一种基于遗传算法的抗体计算优化方法
文献发布时间:2023-06-19 09:54:18
技术领域
本发明涉及生物信息学技术领域,具体涉及蛋白质分子结构设计,尤其是涉及一种基于遗传算法的抗体计算优化方法。
背景技术
近几年,随着抗体及其靶标的生物信息学、结构生物学数据的不断增加,以及计算工具的迭代发展,针对特定抗原或抗原表位进行计算抗体设计优化的技术得到快速发展。利用计算抗体设计方式可以靶向设计具有表位特异性和亲和性的抗体。计算抗体设计的优势在于,基于人工智能的算法模型可以构建大规模的计算抗体突变库,通过基于知识的机器学习模型对抗体的溶解度、表面疏水性、局部表面电荷、聚集倾向性等抗体关键特性进行评估,从而快速筛选具有开发潜力的先导抗体并进行优化,可以极大的减少临床前药物研发成本和周期。
抗体由重链和轻链组成,重链和轻链与抗原结合的区域称为互补结合区(CDR)。其中CDR H3在与抗原结合中起到重要作用,因此成为抗体优化设计的热点区域。
抗体计算优化设计涉及多个环节,包括但不限于序列注释、序列设计、抗体建模、H3环建模、分子对接、可开发性预测等,实现上述功能通常需要多个不同工具完成,这些工具由不同的研究人员开发,存在算法性能参差不齐、编写语言不一、代码编写复杂,极大限制了研究人员利用这些工具进行抗体设计的能力。
因此,现有的抗体计算优化设计方法需要学习并操作多种不同算法、工具、软件;并且需要依赖专家经验,对抗体的个别位点实施特异性突变,以预测抗体结合性能是否得到提高;其生成的抗体序列受现有抗体序列制约比较明显,无法探索更多可能的抗体更优解。
发明内容
鉴于此,本发明的目的是提供一种基于遗传算法的抗体计算优化方法,针对目前抗体计算设计相关工具分散的缺陷,对现有工具进行改写、优化和封装,构建具备全流程自动化的抗体设计系统,涵盖了肽链处理、表位识别、序列注释、序列设计、抗体同源建模、CDRH3环从头建模、抗原抗体分子对接、抗体生物物理性质预测等功能。
为了达到上述目的,本发明提供如下技术方案:
一种基于遗传算法的抗体计算优化方法,包括:
肽链处理:用户上传抗体-抗原复合物结构文件或抗体、抗原的结构文件,以及抗体序列,并指定抗体、抗原对应的链编号,并在有条件的基础上提供关键抗原表位列表;
表位识别:系统识别抗体-抗原复合物结构文件中的抗体-抗原的接触位点;
序列注释:系统通过抗体编号系统对抗体重链进行编码,并根据注释结果识别抗体CDR H3序列;
序列设计:通过遗传算法对原始抗体的CDR H3序列进行迭代优化设计,输出优化抗体CDR H3序列集合;将优化抗体CDR H3序列接回原始抗体重链序列相应位置,获得优化后的抗体重链,将优化后抗体重链与原始抗体轻链合并,获得优化后的抗体序列;
抗体建模:对优化后的抗体序列进行同源建模,模板采用原始抗体,最后对CDR H3区的结构进行从头建模加以改进,获得优化抗体PDB结构文件;
分子对接:通过各向异性网络模型对优化后的抗体和抗原结构进行柔性对接,采用DFIRE函数进行评分,并将该评分值作为预测的结合自由能ΔG;
抗体性质评估:对输出的优化抗体,通过综合评分结果对优化抗体进行排序,输出优化抗体序列库;并对输出的优化抗体进行生物物理性质预测。
