一种大数据任务调度方法
文献发布时间:2023-06-29 06:30:04
技术领域
本发明涉及计算机技术领域,尤其涉及一种大数据任务调度方法。
背景技术
大数据,或称巨量资料,指的是所涉及的资料量规模巨大到无法透过主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。数据种类多,量大,由于数据的时效性,要求各类数据生成需要并行运行,容易导致数据错乱。由于大数据集群服务器一直需要高负荷处理大量数据, 容易出现波动,有时集群还会崩溃, 导致数据处理异常。
现有的大数据任务调度方式大数据计算场景中采用的调度方式主要为两种:(1)定时调度:指定执行时间进行一次或多次周期执行,但该调度方式依赖时间周期,使用场景受限;(2)依赖调度:直接批量创建的一组带依赖关系的任务,现有的依赖调度方式主要是通过任务的依赖关系建立一系列具备关联关系的任务链,通过任务链绘制树状关系图,这种方法可以相对清楚完整地展示各任务之间的依赖关系,但是大数据的数据量庞大,任务链的建立工作复杂。
发明内容
因此,为解决上述问题,本发明提供了一种大数据任务调度方法。
本发明是通过以下技术方案实现的:
一种大数据任务调度方法,包括以下步骤:
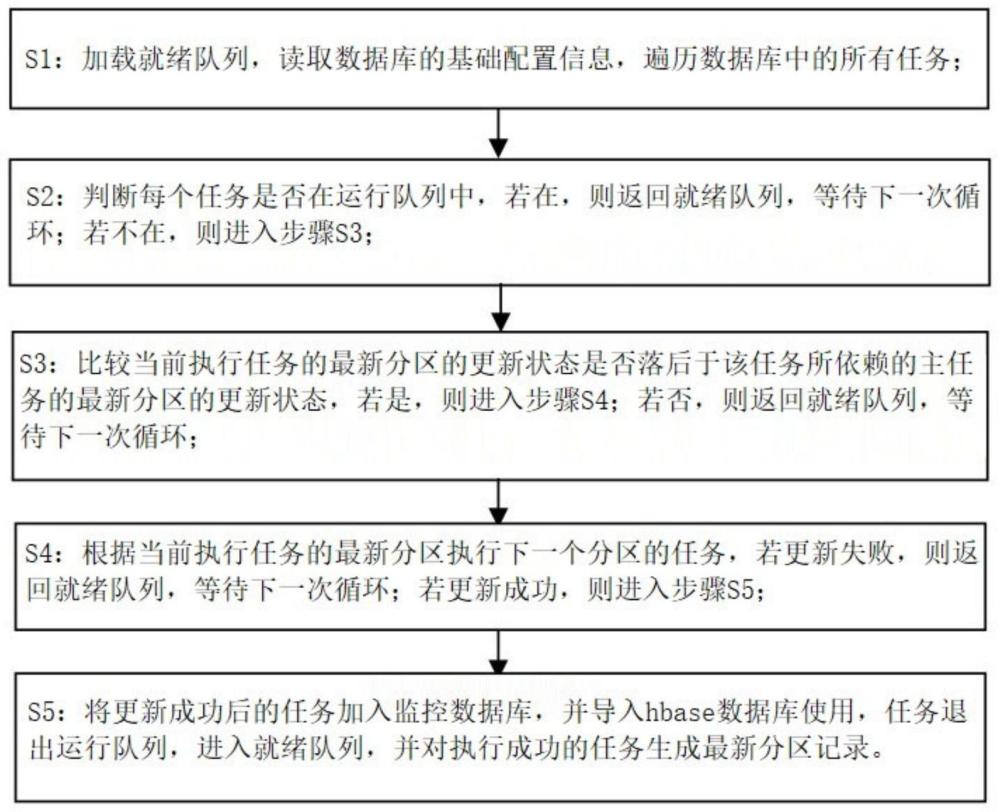
S1:加载就绪队列,读取数据库的基础配置信息,遍历数据库中的所有任务;
S2:判断每个任务是否在运行队列中,若在,则返回就绪队列,等待下一次循环;若不在,则进入步骤S3;
S3:比较当前执行任务的最新分区的更新状态是否落后于该任务所依赖的主任务的最新分区的更新状态,若是,则进入步骤S4;若否,则返回就绪队列,等待下一次循环;
S4:根据当前执行任务的最新分区执行下一个分区的任务,若更新失败,则返回就绪队列,等待下一次循环;若更新成功,则进入步骤S5;
S5:将更新成功后的任务加入监控数据库,并导入hbase数据库使用,任务退出运行队列,进入就绪队列,并对执行成功的任务生成最新分区记录。
优选的,所述基础配置信息包括数据库地址账号密码、hdfs信息、hbase信息,所述数据库内的信息至少包括所有任务的最新分区记录以及所有任务在上一次循环中的执行结果。
优选的,每个任务的脚本中编入有该任务与其他任务的依赖关系,以及与该任务具备依赖关系的任务的名称。
优选的,所述步骤S3包括以下步骤:
S31:通过当前执行任务的脚本中编入的依赖关系找出该任务依赖的所有主任务;
S32:分别提取出当前执行任务和其主任务的最新分区记录;
S33:比较当前执行任务与其主任务的最新分区记录,若当前执行任务的最新分区比主任务的最新分区落后,则进入步骤S4;若当前执行任务的最新分区不比主任务的最新分区落后,则返回就绪队列,等待下一次循环。
优选的,所述最新分区记录包括任务的名称以及该任务的最新分区信息。
优选的,步骤S4、S5中,若当前执行任务更新失败或者执行失败,则将该任务标记为数据异常。
优选的,通过任务的分区数量和/或最新分区所标记的时间判断该任务的最新分区的更新状态。
