一种基于抽象语法树的开源软件缺陷数据分类方法及系统
文献发布时间:2023-06-19 09:27:35
技术领域
本发明涉及软件缺陷预测及软件可靠性技术领域,特别是涉及一种基于抽象语法树的开源软件缺陷数据分类方法及系统。
背景技术
在21世纪,软件已经成为不可或缺的生产工具,不仅在科研、工程、金融等专业领域发挥举足轻重的作用,更是在人们的生活中无处不在,影响着千家万户。随着软件在社会生活中的地位日益提升,软件规模与日俱增,软件复杂度几何式提升,这导致了软件缺陷的产生越来越频繁,对不同领域的负面影响越来越大,软件缺陷问题日益成为学界研究的热点。在软件开发的各个阶段中,如何识别与修复软件缺陷,已经成为提高软件质量工作中重要的一环。
软件缺陷预测能够通过提前发现与锁定软件中的缺陷模块,从而能够在开发资源有限的情况下保证软件质量,减少缺陷的产生和影响,已成为软件工程中一个非常重要的研究课题。软件缺陷检测技术分为静态与动态两种。软件缺陷预测技术能够帮助提高软件开发过程中资源分配的效率,对缺陷倾向性较高的模块进行及时的优化和修复,从而提高软件开发的效率和质量。
美国国家航空航天局(NASA)较早地启动了软件缺陷预测技术的研究,并开展了软件度量程序(MetricDataProgram,MDP)项目。该项目提供了开源的软件缺陷预测数据集,为软件缺陷预测领域提供了重要的数据支撑。我国的国家自然科学基金委员会在2007年年底启动“可信软件基础研究”重大研究计划,将软件缺陷预测作为重要科学目标。然而,目前的公开数据集内的缺陷数据较少,且项目特征重复性很高,软件缺陷预测对大数据的要求日益强烈。
大数据的需求表明,目前各软件项目内的缺陷数据已经不足以支持缺陷预测的数据需求,在软件开源的趋势下,目光应投向开源软件项目中的缺陷数据。GitHub作为通过Git进行版本控制的软件源代码托管服务,成为了全球最大的开源软件托管平台。根据GitHubUniverse开发者大会上发布的2019年度报告,目前GitHub拥有超过4000万开发人员,其中包括2019年的1000万新用户,合并了超过8700万个请求,其中包含了大量的软件缺陷信息及其修复数据,使获取大数据的缺陷预测数据集成为可能。
此外,缺陷分类技术能够将缺陷数据集中的信息粒度细分化,能够帮助提高缺陷数据集的质量。软件缺陷静态预测方法基于缺陷预测数据集中的度量信息,通常对目标软件模块的缺陷倾向性、缺陷密度等进行预测,即将软件程序模块预测为有缺陷倾向性(defectproneness,简称FP模块)或无缺陷倾向性(nondefectproneness,简称NFP模块)或输出预测模块的缺陷密度或缺陷数。而缺陷分类对缺陷信息的进一步分析,丰富了缺陷数据中的度量信息。基于缺陷分类的缺陷分析方法以客观的数据统计为基础,能为缺陷研究和预测结果从二分类到多分类奠定数据基础。缺陷分类对缺陷数据进行了属性定义,通过缺陷属性反映有关软件产品开发过程的更多信息。另外,传统软件缺陷分析运用统计分析等手段推断缺陷被引入的原因,存在人工操作过程复杂、人力成本和时间成本高、受主观意见影响分类过程、缺陷分类数据来源有限等问题。
发明内容
基于此,有必要提供一种基于抽象语法树的开源软件缺陷数据分类方法及系统,以解决人工操作过程复杂、人力成本和时间成本高、受主观意见影响分类过程、缺陷分类数据来源有限的问题。
为实现上述目的,本发明提供了如下方案:
一种基于抽象语法树的开源软件缺陷数据分类方法,包括:
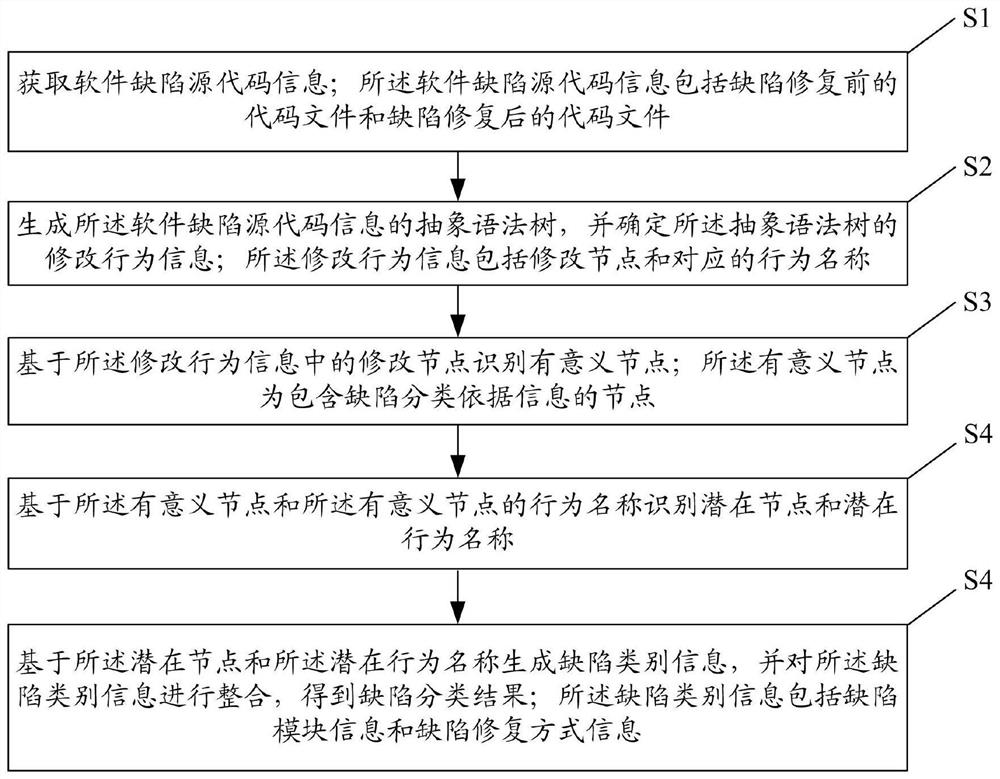
获取软件缺陷源代码信息;所述软件缺陷源代码信息包括缺陷修复前的代码文件和缺陷修复后的代码文件;
生成所述软件缺陷源代码信息的抽象语法树,并确定所述抽象语法树的修改行为信息;所述修改行为信息包括修改节点和对应的行为名称;所述行为名称包括增加、删除、修改和移动;
