一种行人再识别系统中防御图像噪声攻击的方法
文献发布时间:2023-06-19 10:38:35
技术领域
本发明涉及智能安防、视频监控防御技术领域,尤其涉及一种行人再识别系统中防御图像噪声攻击的方法。
背景技术
随着深度学习的不断发展,深度学习在恶意检测、图像识别、无人驾驶、人脸识别等人们日常生活中应用广泛,有效改善了人们的生活水平,实现了最先进的性能,但深度学习在给人们生活带来便利的同时,也相应的带来了危险的威胁。攻击者可以针对检测模型的特点,利用不同的规则逃避模型的检测,造成了严重的影响。
行人再识别(Re-ID)是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术,广泛被认为是“图像检索”的一个子问题,行人再识别目的是在多个不重叠的摄像机视图中匹配感兴趣的人,例如图3,上面一行的图片由A摄像头拍摄得到,下面一行的图片由B摄像头拍摄得到,并且,上下对应的两张图片都属于同一个人的图片,只是由于光照、拍摄角度等因素,导致同一个人的两张图片有所不同,假设感兴趣的目标人是第一行图片中的第一个人,那么行人再识别问题就相当于在AB两个摄像机中或者更多的摄像机进行这个感兴趣的目标人的识别匹配。行人再识别的任务旨在对目标行人与覆盖整个区域的无重叠多摄像机视角下出现的所有行人进行身份对比以获得目标行人的时空信息,因此有着广泛的应用,比如智能安防、智能商业-无人超市、相册聚类等。但近年来由于对抗样本的攻击,目前行人再识别防御问题是研究的热点问题,对抗样本的概念是2014年被首次提出,其本质是在正常样本上添加一些人眼不可见的扰动,添加后生成的样本能使行人再识别模型在识别这个样本时出现错误的结果,而对于对抗样本的防御技术却一直处于争论不休的阶段,多数的防御方法都只针对于一种或少数的几种攻击,很难找到一种通用的较好的鲁棒性增强方法。
目前现有的行人再识别对抗防御方法并未考虑处理前后特征差异而造成的识别性能下降。现有的对抗样本防御方法中对抗训练方法使用较为广泛,它的核心思想是在模型训练的每一次迭代中借助当前模型与某种攻击算法动态地生成对抗样本,并将之作为训练数据,与原图像训练数据共同实现模型当前轮次的训练,这在很大程度上提升了对抗样本的抵御能力。然而在行人再识别上应用时,却存在一定的弊端,针对于对抗图像噪声攻击,传统的对抗样本防御方法采用的降噪网络并没有考虑到在进行降噪对抗训练时正常输入的图像也会受到其处理重构导致网络识别性能有所下降,虽然目前已经有采用加入检测网络来判断输入样本是否为对抗样本,如果判断为正常图片,则直接输入主干网络,但硬性判定的方法却引入了判断网络的误差,判断错误的原始样本也会进入修正网络,然而实际行人再识别问题中,真实数据规模远大于对抗攻击的对抗样本规模,而判断检测的方法多用于图像分类任务,用在行人再识别降噪网络中会造成模型复杂化,对模型的性能造成了很大的影响。
如何解决上述技术问题为本发明面临的课题。
发明内容
本发明的目的在于提供一种行人再识别系统中防御图像噪声攻击的方法,该方法能有效弥补行人再识别系统对于对抗图像噪声攻击的防御缺陷,提升行人再识别模型对于对抗噪声攻击的抵御能力。
本发明是通过如下措施实现的:一种行人再识别系统中防御图像噪声攻击的方法,包括以下步骤:
步骤1:准备正常图像样本集:
正常图像样本集表示的是未经过任何操作直接采集得到的正常图片,准备正常图像样本集时,可使用已公开数据集Market-1501、CUHK03、DukeMTMC-reID等,或进行自行拍摄数据集作为正常图像样本集X={x
步骤2:构造行人再识别模型:
正常数据集为X={x
在给定探测图像集
行人再识别模型的具体步骤为:
1.通过对L和Y增加损失函数来训练参数为Θ的特征提取器F;
2.分别提取P和X的中间层的激活作为他们的视觉特征F(M,Θ)和F(W,Θ);
3.计算F(M,Θ)和F(W,Θ)之间的成对距离用于索引和排序。
步骤3:使用正常图像样本集,分别利用不同的对抗攻击方法生成对抗图像样本集:
使用准备好的正常图像样本集X={x
步骤4:将所有图像样本分为训练图像样本集和测试图像样本集。
融合所有对抗样本及正常图像样本构成图像样本集X'={X,X
步骤5:将训练图像样本通过构造的行人再识别模型完成模型训练。
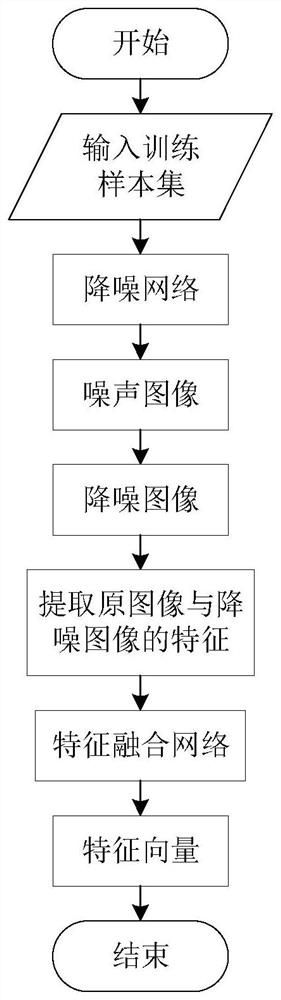
首先输入训练图像样本X'
