一种盲音频水印嵌入和提取方法及系统
文献发布时间:2023-06-19 11:17:41
技术领域
本发明涉及音频处理领域,特别是涉及一种盲音频水印嵌入和提取方法及系统。
背景技术
随着互联网技术的不断发展,多媒体技术随之迅速发展,音频水印技术在音频/语音文件的版权保护,多媒体检索和识别的信息标注,语音内容认证等领域得到了广泛的应用。
目前,现有的音频水印技术基于离散小波变换(DWT)、离散余弦变换(DCT)、双树复小波变换(DT-CWT)、分数阶傅里叶变换(FRT)、Arnold变换、熵、快速傅里叶变换(FFT)、频谱等技术取得了一系列的研究成果,各种音频水印算法的嵌入位置分别在嵌入容量、透明性、鲁棒性等方面有着较为突出的优势。水印嵌入位置的选择会直接影响到音频水印的性能,通过选择合适的嵌入位置和嵌入方法,能够有效地平衡音频水印的嵌入容量、透明性和鲁棒性,且能够实现对音频水印算法的优化。例如,通过区分静音段浊音段、遗传算法、建立听觉模型等方法对音频水印实现自适应嵌入,能够有效地提高数字水印的性能。但现有的鲁棒音频水印方法大多都是基于DCT、DWT、DFT等变换域进行水印的嵌入,这些算法普遍具有很强的鲁棒性或不可感知性,不过音频的音质与鲁棒性,作为水印信号嵌入时相互影响,始终不能够得到很好的平衡。
发明内容
本发明的目的是提供一种盲音频水印嵌入和提取方法及系统,以实现在保证音频水印的嵌入容量和透明性的情况下,提高鲁棒性。
为实现上述目的,本发明提供了如下方案:
一种盲音频水印嵌入方法,包括:
获取待嵌入水印语音;
对所述待嵌入水印语音进行嵌入位置选择,确定第一水印嵌入位置矩阵;
根据所述第一水印嵌入位置矩阵确定第一水印嵌入的帧;
将所述第一水印嵌入的帧进行双树复小波变换,得到第一细节分量;
对所述第一细节分量进行奇异值分解,得到第一奇异值矩阵;
将所述第一奇异值矩阵进行量化,得到第一量化值;
根据所述待嵌入水印语音的特征矩阵构建水印信息;
将所述水印信息嵌入所述第一奇异值矩阵,得到带有水印信息的矩阵;
根据所述水印信息对所述第一量化值进行修改,得到修改后的第一量化值;
利用所述带有水印信息的矩阵和所述修改后的第一量化值进行重构,得到嵌入水印信息的音频。
可选的,所述对所述待嵌入水印语音进行嵌入位置选择,确定第一水印嵌入位置矩阵,具体包括:
将所述待嵌入水印语音进行分段,得到第一语音段和第二语音段;所述第一语音段的能量高于所述第二语音段的能量;
选取第一设定帧作为所述第二语音段的水印嵌入位置;所述第一设定帧包括第一设定范围的帧、所述第二语音段中的能量最高的帧和第二设定范围的帧;其中,所述第一设定范围的帧在所述第二语音段中的能量最高的帧之前,所述第二设定范围的帧在所述第二语音段中的能量最高的帧之后;
删除所述第一语音段中的能量最高的帧,得到第三语音段;
选取第二设定帧和第三设定帧作为所述第一语音段的水印嵌入位置;所述第二设定帧包括第三设定范围的帧、所述第一语音段中的能量最高的帧和第四设定范围的帧;所述第三设定范围的帧在所述第一语音段中的能量最高的帧之前,所述第四设定范围的帧在所述第一语音段中的能量最高的帧之后;所述第三设定帧包括第五设定范围的帧、所述第三语音段中的能量最高的帧和第六设定范围的帧;其中,所述第五设定范围的帧在所述第三语音段中的能量最高的帧之前,所述第六设定范围的帧在所述第三语音段中的能量最高的帧之后;
根据所述第二语音段的水印嵌入位置和所述第一语音段的水印嵌入位置确定第一水印嵌入位置矩阵。
可选的,所述根据所述待嵌入水印语音的特征矩阵构建水印信息,具体包括:
将所述嵌入水印语音进行分帧处理,得到多帧待嵌入水印语音;
将多帧所述待嵌入水印语音进行分段处理,得到多段待嵌入水印语音;
