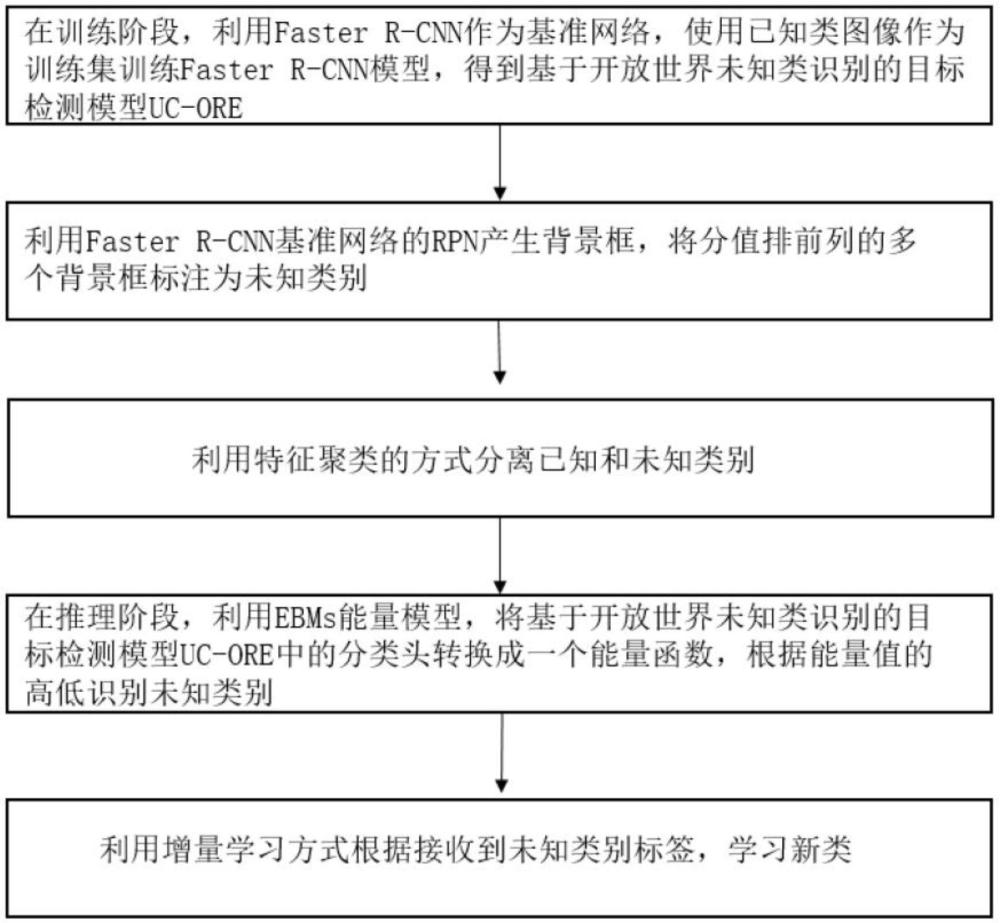
一种开放世界未知类识别的目标检测方法,包括以下步骤:
S1、在训练阶段,利用Faster R-CNN作为基准网络,使用已知类图像作为训练集训练Faster R-CNN模型,得到基于开放世界未知类识别的目标检测模型UC-ORE;
S2、利用Faster R-CNN基准网络的RPN产生背景框,将分值排前列的多个背景框标注为未知类别;
S3、利用特征聚类的方式分离已知和未知类别;
S4、在推理阶段,利用EBMs能量模型,将基于开放世界未知类识别的目标检测模型UC-ORE中的分类头转换成一个能量函数,根据能量值的高低识别未知类别;
S5、根据接受到未知类别标签,利用增量学习方式学习新类,进而循环实现开放世界未知类识别。
进一步地,步骤S1中,训练集采用Pascal VOC 2007和MS-COCO标准数据集作为检测基准;在标准数据集上训练任务,利用Faster R-CNN作为基准网络;其中,Faster R-CNN全称Faster Region-based Convolutional Neural Network,是一种两阶段目标检测算法。
进一步地,步骤S2中,在Faster R-CNN的候选框提取网络RPN产生的背景框中,背景框实际上是没有被标注的区域,所以这些背景框中分数较高的很可能就是没有标注的未知类别,直接将候选框提取网络RPN产生的背景框中,按分值排序,前
进一步地,步骤S3中,潜在空间中的类分离是开放世界目标检测方法识别未知类的理想特征;一种自然的方法是将潜在空间中的类分离建模为一个特征聚类问题,在这个问题中,同一类的实例将被迫保持在附近,而不同类的实例将被推得很远,且由于未知类别可能是多种多样的,实际上并不是同一个类别,把未知类别归为一个类别可能会产生副作用,利用特征聚类的方式分离已知和未知类别,且对分离的未知类别进行初步分类,区分未知类别中的相同类和不同类;
具体利用同一类别的对象在特征空间上距离小于不同类别对象在特征空间上的距离这一特性,实现潜在空间中的类分离,具体如下:
首先对已知类别的对象进行k-means聚类,得到对应类别的聚类簇中心;
然后,计算一个新的未知类别与现有的已知类别的簇中心的距离,若存在该未知类别与所有现有的已知类别的簇中心的距离的最小值,低于设定的阈值,则将该未知类别归纳为该最小值对应的现有的已知类别,否则将该未知类别归纳为一个新的未知类别,从而实现分离已知和未知类别,并对未知类别初步分类。
进一步地,步骤S4中,利用EBMs能量模型,将基于开放世界未知类识别的目标检测模型UC-ORE中的分类头转换成一个能量函数;其中EBMs是指Energy-Based Models,即基于能量的模型,是一种概率生成模型;
基于能量模型 (EBMs)中,给定特征空间
能量模型(EBMs)给已知类别的数据分配低能量值,给未知类分配高能量值,根据能量值的高低识别未知类别。
进一步地,步骤S4中,使用能量函数公式进行计算,其中特征空间的已知和未知类标签集合
其中,
进一步地,步骤S5中,当接收到已识别未知类别对象标签,输入新的未知类别标签,重新训练得到基于开放世界未知类识别的目标检测模型UC-ORE,进而实现开放世界未知类识别。