进一步地,在所述数据处理过程中:用户上传抗体-抗原复合物结构文件,系统将根据用户指定的抗体和抗原链编号,从复合物结构文件中提取出对应的链,形成单独的抗体和抗原结构文件;若用户上传单独抗原、抗体结构文件,系统将根据CDR H3和/或关键抗原表位进行分子对接,获取抗体-抗原复合物结构文件;
进一步地,系统识别该抗体和抗原复合物结构文件中的抗体-抗原的接触位点,定义与CDR H3区域位点距离小于等于5埃范围内的抗原位点为初始抗原表位;如果用户提交了关键抗原表位,则将其优先定义为初始抗原表位。
进一步地,在所述序列注释过程中,采用Chothia(H95-H102)、kabat(H95-102)、Contact(H93-H101)、IMGT(H93-H102)其中任一种编号方案对抗体重链进行编码,括号内为该编号方案下CDR H3对应的序列编码范围。
进一步地,所述序列设计过程中,在遗传算法起始时,设置N个起始CDR H3种子序列,在每轮迭代中,根据设置的重组率和变异率,对CDR H3序列进行变异,完成迭代。
进一步地,所述序列设计过程中,在迭代过程中,根据序列综合评分S,决定该序列是否进入下一轮,以及该序列在下一轮所占比例。
进一步地,在迭代过程中,可根据设置的迭代次数完成迭代,或当生成的优化抗体数量达到预设阈值时结束迭代。
进一步地,所述抗体建模过程中,可采用Modeller、SWISS-MODEL、I-TASSER、Rosetta、AbodyBuilder中任一种软件进行同源建模。
进一步地,在抗体分子对接过程中,采用CDR H3和初始抗原表位或关键抗原表位作为对接约束条件,以确保优化后的抗体-抗原结合位点限制在初始抗原表位附近。
进一步地,在抗体分子对接完成后,识别抗原与优化抗体CDR H3的接触位点,定义为优化抗原表位。
进一步地,系统通过预测结合自由能和表位覆盖度对序列进行综合评分:将优化后的抗原表位定义为集合A,初始抗原表位定位为集合B,定义表位覆盖度C;
序列综合评分:S=C×ΔG式(2)。
进一步地,所述抗体性质评估过程中,抗体的生物物理性质指标包括AC-SINS(亲和捕获自相互作用纳米粒子光谱)、CSIBLI(基于生物层干涉法的克隆自相互作用)、PSR(多特异性试剂结合)、BVP-ELISA(杆状病毒颗粒ELISA)、CIC(交叉作用色谱)、ELISA(酶联免疫吸附)、HEK(HEK细胞表达效价)、HIC(疏水作用色谱)、SGAC-SINS(盐梯度亲和捕获自相互作用纳米粒子光谱)、SMAC(立式单层吸附色谱)、SEC(尺寸排阻色谱)、DSF(差示扫描荧光定量)。
本发明的一种基于遗传算法的抗体计算优化方法,其有益效果在于:
(1)本方案整合了抗体计算优化流程的基本要素,可以在同一平台实现流程的自动化。
(2)本方案通过遗传算法进行CDR H3序列设计,可以减少在序列位点突变中对专家经验的依赖。
(3)本方案根据已知抗原的抗体序列,针对整个CDR H3序列进行序列设计,利用遗传算法,迭代生成和评价随机位点、随机残基组合而成的变异抗体序列,扩展了抗体序列的可能形式,并与原始抗体进行综合评分比较,从而获取优化抗体或剔除低质抗体,产生新颖的抗体CDR H3序列和结构,最终生成候选抗体序列库。
(4)本方案通过对候选抗体进行生物物理性质预测,为候选抗体的筛选提供指导。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