基于所述修改行为信息中的修改节点识别有意义节点;所述有意义节点为包含缺陷分类依据信息的节点;
基于所述有意义节点和所述有意义节点的行为名称识别潜在节点和潜在行为名称;所述潜在节点为所述有意义节点中代码修改属性正确的节点;所述潜在行为名称为与所述潜在节点对应的修改行为正确的行为名称;
基于所述潜在节点和所述潜在行为名称生成缺陷类别信息,并对所述缺陷类别信息进行整合,得到缺陷分类结果;所述缺陷类别信息包括缺陷模块信息和缺陷修复方式信息。
可选的,所述生成所述软件缺陷源代码信息的抽象语法树,并确定所述抽象语法树的修改行为信息,具体包括:
采用树差异对比器分别生成缺陷修复前的代码文件的抽象语法树和缺陷修复后的代码文件的抽象语法树;
采用比较器对所述缺陷修复前的代码文件的抽象语法树和所述缺陷修复后的代码文件的抽象语法树进行差分对比分析,生成抽象语法树的修改行为信息。
可选的,所述基于所述修改行为信息中的修改节点识别有意义节点,具体包括:
生成所有修改节点的父节点组;一个所述修改节点对应一组父节点组;
采用树结构自底向上遍历的方式确定各所述父节点组中节点属性为设定分类依据属性的节点;
将所述修改节点和各所述父节点组中节点属性为设定分类依据属性的节点确定为有意义节点。
可选的,所述设定分类依据属性包括数据的定义声明和初始化、数据的赋值、数学计算与逻辑计算、方法与接口调用、方法定义与声明、条件控制结构、循环控制结构、异常处理结构、同步异步结构以及不纳入。
可选的,所述基于所述有意义节点和所述有意义节点的行为名称识别潜在节点和潜在行为名称,具体包括:
依据潜在节点规则确定所述有意义节点中的潜在节点;
依据潜在行为名称规则对所述潜在节点的行为名称进行更改,得到潜在行为名称。
可选的,所述依据潜在节点规则确定所述有意义节点中的潜在节点,具体包括:
根据节点属性判断当前节点是否为第一设定节点,得到第一判断结果;所述第一设定节点为包含潜在节点的程度大于第一设定值的节点;所述当前节点为所述有意义节点中的一个节点;
创建当前节点的所有父节点,并根据节点属性判断当前节点的所有父节点中是否存在目标节点,得到第二判断结果;所述目标节点为成为潜在节点的程度大于第二设定阈值的节点;
自底向上遍历当前节点的所有父节点,判断在遍历到所述目标节点之前,所有被遍历到的父节点中是否不存在块节点,得到第三判断结果;
判断当前节点的所有父节点中的节点位置是否存在符合第一设定要求的节点,得到第四判断结果;
若所述第一判断结果、所述第二判断结果、所述第三判断结果和所述第四判断结果均为是,则将当前节点确定为潜在节点。
可选的,所述依据潜在行为名称规则对所述潜在节点的行为名称进行更改,得到潜在行为名称,具体包括:
根据节点属性判断所述修改节点中是否不包含所述潜在节点,得到第五判断结果;
根据节点属性判断目标潜在节点的所有父节点中是否存在符合第二设定要求的父节点,得到第六判断结果;
若所述第五判断结果和所述第六判断结果均为是,则将所述目标潜在节点的行为名称更改为修改,并将更改后的行为名称确定为潜在行为名称。
可选的,所述基于所述潜在节点和所述潜在行为名称生成缺陷类别信息,并对所述缺陷类别信息进行整合,得到缺陷分类结果,具体包括:
将所述潜在节点中潜在行为名称为移动的节点确定为移动节点;
对所述移动节点进行拆分或将所述移动节点的行为名称转化为增加、删除或修改,得到修改后的潜在行为名称;
依据节点变动属性与缺陷类别的映射关系生成缺陷模块信息;
依据行为名称与修复方式的映射关系生成缺陷修复方式信息;
对所述缺陷模块信息和所述缺陷修复方式信息进行整合,得到缺陷分类结果。
本发明还提供了一种基于抽象语法树的开源软件缺陷数据分类系统,包括:
数据获取模块,用于获取软件缺陷源代码信息;所述软件缺陷源代码信息包括缺陷修复前的代码文件和缺陷修复后的代码文件;
抽象语法树生成模块,用于生成所述软件缺陷源代码信息的抽象语法树,并确定所述抽象语法树的修改行为信息;所述修改行为信息包括修改节点和对应的行为名称;所述行为名称包括增加、删除、修改和移动;
有意义节点识别模块,用于基于所述修改行为信息中的修改节点识别有意义节点;所述有意义节点为包含缺陷分类依据信息的节点;
潜在节点识别模块,用于基于所述有意义节点和所述有意义节点的行为名称识别潜在节点和潜在行为名称;所述潜在节点为所述有意义节点中代码修改属性正确的节点;所述潜在行为名称为与所述潜在节点对应的修改行为正确的行为名称;
缺陷分类模块,用于基于所述潜在节点和所述潜在行为名称生成缺陷类别信息,并对所述缺陷类别信息进行整合,得到缺陷分类结果;所述缺陷类别信息包括缺陷模块信息和缺陷修复方式信息。
可选的,所述抽象语法树生成模块,具体包括:
抽象语法树生成单元,用于采用树差异对比器分别生成缺陷修复前的代码文件的抽象语法树和缺陷修复后的代码文件的抽象语法树;
差分对比单元,用于采用比较器对所述缺陷修复前的代码文件的抽象语法树和所述缺陷修复后的代码文件的抽象语法树进行差分对比分析,生成抽象语法树的修改行为信息。
与现有技术相比,本发明的有益效果是:
本发明提出了一种基于抽象语法树的开源软件缺陷数据分类方法及系统,利用抽象语法树对软件缺陷源代码语义信息进行分析,利用抽象语法树中节点的名称与结构关系形成分类依据信息,实现了对开源软件缺陷的自动分类,解决了大部分软件缺陷分类方法存在的人工操作过程复杂、人力成本和时间成本高、受主观意见影响分类过程、缺陷分类数据来源有限等问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的基于抽象语法树的开源软件缺陷数据分类方法的流程图;
图2为本发明实施例提供的基于抽象语法树的开源软件缺陷数据分类方法的基本原理图;
图3为本发明实施例提供的数据读取与语法树分析模块的工作过程示意图;
图4为本发明实施例提供的节点信息分析模块的工作过程示意图;
图5为本发明实施例提供的基于抽象语法树的开源软件缺陷数据分类系统的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
本实施例提供的基于抽象语法树的开源软件缺陷数据分类方法指的是静态缺陷预测方法,它可以从软件缺陷历史数据中挖掘缺陷的度量信息,设计形成软件缺陷预测数据集,对目标软件模块是否存在缺陷进行预测。该方法实现了将软件缺陷分类包含的更加丰富的缺陷信息与缺陷预测很好地结合。
本实施例提供的基于抽象语法树的开源软件缺陷数据分类方法具体的是一种面向GitHub等开源软件托管平台的基于抽象语法树的开源软件缺陷数据自动分类方法。GitHub网站作为开源托管平台,保存有大量的软件源代码数据。利用抽象语法树对软件缺陷源代码语义信息的分析,根据抽象语法树的节点变动情况对缺陷属性进行定义,得到缺陷分类依据,代入分类模型得到缺陷的分类结果,实现开源软件缺陷数据的自动分类。
图1为本发明实施例提供的基于抽象语法树的开源软件缺陷数据分类方法的流程图。参见图1,本实施例的基于抽象语法树的开源软件缺陷数据分类方法,包括:
步骤101:获取软件缺陷源代码信息;所述软件缺陷源代码信息包括缺陷修复前的代码文件和缺陷修复后的代码文件。
本实施例的软件缺陷源代码信息是指GitHub等开源软件版本托管平台上获取的有关软件缺陷修复的源代码信息。
步骤102:生成所述软件缺陷源代码信息的抽象语法树,并确定所述抽象语法树的修改行为信息;所述修改行为信息包括修改节点和对应的行为名称。
所述行为名称包括增加、删除、修改和移动。
所述步骤102,具体包括:
