非结构化文本的事件抽取方法、系统及装置
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及人工智能自然语言处理技术领域,尤其是涉及一种非结构化文本的事件抽取方法、系统及装置。
背景技术
在现有技术中,事件抽取是把含有事件信息的非结构化文本以结构化的形式呈现出来,在自动文摘、自动问答、信息检索等领域有着广泛的应用。事件抽取技术的核心价值,是可以把半结构化、非结构化数据转换为对事件的结构化描述,进而支持丰富的下游应用。
目前的实体识别主要采取机器学习、深度学习,但是都存在不足之处:
(1)基于深度学习、机器学习的方法,首先需要收集前期的训练语料,然后进行标注,然而,对于金融、保险、石化等垂直领域,所需的标注语料是非常稀缺的,从而增加了该技术方案落地的困难性;同时,深度学习的效果存在很大的不稳定因素,准确率难以把控;
(2)基于深度学习、机器学习的方法,对于事件类型的增加则比较繁琐,需要从新训练,效率低下。
因此目前亟需一种新的非结构化文本事件抽取方法。
发明内容
本发明的目的在于提供一种非结构化文本的事件抽取方法、系统及装置,旨在解决现有技术中的上述问题。
本发明提供一种非结构化文本的事件抽取方法,包括:
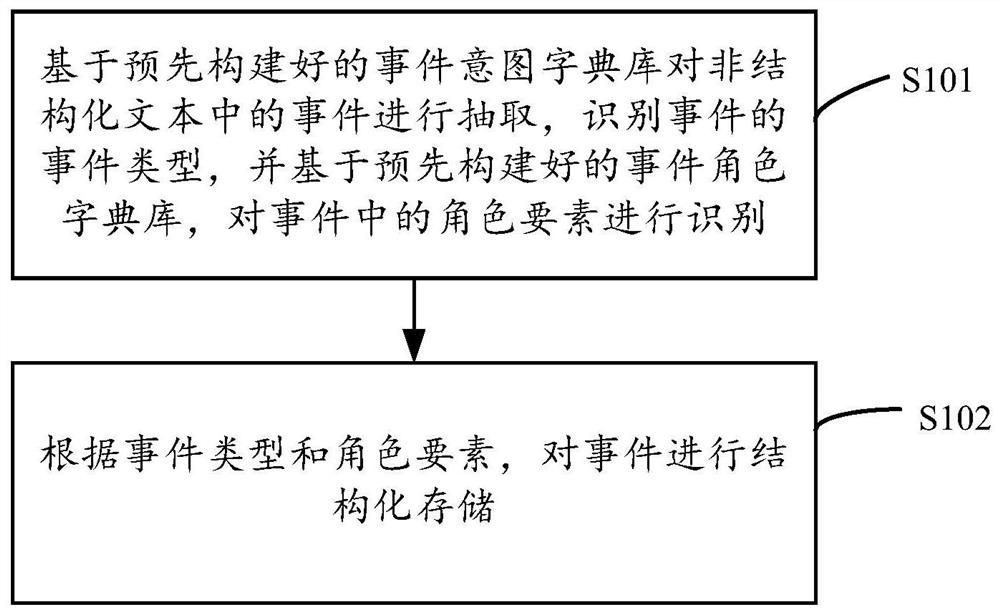
基于预先构建好的事件意图字典库对非结构化文本中的事件进行抽取,识别事件的事件类型,并基于预先构建好的事件角色字典库,对事件中的角色要素进行识别;
根据事件类型和角色要素,对事件进行结构化存储。
本发明提供一种非结构化文本的事件抽取系统,包括:
解析层,用于基于预先构建好的事件意图字典库对非结构化文本中的事件进行抽取,识别事件的事件类型,并基于预先构建好的事件角色字典库,对事件中的角色要素进行识别;
应用层,用于根据事件类型和角色要素,对事件进行结构化存储。
本发明实施例还提供一种非结构化文本的事件抽取装置,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,计算机程序被处理器执行时实现上述非结构化文本的事件抽取方法的步骤。
本发明实施例还提供一种计算机可读存储介质,计算机可读存储介质上存储有信息传递的实现程序,程序被处理器执行时实现上述非结构化文本的事件抽取方法的步骤。
采用本发明实施例,在特定领域中性能较好,知识表示简洁,便于理解和后续应用;本发明实施例通过配置字典的形式,使得问句中事件的解析更灵活,便于维护,易于扩展,避免了深度学习需要收集相关语料、标注、训练等复杂的工序。此外,本发明实施例基于规则的方式,在领域内能够实现较高的事件识别准确率,避免了基于深度学习的不稳定性。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例的非结构化文本的事件抽取方法的示意图;
图2是本发明实施例的非结构化文本的事件抽取方法详细处理的示意图;
图3是本发明实施例的非结构化文本的事件抽取系统的示意图;
图4是本发明实施例的非结构化文本的事件抽取装置的示意图。
具体实施方式
本发明实施例的技术方案意在通过规则和字典相结合的方法,实现非结构化文本中事件的抽取。通过事件意图字典,识别出文本是否含具有表述事件的意图;对于事件中具体角色的识别则是通过定义相对对应的角色字典,通过角色字典识别事件的各个角色。在本发明实施例中,基于规则和字典的事件抽取解析方法总共分为三个部分,数据层、解析层以及应用层。数据层主要为梳理相关的事件类型,以及各个事件类型的事件角色;然后通过文本数据,整理出各个事件类型的规则字典,构成事件意图字典库;同时,由业务专家给出各个事件下的业务领域内关注的事件角色要素,构成事件角色字典库;解析层主要是利用整理好的规则字典库,对文本中的事件进行抽取。意图字典库识别出文本中的事件类型,然后通过事件角色字典库识别出事件的各个角色要素。应用层主要对抽取的事件进行结构化存储,以便于上层应用的使用。