将多段所述待嵌入水印语音中的每帧待嵌入水印语音进行快速傅里叶变换,得到每帧所述待嵌入水印语音的频域信号;
根据所述频域信号计算每帧待嵌入水印语音的对数能量;
根据每帧待嵌入水印语音的对数能量确定每段待嵌入水印语音的对数能量;
根据每段待嵌入水印语音的对数能量确定每段待嵌入水印语音水印能量最高的帧;
选取第四设定帧作为每段需要提取特征的帧;所述第四设定帧包括所述每段待嵌入水印语音中的水印能量最高的帧和第七设定范围的帧;所述水印能量最高的帧在第七设定范围的帧之后;
根据所述每段需要提取特征的帧确定特征选择矩阵;
根据所述特征选择矩阵和所述待嵌入水印语音的特征矩阵确定水印特征矩阵;
根据所述水印特征矩阵构建音频指纹;
根据所述音频指纹确定水印信息。
可选的,所述利用所述带有水印信息的矩阵和所述修改后的第一量化值进行重构,得到嵌入水印信息的音频,具体包括:
根据所述修改后的第一量化值和所述带有水印信息的矩阵进行重构,得到重构后的第一奇异值矩阵;
将所述重构后的第一奇异值矩阵进行第一细节分量重构,得到重构后的第一细节分量;
对所述重构后的第一细节分量进行双树复小波逆变换,得到嵌入水印信息的音频。
一种盲音频水印嵌入系统,包括:
待嵌入水印语音获取模块,用于获取待嵌入水印语音;
第一水印嵌入位置矩阵确定模块,用于对所述待嵌入水印语音进行嵌入位置选择,确定第一水印嵌入位置矩阵;
第一水印嵌入的帧确定模块,用于根据所述第一水印嵌入位置矩阵确定第一水印嵌入的帧;
第一细节分量确定模块,用于将所述第一水印嵌入的帧进行双树复小波变换,得到第一细节分量;
第一奇异值矩阵确定模块,用于对所述第一细节分量进行奇异值分解,得到第一奇异值矩阵;
第一量化值确定模块,用于将所述第一奇异值矩阵进行量化,得到第一量化值;
水印信息构建模块,用于根据所述待嵌入水印语音的特征矩阵构建水印信息;
带有水印信息的矩阵确定模块,用于将所述水印信息嵌入所述第一奇异值矩阵,得到带有水印信息的矩阵;
修改模块,用于根据所述水印信息对所述第一量化值进行修改,得到修改后的第一量化值;
重构模块,用于利用所述带有水印信息的矩阵和所述修改后的第一量化值进行重构,得到嵌入水印信息的音频。
可选的,所述第一水印嵌入位置矩阵确定模块,具体包括:
分段单元,用于将所述待嵌入水印语音进行分段,得到第一语音段和第二语音段;所述第一语音段的能量高于所述第二语音段的能量;
第一选取单元,用于选取第一设定帧作为所述第二语音段的水印嵌入位置;所述第一设定帧包括第一设定范围的帧、所述第二语音段中的能量最高的帧和第二设定范围的帧;其中,所述第一设定范围的帧在所述第二语音段中的能量最高的帧之前,所述第二设定范围的帧在所述第二语音段中的能量最高的帧之后;
删除单元,用于删除所述第一语音段中的能量最高的帧,得到第三语音段;
第二选取单元,用于选取第二设定帧和第三设定帧作为所述第一语音段的水印嵌入位置;所述第二设定帧包括第三设定范围的帧、所述第一语音段中的能量最高的帧和第四设定范围的帧;所述第三设定范围的帧在所述第一语音段中的能量最高的帧之前,所述第四设定范围的帧在所述第一语音段中的能量最高的帧之后;所述第三设定帧包括第五设定范围的帧、所述第三语音段中的能量最高的帧和第六设定范围的帧;其中,所述第五设定范围的帧在所述第三语音段中的能量最高的帧之前,所述第六设定范围的帧在所述第三语音段中的能量最高的帧之后;
第一水印嵌入位置矩阵确定单元,用于根据所述第二语音段的水印嵌入位置和所述第一语音段的水印嵌入位置确定第一水印嵌入位置矩阵。
一种盲音频水印提取方法,包括:
获取待提取水印语音;
对所述待提取水印语音进行嵌入位置选择,确定第二水印嵌入位置矩阵;