采用树差异对比器分别生成缺陷修复前的代码文件的抽象语法树和缺陷修复后的代码文件的抽象语法树;采用比较器对所述缺陷修复前的代码文件的抽象语法树和所述缺陷修复后的代码文件的抽象语法树进行差分对比分析,生成抽象语法树的修改行为信息。
步骤103:基于所述修改行为信息中的修改节点识别有意义节点;所述有意义节点为包含缺陷分类依据信息的节点。
所述步骤103,具体包括:
生成所有修改节点的父节点组;一个所述修改节点对应一组父节点组。采用树结构自底向上遍历的方式确定各所述父节点组中节点属性为设定分类依据属性的节点。将所述修改节点和各所述父节点组中节点属性为设定分类依据属性的节点确定为有意义节点。所述设定分类依据属性包括数据的定义声明和初始化、数据的赋值、数学计算与逻辑计算、方法与接口调用、方法定义与声明、条件控制结构、循环控制结构、异常处理结构、同步异步结构以及不纳入。
步骤104:基于所述有意义节点和所述有意义节点的行为名称识别潜在节点和潜在行为名称。
所述潜在节点为所述有意义节点中代码修改属性正确的节点;所述潜在行为名称为与所述潜在节点对应的修改行为正确的行为名称。
所述步骤104,具体包括:
依据潜在节点规则确定所述有意义节点中的潜在节点;依据潜在行为名称规则对所述潜在节点的行为名称进行更改,得到潜在行为名称。具体的:
1)所述依据潜在节点规则确定所述有意义节点中的潜在节点,具体包括:
根据节点属性判断当前节点是否为第一设定节点,得到第一判断结果;所述第一设定节点为包含潜在节点的程度大于第一设定值的节点(可能包含潜在节点);所述当前节点为所述有意义节点中的一个节点。所述第一设定节点具体包括VariableDeclarationStatement、VariableDeclarationExpression、Assignment、InfixExpression、PrefixExpression、MethodInvocation、SuperMethodInvocation、ClassInstanceCreation、This-Expression。
创建当前节点的所有父节点,并根据节点属性判断当前节点的所有父节点中是否存在目标节点,得到第二判断结果;所述目标节点为成为潜在节点的程度大于第二设定阈值的节点(可能成为潜在节点)。所述目标节点具体包括IfStatement、SwitchStatement、SwitchCase、ConditionalExpression、WhileStatement、DoStatement、ForStatement、EnhancedForStatement、TryStatement、ThrowStatement。
自底向上遍历当前节点的所有父节点,判断在遍历到所述目标节点之前,所有被遍历到的父节点中是否不存在块节点,得到第三判断结果。
判断当前节点的所有父节点中的节点位置是否存在符合第一设定要求的节点,得到第四判断结果。若目标节点为IfStatement、SwitchStatement、SwitchCase、ForStatement、EnhancedForStatement、WhileStatement、TryStatement、ThrowStatement,则所述第一设定要求为:是与目标节点位置相距最近的子节点;若目标节点为Conditional-Expression,则所述第一设定要求为:是与目标节点位置相距最近且相对距离不为0的子节点;若目标节点为DoStatement,则所述第一设定要求为:与目标节点位置相距为DoBlock节点长度与DoStatement节点长度之和。
若所述第一判断结果、所述第二判断结果、所述第三判断结果和所述第四判断结果均为是,则将当前节点确定为潜在节点。
2)所述依据潜在行为名称规则对所述潜在节点的行为名称进行更改,得到潜在行为名称,具体包括:
根据节点属性判断所述修改节点中是否不包含所述潜在节点,得到第五判断结果。
根据节点属性判断目标潜在节点的所有父节点中是否存在符合第二设定要求的父节点,得到第六判断结果。第二设定要求为父节点为潜在节点。
若所述第五判断结果和所述第六判断结果均为是,则将所述目标潜在节点的行为名称更改为修改,并将更改后的行为名称确定为潜在行为名称。
步骤105:基于所述潜在节点和所述潜在行为名称生成缺陷类别信息,并对所述缺陷类别信息进行整合,得到缺陷分类结果;所述缺陷类别信息包括缺陷模块信息和缺陷修复方式信息。
所述步骤105,具体包括:
将所述潜在节点中潜在行为名称为移动的节点确定为移动节点。对所述移动节点进行拆分或将所述移动节点的行为名称转化为增加、删除或修改,得到修改后的潜在行为名称。依据节点变动属性与缺陷类别的映射关系生成缺陷模块信息。依据行为名称与修复方式的映射关系生成缺陷修复方式信息。对所述缺陷模块信息和所述缺陷修复方式信息进行整合,得到缺陷分类结果。
在实际应用中,结合基于抽象语法树的开源软件缺陷数据分类原理对上述方法进行详细说明。
参见图2,图2中的标号①部分表示数据读取与语法树分析模块,标号②部分表示节点信息分析模块,标号③部分表示分类信息生成模块。其中,所述数据读取与语法树分析模块的主要功能为对在GitHub网站上获取的软件缺陷的源代码信息进行读取与分析,生成缺陷源代码对应的抽象语法树并进行树差分对比处理,得到以抽象语法树节点为单位的进一步缺陷信息。所述节点信息分析模块的主要功能为将节点信息进行分析与处理,利用树节点的名称与结构关系定义缺陷属性,形成分类依据信息。所述分类信息生成模块的主要功能为根据分类模型和配置,将分类依据信息对应缺陷的分类结果,并将缺陷类别集合进行整理合并。
所述基于抽象语法树的开源软件缺陷数据分类方法的工作过程包括:
步骤1:数据读取与语法树分析。数据是指GitHub等开源软件版本托管平台上获取的有关软件缺陷修复的源代码信息。语法树是指抽象语法树,是基于抽象语法结构将源代码转化为节点树形结构的一种表达方式,它从语义信息的角度描述了程序代码中的静态文本信息和逻辑结构。
步骤1-1:数据读取。将软件中缺陷修复的源代码信息作为系统的输入,参见图3,输入为软件项目中某一个缺陷修复前的代码文件(a.java)与修复后的代码文件(b.java),利用基于EclipseJDT的开源的语法树分析工具GumTreeDiff(树差异对比器)对两个代码文件的源代码信息进行读取,分别生成对应的抽象语法树,对源代码的语义信息进行转化和存储。
抽象语法树为树形结构,根节点表示编译单元,叶节点为代码的基本元素,例如变量、符号、关键字等。根节点与叶节点间的中间节点以树状关系层层关联,本实施例中需要处理的抽象语法树节点共36个。
步骤1-2:语法树分析。用比较器对生成的两颗抽象语法树的节点结构进行对比分析,提取代码的更改信息。参见图3,对比结果为两个抽象语法树之间的节点结构差异,表现为两个树节点的映射关系,即更改前节点与更改后节点的对应关系。
依据抽象语法树差异能够生成以抽象语法树节点为单位的进一步缺陷信息,即抽象语法树的修改行为信息,其包括两方面的内容:修改节点和行为名称。修改节点指的是将语法树的修改行为定位缩小为树节点的更改后,对应的节点信息;行为名称包括增加、删除、修改和移动。
步骤2:节点信息分析。节点信息包括节点名称、节点的父节点与子节点结构关系。
步骤2-1:将直接修改节点识别为有意义节点。直接修改节点指的是步骤1产生的抽象语法树的修改行为信息中的修改节点。有意义节点指的是包含缺陷分类依据信息的节点,即本实施例认为,有意义节点的变动意味着代码变动具有作为分类依据的属性。本实施例对有意义节点的规定如下:
①FieldDeclaration、VariableDeclarationStatement、VariableDeclaration-Expression节点的变动代表代码修改与数据的定义声明和初始化相关;
②Assignment节点的变动代表代码修改与数据的赋值相关;
③InfixExpression、PrefixExpression、PostfixExpression节点的变动代表代码修改与数学计算与逻辑计算相关;
④IfStatement、SwitchStatement、SwitchCase、ConditionalExpression节点的变动代表代码修改与条件控制结构相关;
⑤WhileStatement、DoStatement、ForStatement、EnhancedForStatement、BreakStatement、ContinueStatement节点的变动代表代码修改与循环控制结构相关;
⑥TryStatement、ThrowStatement节点的变动代表代码修改与异常处理结构相关;
⑦SynchronizedStatement节点的变动代表代码修改与同步异步结构相关;
⑧MethodInvocation、SuperMethodInvocation、ClassInstanceCreation、ThisExpression、ConstructorInvocation节点的变动代表方法代码修改与接口调用相关;
⑨SuperConstructorInvocation、MethodDeclaration、ReturnStatement节点的变动代表代码修改与方法定义与声明相关;
⑩PackageDeclaration、ImportDeclaration、Block、AnnotationType-Declaration、MarkerAnnotation节点的变动代表的意义不纳入考虑。属性与节点名称的对应关系如表1所示。
表1
参见图4,生成所有直接修改节点的父节点组,遍历每个直接修改节点的父节点组,即通过树结构自底向上遍历的方式找到变动节点父节点中的有意义节点,即表1中所列节点,当当前节点为上述所列的有意义节点之一时停止遍历。
步骤2-2:识别潜在节点信息。潜在节点指包含节点修改行为准确意义的节点,通常存在于有意义节点的父节点中,也是一个有意义节点。
步骤2-1中所得有意义节点所包含的代码修改属性,不一定是准确的。参见图4,识别潜在节点过程基于规则,进行节点意义是否准确的判断的工作过程主要概括为:将意义可能不准确的节点还原为其意义准确的节点(意义可能被忽视的节点),即将可能包含潜在节点的节点还原为可能成为潜在节点的节点。在目前的系统中主要指将某些可能属于控制逻辑结构中控制条件部分的,但有不包含控制逻辑属性的节点还原为控制逻辑相关的相应节点。
可能包含潜在节点的节点包括:VariableDeclarationStatement、VariableDeclarationExpression、Assignment、InfixExpression、PrefixExpression、MethodInvocation、SuperMethodInvocation、ClassInstanceCreation、This-Expression,可能成为潜在节点的节点包括:IfStatement、SwitchStatement、SwitchCase、ConditionalExpression、WhileStatement、DoStatement、ForStatement、EnhancedForStatement、TryStatement、ThrowStatement。具体如表2所示。
表2
进行潜在节点识别的工作过程与规则主要为:
(1)根据节点属性判断当前节点是否为表2中的可能包含潜在节点的节点;
(2)创建其父节点列表,根据节点属性判断当前节点的所有父节点中是否存在表2中的可能成为潜在节点的节点(目标节点);
