一种基于大数据和机器学习算法创作短视频的系统和方法
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及一种创作短视频的系统,具体是一种基于大数据和机器学习算法创作短视频的系统和方法。
背景技术
现有领域中,并没有一个科学化的、能够吸引观众的短视频创作体系和方法,短视频创作者在创作短视频时,往往根据经验确定选题、配乐、背景等短视频重要元素。囿于人脑的局限性,创作者无法穷尽浏览所有短视频,从而无法科学化的对短视频进行拆分分析,进而无法更高效的创作出受广大观众喜爱的短视频。简而言之,现有的短视频创作方法,在赢得广大观众喜爱这方面,属于大海捞针,碰运气。
发明内容
本发明的目的在于提供一种基于大数据和机器学习算法创作短视频的系统和方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种基于大数据和机器学习算法创作短视频的系统,包括数据采集模块、达人画像模块、视频特征模块、达人管理展示模块、投放效果模块和视频片段库;
所述数据采集模块分别与达人画像模块和视频特征模块连接,用于采集全网短视频,并将达人相关数据存储到达人画像模块,将视频相关数据存储到视频特征模块;
所述视频特征模块用于存储视频特征数据、以及使用该数据对视频生成形成指导性意见;
所述达人画像模块与达人管理展示模块连接,用于将各个达人的画像数据与广告主所提出的需推广产品的属性进行匹配,最终输出每个达人与产品的匹配度评分;
所述投放效果模块与视频特征模块连接,用于监控投放出去的短视频的观众反馈,并将收集到的视频数据输入到视频特征模块进行解析后,与其他视频的视频特征一起存储;
所述视频片段库分别与视频特征模块和投放效果模块连接,用于存储所有短视频片段。
作为本发明进一步的方案:所述数据采集模块包括视频抓取组件、主体标签组件、画面分解组件、文本分解组件、声音分解组件、故事线分解组件和视频效果分解组件;所述视频抓取组件分别与主体标签组件、画面分解组件、文本分解组件、声音分解组件、故事线分解组件和视频效果分解组件连接;所述主体标签组件与达人画像模块连接;所述画面分解组件、文本分解组件、声音分解组件、故事线分解组件和视频效果分解组件分别与视频特征模块连接;
所述达人画像模块包括达人画像库和与达人画像库连接的达人评分算法,所述达人画像库和达人评分算法分别与达人管理展示模块连接,所述主体标签组件与达人画像库连接;
所述视频特征模块包括与投放效果模块连接的视频特征库和与视频特征库连接的视频特征处理组件,所述画面分解组件、文本分解组件、声音分解组件、故事线分解组件和视频效果分解组件分别与视频特征库连接,所述视频片段库与视频特征处理组件连接;
所述达人管理展示模块包括达人展示页面和与达人展示页面连接的达人排期库,所述达人画像库和达人评分算法分别与达人展示页面连接。
作为本发明进一步的方案:所述视频抓取组件用于抓取短视频,采用Python语言开发,并采用开源的request、json库,其工作步骤如下:
步骤101、分析网页类型,获取爬虫参数;
步骤102、模拟浏览器发送请求,获取响应数据;
步骤103、解析数据,使用json库把json字符串转换为python可交互的数据类型;
步骤104、保存数据,将视频数据保存在目标文件夹中。
作为本发明进一步的方案:所述主体标签组件通过主体标签库和达人画像库的配合将短视频中的表演主体进行标签化处理;
主体标签库存储了若干个描述主体特征的标签,达人画像库以主体编号为唯一ID,列出若干个主体标签库中的标签,达人画像库的记录方式为0/1记录,满足该标签则为1,否则为0,达人画像库同步记录该主体满足某标签的视频的个数;