根据所述第二水印嵌入位置矩阵确定第二水印嵌入的帧;
将所述第二水印嵌入的帧进行双树复小波变换,得到第二细节分量;
对所述第二细节分量进行奇异值分解,得到第二奇异值矩阵;
将所述第二奇异值矩阵进行量化,得到第二量化值;
根据所述第二量化值提取所述第二细节分量的水印信息;
将所述第二细节分量的水印信息进行归一化汉明距离度量,确定度量值;
根据所述度量值得到优化水印信息和非优化水印信息;
将所述非优化水印信息和所述优化水印信息进行异或操作,确定音频水印。
可选的,所述将所述非优化水印信息和所述优化水印信息进行异或操作,确定音频水印,具体包括:
将非优化水印信息和优化水印信息进行异或,确定两个位置矩阵;
将两个所述位置矩阵取交集,得到水印优化矩阵;
根据所述水印优化矩阵和所述非优化水印信息确定音频水印。
一种盲音频水印提取系统,包括:
待提取水印语音获取模块,用于获取待提取水印语音;
第二水印嵌入位置矩阵确定模块,用于对所述待提取水印语音进行嵌入位置选择,确定第二水印嵌入位置矩阵;
第二水印嵌入的帧确定模块,用于根据所述第二水印嵌入位置矩阵确定第二水印嵌入的帧;
第二细节分量确定模块,用于将所述第二水印嵌入的帧进行双树复小波变换,得到第二细节分量;
第二奇异值矩阵确定模块,用于对所述第二细节分量进行奇异值分解,得到第二奇异值矩阵;
第二量化值确定模块,用于将所述第二奇异值矩阵进行量化,得到第二量化值;
提取模块,用于根据所述第二量化值提取所述第二细节分量的水印信息;
度量值确定模块,用于将所述第二细节分量的水印信息进行归一化汉明距离度量,确定度量值;
优化水印信息和非优化水印信息模块,用于根据所述度量值得到优化水印信息和非优化水印信息;
音频水印确定模块,用于将所述非优化水印信息和所述优化水印信息进行异或操作,确定音频水印。
可选的,所述音频水印确定模块,具体包括:
异或单元,用于将所述非优化水印信息和所述优化水印信息进行异或,确定两个位置矩阵;
取交单元,用于将两个所述位置矩阵取交集,得到水印优化矩阵;
音频水印确定单元,用于根据所述水印优化矩阵和所述非优化水印信息确定音频水印。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明提供的一种盲音频水印嵌入和提取方法及系统,利用双数复小波变换和奇异值分解对语音进行处理,将水印信息通过量化的方式嵌入到奇异值矩阵中,最后获得嵌入水印信息的音频,使得鲁棒音频水印具有良好的透明性和鲁棒性,具有较高的运行效率,经过多次操作提取的水印信息仍具有较高的查全率和查准率,因此,实现了在保证音频水印的嵌入容量和透明性的情况下,提高鲁棒性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提供的一种盲音频水印嵌入方法流程图;
图2为本发明提供的盲音频水印嵌入和提取方法流程图;
图3为本发明提供的原始语音和含有水印信息的语音的波形图;
图4为本发明提供的原始语音和含有水印信息的语音的语谱图;
图5为本发明提供的一种盲音频水印嵌入系统示意图;
图6为本发明提供的一种盲音频水印提取方法流程图;
图7为本发明提供的一种盲音频水印提取系统示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种盲音频水印嵌入和提取方法及系统,以实现在保证音频水印的嵌入容量和透明性的情况下,提高鲁棒性。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,本发明提供的一种盲音频水印嵌入方法,包括:
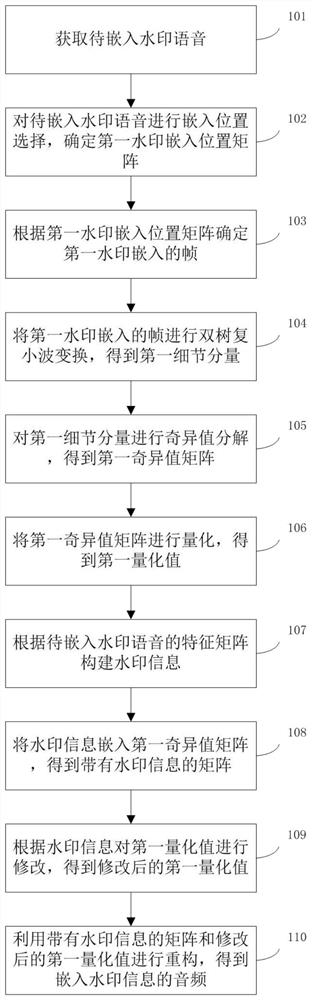