本发明技术方案的有益效果主要体现在:
1、通过指明任务的依赖关系,记录各个任务的最新记录,同时将正在运行的任务和准备运行的任务通过队列区分,有效的处理了多个任务并行运行而导致的错乱问题,单次执行中,任务间调度的关系简单,执行效率高,不易出错且适用范围广。
2、采用循环队列搭配最新分区记录的方式保证了数据的稳定性。
3、当集群波动导致任务数据异常时, 将该任务标记为数据异常,提醒工作人员处理数据,同时标记为数据异常的任务依然排队进入下一次循环,防止遗漏。
附图说明
图1:是一种大数据任务调度方法的步骤示意图;
图2:是步骤S1、S2的流程示意图。
具体实施方式
为使本发明的目的、优点和特点能够更加清楚、详细地展示,将通过下面优选实施例的非限制性说明进行图示和解释。该实施例仅是应用本发明技术方案的典型范例,凡采取等同替换或者等效变换而形成的技术方案,均落在本发明要求保护的范围之内。
同时声明,在方案的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“前”、“后”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
此外,本方案中的术语“第一”、“第二”仅用于描述目的,而不能理解为指示或者暗示对重要性的排序,或者隐含指明所示的技术特征的数量。因此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明中,“多个”的含义是两个或者两个以上,除非另有明确具体的限定。
本发明揭示了一种大数据任务调度方法,具体地,本方法主要通过多表协同和单表执行两个部分组成,其中,数据库在进入循环之前具有一个用于表示主任务的原始表格,数据库中的所有任务均依赖主任务,并分别建立依赖原始表格的任务表,在任务的循环过程中,在任务表中建立分区,通过更新、记录任务表中的分区信息了解任务的更新状态,多表协同是任务正式执行之前的准备工作,主要包括同时读取数据库中所有任务的基础配置信息,并同步判断这些任务是否正在运行,避免因重复执行降低工作效率;单表执行是逐一判断每个任务是否为最新状态,以及对未更新的任务进行更新的过程。
如图1所示,一种大数据任务调度方法具体包括以下步骤:
S1:加载就绪队列,读取数据库的基础配置信息,遍历数据库中的所有任务;
其中,所述就绪队列中排队的是当前不在运行,准备进入下一次循环的任务,所述基础配置信息包括数据库地址账号密码、hdfs信息、hbase信息,通过登录所述数据库地址账号密码可以监控数据库内的所有任务并读取任务的信息, 所述数据库内的信息至少包括所有任务的最新分区记录以及所有任务在上一次循环中的执行结果,所述hdfs信息用于访问hadoop集群, 所述hbase信息用于存储业务数据。
S2:判断每个任务是否在运行队列中,若在,则返回就绪队列,等待下一次循环;若不在,则进入步骤S3;
其中,如图2所示,所述最新分区记录包括任务的名称以及该任务的最新分区信息,所述运行队列中的任务是正在执行的任务,步骤S2中,先加载运行队列,通过判断任务是否在运行队列中,可以避免单个任务同时运行,防止更新过程中出现错乱,同时避免因重复执行降低工作效率。