主体标签组件采用Python语言开发,其工作步骤如下:
步骤201、将短视频中的表演主体分离出来;
步骤202、将分离出来的表演主体进行编号,并与预存的主体标签库的标签做对比,计算各个标签的相关度;
步骤203、将高相关度的主体标签更新到达人画像库中,如果该标签计数本来为0,则更新为1;如果本来为1,则将记录该主体满足某标签的视频个数增加1。
作为本发明进一步的方案:所述画面分解组件将视频的画面特征,分解提取并存储,其工作步骤如下:
步骤301、将短视频中关键帧的画面内各个基础特征采用图像识别算法对比图文预训练神经网络模型CLIP提取出来;
步骤302、将分离出来的特征的值存储到视频特征库中的相关列中。
作为本发明进一步的方案:所述文本分解组件将视频的文本特征分解提取并存储,其工作步骤如下:
步骤401、将短视频中全部文案通过语音识别算法转变为文字;
步骤402、将文字稿采用语义识别算法分解出感兴趣的标签;
步骤403、将感兴趣的标签存储到视频特征库中的相关列中。
作为本发明进一步的方案:所述声音分解组件将视频的声音特征分解提取并存储,其工作步骤如下:
步骤501、将短视频中全部音轨通过音色处理算法转换成计算机能读懂的带音频属性的可量化信息串;
步骤502、将音轨信息串的波频、波长信息进行统计汇总,形成对语气、语调标签的量化指标;
步骤503、将以上量化指标存储到视频特征库中的相关列中。
作为本发明进一步的方案:所述故事线分解组件将视频的情节特征分解提取并存储,其工作步骤如下:
步骤601、输入文本分解组件中的执行结果;
步骤602、将文字稿采用语义识别算法和情绪归类算法分解出故事结构、结构占比、结构时长的量化属性;
步骤603、将以上量化属性存储到视频特征库中的相关列中。
作为本发明进一步的方案:所述视频效果分解组件将提取视频播放效果特征并存储,其工作步骤如下:
步骤701、将短视频的播放效果指标统计提取;
步骤702、将以上量化属性存储到视频特征库中的相关列中。
作为本发明进一步的方案:所述视频特征库以视频编号为唯一ID,以数据采集模块的输出为输入,将量化分解后的视频分为画面、文本、声音、故事线这四个大维度存储。
作为本发明进一步的方案:所述视频特征处理组件采用视频特征库的特征数据,输出短视频优化建议,其工作步骤如下:
步骤801、接收视频特征库的特征数据输入;
步骤802、以各个视频的播放效果为目标变量,以各个视频的画面、文本、声音、故事线、达人画像维度的特征为预测变量,使用有监督机器学习算法建模;
步骤803、提取建模过程中的各个预测变量的特征重要性;
步骤804、将特征重要性排名输出给用户。
作为本发明进一步的方案:所述视频片段库存储的短视频片段包括视频抓取组件的生产物、以及使用本系统的创作者出品的生产物;视频片段库中的视频拆解组件将视频拆解成视频片段,其工作步骤如下:
步骤901、接收视频抓取组件抓取的视频片段;
步骤902、接收创作者拍摄好的完整视频;
步骤903、使用多模态视频理解技术对视频进行拆解,成为片段;
步骤904、将视频片段编号,并存储到视频片段库中。
作为本发明进一步的方案:所述达人排期库内存储了达人可以接拍视频的日期和时间,以及在各个日期拍摄的收费,其数据来自于达人展示页面,工作步骤如下:
步骤1001、广告主在达人展示页面浏览达人数据并点击向感兴趣的达人发起广告拍摄邀约;
步骤1002、达人展示页面接收到该邀约后,通知达人确认;
步骤1003、达人确认后,该邀约数据录入达人排期库,达人可接拍视频的时间减少;
步骤1004、达人排期库向达人展示页面发送信息,更新达人可接拍视频时间展示。
