一种半监督模型的训练方法、装置及相关设备
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及图像处理技术领域,尤其涉及一种半监督模型的训练方法、装置及相关设备。
背景技术
半监督模型学习允许训练集中含有无标注的数据,降低了深度学习对训练数据的要求,使深度学习能够在更广泛的领域得到应用。
但是传统半监督研究假定标注数据与无标注数据属于同一分布,即无标注数据归属于某一已知类别。然而当无标注数据与标注数据分布不匹配,出现已知类别外的样本时,传统半监督的打标器只能对此类样本猜测错误标签,并且错误标签在后续的一致性正则化误差计算中扰乱样本分布形态,影响半监督模型的训练过程,且训练出来的半监督模型的泛化能力较低。
发明内容
本发明的目的在于提供一种半监督模型的训练方法、装置及相关设备,能够提升半监督模型的泛化能力。
为实现上述目的,第一方面,本发明提供了一种半监督模型的训练方法,包括:
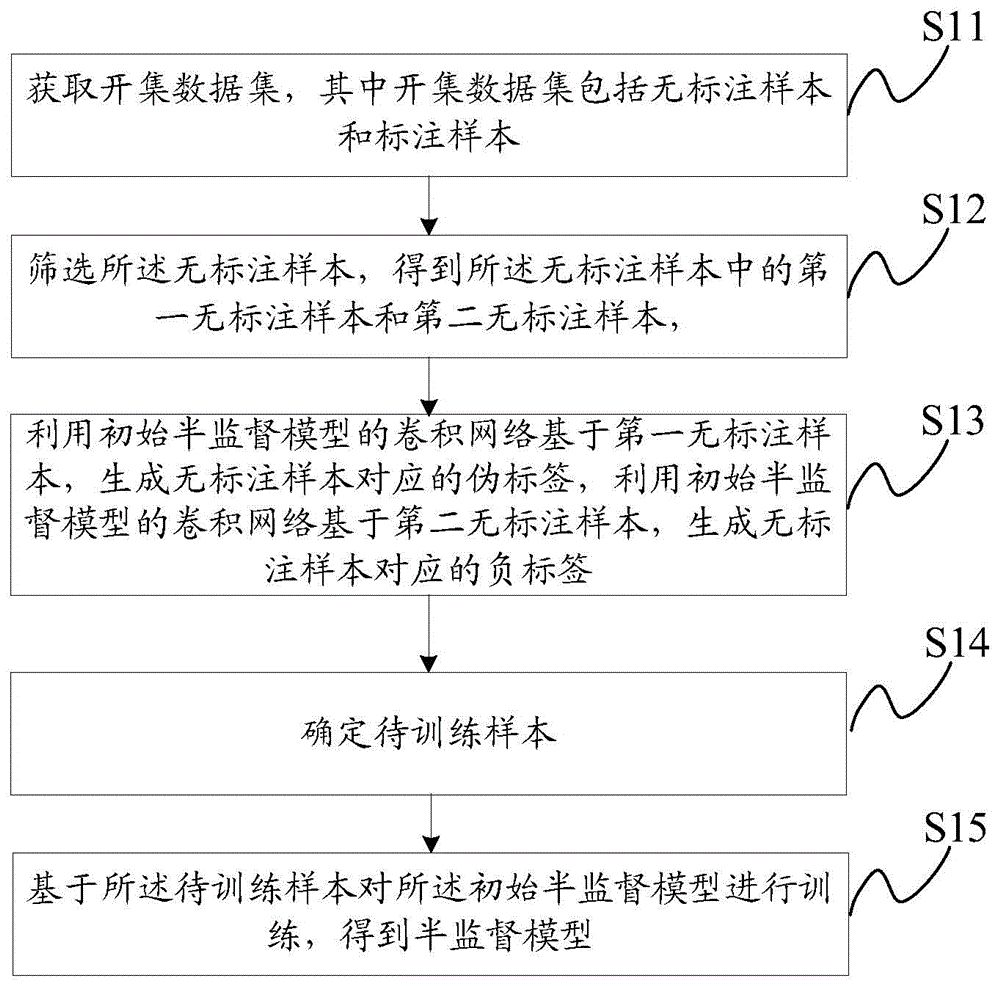
获取开集数据集,其中,开集数据集包括无标注样本和标注样本;
筛选所述无标注样本,得到所述无标注样本中的第一无标注样本和第二无标注样本,所述第一无标注样本和第二无标注样本不同;
利用初始半监督模型的卷积网络基于所述第一无标注样本,生成无标注样本对应的伪标签,利用初始半监督模型的卷积网络基于所述第二无标注样本,生成无标注样本对应的负标签;
确定待训练样本,其中,所述待训练样本中至少包括标注样本、已知类别样本以及失配样本,所述已知类别样本为所述伪标签和第一无标注样本的集合,所述失配样本为所述负标签和第二无标注样本的集合;
基于所述待训练样本对所述初始半监督模型进行训练,得到半监督模型。
可选的,所述筛选所述无标注样本,得到所述无标注样本中的第一无标注样本和第二无标注样本包括:
利用相似度指数识别第一无标注样本和第二无标注样本。
可选的,所述利用相似度指数识别出第一无标注样本和第二无标注样本,包括:
确定所述标注样本对应的特征中心;
计算所述特征中心与无标注样本的相似度指数,所述相似度指数包括方向指数或者距离指数中的至少一种;
根据相似度指数识别出第一无标注样本和第二无标注样本。
可选的,所述确定所述标注样本对应的特征中心,包括:
其中,c为标注样本中的已知类别,x为标注数据,g(x)为标注数据x在特征空间中的坐标,I[·]为指示函数,i表示样本的序号,y为样本标签,N表示标注样本总量,N
可选的,若所述待训练样本为失配样本,所述失配样本还包括正标签样本,所述正标签样本中包括正标签和复制的第二无标注样本,基于所述待训练样本对所述初始半监督模型进行训练,得到半监督模型,包括:
获取所述失配样本中的负标签对应的正标签;
复制所述失配样本中的第二无标注样本,与正标签组成正标签样本;
利用所述正标签样本与所述失配样本对初始半监督模型进行训练,得到半监督模型。
第二方面,本发明提供了一种半监督模型的训练装置,包括:
样本获取模块,用于获取开集数据集,其中,开集数据集包括无标注样本和标注样本;
筛选样本模块,用于筛选所述无标注样本,得到所述无标注样本中的第一无标注样本和第二无标注样本,所述第一无标注样本和第二无标注样本不同;
伪标签生成模块,用于利用初始半监督模型的卷积网络基于所述第一无标注样本,生成无标注样本对应的伪标签,利用初始半监督模型的卷积网络基于所述第二无标注样本,生成无标注样本对应的负标签;
待训练样本确定模块,用于确定待训练样本,其中,所述待训练样本中至少包括标注样本、已知类别样本以及失配样本,所述已知类别样本为所述伪标签和第一无标注样本的集合,所述失配样本为所述负标签和第二无标注样本的集合;