进一步地,重新训练得到基于开放世界未知类识别的目标检测模型UC-ORE时,利用基于样本回放的增量学习方法学习新类,即存储一部分具有代表性的旧数据,并在每个增量步骤之后对基于开放世界未知类识别的目标检测模型UC-ORE进行微调,将基于开放世界未知类识别的目标检测模型UC-ORE除了输出层外其他层参数冻结,只对最后输出层的参数进行调整。
进一步地,基于样本回放的增量学习是一种机器学习方法,主要用于处理在线学习中新数据的加入,它的基本思想是使用历史数据来训练目标检测模型UC-ORE,然后将新数据与历史数据一起使用以更新模型;这种方法的主要优点是它可以避免重新训练整个模型,因此可以大大提高训练效率,一种常见的策略是随机选择一部分历史数据来与新数据一起使用,这种方法可以防止模型对某些历史数据过于依赖,从而提高模型的泛化能力,具体包括以下步骤:
S5.1、初始化模型:在增量学习开始之前,需要先初始化目标检测模型UC-ORE,并将其用于训练一部分数据;
S5.2、训练模型:使用一部分新的数据进行目标检测模型UC-ORE的训练;
S5.3、样本回放:将之前训练过的数据集中的设定比例的样本存储在一个缓冲区中,称为回放缓冲区,随后从回放缓冲区中随机抽取设定比例的的样本,将这些样本与当前训练数据一起用于目标检测模型UC-ORE的训练;
S5.4、模型更新:将使用回放缓冲区中的样本进行训练后的目标检测模型UC-ORE与步骤S5.2中训练的目标检测模型UC-ORE进行合并,得到新的目标检测模型UC-ORE;
S5.5、测试模型:使用测试数据集对步骤S5.3中的目标检测模型UC-ORE进行评估。
S5.6、如果还有新的数据需要进行训练,返回步骤S5.2,否则,结束增量学习。
进一步地,所述进行微调是在接收到未知类别的标签时,为了避免模型重新训练,使用一部分代表性的历史数据和新数据训练模型;在模型微调中,只对最后输出层的参数进行调整的方法通常称为“头部微调”(head fine-tuning)或“全局微调”;
这种方法的主要思想是,利用预训练模型在大规模数据上学习到的通用特征,只对模型的最后几层进行微调,从而使得模型在新的任务上能够更好地适应,具体实现的流程如下:
A1、加载预训练模型:使用已经在大规模数据上预训练好的目标检测模型UC-ORE作为初始模型;
A2、冻结模型参数:对于不需要微调的层,将它们的参数冻结,使得它们在训练过程中不会发生变化;
A3、替换输出层:将目标检测模型UC-ORE的最后一层输出层替换为新的适应任务的输出层,该输出层包含新任务所需的类别数;
A4、只训练新的输出层:只对新的输出层进行训练,使得目标检测模型UC-ORE能够更好地适应新的任务;
A5、解冻参数:如果需要微调其他层的参数,则解冻这些层的参数,让它们能够在微调中发生变化;
A6、微调模型:对整个目标检测模型UC-ORE进行微调,直到目标检测模型UC-ORE在新的任务上收敛。
相比于现有技术,本发明的优点在于:
