基于自监督对比学习与半监督混合的人脸表情识别方法
文献发布时间:2023-06-29 06:30:04
技术领域
本发明涉及人脸表情识别技术领域,具体为基于自监督对比学习与半监督混合的人脸表情识别方法。
背景技术
表情是人际交往中传递情感的重要方式之一,人脸表情识别是指利用计算机对检测到的人脸进行面部表情特征提取,使计算机能够按照人的思维认识对人脸表情进行相应的理解处理,并能够根据人们的需求做出响应,建立友好的、智能化的人机交互环境。近年来人脸表情识别在一系列应用,例如人机交互、社交机器人、心理健康监测等方面发挥着重要作用。
当前人脸表情识别技术大多数基于大规模高质量标签的人脸表情数据集进行应用,但是这些高质量的标签数据集往往需要专业人士花费大量时间进行处理,所需的成本是极高的。更值得注意的是,不同水平会导致标签不一致以及噪声标签,这会进一步阻碍模型的学习能力。所以开发一种减少对标签数据依赖性又同时保证人脸表情识别性能的方法是很有必要的。
发明内容
(一)解决的技术问题
针对现有技术的不足,本发明提供了基于自监督对比学习与半监督混合的人脸表情识别方法,解决了当前人脸表情识别技术耗时耗力,且成本极高以及不同水平会导致标签不一致以及噪声标签,这会进一步阻碍模型的学习能力的问题。
(二)技术方案
为实现上述目的,本发明提供如下技术方案:基于自监督对比学习与半监督混合的人脸表情识别方法,包括以下步骤:
S1、通过对无标签的人脸表情数据集进行实例级别的区分,并采用BYOL模型训练200轮,最终获得骨干模型的输出特征层以用作后续半监督方法的预训练权重;
S2、为了更好的使用对比学习模型,采用pytorch_lighting的框架进行训练,并采取了特殊的权重提取方式,具体过程为:遍历pytorch_lighting权重格式,根据resnrt的权重规范,依次提取权重字典的内容一一赋值至resnet的初始结构中,最终获得想要的部分权重后再进行半监督微调训练;
S3、先将人脸表情数据集RAF-DB上采用分割算法以划分出标签数据集以及无标签数据集;
S4、对于标签数据集直接采用预训练模型来进行全监督微调;对于无标签数据集,一方面采取自适应置信度边界的方面来划分该部分数据集为高置信度无标签数据集以及低置信度无标签数据集;对于高置信度无标签数据集采取全监督微调方法,对于低置信度无标签数据集采用监督对比学习方法SupCon来进行监督对比训练;
S5、将最终训练好的权重提取骨干,然后进行实现人脸表情识别设计,以达到输入图片及其自动判别图片为哪个人脸表情类别的效果。
优选的,所述S1中,实例级别的区分主要是指在不同的数据增强图(正样本对)下,在表示级别上最大化相同图像的相似性,而最小化不同实例的相似性(负样本对)。
优选的,所述S3中,分割算法采取特定规则,当索引为1时,将标签都打乱,然后取列表前250个作为train_labeled_idxs,剩下的为train_unlabeled_idxs;当标签索引为0以及2-6时,将所有标签打乱,然后取列表前(4000-250)/6个作为train_labeled_idxs,剩下的为train_unlabeled_idxs,此处4000标签数据值是可人为改动的。
(三)有益效果
本发明提供了基于自监督对比学习与半监督混合的人脸表情识别方法,具备以下有益效果:
本发明公开的方法是基于自监督方法的,然后配合半监督方法进行高效学习,从而实现低成本高质量的人脸表情识别。并且能够很大程度减小对大规模高质量标签数据集的依赖性。
附图说明
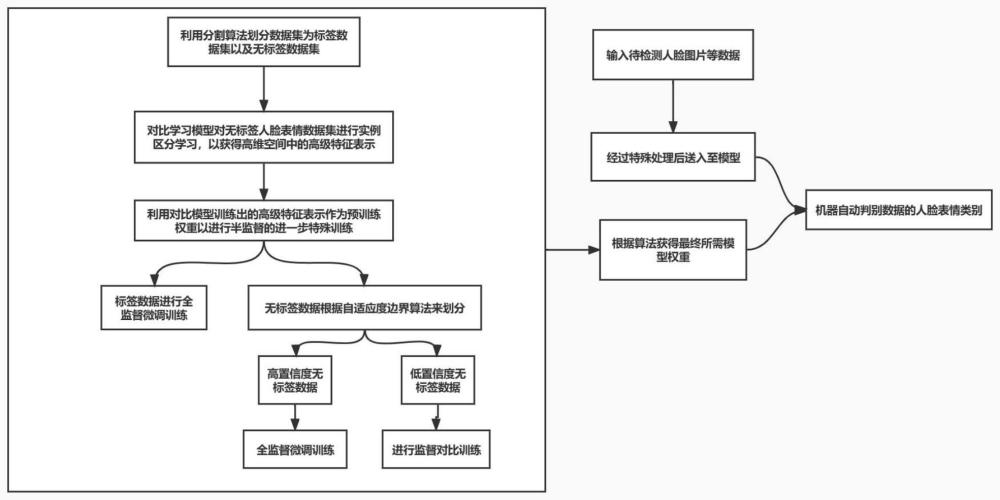
图1为本发明的方法流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明提供一种技术方案:基于自监督对比学习与半监督混合的人脸表情识别方法,包括以下步骤:
S1、通过对无标签的人脸表情数据集进行实例级别的区分,实例级别的区分主要是指在不同的数据增强图(正样本对)下,在表示级别上最大化相同图像的相似性,而最小化不同实例的相似性(负样本对),并采用BYOL或者SimSiam模型训练200轮,最终获得骨干模型的输出特征层以用作后续半监督方法的预训练权重;
S2、为了更好的使用对比学习模型,采用pytorch_lighting的框架进行训练,并采取了特殊的权重提取方式,具体过程为:遍历pytorch_lighting权重格式,根据resnrt的权重规范,依次提取权重字典的内容一一赋值至resnet的初始结构中,最终获得想要的部分权重后再进行半监督微调训练;
S3、先将人脸表情数据集RAF-DB上采用分割算法以划分出标签数据集以及无标签数据集,分割算法采取特定规则,当索引为1时,将标签都打乱,然后取列表前250个作为train_labeled_idxs,剩下的为train_unlabeled_idxs;当标签索引为0以及2-6时,将所有标签打乱,然后取列表前(4000-250)/6个作为train_labeled_idxs,剩下的为train_unlabeled_idxs,此处4000标签数据值是可人为改动的;
S4、对于标签数据集直接采用预训练模型来进行全监督微调;对于无标签数据集,一方面采取自适应置信度边界的方面来划分该部分数据集为高置信度无标签数据集以及低置信度无标签数据集;对于高置信度无标签数据集采取全监督微调方法,对于低置信度无标签数据集采用监督对比学习方法SupCon来进行监督对比训练;
S5、将最终训练好的权重提取骨干,然后进行实现人脸表情识别设计,以达到输入图片及其自动判别图片为哪个人脸表情类别的效果。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。