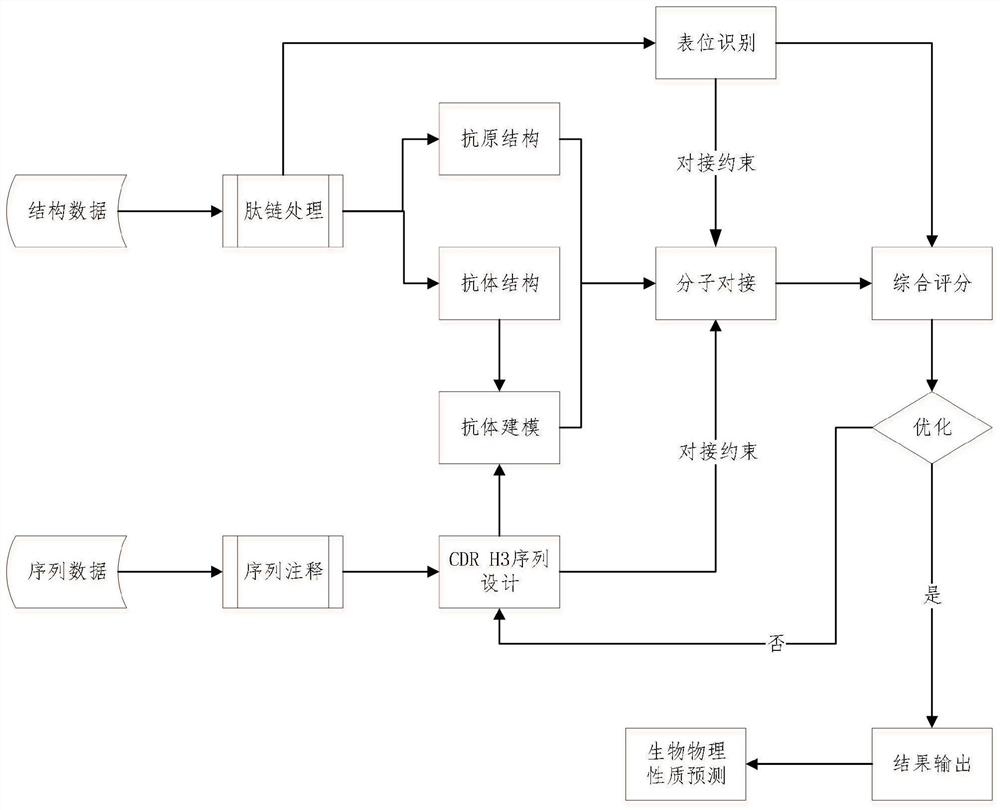
图1是本发明的抗体计算优化方法示意图。
具体实施方式
下面将结合本发明的附图,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明提出一种基于遗传算法的抗体优化方法和系统。该系统基于已知抗体序列数据,针对其重链高可变H3区段(CDR H3),利用遗传算法,迭代生成和评价随机位点、随机残基组合而成的变异抗体序列,并与原始抗体进行综合评分比较,从而获取优化抗体或剔除低质抗体,最终生成候选抗体序列库。
该系统整合了抗体计算设计的完整环节,对部分已有算法工具进行了优化和封装。涵盖了肽链处理、表位识别、序列注释、CDR H3序列设计、抗体同源建模、CDR H3环建模、分子对接、抗体性质评估等算法,具备全流程自动化的抗体设计功能。
该抗体优化方法具体如下:
肽链处理:用户可以单独上传抗体、抗原的结构文件和抗体重链、轻链序列,并指定对应的链编号,并且可以选择是否添加关键抗原表位。用户如果提交抗体-抗原复合物结构文件(.pdb格式),系统将根据用户指定的抗体和抗原链编号,从复合物结构文件中提取出对应的链,形成单独的抗体和抗原结构文件。用户如果提交单独的抗体、抗原结构文件,系统将根据序列注释的CDR H3和/或关键抗原表位进行分子对接,获取抗体-抗原复合物结构文件。
表位识别:对于用户输入的或系统根据抗原、抗体文件构建的抗体-抗原复合物,系统通过prodigy工具识别复合物结构文件中抗体-抗原的接触位点,并进一步定义与原始抗体CDR H3区域位点结合的抗原位点为初始抗原表位,与优化后抗体CDR H3区域位点结合的抗原位点为优化抗原表位。当用户提交了关键抗原表位时,优先将关键抗原表位作为初始抗原表位,不再另外进行初始抗原表位识别。
序列注释:CDR H3区是影响抗体结合效力的关键位点,本方法的策略是通过对抗体CDR H3序列进行优化,提高该区域的结合力。因此首先需要识别抗体的CDR H3序列。系统通过Kabat编号方案对抗体重链进行编码,并根据注释结果识别抗体CDR H3序列,在该编号体系下CDR H3序列范围在H95-H102。
在序列注释过程可采用Chothia(H95-H102)、Kabat(H95-102)、Contact(H93-H101)、IMGT(H93-H102)其中任一种编号方案对抗体重链进行编码,Kabat是最早提出并广泛应用的一种编号方案,因此本发明优先选择Kabat进行抗体编号。
序列设计:通过遗传算法对原始抗体的CDR H3序列进行迭代优化设计,输出优化抗体结构和序列。
在遗传算法起始时,设置N个起始种子(默认值为10),即原始CDR H3序列。在接下来的每一轮迭代中,根据设置的重组率和变异率,对CDR H3序列进行变异。默认的重组率为0.5,变异率为0.2,迭代次数50。在每一轮中,根据序列综合评分,决定该序列是否进入下一轮,以及其在下一轮所占比例。根据设置的迭代次数,完成迭代,或当生成的优化抗体数量达到预设阈值时(M,默认值为10)结束迭代,并输出对应的优化抗体结构和序列。
