一种OCR文本纠错方法
文献发布时间:2024-01-17 01:28:27
技术领域
本发明属于数据处理领域,具体涉及一种OCR文本纠错方法。
背景技术
近几十年来,书籍、报纸文章和文化档案等文本资源的大规模数字化一直在进行,使这些资源可以公开用于研究。通过光学字符识别(Optical Character Recognition,简称OCR)将文档图像转换为机器可读的文本,从而实现了一种使用自动化工具探索大量文档语料库的现实方式,例如为文本搜索和机器翻译建立索引。近年来深度学习在OCR领域取得了巨大的成功,但OCR应用中识别错误时有出现。错误的识别结果不仅难以阅读和理解,同时也降低文本的信息价值。在某些领域,如医疗行业,识别错误可能带来巨大的损失。因此如何降低OCR任务的错字率受到学术界和工业界的广泛关注。现有的OCR文本纠错方案主要聚焦于纯文本图像的OCR文本错误纠正,这些方案在面对如发票,银行流水等非结构化文档图像的OCR文本纠错时,将难以利用文档自身的语义信息就行纠错。本发明基于微软团队研发的多模态文档理解预训练模型Layout Language Model version 2.0,通过调整模型以适配文本纠错任务,提升了对非结构化文档图像的OCR文本的纠错性能。
现有的OCR文本纠错方法主要从自然语言处理的角度来对文本进行纠错,非常依赖于文档上下文包含的语义信息。而对于发票,银行流水等非结构化文档,其本身包含文本和数字,文本段之间并没有较强的语义关系,因此现有的方法对于这类文档图像的纠错效果并不理想。
发明内容
文档图像本身包含丰富的布局和视觉信息,有效地利用这些信息可以提升OCR文本纠错的性能。得益于微软团队研发的多模态文档理解预训练模型,其涉及图像文本对齐,以及遮罩式视觉语言模型等预训练任务,使得模型可以提取出文档图像的布局和视觉信息。本发明在编码器后链接一个全连接层(Dense Layer)作为解码器(Decoder)。在解码器解码过程中,使用集束搜索(Beam Search)方法优化解空间的搜索路径,得到排名前K(K为集束搜索的搜索宽度)的候选结果。再对候选结果通过log_softmax函数计算出概率分布,最终从概率分布中选出概率分数最高的候选作为纠错后的文本。
本发明提出的一种OCR文本纠错方法,具体包括如下步骤:
步骤1:数据采集与预处理;
步骤1.1:采集扫描图片,获取扫描图片的OCR原始文本,对获取的OCR原始文本进行人工校对,得到对应的人工校对文本,然后将获取的数据分为训练集、验证集和测试集;
步骤1.2:进行文本对齐;
将OCR原始文本与人工校对文本进行对齐,使得OCR原始文本与人工校对文本之间的编辑距离最小,所述编辑距离是针对两个字符串的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串;将OCR对齐文本和人工校对对齐文本合并,形成文本对;
步骤1.3:对文本对中的文本进行窗口分割,窗口分割时的滑动步长小于窗口的长度;
步骤1.4:移除文本对中的占位符;
步骤1.5:将步骤1.4得到的文本转换为词向量;
步骤1.6:对每个字符计算出一个边框;
步骤1.7:使用python图像处理函数库cv2加载扫描图片,加载后的图片以三维张量I的形式存储;
步骤2:采用步骤1得到的数据训练一个纠错模型,该纠错模型包括:编码器和解码器,所述编码器包括:文本编码器、图像编码器、布局编码模块、多模态编码器,解码器为全连接层;多模态编码器的输出连接解码器的输入;
所述文本编码器包括文本向量编码器,分段向量编码器,一维位置向量编码器;将步骤1.5得到的词向量分别经过文本向量编码器、分段向量编码器、一维位置向量编码器分别得到文本向量编码WordEmbedding(S)、分段向量编码SegEmb(s
T=WordEmbedding(S)+SegEmb(s
所述图像编码器包括:视觉编码器,线性投影层,一维位置编码器,分段向量编码器;将步骤1.7得到的三维张量I通过视觉编码器后得到特征向量,再平均池化为固定尺寸;然后依次进行按行展开,然后经过线性投影层得到特征向量序列Proj(VisTokEmb(I));将特征向量补充一维位置向量和分段向量后,经过分段向量编码器后得到SegEmb(s
