基于文档嵌入模型的大规模平行坐标数据简化方法
文献发布时间:2023-06-19 10:16:30
技术领域
本发明涉及一种基于文档嵌入模型的文档表达方法以及大规模平行坐标的简化方法,属于信息技术领域。
背景技术
平行坐标是利用线段的几何布局呈现多维属性数据,其独特的几何分布特性和优越的视觉表达性能使其广泛应用于多维数据的探索和分析。然而,随着多维数据规模的增大,平行坐标系中大量数据线交叉、重叠和覆盖,严重干扰用户对于原始多维数据的认知。
过滤、绑定和采样是解决大规模平行坐标视觉混淆的主要方法。过滤可灵活选择坐标轴的属性范围,进而降低平行坐标系中多维数据呈现的冗余程度,可以帮助用户聚焦感兴趣特征的数据。但在具体的过滤过程洪,需要用户对于原始坐标轴的含义具有先验知识,而且过滤后得到的结果更加侧重于局部数据,难以呈现原始多维数据的宏观分布,存在局限性;绑定是另外一种降低平行坐标系中大规模数据视觉混淆的有效方法,主要通过绑定具有相似特征的数据线条,降低视觉紊乱的同时增强关联特征视觉感知。在具体的线条绑定过程中,存在数据理解歧义,为平行坐标系中多维数据的理解和探索带来不确定性;;采样是降低数据规模的有效手段。针对平行坐标系中大规模数据进行采样,能够在降低视觉紊乱的基础上,很好地保留原始多维数据的宏观分布特征。以随机采样算法(RandomSampling)为例,它不仅能够保持原始数据的空间分布,而且能够增强原始数据的几何特征表示。
尽管上述方法能够从不同角度降低大规模平行坐标系中的视觉混乱问题,但在具体的简化过程中,单个或相邻坐标轴之间的数据分布被考虑地比较细致,而多维数据穿越坐标轴之间形成的上下文特征没有被综合考虑。实际上,多维数据穿越平行坐标系中的坐标中,其连续分布特征具有重要的意义。而传统的采样算法很难保持平行坐标系中连续特征,存在一定的局限性。例如,Ellis等提出的采样透镜方法,虽然可以缓解视觉混淆区域的数据重叠问题,却难以观察数据的层次类别特征,尤其是数据穿越坐标轴之间形成的上下文特征,很容易隐藏且丢失视觉连续性。因此,面向大规模平行坐标开展采样算法研究,如何保持数据穿越坐标轴之间的上下文关联特征,具有重要的意义。
近年来,在自然语言处理(NLP)领域,表征学习被有效地应用于连续语境特征的分析。Word2Vec是Mikolov团队提出的一种用于生成单词向量的非监督式学习算法,根据给定的语料库,通过优化训练模型,可以快速地将一个词表达为向量形式。自Word2Vec算法提出以来,被专家们广泛应用于各个领域。例如,Zhou et al.提出一种基于Word2Vec模型的简化大规模地理空间OD轨迹的算法;Xue et al.提出一种利用Word2Vec模型构建情感词典的方法。相比于Word2Vec模型,Doc2Vec是一种文档嵌入模型,是一种基于神经网络的无监督学习算法,能够把句子、段落、文档表示为向量。Bilgin等通过Doc2Vec文档嵌入模型对土耳其语和英语的Twitter信息进行情感分析;Lee等设计一种基于Doc2Vec模型的文档表示方法,能够同时表示文档的上下文关系和情感特征。
发明内容
本发明的目的是提供一种基于文档嵌入模型的大规模平行坐标数据简化方法。
为实现上述目的,本发明所采取的技术方案是:本发明大规模平行坐标数据简化方法包括:
(1)对平行坐标系中每个属性轴上的数据进行聚类,将平行坐标系中不同坐标轴上的相同的聚类视为同一单词,将穿插于平行坐标系的每条数据线视为由单词组成的一个句子,所有数据线对应的句子合成语料库;