下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”、“顺时针”、“逆时针”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个所述特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。此外,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
方法实施例
根据本发明实施例,提供了一种非结构化文本的事件抽取方法,图1是本发明实施例的非结构化文本的事件抽取方法的流程图,在执行如图1所示的处理步骤之前,首先需要进行如下准备处理:构建事件意图字典库和事件角色字典库,具体包括:
根据业务需要定义从非结构化文本中抽取的事件类型以及与各个事件类型对应的角色元素;
根据定义的事件类型,从非结构化文本整理出对应的事件类型规则,根据事件类型和事件类型规则构建事件意图字典库;
根据定义的与各个事件类型对应的角色元素,整理业务领域内的事件角色实例,根据角色元素和事件角色实例构建事件角色字典库,其中,事件角色字典库与相应的事件类型相对应,具体包括:人物字典、人物职务字典、和/或地点字典。
在本发明实施例中,在事件意图字典库和事件角色字典库运行一段时间且积累了足够的语料之后,利用得到的结构化数据进行语料标注,并利用深度学习的方法对新的事件类型规则和事件角色实例进行深度挖掘,更新事件意图字典库和事件角色字典库。
如图1所示,根据本发明实施例的非结构化文本的事件抽取方法具体包括:
步骤101,基于预先构建好的事件意图字典库对非结构化文本中的事件进行抽取,识别事件的事件类型,并基于预先构建好的事件角色字典库,对事件中的角色要素进行识别;步骤101具体包括如下处理:
对非结构化文本进行预处理;
对预处理后的非结构化文本进行分句;
基于预先构建好的事件意图字典库进行逐句识别,根据事件类型规则判断每个句子中蕴含的事件类型;
基于与事件类型对应的事件角色字典库,识别出事件中的事件角色实例。
步骤102,根据事件类型和角色要素,对事件进行结构化存储。
以下结合附图,对本发明实施例的上述技术方案进行详细说明。
根据本发明实施例的方法具体包括如下处理:
步骤1,规则字典库的构建:
1、数据的准备:准备需要抽取的非结构化文本,定义业务上要抽取的事件类型以及各个事件类型要抽取的角色元素。例如,要抽取的事件类型为人物的观点,该事件类型的角色元素为发表观点的人物,人物的职务,人物所在的机构,发表观点的时间,以及观点的内容。每一种事件类型,都对应一套角色实例字典。
2、规则字典的梳理:
(1)事件类型字典的梳理:
定义好事件的类型及角色元素之后,需要梳理事件类型的规则及角色元素字典。通过梳理部分的非结构化文本,整理出一部分相关的事件类型规则,如表1所示:
表1
(2)角色实例字典的梳理:整理出业务领域类常用的事件角色实例。对于业务领域类的事件角色,由于垂直领域类比较关注的角色相对有限,通过一定的梳理可以很好的得到相应的数据,这种做法比较容易在垂直领域落地,而对于通用领域,该方法可操作性不强。例如,对应“观点”这一事件类型,所对应的角色实例字典有人物字典、人物职务字典、地点字典等,在整理出领域内比较关注的人物名称、职务名称等后,就可以构建相应的字典。
3、字典的补充:在经过上述的字典构建之后,通过字典库运行一段时间,积累了足够的语料之后,可以利用得到的结构化数据进行语料标注,然后利用深度学习的方法对其进行深度挖掘,补充字典中没有的角色实例和事件类型,从而实现闭环的事件加工。
步骤2,事件解析应用:图2是本发明实施例的非结构化文本的事件抽取方法详细处理的流程图,如图2所示,在准备好事件类型字典和角色实例之后,事件解析应用流程如下:
1、输入非结构化文本:输入要加工的非结构化的文本数据,进行相应的预处理,比如大小写转换、特殊字符剔除、停用词的去除等。
2、根据标点符号进行文本的拆分,进行分句:由于对于篇章和段落的分析效果比较差,因为篇章和句子中可能含有多个事件类型,每个事件类型又包含多个事件角色,这样事件类型和角色的对应就是一个难点。通过分析得出,大多数事件的角色元素及事件要领可在一句化表述清楚,因此,本发明实施例采用以句子为分析单位。
3、通过事件类型字典逐句识别,判断句子中蕴含的事件类型:对于分句的文本,通过事件类型字典中定义的事件类型的规则识别出文本中所蕴含的事件类型。
4、判断出事件类型之后,通过角色实例字典识别出事件中的角色实例:识别出句子文本中蕴含的事件类型之后,再通过事件类型所对应的角色实例字典,识别出事件类型所对应的各个角色。例如,对应“观点”这一事件类型,所对应的角色实例字典有人物字典、人物职务字典、地点字典等。
综上所述,本发明实施例的基于规则字典匹配的技术方案在特定领域中性能较好,知识表示简洁,便于理解和后续应用。本发明实施例通过配置字典的形式,使得问句中事件的解析更灵活,便于维护,易于扩展,例如,有新的事件类型的加入,直接通过配置字典即可增加新的事件类型,避免了深度学习需要收集相关语料、标注、训练等复杂的工序。此外,本发明实施例基于规则的方式,在领域内能够实现较高的事件识别准确率,避免了基于深度学习的不稳定性。
系统实施例
根据本发明实施例,提供了一种非结构化文本的事件抽取系统,图3是本发明实施例的非结构化文本的事件抽取系统的示意图,如图3所示,根据本发明实施例的非结构化文本的事件抽取系统具体包括:
数据层30,用于构建事件意图字典库和事件角色字典库;
数据层30具体用于:
根据业务需要定义从非结构化文本中抽取的事件类型以及与各个事件类型对应的角色元素;
根据定义的事件类型,从非结构化文本整理出对应的事件类型规则,根据事件类型和事件类型规则构建事件意图字典库;
根据定义的与各个事件类型对应的角色元素,整理业务领域内的事件角色实例,根据角色元素和事件角色实例构建事件角色字典库,其中,事件角色字典库与相应的事件类型相对应,具体包括:人物字典、人物职务字典、和/或地点字典;
在事件意图字典库和事件角色字典库运行一段时间且积累了足够的语料之后,利用得到的结构化数据进行语料标注,并利用深度学习的方法对新的事件类型规则和事件角色实例进行深度挖掘,更新事件意图字典库和事件角色字典库。
解析层32,用于基于预先构建好的事件意图字典库对非结构化文本中的事件进行抽取,识别事件的事件类型,并基于预先构建好的事件角色字典库,对事件中的角色要素进行识别;解析层32具体用于:
对非结构化文本进行预处理;
对预处理后的非结构化文本进行分句;
基于预先构建好的事件意图字典库进行逐句识别,根据事件类型规则判断每个句子中蕴含的事件类型;
基于与事件类型对应的事件角色字典库,识别出事件中的事件角色实例。
应用层34,用于根据事件类型和角色要素,对事件进行结构化存储。
本发明实施例是与上述方法实施例对应的系统实施例,各个模块的具体操作可以参照方法实施例的描述进行理解,在此不再赘述。
装置实施例一
本发明实施例提供一种非结构化文本的事件抽取装置,如图4所示,包括:存储器40、处理器42及存储在所述存储器40上并可在所述处理42上运行的计算机程序,所述计算机程序被所述处理器42执行时实现如方法实施例中所述的步骤。
装置实施例二
本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质上存储有信息传输的实现程序,所述程序被处理器42执行时实现如方法实施例中所述的步骤。
本实施例所述计算机可读存储介质包括但不限于为:ROM、RAM、磁盘或光盘等。
显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 非结构化文本的事件抽取方法、系统及装置
- 非结构化文本事件抽取方法