S3:比较当前执行任务的最新分区的更新状态是否落后于该任务所依赖的主任务的最新分区的更新状态,若是,则进入步骤S4;若否,则返回就绪队列,等待下一次循环;
所述步骤S3包括以下步骤:
S31:通过当前执行任务的脚本中编入的依赖关系找出该任务依赖的所有主任务;
其中,每个任务的脚本中编入有该任务与其他任务的依赖关系,以及与该任务具备依赖关系的任务的名称,通过当前执行任务的脚本中的依赖关系可以检索得到当前执行任务所依赖的所有主任务的名称,并通过主任务的名称在数据库中检索并提取出该主任务的最新分区记录。
S32:分别提取出当前执行任务和其主任务的最新分区记录;
S33:比较当前执行任务与其主任务的最新分区记录,若当前执行任务的最新分区与主任务的最新分区更新状态一致,则返回就绪队列,等待下一次循环;若当前执行任务的最新分区比主任务的最新分区落后,则进入步骤S4。
在一实施例中,可通过任务的分区数量来判断该任务的最新分区的更新状态,该判断方式适用于在初始状态下,每个任务的任务表中的分区数量都是一致的情况,在对其中一个任务进行更新后,该任务中的分区数量增加,在判断任务的最新分区的更新状态时,通过比较两个任务的任务表中分区的数量的大小,可以得出两个任务的更新次数,从而判断两个任务最新分区的更新状态。
在另一实施例中,最新分区所标记的时间判断该任务的最新分区的更新状态,在生成当前执行任务的最新分区记录的同时,标记最新分区的更新时间,在判断任务的最新分区的更新状态时,通过比较两个任务的任务表中分区的更新时间的早晚,可以判断两个任务最新分区的更新状态。
在其他实施例中,还可以通过其他现有的标记方式记录、判断该任务的最新分区的更新状态,在此不做赘述。
S4:根据当前执行任务的最新分区执行下一个分区的任务,若更新失败,则返回就绪队列,等待下一次循环;若更新成功,则进入步骤S5;
具体地,在一次循环中,一个任务只能更新一个分区,若当前执行任务的分区和其主任务之间相差多个分区,则需要通过多次循环,直至当前执行任务的分区和所有其依赖的主任务之间的更新状态一致时,在下一次循环的步骤S33中,判断该任务的最新分区与主任务的最新分区更新状态一致,则返回就绪队列,等待下一次循环。
S5:将更新成功后的任务加入监控数据库,并导入hbase数据库使用,任务退出运行队列,进入就绪队列,并对执行成功的任务生成最新分区记录。
在一实施例中,还包括,在步骤S4、S5中,若当前执行任务更新失败或者执行失败,则将该任务标记为数据异常,同时,可以将标记为数据异常的任务的相关数据复制在一个异常任务数据库中,并提示工作人员处理,更新失败和执行失败的任务继续进入下一次循环,直至异常数据处理完成后,按上述步骤完成更新,异常数据的处理方法为现有技术,在此不做赘述。
本发明尚有多种实施方式,凡采用等同变换或者等效变换而形成的所有技术方案,均落在本发明的保护范围之内。
- 一种大数据平台中的任务调度方法、装置、设备及介质
- 一种风电大数据平台的计算任务调度方法、装置和设备