作为本发明进一步的方案:所述达人展示页面采用HTML网页,向广告主展示各个达人的画像信息和排期信息,供广告主挑选合作,其展示数据来自于达人画像库和达人排期库,工作步骤如下:
步骤1101、接收达人画像库的数据及其数据更新;
步骤1102、接收达人排期库的排期数据及其数据更新;
步骤1103、接收达人评分算法的数据及其数据更新;
步骤1104、在HTML页面向登陆用户展示数据。
一种基于大数据和机器学习算法创作短视频的方法,包括如下步骤:
步骤1、广告主提出广告需求;
步骤2、达人画像模块从数据采集模块获取达人数据;
步骤3、达人评分算法获取达人画像模块的达人数据,并通过达人与广告主的匹配评分选取达人;
步骤4、视频特征模块采用语义理解算法和视频特征提取算法从数据采集模块获取并拆解出视频特征数据,并依此向编剧团队提供选题、文案、时长的拍摄建议;
步骤5、编剧团队采用以上建议,根据选取的达人特点设计剧本,并监督达人拍摄;
步骤6、编剧团队将视频剪辑成片段存入视频片段库;
步骤7、视频特征模块将新视频进行语义理解和视频特征提取与分类后的特征再存入视频特征库;
步骤8、视频被投放到短视频平台;
步骤9、投放效果模块采集以上投放的短视频的投放效果数据;
步骤10、投放效果模块调用推荐优化算法,输入短视频的投放效果数据;
步骤11、推荐优化算法调用视频特征模块,输入视频特征;
步骤12、推荐优化算法,结合步骤10和步骤11中的视频特征和投放效果,采用有监督学习模型,科学地给出重新剪辑建议;
步骤13、编剧团队重新剪辑视频,并调用视频特征模块将新视频的特征存入视频特征库,重复步骤8-步骤13,反复优化短视频。
与现有技术相比,本发明的有益效果是:
本系统由数据采集模块,达人画像模块,视频特征模块,达人管理展示模块,投放效果模块和视频片段库构成,将本系统和本方法命名为视频引擎优化,英文名为VideoEngine Optimization,简称VEO。本发明应用大数据分析技术和机器学习算法,采集全网数百万条优质短视频,将每条短视频抽象量化为数百个视频元素,使得所有短视频均可以被量化分析。
该发明主要作用为分析短视频和优化短视频,相比现有的专家分析法,该发明通过大数据分析技术,能够让使用者在相同时间内,分析50倍以上的短视频数量。相比现有的短视频优化技术,该发明使得短视频优化过程能够系统化,流程化地由机器学习算法批量完成,让使用者的优化效率提升10倍以上。该发明创造性地将最先进的机器学习算法和图像识别算法应用到了短视频优化的领域中。
视频特征模块根据短视频内容的情节进展拆解短视频,将拆解后的短视频片段构建成一个海量的视频片段库,使得创作者能够更加方便的根据想要的视频元素找到相应片段,然后快速组装视频,快速迭代。投放效果模块能够监测短视频投放到抖音,快手等短视频平台后的投放效果,如:点赞数,圈粉数等,并利用大数据分析技术,给出创作者反馈意见,如:应该缩短时长,调整主题,增加视频主角等,使得创作者能够快速修正,重新组装,再次投放。达人管理与展示模块能够让广告主快速的筛选出适合自己产品和品牌的达人。数据采集模块和视频片段库是该发明功能性模块,为其他模块提供视频原料输入,支持其他模块的高效运行。
附图说明
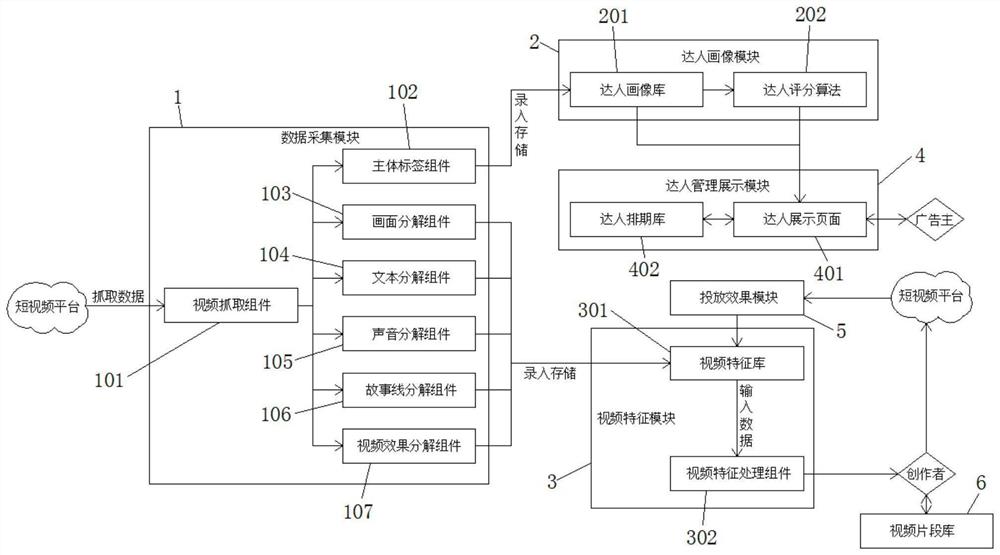
图1为一种基于大数据和机器学习算法创作短视频的系统和方法的系统图。
图中:1、数据采集模块;101、视频抓取组件;102、主体标签组件;103、画面分解组件;104、文本分解组件;105、声音分解组件;106、故事线分解组件;107、视频效果分解组件;2、达人画像模块;201、达人画像库;202、达人评分算法;3、视频特征模块;301、视频特征库;302、视频特征处理组件;4、达人管理展示模块;401、达人展示页面;402、达人排期库;5、投放效果模块;6、视频片段库。