目前开放世界目标检测方法在实现过程中,虽然识别出了未知类别,但是归统一的未知类,但是未知类别是多种多样的,实际上并不是同一个类别,这会导致产生副作用,且对未知类的分类存在巨大商业价值,例如,在机器人和自动驾驶汽车的实际应用中需要探索未知环境,并针对不同的未知类别采取不同的策略;本发明通过对未知类别的细分,提高了开放世界目标检测的精度。
附图说明
图1为本发明实施例中一种开放世界未知类识别的目标检测方法的流程图;
图2为本发明实施例中PRN标注未知类示意图;
图3为本发明实施例中特征聚类示意图;
图4为本发明实施例中的效果图。
具体实施方式
为使本发明地目的、技术方案和优点更加清楚明白,下面结合附图并举实施例,对本发明地具体实施进行详细说明,显然,所描述的实施例是本发明一部分实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得地所有其他实施例,都属于本发明保护的范围。
实施例:
一种开放世界未知类识别的目标检测方法,如图1所示,包括以下步骤:
S1、在训练阶段,利用Faster R-CNN作为基准网络,使用已知类图像作为训练集训练Faster R-CNN模型,得到基于开放世界未知类识别的目标检测模型UC-ORE;
在一个实施例中,训练集采用Pascal VOC 2007和MS-COCO标准数据集作为检测基准;在标准数据集上训练任务,利用Faster R-CNN作为基准网络;其中,Faster R-CNN全称Faster Region-based Convolutional Neural Network,是一种两阶段目标检测算法。在Faster R-CNN模型的训练阶段,设置目标检测的置信度SCORE为0.35,非极大值抑制NMS设置为0.35。
S2、利用Faster R-CNN基准网络的RPN产生背景框,将分值排前列的多个背景框标注为未知类别;
如图2所示,在Faster R-CNN的候选框提取网络RPN产生的背景框中,背景框实际上是没有被标注的区域,所以这些背景框中分数较高的很可能就是没有标注的未知类别,直接将候选框提取网络RPN产生的背景框中,按分值排序,前
S3、利用特征聚类的方式分离已知和未知类别;
如图3所示,潜在空间中的类分离是开放世界目标检测方法识别未知类的理想特征;一种自然的方法是将潜在空间中的类分离建模为一个特征聚类问题,在这个问题中,同一类的实例将被迫保持在附近,而不同类的实例将被推得很远,且由于未知类别可能是多种多样的,实际上并不是同一个类别,把未知类别归为一个类别可能会产生副作用,利用特征聚类的方式分离已知和未知类别,且对分离的未知类别进行初步分类,区分未知类别中的相同类和不同类;
具体利用同一类别的对象在特征空间上距离小于不同类别对象在特征空间上的距离这一特性,实现潜在空间中的类分离,具体如下:
首先对已知类别的对象进行k-means聚类,得到对应类别的聚类簇中心;
然后,计算一个新的未知类别与现有的已知类别的簇中心的距离,若存在该未知类别与所有现有的已知类别的簇中心的距离的最小值,低于设定的阈值,则将该未知类别归纳为该最小值对应的现有的已知类别,否则将该未知类别归纳为一个新的未知类别,从而实现分离已知和未知类别,并对未知类别初步分类。
S4、在推理阶段,利用EBMs能量模型,将基于开放世界未知类识别的目标检测模型UC-ORE中的分类头转换成一个能量函数,根据能量值的高低识别未知类别;