将三个部分相加得到图像编码V:
V=Proj(VisTokEmb(I))+PosEmb1D(P
所述布局编码模块是对步骤1.6得到的边框所表示的二维位置信息进行编码;
所述多模态编码器为融合文本编码器、图像编码器、布局编码模块的输出;
所述纠错模型的损失函数为:
其中,t为标签y
步骤3:遇到新的待纠错文本后,采用步骤1的方法进行预处理,然后采用步骤2训练好的纠错模型进行纠错。
进一步的,所述步骤1.2中编辑距离的计算方法为:
A1:给定OCR原始文本序列A={a
定义:
LD(A,B)表示字符串A和字符串B的编辑距离,即将字符串A通过插入,删除和修改字符的方式转换为字符串B所用的最少操作次数;
LD(A,B)=0表示两个字符串的长度和内容完全一样;
LD(i,j)=LD(a
A2:初始一个分数矩阵H,使行i表示字符a
A3:计算矩阵H中每一项的值LD(i,j):
如果字符串A的第i个字符与字符串B的第j个字符串相同,即a
若a
A4:回溯,从矩阵右下角L(m,n)处开始:
若a
若a
A5:初始化结果序列A’和B’为空序列,即A′={},B’={};
A6:根据步骤A4中产生的回溯路径,写出匹配字符串:
从最右下角单元格LD(m,n)开始回溯,若回溯到第i行第j列单元格的左上角即第i-1行第j-1列单元格,将a
若回溯到上边即第i-1行第j列单元格,将a
若回溯到左边即第i行第j-1列单元格,将占位符^添加到匹配序列A′,将b
进一步的,所述步骤1.6的具体方法为:
B1:边框简化:
原始边框坐标为:[x
简化后的边框坐标为:[x′
x′
x′
其中,min(*)和max(*)分别表示取最小值和最大值的操作;
B2:边框正则化:
对顶点坐标为[x′
其中W表示图片的宽度,H表示图片高度。
进一步的,所述步骤2中的布局编码模块为使用4个torch.nn.Embedding模块,分别对边框的四个顶点坐标进行编码;给定经过步骤1.6的正则化处理后的边框[x″
L=Concat(PosEmb2D(x″
其中Concat表示拼接操作。
进一步的,所述多模态编码器中的处理方法为:
C1:采用自注意力机制将文本向量编码和图像向量编码V拼接成一个序列X;
C2:将X加上二维位置编码L得到:
x=X+L。
进一步的,所述步骤C1中自注意力机制的注意力得分为:
其中:
d
本发明首次将预训练模型用于对非结构化文档图像的OCR文本进行纠错。相比于之前仅使用纯本文进行OCR文本纠错,该发明能够更好地利用文档的布局和视觉信息,更好地提升了纠错结果,在数据集SROIE上的纠错性能较纯文本的纠错方案提升了约20%。
附图说明
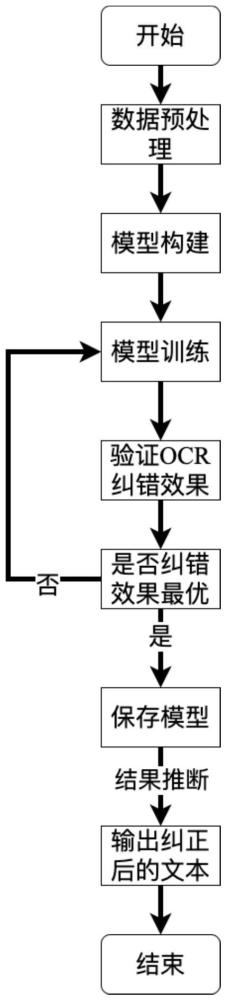
图1是本发明的OCR文本纠错方法的流程图;
图2是本发明的模型架构图;
图3是本发明的OCR文本对齐实施例示意图;
图4是本发明的文本分割实例(分割窗口大小为10)示意图;
图5是本发明的模型输入示意图;
图6是本发明的Beam Search实例示意图。
具体实施方式
本发明提出的一种OCR文本纠错方法是一种针对非结构化文档图像,基于预训练模型的OCR文本纠错技术。该技术的具体实施步骤如下:
S1.数据预处理
本发明使用的数据集为“扫描发票OCR和信息抽取”(Scanned receipts OCR andinformation extraction,简称SROIE),该数据集由发票的扫描图片,它总共包含1000张图片,以及每张收据图像对应的OCR原始文本和每一段文本对应的边框,以及通过人工校对后的正确文本(简称人工校对文本,Ground Truth)这四个部分组成。
S1.1数据集分割:将数据集按照7:2:1的比例分为训练集,验证集和测试集。其中测试集仅存在发票的扫描图片。
S1.2文本对齐