步骤101:获取待嵌入水印语音。
步骤102:对待嵌入水印语音进行嵌入位置选择,确定第一水印嵌入位置矩阵。步骤102,具体包括:
将待嵌入水印语音进行分段,得到第一语音段和第二语音段;第一语音段的能量高于第二语音段的能量。
选取第一设定帧作为第二语音段的水印嵌入位置;第一设定帧包括第一设定范围的帧、第二语音段中的能量最高的帧和第二设定范围的帧;其中,第一设定范围的帧在第二语音段中的能量最高的帧之前,第二设定范围的帧在第二语音段中的能量最高的帧之后。
删除第一语音段中的能量最高的帧,得到第三语音段。
选取第二设定帧和第三设定帧作为第一语音段的水印嵌入位置;第二设定帧包括第三设定范围的帧、第一语音段中的能量最高的帧和第四设定范围的帧;第三设定范围的帧在第一语音段中的能量最高的帧之前,第四设定范围的帧在第一语音段中的能量最高的帧之后;第三设定帧包括第五设定范围的帧、第三语音段中的能量最高的帧和第六设定范围的帧;其中,第五设定范围的帧在第三语音段中的能量最高的帧之前,第六设定范围的帧在第三语音段中的能量最高的帧之后。
根据第二语音段的水印嵌入位置和第一语音段的水印嵌入位置确定第一水印嵌入位置矩阵。
步骤103:根据第一水印嵌入位置矩阵确定第一水印嵌入的帧。
步骤104:将第一水印嵌入的帧进行双树复小波变换,得到第一细节分量。
步骤105:对第一细节分量进行奇异值分解,得到第一奇异值矩阵。
步骤106:将第一奇异值矩阵进行量化,得到第一量化值。
步骤107:根据待嵌入水印语音的特征矩阵构建水印信息。步骤107,具体包括:
将待嵌入水印语音进行分帧处理,得到多帧待嵌入水印语音。
将多帧待嵌入水印语音进行分段处理,得到多段待嵌入水印语音。
将多段待嵌入水印语音中的每帧待嵌入水印语音进行快速傅里叶变换,得到每帧待嵌入水印语音的频域信号。
根据频域信号计算每帧待嵌入水印语音的对数能量。
根据每帧待嵌入水印语音的对数能量确定每段待嵌入水印语音的对数能量。
根据每段待嵌入水印语音的对数能量确定每段待嵌入水印语音水印能量最高的帧。
选取第四设定帧作为每段需要提取特征的帧;第四设定帧包括每段待嵌入水印语音中的水印能量最高的帧和第七设定范围的帧;水印能量最高的帧在第七设定范围的帧之后。
根据每段需要提取特征的帧确定特征选择矩阵。
根据特征选择矩阵和待嵌入水印语音的特征矩阵确定水印特征矩阵。
根据水印特征矩阵构建音频指纹。
根据音频指纹确定水印信息。
步骤108:将水印信息嵌入第一奇异值矩阵,得到带有水印信息的矩阵。
步骤109:根据水印信息对第一量化值进行修改,得到修改后的第一量化值。
步骤110:利用带有水印信息的矩阵和修改后的第一量化值进行重构,得到嵌入水印信息的音频。步骤110,具体包括:
根据修改后的第一量化值和带有水印信息的矩阵进行重构,得到重构后的第一奇异值矩阵。
将重构后的第一奇异值矩阵进行第一细节分量重构,得到重构后的第一细节分量。
对重构后的第一细节分量进行双树复小波逆变换,得到嵌入水印信息的音频。
如图5所示,一种盲音频水印嵌入系统,包括:
待嵌入水印语音获取模块501,用于获取待嵌入水印语音。
第一水印嵌入位置矩阵确定模块502,用于对待嵌入水印语音进行嵌入位置选择,确定第一水印嵌入位置矩阵。
第一水印嵌入的帧确定模块503,用于根据第一水印嵌入位置矩阵确定第一水印嵌入的帧。
第一细节分量确定模块504,用于将第一水印嵌入的帧进行双树复小波变换,得到第一细节分量。
第一奇异值矩阵确定模块505,用于对第一细节分量进行奇异值分解,得到第一奇异值矩阵。
第一量化值确定模块506,用于将第一奇异值矩阵进行量化,得到第一量化值。