将训练图像样本通过降噪网络得到噪声图像。
降噪网络是负责提取输入图像样本的噪声分布并输出噪声图像,降噪网络使用一种忙降噪的防御对抗网络,由于对抗噪声不同于传统意义上的噪声,它并无数学公式来描述,并且传统的噪声会影响图像的观感,但较难影响深度网络对目标任务的性能,而对抗噪声并不会对图像的观感造成影响,但却会大幅影响深度网络对目标任务的性能,因此这里不能使用传统意义上的降噪网络,使用忙降噪的防御对抗网络。
将训练图像样本减去噪声图像得到降噪图像。
提取原图像的特征以及降噪图像的特征。
将提取的所有特征输入特征融合训练网络得到训练后的特征向量;
这里将降噪前后特征加入特征融合训练网络是用来考量降噪前后特征差异,以减少对抗网络对非对抗样本的影响,弥补了现有行人再识别系统中防御缺陷。
步骤6:在测试样本集上进行行人图像识别,检验行人图像识别效果。
将测试样本集X'
评价指标可使用rank-k、mAP。
rank-k:算法返回的排序列表中,前k位为存在检索目标则称为rank-k命中;例:rank1:首位为检索目标则rank-1命中。
mAP(mean average precision):反应检索的人在数据库中所有正确的图片排在排序列表前面的程度,能更加全面的衡量Re-ID算法的性能。例:假设检索行人在图库中有4张图片,在检索的列表中位置分别为1、2、5、7,则ap为(1/1+2/2+3/5+4/7)/4=0.793;ap较大时,该行人的检索结果都相对靠前,对所有查询的ap取平均值得到mAP。
与现有技术相比,本发明的有益效果为:
(1)本发明将训练图像进行降噪后,对降噪后的图像进行特征提取时并降噪前的图像也进行特征提取,将两次提取的特征同时输入特征融合网络得到降噪前后融合的特征,用融合后的特征进行行人再识别时,将会得到更好的识别效果。
(2)利用多种对抗攻击方法进行行人再识别对抗样本生成,通过多种对抗攻击样本的对抗训练,有效提高行人再识别模型的抵御能力。
(3)考虑了处理前图像特征和处理后图像特征的差异,解决了现有技术问题中由于特征差异带来的识别率下降问题。
(4)采用特征融合的方法,解决了判断检测带来的模型复杂问题。
(5)不需要预先知道模型的部分参数,在使用时可扩展性更强。
(6)采用多种攻击方法进行对抗训练,有效提高模型抵御能力。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
图1为本发明的整体流程示意图。
图2为本发明对抗噪声样本生成流程示意图。
图3为本发明的跨摄像机行人识别示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。当然,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
实施例1
参见图1至图3,本发明提供了一种行人再识别系统中防御图像噪声攻击的方法,以Market-1501作为正常数据集为例,Market-1501数据集是由6个摄像机拍摄的1501个行人组成的,每个行人都至少由2个摄像机捕获到,并且在一个摄像机中可能有多个图像,训练集有751人,包含12936张图像,平均每个人有17.2张训练数据;测试集有750人,包含19732张图像,平均每个人有26.3张测试数据。
具体包括以下步骤:
步骤1:准备正常数据集;以Market-1501数据集为正常数据集X={x
步骤2:构造行人再识别模型;使用一个基线模型来构造行人再识别模型,利用三重损失训练Re-ID模型,给定探测图像集
步骤3:利用对抗攻击方法分别生成对抗图像样本集。
采用错误排序损失函数公式来生成对抗噪声扰动攻击样本X
这里的I是正常图像样本集X中的图像,
步骤4:将所有图像样本分为训练图像样本集和测试图像样本集。
融合所有对抗样本及正常图像样本构成图像样本集X'={X,X
步骤5:将训练图像样本通过构造的行人再识别模型完成模型训练。
首先输入训练图像样本X'
将训练图像样本X'
将训练图像样本X'
分别提取原图像X'
将所提取的原图像特征与降噪图像特征输入特征融合训练网络最终得到特征向量Γ;
步骤6:在测试样本集X'
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种行人再识别系统中防御图像噪声攻击的方法
- 一种行人再识别视频监控系统中物理图案攻击的防御方法