(3)自底向上遍历当前节点的所有父节点,判断在遍历到所述目标节点之前,所有被遍历到的父节点中是否不存在块节点,得到第三判断结果;
(4)根据存在的目标节点判断,父节点列表中是否有节点的位置是否符合相应的要求,要求如下:
若目标节点为IfStatement、SwitchStatement、SwitchCase、ForStatement、EnhancedForStatement、WhileStatement、TryStatement、ThrowStatement,则要求为:是与目标节点位置相距最近的子节点;若目标节点为Conditional-Expression,则要求为:是与目标节点位置相距最近且相对距离不为0的子节点;若目标节点为DoStatement,则要求为:与目标节点位置相距为DoBlock节点长度与DoStatement节点长度之和。具体如表3所示。
表3
(5)若以上判断皆为是,则存在潜在节点,当前节点应更换为潜在节点。
步骤2-3:潜在行为名称识别。潜在行为名称指对应修改行为意义准确的行为名称,也是增加、删除、修改和移动4种之一。
步骤2-2中所得潜在节点对应的原节点的行为名称,不一定是准确的。参见图4,潜在行为名称的识别基于规则,在目前的系统中主要指对以下情况的判断:原意义不准确节点的增加和删除,实际是对目标潜在节点的修改,由此对潜在行为名称进行识别的工作过程与规则主要为:
(1)根据是否在步骤2-1中判断存在潜在节点,并发生当前节点的更换,对当前节点是否因意义不准确而发生变动进行判断;
(2)根据节点属性判断此次代码修改发生变动的所有直接修改节点中是否不包含潜在节点;
(3)根据节点属性判断当前节点的所有父节点中是否存在节点符合如下要求:直接父节点即为潜在节点;
(4)若以上判断皆为是,则与节点组合的行为名称不准确,应改为“修改”。
步骤3:分类信息生成。分类信息是指本实施例对应的分类方法的分类结果。本实施例的分类方法以两个不同的维度对缺陷进行分类:缺陷产生的模块和缺陷修复的方式,本实施例的分类方法将缺陷分为数据缺陷、计算缺陷、控制逻辑缺陷、时序缺陷和接口缺陷,其对应代码的缺少、冗余和错误。具体如表4所示。
表4
步骤3-1:移动节点拆分与转化:行为名称为移动的节点较为特殊,包含两个节点信息,移动源节点与移动目的地节点,默认节点信息为移动源节点。通过以下规则拆分或转化为增加、删除和修改节点:
(1)若移动目的节点为IfStatement、SwitchStatement、WhileStatement、DoStatement、EnhancedForStatement、ForStatement、ConditionalExpression、TryStatement、ThrowStatement、SynchronizedStatement、ReturnStatement中其中一个,则节点信息改为移动目的地节点,行为名称改为增加。
(2)若所有节点信息皆为移动类型节点,则将行为名称全部改为修改。
步骤3-2:生成缺陷类别信息。经过以上步骤得到的分类依据信息为:节点信息与行为名称,且节点信息皆为有意义节点。缺陷类别的生成从两个维度进行。
第一部分:有意义节点代表着代码变动属性,能够与缺陷类别的第一个维度(缺陷模块信息)进行对应,关系如下:
数据的定义与声明和初始化、数据的赋值对应数据类型缺陷,数学计算逻辑计算对应计算类型缺陷,条件控制结构、循环控制结构、异常处理结构、图同步异步结构对应控制逻辑类型缺陷,同步异步结构对应时序类型缺陷,方法与接口调用,方法定义与声明对应接口类型缺陷,不纳入考虑的代码变动属性忽略不计。具体如表5所示。
表5
第二部分,行为名称与缺陷类别的第二个维度(缺陷修复方式信息)进行对应,对应关系为:增加、删除和修改分别对应缺少、冗余和错误。