水印信息构建模块507,用于根据待嵌入水印语音的特征矩阵构建水印信息。
带有水印信息的矩阵确定模块508,用于将水印信息嵌入第一奇异值矩阵,得到带有水印信息的矩阵。
修改模块509,用于根据水印信息对第一量化值进行修改,得到修改后的第一量化值。
重构模块510,用于利用带有水印信息的矩阵和修改后的第一量化值进行重构,得到嵌入水印信息的音频。
其中,第一水印嵌入位置矩阵确定模块502,具体包括:
分段单元,用于将待嵌入水印语音进行分段,得到第一语音段和第二语音段;第一语音段的能量高于第二语音段的能量。
第一选取单元,用于选取第一设定帧作为第二语音段的水印嵌入位置;第一设定帧包括第一设定范围的帧、第二语音段中的能量最高的帧和第二设定范围的帧;其中,第一设定范围的帧在第二语音段中的能量最高的帧之前,第二设定范围的帧在第二语音段中的能量最高的帧之后。
删除单元,用于删除第一语音段中的能量最高的帧,得到第三语音段。
第二选取单元,用于选取第二设定帧和第三设定帧作为第一语音段的水印嵌入位置;第二设定帧包括第三设定范围的帧、第一语音段中的能量最高的帧和第四设定范围的帧;第三设定范围的帧在第一语音段中的能量最高的帧之前,第四设定范围的帧在第一语音段中的能量最高的帧之后;第三设定帧包括第五设定范围的帧、第三语音段中的能量最高的帧和第六设定范围的帧;其中,第五设定范围的帧在第三语音段中的能量最高的帧之前,第六设定范围的帧在第三语音段中的能量最高的帧之后。
第一水印嵌入位置矩阵确定单元,用于根据第二语音段的水印嵌入位置和第一语音段的水印嵌入位置确定第一水印嵌入位置矩阵。
如图6所示,本发明还提供了一种盲音频水印提取方法,包括:
步骤601:获取待提取水印语音。
步骤602:对待提取水印语音进行嵌入位置选择,确定第二水印嵌入位置矩阵。
步骤603:根据第二水印嵌入位置矩阵确定第二水印嵌入的帧。
步骤604:将第二水印嵌入的帧进行双树复小波变换,得到第二细节分量。
步骤605:对第二细节分量进行奇异值分解,得到第二奇异值矩阵。
步骤606:将第二奇异值矩阵进行量化,得到第二量化值。
步骤607:根据第二量化值提取第二细节分量的水印信息。
步骤608:将第二细节分量的水印信息进行归一化汉明距离度量,确定度量值。
步骤609:根据度量值得到优化水印信息和非优化水印信息。
步骤610:将非优化水印信息和优化水印信息进行异或操作,确定音频水印。其中,步骤610,具体包括:
将非优化水印信息和优化水印信息进行异或,确定两个位置矩阵。
将两个位置矩阵取交集,得到水印优化矩阵。
根据水印优化矩阵和非优化水印信息确定音频水印。
如图7所示,本发明还提供了一种盲音频水印提取系统,包括:
待提取水印语音获取模块701,用于获取待提取水印语音。
第二水印嵌入位置矩阵确定模块702,用于对待提取水印语音进行嵌入位置选择,确定第二水印嵌入位置矩阵。
第二水印嵌入的帧确定模块703,用于根据第二水印嵌入位置矩阵确定第二水印嵌入的帧。
第二细节分量确定模块704,用于将第二水印嵌入的帧进行双树复小波变换,得到第二细节分量。
第二奇异值矩阵确定模块705,用于对第二细节分量进行奇异值分解,得到第二奇异值矩阵。
第二量化值确定模块706,用于将第二奇异值矩阵进行量化,得到第二量化值。
提取模块707,用于根据第二量化值提取第二细节分量的水印信息。
度量值确定模块708,用于将第二细节分量的水印信息进行归一化汉明距离度量,确定度量值。
优化水印信息和非优化水印信息模块709,用于根据度量值得到优化水印信息和非优化水印信息。
音频水印确定模块710,用于将非优化水印信息和优化水印信息进行异或操作,确定音频水印。