利用EBMs能量模型,将基于开放世界未知类识别的目标检测模型UC-ORE中的分类头转换成一个能量函数;其中EBMs是指Energy-Based Models,即基于能量的模型,是一种概率生成模型;
基于能量模型 (EBMs)中,给定特征空间
能量模型(EBMs)给已知类别的数据分配低能量值,给未知类分配高能量值,根据能量值的高低识别未知类别。
使用能量函数公式进行计算,其中特征空间的已知和未知类标签集合
其中,
S5、根据接受到未知类别标签,利用增量学习方式学习新类,进而循环实现开放世界未知类识别;
当接收到已识别未知类别对象标签,输入新的未知类别标签,重新训练得到基于开放世界未知类识别的目标检测模型UC-ORE,进而实现开放世界未知类识别。
进一步地,重新训练得到基于开放世界未知类识别的目标检测模型UC-ORE时,利用基于样本回放的增量学习方法学习新类,即存储一部分具有代表性的旧数据,并在每个增量步骤之后对基于开放世界未知类识别的目标检测模型UC-ORE进行微调,将基于开放世界未知类识别的目标检测模型UC-ORE除了输出层外其他层参数冻结,只对最后输出层的参数进行调整。
进一步地,基于样本回放的增量学习是一种机器学习方法,主要用于处理在线学习中新数据的加入,它的基本思想是使用历史数据来训练模型,然后将新数据与历史数据一起使用以更新模型。这种方法的主要优点是它可以避免重新训练整个模型,因此可以大大提高训练效率,一种常见的策略是随机选择一部分历史数据来与新数据一起使用,这种方法可以防止模型对某些历史数据过于依赖,从而提高模型的泛化能力,具体包括以下步骤:
S5.1、初始化模型:在增量学习开始之前,需要先初始化目标检测模型UC-ORE,并将其用于训练一部分数据;
S5.2、训练模型:使用一部分新的数据进行目标检测模型UC-ORE的训练;
S5.3、样本回放:将之前训练过的数据集中的设定比例的样本存储在一个缓冲区中,称为回放缓冲区,随后从回放缓冲区中随机抽取设定比例的的样本,将这些样本与当前训练数据一起用于目标检测模型UC-ORE的训练;
S5.4、模型更新:将使用回放缓冲区中的样本进行训练后的目标检测模型UC-ORE与步骤S5.2中训练的目标检测模型UC-ORE进行合并,得到新的目标检测模型UC-ORE;
S5.5、测试模型:使用测试数据集对步骤S5.3中的目标检测模型UC-ORE进行评估。
S5.6、如果还有新的数据需要进行训练,返回步骤S5.2,否则,结束增量学习。
进一步地,所述进行微调是在接收到未知类别的标签时,为了避免模型重新训练,使用一部分代表性的历史数据和新数据训练模型;在模型微调中,只对最后输出层的参数进行调整的方法通常称为“头部微调”(head fine-tuning)或“全局微调”;
这种方法的主要思想是,利用预训练模型在大规模数据上学习到的通用特征,只对模型的最后几层进行微调,从而使得模型在新的任务上能够更好地适应,具体实现的流程如下:
A1、加载预训练模型:使用已经在大规模数据上预训练好的目标检测模型UC-ORE作为初始模型;
A2、冻结模型参数:对于不需要微调的层,将它们的参数冻结,使得它们在训练过程中不会发生变化;