抗体建模:将遗传算法优化过程中,将生成的CDR H3序列接回原始抗体重链序列相应位置,获得优化后抗体重链。将原始抗体轻链与优化后抗体重链合并,获得优化后的抗体序列。然后通过Modeller中的automodel对优化后的抗体序列进行同源建模,模板采用原始抗体结构文件。然后通过Modeller中提供的loop优化对CDR H3区的结构进行从头建模,获得优化抗体PDB结构文件。
所述抗体建模过程中,可采用Modeller、SWISS-MODEL、I-TASSER、Rosetta、AbodyBuilder中任一种软件进行同源建模,本发明优选采用Modeller同源建模。
分子对接:在lightdock中通过各向异性网络模型(ANN)对优化后的抗体和原始抗原结构进行柔性对接,采用DFIRE函数进行评分,并将该值作为预测的结合自由能ΔG。在对接过程中,将CDR H3和初始抗原表位(或关键抗原表位)作为对接约束条件。通过prodigy识别优化后的抗体与抗原对接位点,并获取优化后的抗原表位。
综合评分:将优化后的抗原表位定义为集合A,初始抗原表位定义为集合B,我们定义了表位覆盖度(C):
综合评分:S=C×ΔG (公式2)
通过设置表位覆盖度这一指标,我们将优化后的抗体-抗原结合位点限制在初始抗原表位附近,以确保我们的计算设计抗体满足最初的目的,即通过序列的优化提升其亲和力。通过综合评分我们对优化抗体序列进行排序。
抗体生物物理性质预测:对输出的≥M个优化抗体,利用Abpred分别预测抗体的12项生物物理指标。包括AC-SINS(亲和捕获自相互作用纳米粒子光谱)、CSIBLI(基于生物层干涉法的克隆自相互作用)、PSR(多特异性试剂结合)、BVP-ELISA(杆状病毒颗粒ELISA)、CIC(交叉作用色谱)、ELISA(酶联免疫吸附)、HEK(HEK细胞表达效价)、HIC(疏水作用色谱)、SGAC-SINS(盐梯度亲和捕获自相互作用纳米粒子光谱)、SMAC(立式单层吸附色谱)、SEC(尺寸排阻色谱)、DSF(差示扫描荧光定量),并分别按照各项评估的结果对优化抗体进行排名。
在本发明提出一种通过遗传算法模型进行抗体计算优化的方案。该方案根据已知抗原的抗体序列,针对其CDR H3区段,利用遗传算法,迭代生成和评价随机位点、随机残基组合而成的变异抗体序列,并与原始抗体进行综合评分比较,从而获取优化抗体或剔除低质抗体,最终生成候选抗体序列库,并对候选抗体进行生物物理性质预测。该方法的技术关键点重点表现在以下三个方面:
1、抗体优化设计流程:面向抗体设计优化问题,集成优化蛋白质序列分析、空间建模、分子对接和属性预测等成熟权威算法工具,构建松耦合、自动化的计算模拟仿真流程。
2、抗体CDR H3变异文库构建算法:针对抗体CDR H3局部搜索空间海量潜在可能,采用启发式遗传算法,以抗体关键性能指标作为评价标准,在可接受的时间和成本下,构建符合预期的变异文库。
3、抗体性能评价策略:考虑计算模拟仿真过程产生的误差和噪声,在常用亲和力评价指的基础上,引入抗原表位覆盖度指标作为限制条件,指导并加速局部搜索过程。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 一种基于遗传算法的抗体计算优化方法
- 基于遗传算法的无人机辅助边缘计算的能耗优化方法