具体实施方式
下面结合具体实施方式对本专利的技术方案作进一步详细地说明。
请参阅图1,一种基于大数据和机器学习算法创作短视频的系统,包括数据采集模块1、达人画像模块2、视频特征模块3、达人管理展示模块4、投放效果模块5和视频片段库6;
所述数据采集模块1分别与达人画像模块2和视频特征模块3连接,用于采集全网短视频,解析提取后作为整个系统的喂养材料,并将达人相关数据存储到达人画像模块2,将视频相关数据存储到视频特征模块3;
所述视频特征模块3用于存储视频特征数据、以及使用该数据对视频生成形成指导性意见;
所述达人画像模块2与达人管理展示模块4连接,用于将各个达人的画像数据,如:女性,中年,高颜值,身高,长发,粉丝数,带货转化率等,与广告主所提出的需推广产品的属性进行匹配,最终输出每个达人与产品的匹配度评分;
所述投放效果模块5与视频特征模块3连接,用于监控投放出去的短视频的观众反馈,并将收集到的视频数据输入到视频特征模块3进行解析后,与其他视频的视频特征一起存储;投放效果模块5的工作原理数据采集模块1的视频抓取组件101类似,其二者差异性在于:视频抓取组件101抓取的系非经过本系统生产及投放的视频,投放效果模块5采集的是本系统产生并投放的视频;投放效果模块5仅采集投放效果数据,而视频抓取组件101同时采集视频的其他维度数据,引入投放效果模块5的作用在于减少冗余计算,降低系统运转负荷。
所述视频片段库6分别与视频特征模块3和投放效果模块5连接,用于存储所有短视频片段。
进一步的,所述数据采集模块1包括视频抓取组件101、主体标签组件102、画面分解组件103、文本分解组件104、声音分解组件105、故事线分解组件106和视频效果分解组件107;所述视频抓取组件101分别与主体标签组件102、画面分解组件103、文本分解组件104、声音分解组件105、故事线分解组件106和视频效果分解组件107连接;所述主体标签组件102与达人画像模块2连接;所述画面分解组件103、文本分解组件104、声音分解组件105、故事线分解组件106和视频效果分解组件107分别与视频特征模块3连接;
所述达人画像模块2包括达人画像库201和与达人画像库201连接的达人评分算法202,所述达人画像库201和达人评分算法202分别与达人管理展示模块4连接,所述主体标签组件102与达人画像库201连接;达人评分算法202的作用是基于达人画像库201内的达人画像数据,和广告主给出的产品与品牌画像数据,针对每一个待投产品计算出达人和待投放产品的匹配度。达人评分算法202使用Python语言研发,底层算法采用无监督机器学习算法,在此基础上叠加有监督学习算法,采用了先归类后评分的组合学习技术。
所述视频特征模块3包括与投放效果模块5连接的视频特征库301和与视频特征库301连接的视频特征处理组件302,所述画面分解组件103、文本分解组件104、声音分解组件105、故事线分解组件106和视频效果分解组件107分别与视频特征库301连接,所述视频片段库6与视频特征处理组件302连接;
所述达人管理展示模块4包括达人展示页面401和与达人展示页面401连接的达人排期库402,所述达人画像库201和达人评分算法202分别与达人展示页面401连接。
进一步的,所述视频抓取组件101用于抓取短视频,采用Python语言开发,并采用开源的request、json库,其工作步骤如下:
步骤101、分析网页类型,获取爬虫参数;