A3、替换输出层:将目标检测模型UC-ORE的最后一层输出层替换为新的适应任务的输出层,该输出层包含新任务所需的类别数;
A4、只训练新的输出层:只对新的输出层进行训练,使得目标检测模型UC-ORE能够更好地适应新的任务;
A5、解冻参数:如果需要微调其他层的参数,则解冻这些层的参数,让它们能够在微调中发生变化;
A6、微调模型:对整个目标检测模型UC-ORE进行微调,直到目标检测模型UC-ORE在新的任务上收敛。
为了证明本申请所提出的方法的有效性,下面进行验证实验:
提出了一项全面的评估标准来探讨基于开放世界未知类识别的目标检测模型UC-ORE的性能,包含对未知类别对象的识别,检测已知类别,以及对未知类提供标签时逐渐学习新类别。
数据分割:把类分成一组任务
在一个实施例中,考虑来自Pascal VOC和MS-COCO的类。将所有VOC类和数据分组为第一个任务
表1
评估指标:由于未知目标很容易与已知目标混淆,因此使用Wilderness Impact(WI)指标来明确描述这种行为,理想情况下,WI应该更小,因为当未知目标被添加到测试集时,精度不能下降。除了WI之外,还使用绝对开集误差(A-OSE)来反映错误分类为已知类的未知目标的数量。WI和A-OSE都隐式地度量模型在处理未知目标方面的有效性。
表2显示了在开放世界目标检测上,UC-ORE与Faster RCNN的比较。在学习每个任务之后,WI和A-OSE度量用于量化未知实例与任何已知类的混淆程度。发现UC-ORE的WI和A-OSE分数明显较低,这是由于对未知目标的显式建模。当在任务2中逐步标记未知类时,发现基线检测器在已知类集合(通过mAP量化)上的性能从56.16%显著下降到5.011%。UC-ORE能够同时实现两个目标:检测已知类和降低未知类的影响。类似的趋势也出现在任务3和任务4类中。
表2展示了UC-ORE在开放世界目标检测中的表现。WI和A-OSE量化评估了UC-ORE如何处理未知类,而mAP衡量了它如何很好地检测已知类。可以看到在所有指标上,UC-ORE都始终优于基于Faster R-CNN的基准。
表2
本发明中,使用UC-ORE对未知物体进行清晰建模,使得它在增量目标检测任务中表现良好。这是因为,UC-ORE减少了未知目标被分类为已知目标的混淆,这使得检测器可以增量地学习真实的前景目标。使用ILOD(增量目标检测器的缩写)中使用的标准来评估UC-ORE,使用Pascal VOC 2007数据集,把该数据集分成三组:10(已知类)+10(未知类),15(已知类)+5(未知类),19(已知类)+1(未知类)来使检测器进行增量学习。在三种不同的设置下将UC-ORE与ILOD进行了比较。如下表3所示,UC-ORE在所有设置中都表现十分出色。
表3
需要说明的是,任何本发明所属技术领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式上及细节上进行变更和修改。因此,本发明的一些等同修改和变更也应该在本发明的权利要求的保护范围内。此外,尽管本说明书中使用了一些特定的术语,但这些术语只是为了方便说明,并不对本发明构成任何限制。