训练模块,用于基于所述待训练样本对所述初始半监督模型进行训练,得到半监督模型。
第三方面,本发明提供了一种电子设备,包括至少一个存储器和至少一个处理器,所述存储器存储一条或多条计算机可执行指令,所述处理器调用所述一条或多条计算机可执行指令,以执行如第一方面所述的训练方法。
第四方面,本发明提供了一种存储介质,所述存储介质存储一条或多条计算机可执行指令,所述一条或多条计算机可执行指令用于执行如第一方面所述的训练方法。
基于以上,本发明实施例提供了一种半监督模型的训练方法,包括:获取开集数据集,其中,开集数据集包括无标注样本和标注样本;筛选所述无标注样本,得到所述无标注样本中的第一无标注样本和第二无标注样本,所述第一无标注样本和第二无标注样本不同;利用初始半监督模型的卷积网络基于所述第一无标注样本,生成无标注样本对应的伪标签,利用初始半监督模型的卷积网络基于所述第二无标注样本,生成无标注样本对应的负标签;确定待训练样本,其中,所述待训练样本中至少包括标注样本、已知类别样本以及失配样本,所述已知类别样本为所述伪标签和第一无标注样本的集合,所述失配样本为所述负标签和第二无标注样本的集合;基于所述待训练样本对所述初始半监督模型进行训练,得到半监督模型。可见,本发明实施例中在开集数据集的基础上,通过为无标注样本生成对应的负标签,使半监督模型能够根据标注样本、已知类别样本以及失配样本进行训练,从而学习已知类别样本以及失配样本的特征差异,在所有类别下降低对失配样本的预测置信度,能够实现半监督模型的反向约束,从特征空间中分离失配样本,提升半监督模型的泛化能力。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中一种半监督模型的训练方法的步骤示意图;
图2为本发明实施例中利用相似度指数识别出第一无标注样本和第二无标注样本的步骤示意图;
图3为本发明实施例中半监督模型的训练过程的流程示意图;
图4为本发明实施例中半监督深度模型与传统半监督模型的对比图;
图5为本发明实施例中提供的基于半监督模型的训练装置的可选框图;
图6为本发明实施例中提供的电子设备的框图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
图1为本发明实施例中一种半监督模型的训练方法的步骤示意图。参考图1所示,半监督模型的训练方法的步骤可以具体包括:
步骤S11、获取开集数据集,其中,开集数据集包括无标注样本和标注样本。
步骤S12、筛选所述无标注样本,得到所述无标注样本中的第一无标注样本和第二无标注样本,所述第一无标注样本和第二无标注样本不同。
在一种可选实施例中,利用相似度指数识别第一无标注样本和第二无标注样本。其中,第一无标注样本用于生成已知类别(In-Distribution,ID)样本,所述第二无标注样本用于生成失配(Out-Of-Distribution,OOD)样本。需要说明的是,ID样本又可以被称为属于已知类别的样本,OOD样本即为不属于任何已知类别的失配样本。
具体的,参考图2所示,所述利用相似度指数识别出第一无标注样本和第二无标注样本,包括:
步骤S121、确定所述标注样本对应的特征中心;
在一种实施例中,所述确定所述标注样本对应的特征中心,包括:
其中,在公式1中,c为标注样本中的已知类别,x为标注数据,g(x)为标注数据x在特征空间中的坐标,I[·]为指示函数,i表示样本的序号,y为样本标签,N表示标注样本总量,N
步骤S122、计算所述特征中心与无标注样本的相似度指数,所述相似度指数包括方向指数或者距离指数中的至少一种。