步骤3-3:整合缺陷类别信息。经过以上步骤得到的缺陷类别信息包括缺陷模块信息和缺陷修复方式信息两个维度,两两一组,存在多组,一般一个缺陷的修复过程通常涉及多个改动。因此,将所有缺陷类别信息整合,相同缺陷模块的类别信息合并,合并时对应的缺陷修复方式信息以“错误”为最高优先级留存,若同时存在“缺少”和“冗余”,则视为存在“错误”。经过缺陷类别信息的合并可以得到最终的缺陷分类结果,例如:控制逻辑缺陷(缺少)。本实施例的分类结果为多标签分类,即一个缺陷可能归属不同的多个类别。
本实施例的基于抽象语法树的开源软件缺陷数据分类方法,利用抽象语法树对GitHub网站上软件缺陷源代码语义信息的分析,利用抽象语法树中节点的名称与结构关系形成分类依据信息,实现对开源软件缺陷的自动分类,解决了大部分软件缺陷分类方法存在的人工操作过程复杂、人力成本和时间成本高、受主观意见影响分类过程、缺陷分类数据来源有限等问题。
本实施例的基于抽象语法树的开源软件缺陷数据分类方法,与现有技术相比,具有以下优势:
1)本实施例的分类方式的数据来源为修复缺陷的代码源文件,在GitHub等开源软件托管平台能获取大量数据来源,因此可利用此系统进行缺陷分类的软件数量十分庞大,足以帮助建立满足深度学习需求的多分类的缺陷数据集。
2)本实施例的分类方法以具体的代码修改内容为依据,分类结果的后续分析统计对软件项目的缺陷修复的具体工作有一定指导意义。
3)本实施例的实现流程具有一定标准化,在根据本实施例内容建立所述软件缺陷自动系统后,系统可以脱离人力监督进行缺陷数据分类和统计,提高了软件领域缺陷分类的自动化程度,避免人工操作过程复杂、人力成本和时间成本高、受主观意见影响分类过程等问题。
4)本实施例所提出的缺陷自动分类方法的具有一定的准确率,按照分类模型和分类详细说明进行人工分类的分类结果,与本实施例的自动分类结果相比,能达到约90%的一致。
本发明还提供了一种基于抽象语法树的开源软件缺陷数据分类系统,图5为本发明实施例提供的基于抽象语法树的开源软件缺陷数据分类系统的结构示意图。
参见图5,本实施例的基于抽象语法树的开源软件缺陷数据分类系统包括:
数据获取模块201,用于获取软件缺陷源代码信息;所述软件缺陷源代码信息包括缺陷修复前的代码文件和缺陷修复后的代码文件。
抽象语法树生成模块202,用于生成所述软件缺陷源代码信息的抽象语法树,并确定所述抽象语法树的修改行为信息;所述修改行为信息包括修改节点和对应的行为名称;所述行为名称包括增加、删除、修改和移动。
有意义节点识别模块203,用于基于所述修改行为信息中的修改节点识别有意义节点;所述有意义节点为包含缺陷分类依据信息的节点。
潜在节点识别模块204,用于基于所述有意义节点和所述有意义节点的行为名称识别潜在节点和潜在行为名称;所述潜在节点为所述有意义节点中代码修改属性正确的节点;所述潜在行为名称为与所述潜在节点对应的修改行为正确的行为名称。
缺陷分类模块205,用于基于所述潜在节点和所述潜在行为名称生成缺陷类别信息,并对所述缺陷类别信息进行整合,得到缺陷分类结果;所述缺陷类别信息包括缺陷模块信息和缺陷修复方式信息。
作为一种可选的实施方式,所述抽象语法树生成模块202,具体包括:
抽象语法树生成单元,用于采用树差异对比器分别生成缺陷修复前的代码文件的抽象语法树和缺陷修复后的代码文件的抽象语法树;
差分对比单元,用于采用比较器对所述缺陷修复前的代码文件的抽象语法树和所述缺陷修复后的代码文件的抽象语法树进行差分对比分析,生成抽象语法树的修改行为信息。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种基于抽象语法树的开源软件缺陷数据分类方法及系统
- 一种基于抽象语法树的开源软件缺陷数据分类方法及系统