(2)利用Doc2Vec文档嵌入模型对所述步骤(1)中得到的语料库进行训练,将语料库中的每个句子表达为一个高维向量;
(3)将所述步骤(2)中得到的高维向量投影到二维空间并进行采样,将与采样点对应的数据线绘制在平行坐标系中,得到简化后的平行坐标系。
进一步地,本发明在所述步骤(1)中,利用高斯混合模型对平行坐标系中每个属性轴上的数据进行聚类。
进一步地,本发明在所述步骤(3)中,利用t-SNE降维方法将所述步骤(2)中得到的高维向量降至二维坐标系中。
进一步地,本发明在所述步骤(3)中,利用自适应蓝噪声采样算法,在二维空间中对高维向量表达的平行坐标数据进行采样。
与现有技术相比,本发明的有益效果是:本发明基于Doc2Vec文档嵌入模型,提出了一种利用该表征学习算法来表达平行坐标中大规模数据之间的上下文特征,进而简化平行坐标视觉抽象性的方法。为了优化结果,本发明进一步采用t-SNE降维方法将高维向量投影到二维空间,增强对数据分布的视觉感知;并采用蓝噪声采样算法,缩小原始数据集大小,对于具有不同上下文特征的数据进行简化表达,降低视觉混乱;而采样出的线条也较好地保持了原始数据在相邻坐标轴之间的相关系数,使得简化结果更具代表性,从而帮助用户更好地理解原始数据的分布特征。同时,Doc2Vec文档嵌入模型可以捕捉平行坐标系中数据之间的连续语义关联特征,进而在简化过程中有效地保持这种特征,使得简化后的平行坐标不仅能够降低视觉冗余,而且能够极大限度地展示数据中隐含的连续关联特征。
附图说明
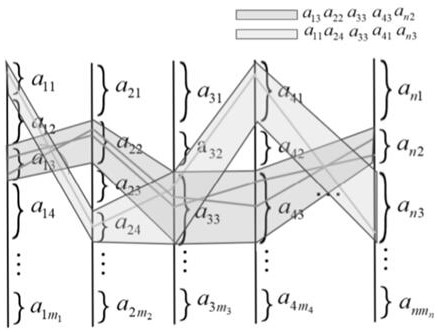
图1是本发明简化方法的一种实施方式的语料库生成说明图;
图2是本发明简化方法的一种实施方式的蓝噪声采样说明图。
具体实施方式
下面结合附图和具体实施例,对本发明作详细的说明。
本发明基于文档嵌入模型的大规模平行坐标数据简化方法的具体包括如下步骤:
步骤(一):对平行坐标系中每个属性轴上的数据进行聚类,将平行坐标系中不同坐标轴上的相同的聚类视为同一单词,将穿插于平行坐标系的每一条数据线视为由单词组成的一个句子,所有数据线对应的句子合成一个基于上下文特征感知的语料库。具体说明如下:
本发明可选择如核密度估计(KDE,kernel density estimation)、K-means、高斯混合模型(GMM,Gaussian Mixture Model)等方法对平行坐标系中每个属性轴上的数据进行聚类。以下以高斯混合模型为例进行说明。如式(1)所示,该高斯混合模型
其中,x表示某维度上的一个数据值;K为该维度上的聚类个数,它可通过核密度估计算法得到;
然而这是一个非凸问题,无法求出全局极值,只能求局部极值。为此,本发明可优选采用期望最大化算法(EM,Expectation Maximization)来应对,首先随机初始化模型参数:
将n维数据的各维度标记为
步骤(二):利用Doc2Vec文档嵌入模型对步骤(一)中得到的语料库进行训练,将语料库中的每个句子表达为一个高维向量。具体说明如下:
首先,将每个句子映射为一个由矩阵D中的列表示的唯一向量,每个单词也映射为一个唯一向量,用
其中,滑动窗口的长度为2k+1,
这里的
这里的y表示预测出单词的概率,U和b是softmax函数的参数,h是将
在句子的训练过程中,句子之间是相互独立的,但单词在句子之间是共享的。所以,在预测单词的概率时,都利用了单词所在句子的语义,因而可对单词向量和句子向量使用随机梯度下降(SGD)进行训练,并使用梯度更新参数。完成训练之后,得到样本中所有的词向量和每句话对应的句子向量。在矢量化空间中,通过一系列平行坐标轴上的属性可以更好地量化上下文特征。句子向量维度可以设定为任意合适值,作为本发明的一个实施例,可根据多次的模型训练试验,最终择优选定句子向量维度为100,并根据用户需求进行交互定义。因此,平行坐标系中的数据项可通过Doc2Vec文档嵌入模型用高维向量表示,其上下文特征在向量化空间中被量化。