步骤S123、根据相似度指数识别出第一无标注样本和第二无标注样本。
在确定特征中心后,可以从方向与距离两个角度对样本相似度度量。从方向上,可以利用余弦相似度依据张量夹角的余弦值评估相似度,此时将余弦相似度作为本发明实施例中的方向指数;从距离上,可以利用欧氏距离能根据张量坐标从距离上评估特征相似度,此时将欧氏距离作为本发明实施例中的距离指数。
无标注样本u与特征中心Center
进一步的,无标注样本u与欧氏距离计算分别如公式3所示,公式3如下:
在本发明实施例中,可以采用方向指数和距离指数共同作为相似度的指数。在该实施例下,根据样本的最大余弦相似度类别c
可选的,该部分的如图3所示,通过筛选的样本作为ID样本获得最大相似度类别伪标签c
可见,在本发明优选的实施例中,可以同时采用方向指数和距离指数共同作为相似度指数效果。需要说明的是,结合余弦相似度与欧氏距离,可以有效度量无标注样本与特征中心的相似度,实现对低相似度的OOD样本过滤,并对具有高相似度的ID样本生成伪标签。
步骤S13、利用初始半监督模型的卷积网络基于所述第一无标注样本,生成无标注样本对应的伪标签,利用初始半监督模型的卷积网络基于所述第二无标注样本,生成无标注样本对应的负标签。
步骤S14、确定待训练样本,其中,所述待训练样本中至少包括标注样本、已知类别样本以及失配样本,所述已知类别样本为所述伪标签和第一无标注样本的集合,所述失配样本为所述负标签和第二无标注样本的集合;
步骤S15、基于所述待训练样本对所述初始半监督模型进行训练,得到半监督模型。
在一种可选实施例中,若所述待训练样本为失配样本,所述失配样本还包括正标签样本,所述正标签样本中包括正标签和复制的第二无标注样本,基于所述待训练样本对所述初始半监督模型进行训练,得到半监督模型,包括:
获取所述失配样本中的负标签对应的正标签;
复制所述失配样本中的第二无标注样本,与正标签组成正标签样本;
利用所述正标签样本与失配样本对初始半监督模型进行训练,得到半监督模型。
可选的,在利用所述正标签样本与失配样本对初始半监督模型进行训练中的负交叉熵损失函数(Negative Cross Entry Loss,NCEL),其中,所述NCEL的表达式如下:
其中,(1-q
基于以上,本发明实施例进一步提供了本发明实施例中的半监督模型与传统的半监督模型Pseudo-Labeling、UDA、MixMatch共同在CIFAR-10开集数据集下的实验过程。参考图4所示,在CIFAR-10中的OOD样本为混合比例70%下,Pseudo-Labeling、UDA和MixMatch模型的准确率分别为74.36%、73.82%和72.96%,甚至低于监督学习76.36%的准确率,表明传统半监督已经不适用于包含OOD样本的开集训练集。而本发明实施例中提出的半监督模型,在大量OOD样本下仍然确保了网络的稳定性,缓解了传统半监督模型在OOD样本下泛化性能下降的问题,在实验中所有条件下的准确率均优于监督学习,并且在混合比例大于10%的开集数据集下,其泛化性能也优于对比的半监督学习方法,在CIFAR-10与SVHN的70%混合比例下的准确率分别为77.67%与90.89%。