步骤102、模拟浏览器发送请求,获取响应数据;
步骤103、解析数据,使用json库把json字符串转换为python可交互的数据类型;
步骤104、保存数据,将视频数据保存在目标文件夹中。
进一步的,所述主体标签组件102通过主体标签库和达人画像库201的配合将短视频中的表演主体,如:人,动画角色等进行标签化处理;主体标签库存储了若干个描述主体特征的标签,如:女性,中年,高颜值,身高,长发等。达人画像库201以主体编号为唯一ID,列出若干个主体标签库中的标签,达人画像库201的记录方式为0/1记录,满足该标签则为1,否则为0,达人画像库201同步记录该主体满足某标签的视频的个数;
主体标签组件102采用Python语言开发,其工作步骤如下:
步骤201、将短视频中的表演主体分离出来;
步骤202、将分离出来的表演主体进行编号,并与预存的主体标签库的标签做对比,计算各个标签的相关度;
步骤203、将高相关度的主体标签更新到达人画像库201中,如果该标签计数本来为0,则更新为1;如果本来为1,则将记录该主体满足某标签的视频个数增加1。
进一步的,所述画面分解组件103将视频的画面特征,如:清晰度,场景属性,道具,色调等标签分解提取并存储,该组件及下面的文本分解组件104,声音分解组件105,故事线分解组件106均依赖于视频特征模块3中的视频特征库301存在,视频特征库301以视频编号为唯一ID,它记录了每个视频的画面,文本,声音,故事线的详细属性。画面分解组件103的工作步骤如下:
步骤301、将短视频中关键帧的画面内各个基础特征采用图像识别算法对比图文预训练神经网络模型CLIP(Contrastive Language-Image Pre-training NeuralNetwork)提取出来;
步骤302、将分离出来的特征的值存储到视频特征库301中的相关列中。
进一步的,所述文本分解组件104将视频的文本特征,如:主题,关键词,语法等标签分解提取并存储,其工作步骤如下:
步骤401、将短视频中全部文案通过语音识别算法转变为文字;
步骤402、将文字稿采用语义识别算法分解出感兴趣的标签;
步骤403、将感兴趣的标签存储到视频特征库301中的相关列中。
进一步的,所述声音分解组件105将视频的声音特征,如:语气,语调,风格等标签分解提取并存储,其工作步骤如下:
步骤501、将短视频中全部音轨通过音色处理算法转换成计算机能读懂的带音频属性的可量化信息串;
步骤502、将音轨信息串的波频、波长信息进行统计汇总,形成对语气、语调标签的量化指标;
步骤503、将以上量化指标存储到视频特征库301中的相关列中。
进一步的,所述故事线分解组件106将视频的情节特征,如:故事结构,结构占比,结构时长等标签分解提取并存储,其工作步骤如下:
步骤601、输入文本分解组件104中第一步的执行结果;
步骤602、将文字稿采用语义识别算法和情绪归类算法分解出故事结构、结构占比、结构时长的量化属性;
步骤603、将以上量化属性存储到视频特征库301中的相关列中。
进一步的,所述视频效果分解组件107将提取视频播放效果特征,如:完播率,播放量,点赞数等指标并存储,其工作步骤如下:
步骤701、将短视频的播放效果指标统计提取;
步骤702、将以上量化属性存储到视频特征库301中的相关列中。
进一步的,所述视频特征库301以视频编号为唯一ID,以数据采集模块1的输出为输入,将量化分解后的视频分为画面、文本、声音、故事线这四个大维度存储。
进一步的,所述视频特征处理组件302采用视频特征库301的特征数据,输出短视频优化建议,其工作步骤如下:
步骤801、接收视频特征库301的特征数据输入;
步骤802、以各个视频的播放效果为目标变量,以各个视频的画面、文本、声音、故事线、达人画像维度的特征为预测变量,使用有监督机器学习算法建模;
步骤803、提取建模过程中的各个预测变量的特征重要性;
步骤804、将特征重要性排名输出给用户。该结果直接显示,存储在系统闪存中保留1天,不存储进数据库做长期保存。每天早上7点该组件基于最新数据重新生成一次。
进一步的,所述视频片段库6存储的短视频片段包括视频抓取组件101的生产物、以及使用本系统的创作者出品的生产物;该模块的作用在于方便创作者快速查阅及剪辑出新的短视频。视频片段库6中的视频拆解组件将视频拆解成视频片段,其工作步骤如下:
步骤901、接收视频抓取组件101抓取的视频片段;
步骤902、接收创作者拍摄好的完整视频;
步骤903、使用多模态视频理解技术对视频进行拆解,成为片段;
步骤904、将视频片段编号,并存储到视频片段库6中。
进一步的,所述达人排期库402内存储了达人可以接拍视频的日期和时间,以及在各个日期拍摄的收费,其数据来自于达人展示页面401,工作步骤如下:
步骤1001、广告主在达人展示页面401浏览达人数据并点击向感兴趣的达人发起广告拍摄邀约;
步骤1002、达人展示页面401接收到该邀约后,通知达人确认;
步骤1003、达人确认后,该邀约数据录入达人排期库402,达人可接拍视频的时间减少;
步骤1004、达人排期库402向达人展示页面401发送信息,更新达人可接拍视频时间展示。
进一步的,所述达人展示页面401采用HTML网页,向广告主展示各个达人的画像信息和排期信息,供广告主挑选合作,其展示数据来自于达人画像库201和达人排期库402,工作步骤如下:
步骤1101、接收达人画像库201的数据及其数据更新;
步骤1102、接收达人排期库402的排期数据及其数据更新;
步骤1103、接收达人评分算法202的数据及其数据更新;
步骤1104、在HTML页面向登陆用户展示数据。
一种基于大数据和机器学习算法创作短视频的方法,包括如下步骤:
步骤1、广告主提出广告需求;
步骤2、达人画像模块2从数据采集模块1获取达人数据;
步骤3、达人评分算法202获取达人画像模块2的达人数据,并通过达人与广告主的匹配评分选取达人;
步骤4、视频特征模块3采用语义理解算法和视频特征提取算法从数据采集模块1获取并拆解出视频特征数据,并依此向编剧团队提供选题、文案、时长的拍摄建议;
步骤5、编剧团队采用以上建议,根据选取的达人特点设计剧本,并监督达人拍摄;
步骤6、编剧团队将视频剪辑成片段存入视频片段库6;
步骤7、视频特征模块3将新视频进行语义理解和视频特征提取与分类后的特征再存入视频特征库301;
步骤8、视频被投放到短视频平台,如:抖音,快手,小红书;
步骤9、投放效果模块5采集以上投放的短视频的投放效果数据,如:点赞数,播放量,完播率等;
步骤10、投放效果模块5调用推荐优化算法,输入短视频的投放效果数据;
步骤11、推荐优化算法调用视频特征模块3,输入视频特征;
步骤12、推荐优化算法,结合步骤10和步骤11中的视频特征和投放效果,采用有监督学习模型,科学地给出重新剪辑建议;
步骤13、编剧团队重新剪辑视频,并调用视频特征模块3将新视频的特征存入视频特征库301,重复步骤8-步骤13,反复优化短视频。
上面对本专利的较佳实施方式作了详细说明,但是本专利并不限于上述实施方式,在本领域的普通技术人员所具备的知识范围内,还可以在不脱离本专利宗旨的前提下做出各种变化。
- 一种基于大数据和机器学习算法创作短视频的系统和方法
- 一种基于大数据的手机短视频流量时延控制方法及系统