步骤(三):将步骤(二)中得到的高维向量投影到二维空间,在二维空间中对高维向量表达的平行坐标数据进行采样,最终将采样点对应的原始数据线绘制在平行坐标系中,得到简化后的平行坐标系。具体说明如下:
本发明可选用如t-SNE算法、PCA算法、LDA算法等算法中的一种将步骤(二)中得到的高维向量投影到二维空间中,并对该二维空间中的向量点进行采样,最终将采样点对应的原始数据线绘制在平行坐标系中,得到简化后的平行坐标系,增强对语境特征的视觉感知,更好地保持局部和全局结构特征。其中,降维后的二维空间采样方法可选择z-order采样、四叉树采样、蓝噪声采样等方法。为了在不破坏数据特征的情况下大幅度降低数据规模,本发明优选采用自适应蓝噪声采样算法对高维向量投影得到的二维空间中的向量点进行采样。这种方法可以大幅度保留散点图的空间分布,可以更好地保留原始散点图的空间分布特征,从而保留原始数据项的上下文特征。采样过程中,可通过建立泊松圆盘来确定局部采样区域和全局采样率。对于每个泊松圆盘,将其半径初始化为r
其中,投影点密集的局部区域将被半径较小的泊松圆盘覆盖,而投影点稀疏的区域将被半径较大的泊松圆盘覆盖。对于每一个泊松圆盘,都满足稠密区域的被采样点多,稀疏区域的被采样点少。因此,采样点的分布与原始投影点的分布基本一致,具有代表性的上下文特征都会被保留下来。图2说明了矢量化空间中的自适应蓝噪声采样算法,设置一个活动点A,自适应计算半径r
本发明的有效性评估如下:
如以下表1所示,将本发明的平行坐标简化方法(以“Our”表示)与基于K-means聚类的简化方法(以“KC”表示)、基于Random(随机采样,以“RS”表示)的简化方法这两种具有普适性和权威性的简化方法对大规模平行坐标数据简化前后的相关系数差异进行了比较。表1中,横向表示简化过程中随机抽取的数据率,纵向表示三种方法在大规模平行坐标数据简化前后的相关系数的变化。
表1
由表1可以看出,在SYN、MGT、AQM三种任选的大规模数据下,这三种简化方法的相关系数的变化都会随着随机抽取的数据率的增加而减小,这是因为数据项越多,上下文特征保留的越少。尽管如此,本发明方法在大多数情况下仍优于其他两种方法,即大规模平行坐标数据简化前后的相关系数的变化最小,这在很大程度上证明了本发明简化方法在保持大规模平行坐标的上下文特征方面的优越性。
由上可见,本发明通过对平行坐标系中每个轴上的数据进行聚类,将聚类视为单词,并将穿插于平行坐标系中不同属性轴聚类的数据线视为由不同单词组成语句,将所有数据线对应的语句合成语料库;进而利用文档嵌入模型(Doc2Vec)对得到的语料库进行训练,学习得出语料库中的每条语句表达的高维向量,即完成对于平行坐标系中所有数据的向量化表示;进而利用降维算法将描述数据的高维向量投影到二维空间,并进行采样,使其能够在保持数据之间高维语义关联的基础上,降低数据规模,简化平行坐标可视化结果的视觉冗余数据线。由此,本发明通过文档嵌入模型捕捉平行坐标系中数据之间的连续语义关联特征,进而在简化过程中有效地保持这种特征,使得简化后的平行坐标不仅能够降低视觉冗余,而且能够极大限度地展示数据中隐含的连续关联特征。
- 基于文档嵌入模型的大规模平行坐标数据简化方法
- 一种基于大规模主题建模的文档模型扩展方法