基于以上,本发明实施例提供了一种半监督模型的训练方法,包括:获取开集数据集,其中,开集数据集包括无标注样本和标注样本;筛选所述无标注样本,得到所述无标注样本中的第一无标注样本和第二无标注样本,所述第一无标注样本和第二无标注样本不同;利用初始半监督模型的卷积网络基于所述第一无标注样本,生成无标注样本对应的伪标签,利用初始半监督模型的卷积网络基于所述第二无标注样本,生成无标注样本对应的负标签;确定待训练样本,其中,所述待训练样本中至少包括标注样本、已知类别样本以及失配样本,所述已知类别样本为所述伪标签和第一无标注样本的集合,所述失配样本为所述负标签和第二无标注样本的集合;基于所述待训练样本对所述初始半监督模型进行训练,得到半监督模型。可见,本发明实施例中在开集数据集的基础上,通过为无标注样本生成对应的负标签,使半监督模型能够根据标注样本、已知类别样本以及失配样本进行训练,从而学习已知类别样本以及失配样本的特征差异,在所有类别下降低对失配样本的预测置信度,能够实现半监督模型的反向约束,从特征空间中分离失配样本,提升半监督模型的泛化能力。
上述内容提供了本发明实施例中基于半监督模型的训练方法,与之相对应的,本发明一实施例还提供了半监督模型的训练装置,由于装置实施例基本相似于方法实施例,所以描述得比较简单,相关的技术特征的细节部分请参见上述提供的方法实施例的对应说明即可,下述对装置实施例的描述仅仅是示意性的。如图5所示,为本发明实施例提供的基于半监督模型的训练装置的可选框图,包括:
样本获取模块500,用于获取开集数据集,其中,开集数据集包括无标注样本和标注样本;
筛选样本模块510,用于筛选所述无标注样本,得到所述无标注样本中的第一无标注样本和第二无标注样本,所述第一无标注样本和第二无标注样本不同;
伪标签生成模块520,用于利用初始半监督模型的卷积网络基于所述第一无标注样本,生成无标注样本对应的伪标签,利用初始半监督模型的卷积网络基于所述第二无标注样本,生成无标注样本对应的负标签;
待训练样本确定模块530,用于确定待训练样本,其中,所述待训练样本中至少包括标注样本、已知类别样本以及失配样本,所述已知类别样本为所述伪标签和第一无标注样本的集合,所述失配样本为所述负标签和第二无标注样本的集合;
训练模块540,用于基于所述待训练样本对所述初始半监督模型进行训练,得到半监督模型。
本发明实施例还提供一种电子设备,该电子设备可通过装载计算机可执行指令形式(如程序形式)的上述装置,以实现本发明实施例提供的基于小样本的分类方法。可选的,图6示出了本发明实施例提供的电子设备的框图,如图6所示,该电子设备可以包括:至少一个处理器1,至少一个通信接口2,至少一个存储器3和至少一个通信总线4;
在本发明实施例中,处理器1、通信接口2、存储器3、通信总线4的数量为至少一个,且处理器1、通信接口2、存储器3通过通信总线4完成相互间的通信;显然,图示的处理器1、通信接口2、存储器3和通信总线4的通信连接示意仅是可选的;
可选的,通信接口2可以为用于进行网络通信的通信模块的接口;
处理器1可能是中央处理器CPU,或者是特定集成电路ASIC(ApplicationSpecific Integrated Circuit),或者是被配置成实施本发明实施例的一个或多个集成电路。
存储器3可能包含高速RAM存储器,也可能还包括非易失性存储器(non-volatilememory),例如至少一个磁盘存储器。
其中,存储器3存储一条或多条计算机可执行指令,处理器1调用所述一条或多条计算机可执行指令,以执行本发明实施例提供的基于小样本的分类方法。
本发明实施例还可提供一种存储介质,该存储介质可以存储一条或多条计算机可执行指令,所述一条或多条计算机可执行指令可用于执行本发明实施例提供的基于小样本的分类方法。
上文描述了本发明实施例提供的多个实施例方案,各实施例方案介绍的各可选方式可在不冲突的情况下相互结合、交叉引用,从而延伸出多种可能的实施例方案,这些均可认为是本发明实施例披露、公开的实施例方案。
虽然本发明实施例披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。