其中,音频水印确定模块710,具体包括:
异或单元,用于将非优化水印信息和优化水印信息进行异或,确定两个位置矩阵。
取交单元,用于将两个位置矩阵取交集,得到水印优化矩阵。
音频水印确定单元,用于根据水印优化矩阵和非优化水印信息确定音频水印。
本发明还提供了一种盲音频水印嵌入和提取方法的具体实现方式,可应用于语音文件的版权保护、信息标注等。以音频检索为出发点,提取原始语音的音频指纹作为水印信息对语音文件进行标注,用于后续的音频指纹检索。首先在DT-CWT域采用基于能量的水印嵌入位置选择方法确定水印的嵌入位置,其次利用DT-CWT和奇异值分解(SVD)对语音进行处理,将水印信息通过量化的方式嵌入到奇异值矩阵中,最后获得含水印的语音文件。本发明在保证嵌入容量和透明性的情况下,有效地提高了鲁棒性,且对常见的诸如MP3压缩、低通滤波、重量化、重采样等音频攻击方法具有很强的鲁棒性,可以快速高效地对语音文件进行信息标注。
如图2所示,流程主要由水印嵌入、水印提取算法两个部分组成。
1水印嵌入算法
1.1水印生成(构建音频指纹)
为了降低数据量并保证音频指纹的鲁棒性,本发明选择降维后的12维梅尔倒谱系数(Mel-frequency cepstral coefficient,MFCC)特征矩阵中的1、3、10、11、12维特征构建音频指纹,该5维特征包含了原始音频12维矩阵67%以上的信息量。为了进一步降低数据量,可通过基于能量的特征降维对MFCC特征矩阵进行处理并构建音频指纹来作为嵌入的水印信息。水印生成的具体处理步骤如下:
步骤1:特征提取。设语音采样率为16kHz,帧长设定为32ms、帧移为10ms、窗函数为汉明窗,设置24个梅尔滤波器,提取原始语音的12维MFCC特征矩阵MFCC=(M
步骤2:分段并计算对数能量。首先将语音信号按照步骤1的分帧方法分成n
其中,E(i)为对数能量,k为傅里叶变换的点数,k=0,1,...,l-1,l为每帧帧长,i为采样点,b为常数。
步骤3:构建特征矩阵。通过对比每段信号[f
步骤4:构建音频指纹。将特征矩阵MFCC"通过式(2)的阈值判断公式来构建音频指纹h=(h
步骤5:生成水印。首先利用步骤4得到的音频指纹h'构建大小为1200×1的水印w=(h',h',h'),然后对水印w进行整理,重构为600×2的水印ww=(w
1.2嵌入位置选择
本发明通过基于能量的嵌入位置选择方法确定水印嵌入位置,能够在保证嵌入容量的同时,有效地提高鲁棒性和透明性。嵌入位置选择的具体处理步骤如下:
步骤1:预处理。将原始语音进行不重叠分帧,帧长为128、窗函数为汉明窗,分成n
步骤2:分段并计算对数能量。将分帧后的信号平均分为五段、每段帧数为z
步骤3:确定低能量语音段的水印嵌入位置。将两段能量较低的语音段分别通过对比该段信号[f'
步骤4:确定高能量语音段的水印嵌入位置。将三段能量较高的语音段分别通过对比该段信号[f
步骤5:水印嵌入位置整理。将三段高能量语音段的480个水印嵌入帧和两段低能量语音段的120个水印嵌入帧确定后,构建一个n
1.3水印嵌入
音频经过DT-CWT后,其低频分量包含原始语音更多的信息,进行水印嵌入后,水印有较好的鲁棒性,不过对原始语音影响较大,会严重影响水印的透明性,所以本发明选择在高频分量进行水印嵌入。水印嵌入的具体处理步骤如下:
步骤1:DT-CWT变换。将原始语音按照1.2嵌入位置选择中步骤1的分帧方法进行分帧,通过1.2嵌入位置选择中步骤5的水印嵌入位置矩阵T'
步骤2:SVD分解。将DT-CWT后的细节分量D
其中,λ
步骤3:奇异值量化。取奇异值S
c=floor(S(1,1)/a) (4)
其中c为量化值,floor为向下取整函数。