将OCR原始文本与人工校对文本进行对齐,使得OCR原始文本与人工校对文本之间的编辑距离(编辑距离是针对两个字符串的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串)最小,如图3所示。将OCR原始文本和人工校对文本(Ground Truth)通过距离算法对齐后得到OCR对齐文本和Ground Truth对齐文本,将这两部分文本合并形成文本对(OCR_aligned_text,GS_aligned_text)(OCR_aligned_text代表OCR对齐文本,GS_aligned_text代表Ground Truth对齐文本)。
算法步骤如下:
a.给定OCR原始文本序列A={a
首先给出定义:
LD(A,B)表示字符串A和字符串B的编辑距离,即将字符串A通过插入,删除和修改字符的方式转换为字符串B所用的最少操作次数。
LD(A,B)=0表示两个字符串的长度和内容完全一样。
LD(i,j)=LD(a
b.初始化矩阵H,使行i表示字符a
表1分数矩阵
注:_表示空字符\0
c.计算矩阵H中每一项的值LD(i,j):
如果字符串A的第i个字符与字符串B的第j个字符串相同,即a
若a
d.回溯,从矩阵右下角L(m,n)处开始:
若a
若a
e.初始化结果序列A’和B’为空序列(即A′={},B’={})
f.根据步骤d中产生的回溯路径,写出匹配字符串:
从最右下角单元格(LD(m,n))开始回溯,若回溯到第i行第j列单元格的左上角(第i-1行第j-1列)单元格,将a
若回溯到上边(第i-1行第j列)单元格,将a
若回溯到左边(第i行第j-1列)单元格,将占位符^添加到匹配序列A′,将b
S1.3由于一个文档图像包含较长的文本序列,可能超出预训练模型所允许的最大序列长度(超参数max_sequence_length,由人工进行设置,简称最大序列长度),且非结构化文档中同一个文档的文本段之间没有较强的语义关系。因此需要对一篇文档进行窗口分割,分割后的文本长度由超参数窗口尺寸(window size)进行控制,针对不同类型的文档window size的设置不同。同时对OCR对齐文本(OCR aligned text)和Ground truth对齐文本(Ground truth aligned text)进行窗口分割。图4给出了文本分割的一个具体实例,此处取窗口尺寸为10,第一个窗口取第1到第10个字符,第二个窗口取第2到第11个字符,以此类推,直到取到最后一位字符为止。
S1.4将OCR对齐文本和Ground truth对齐文本中的占位符^移除,再将二者合并后得到文本对(Modified_OCR_ext,Modified_Ground_truth_text),作为图2所述模型的输入,如图5所示(Modified_OCR_text代表OCR对齐文本去除占位符后的文本,Modified_Ground_truth_text代表Ground truth对齐文本去除占位符后的文本)。
S1.5分词
OCR原始文本在经过步骤1.2~1.4处理后,还无法直接作为预训练模型的输入。需要将文本转换为词向量。首先使用预训练模型中对由步骤1.4生成的Modified_OCR_text进行分词,将每一个字符转换成字典中的索引,从而得到分词序列W={w
S={[CLS],w
将Modified_Ground_truth_text经相同的操作后得到标签y。
1.6边框处理
1.6.1边框简化
在S1所描述的数据集中,每一个字符对应一个边框,通常一个边框由4个顶点坐标组成的多边形来表示,而为了简化输入,使文本限制在一个矩形中,只使用2个顶点坐标,因此需要对边框进行简化。简化过程如下:
假设原始边框坐标为:[x
简化后的边框坐标为:[x′
x′
x′
(其中,min(*)和max(*)分别表示取最小值和最大值的操作)
1.6.2边框正则化
此外,由于数据集中发票的扫描图片的像素大小不一,导致每个字符边框的坐标分布不均,因此需要对边框进行正则化。具体过程如下:
假设字符c的边框经过步骤1.6.1处理后的顶点坐标为[x′
,其中W表示图片的宽度,H表示图片高度。
经过正则化后边框坐标处于[0,1000)范围内。
1.7图像处理
使用python图像处理函数库cv2加载发票的扫描图片,加载后的图片以三维张量(I)的形式存在于内存当中,作为模型输入的一部分。
2.模型训练
2.1模型构建
2.1.1文本编码模块
文本编码模块包括文本向量编码器WordEmbedding,分段向量编码器SegEmb,一维位置向量编码器PosEmb1D三个部分。每个部分的工作原理如下:
1.由步骤1.5得到的文本序列S首先需要经文本向量编码器编码后得到WordEmbedding(S);
2.为文本序列S中的每个字符添加分段[A],从而得到分段向量s
3.为文本序列S中的每一个字符赋予一个位置索引i(0≤i 最后将三个部分相加得到文本向量编码T: T=WordEmbedding(S)+SegEmb(s 2.1.2图像编码模块 图像编码模块包括视觉编码器VisTokEmb,线性投影层Proj,一维位置编码器,分段向量编码器。每个部分的工作原理如下: 1.将步骤1.7中得到的三维张量I通过视觉编码器编码后得到特征图VisTokEmb(I),再将其(得到的特征图)平均池化为固定尺寸(W×H,W表示图像宽度,H表示图像高度),接着按行展开平均池化后的特征图,之后经过线性投影,就可以得到图像对应的特征向量序列Proj(VisTokEmb(I)); 2.和文本编码T的组成对应,特征向量序列也补充了一维位置向量和分段向量,特征向量序列的分段向量统一归为[C],即分段向量为s 3.为特征向量序列中每一个特征图赋予一个位置索引i(0≤i 最后将三个部分相加得到图像向量编码V: V=Proj(VisTokEmb(I))+PosEmb1D(P 2.1.3布局编码模块 布局编码模块用于对边框所表示的二维位置信息进行编码。 使用4个torch.nn.Embedding模块,分别对边框的四个顶点坐标进行编码。给定经过步骤1.6的正规化处理后的边框[x″ L=Concat(即PosEmb2D(x″ 其中Concat表示拼接操作。 2.1.4多模态编码器 为了融合文本,图像和布局三种输入模态,编码器首先将文本向量编码和图像向量编码V拼接成一个序列X,即 X=Concat(V,T) 然后将X加上二维位置编码L得到编码器的输入向量序列 x=X+L 编码器改进来传统的自注意力机制,引入了空间相对位置信息。传统自注意力机制通过如下方式计算注意力得分: 其中,d 可以看出,这种方式只能隐式地利用输入的绝对位置信息。于是为注意力得分显式地添加空间相对位置偏差项,添加之后的注意力得分表示为: 其中i,j,α 基于这种空间感知的自注意力权重α′ i表示查询向量x 2.1.5解码器 (文本纠错)模型使用全联接层将由步骤2.1.4生成的隐藏层状态向量h 2.2模型训练 训练过程使用Adam优化器训练模型,并且使用了pytorch分布式训练技术,使得模型可以在多张显卡上进行训练,极大地提高了训练的速度。模型训练具体过程如下: 2.2.1数据集加载 数据在经过步骤1的预处理之后,将生成格式为x 2.2.2编码 输入样本x 2.2.5解码 模型使用全联接层将由步骤2.2.4生成的隐藏层状态向量h 2.2.6计算损失值 使用交叉墒函数计算结果向量 其中t为标签y 2.2.7梯度下降 使用Adam优化文本纠错模型的训练学习率,进行梯度下降。 2.2.8结果推断 集束搜索是一种启发式图搜索算法,在结果向量 纠错性能对比如表2所示。本发明采用了滑动窗口的形式分割输入文本,使得模型能更好地理解语义性不强的非结构化商业文档。 表2本发明编码器和Transformer进行OCR文本纠错性能对比 注:OCR字符错误率根据单篇文档的错误字符除以总的字符数得到,平均字符错误率将所有文档的字符错误率取平均,提升比例由纠正前后平均字符错误率差值除以校正前平均字符错误率得到,加粗部分为校正效果最佳时的解码算法,窗口大小以及提升比例。 本发明首次将预训练模型本发明编码器用于对非结构化文档图像的OCR文本进行纠错。相比于之前仅使用纯本文进行OCR文本纠错,该发明能够更好地利用文档的布局和视觉信息,更好地提升了纠错结果,在数据集SROIE上的纠错性能较纯文本的纠错方案提升了约20%。 尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 一种纠错文本的确定方法以及相关设备
- 一种OCR文本纠错方法及装置
- 一种基于OCR识别结果的文本定位纠错方法系统