步骤4:水印的嵌入。根据需要嵌入的水印信息按照式(5)对量化值进行修改,将水印ww中的w
其中c′为修改后的量化值,w为需要嵌入的水印信息。
步骤5:奇异值重构。根据修改后的量化值c'与量化步长a按照式(6)重构每段细节分量的奇异值矩阵。
S′(1,1)=c′×a+0.5×a (6)
步骤6:细节分量重构。按照式(7)通过奇异值矩阵S'与U、V进行每段细节分量的SVD重构、重构细节分量为D'
D′
D′
步骤7:语音重构。对得到的重构细节分量D"
2水印提取算法
步骤1:预处理。按照1.2嵌入位置选择的方法计算语音水印嵌入位置,之后按照1.3水印嵌入中步骤1、步骤2的方法计算每个水印嵌入帧的奇异值S
步骤2:水印的提取。对奇异值S
步骤3:确定水印信息。按照式(10)将w'
其中,L
步骤4:水印的优化。将水印w'
性能分析:
实验语音选自清华大学语言与语言技术中心的开放汉语语音数据库THCHS-30,采样频率为16kHz、采样精度为16bit、单通道wav格式。将1000条语音分别通过音频处理软件Gold Wave 6.38和Matlab R2017a进行重采样、重量化、添加白噪声、MP3压缩等11种内容保持操作,得到共12000条语音作为检索语音数据库。实验硬件环境:Intel(R)Core(TM)i5-7300HQ CPU,2.50GHz,内存8GB。软件环境为:Windows 10,MATLAB R2017a。
1嵌入容量分析
嵌入容量是衡量音频水印算法非常重要的指标之一,国际唱片业协会(International Federation ofthe Phonographic Industry,IFPI)规定鲁棒音频水印算法的嵌入容量应该高于20bps。本发明采用的嵌入容量计算公式如式(11):
其中,p
本发明的嵌入容量在水印嵌入时细节分量的分段数N分别设为2和4来进行测试。当N=2时,嵌入容量为60bps,水印方案嵌入容量较低,不过透明性较高,且对各种攻击有较高的鲁棒性;而当N=4时,嵌入容量为120bps,水印方案在鲁棒性和嵌入容量之间形成一个权衡,在降低一定的透明性和鲁棒性的情况下有效地提高了嵌入容量。本发明在两种分段情况下,水印的嵌入容量皆高于IFPI所规定的鲁棒音频水印的嵌入容量,所以本发明具有较高的嵌入容量,能够满足对语音文件进行信息标注的实际需要。
2透明性分析
本发明选择能够直观、准确地反映含水印语音听觉质量变化程度的信噪比(Signal-to-Noise Ratio,SNR)、感知语音质量评估(Perceptual Evaluation of SpeechQuality,PESQ)对含水印语音听觉质量进行评价,IFPI规定音频水印的SNR应高于20dB,SNR计算公式如式(12):
其中,L为原始语音长度、x为原始语音、y为含水印语音。
PESQ是客观平均意见得分(Mean Opinion Score,MOS)值的评价方法,其值在-1至4.5之间。当PESQ>3.5时,含水印语音的音频质量较好。
本发明在分段数N=2时,SNR为31.54dB、PESQ为4.146,当N=4时,SNR为23.65dB、PESQ为3.894,SNR值均高于IFPI所规定的20dB、PESQ值均高于3.5,说明本发明的透明性较高。
为了进一步验证本发明的透明性性能,在图3和图4中对比了原始语音与含水印语音的波形图与语谱图,其中,图3(a)为原始语音的波形图;图3(b)为含有水印信息的语音的波形图;图4(a)为原始语音语谱图;图4(b)为含有水印信息的语音的语谱图。从图3和图4可以看出,原始语音在嵌入水印后,语音波形变化较小、语谱图变化不明显,说明本发明透明性较高,也说明含水印语音的听觉质量较高。
3鲁棒性分析
本发明采用常见的攻击方法(MP3压缩(128kbps,MP3)、截止频率为4khz的低通滤波(LPF)、重量化(16bit→8bit→16bit,R.Q)、重采样(16khz→8khz→16khz,R.S)、幅度缩放0.8和1.2(A↓和A↑)、添加回声(衰减5%、时长分别为10ms和50ms,E10和E50)和添加20dB、30dB、35dB窄带高斯噪声(G.N20dB、G.N35dB、G.N30dB)等11种内容保持操作)来测试含水印语音的鲁棒性,并通过式(13)的误码率(Bit Error Rate,BER)来衡量鲁棒性。其中BER越小则水印算法的鲁棒性越好,IFPI规定鲁棒水印在面对语音内容保持操作时所提取的水印的BER不能高于20%。表1为本发明在不同分段数下的鲁棒性对比结果表。
其中,w"
表1不同分段数下的鲁棒性对比结果表
由表1可知,在分段数N分别为2和4时,本发明在经过11种内容保持操作后的水印BER均低于IFPI所规定的BER,说明本发明具有较强的鲁棒性。从表1中可以看出,本发明在幅值缩放处理后鲁棒性一般,BER偏高,这是因为本发明采用基于能量来选择水印嵌入位置,而能量对于幅值缩放方面鲁棒性较差。
本发明通过提取原始语音的音频指纹作为水印信息进行嵌入,为了更全面的反映鲁棒性对检索性能的影响,设定相似性阈值0.35≤T≤0.4,并通过归一化汉明距离进行匹配检索,通过式(14)的查全率R和式(15)的查准率P来衡量语音经过11种内容保持操作后音频指纹的检索性能。表2为T=0.35时的经过11种内容保持操作后的音频指纹检索性能表。其中,表格中数值单位均为百分比。
其中,f
表2 T=0.35时的经过11种内容保持操作后的音频指纹检索性能表
由表2可知,在相似性阈值T=0.35时,含水印语音在受到各种内容保持攻击后,查全率和查准率均比较高,能够实现较为精确地检索,说明本发明具有较强的鲁棒性。
4运行效率
本发明在语音库中随机选出1000条长度为20s的语音,计算平均计算时间(包括水印嵌入和提取的时间)。在分段数N=2时,平均计算时间为1.921s,在分段数N=4时,平均计算时间为1.8366s。说明本发明通过能量确定水印嵌入位置,能够简单高效地实现水印的优化,且通过量化可在DT-CWT域细节分量的奇异值矩阵中进行水印嵌入,方法简单高效。
本发明通过提取原始语音的梅尔倒谱系数来构建音频指纹作为水印信息;对原始语音通过基于能量的嵌入位置选择方法确定水印嵌入帧,并对其应用4级DT-CWT变换;选取低频分量分段进行奇异值分解;将音频指纹通过量化的方法嵌入到奇异值矩阵的奇异值中,获得含有水印的语音。利用双树复小波变换(DT-CWT)相较于小波变换和小波包变换的优势、以及SVD在水印嵌入方面的优势,利用基于能量的水印嵌入位置选择方法确定水印嵌入的位置,在保证嵌入容量的前提下来提高鲁棒性;利用DT-CWT和SVD对语音进行处理,将水印信息通过量化的方式嵌入到奇异值矩阵中,使得鲁棒音频水印具有良好的透明性和鲁棒性;具有较高的运行效率;含水印语音在经过多种内容保持操作后所提取的音频指纹仍具有较高的查全率和查准率,说明本发明很好地权衡了嵌入容量、透明性和鲁棒性之间的关系,且对常见的诸如MP3压缩、低通滤波、重量化、重采样等攻击方法具有很强的鲁棒性,可以有效地利用音频水印对语音文件进行信息标注,可满足对原始语音进行信息标注的实际需求。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种盲音频水印嵌入和提取方法及系统
- 一种用于任意嵌入比的图片水印嵌入及盲提取方法