一种实现数据预处理与重排序的数据收发方法和存储设备
文献发布时间:2023-06-19 13:29:16
技术领域
本发明涉及数据处理技术领域,特别涉及一种实现数据预处理与重排序的数据收发方法和存储设备。
背景技术
随着计算机技术的发展伴随着半导体技术的发展,SOC芯片的功能越来越复杂,其需要进行大批量数据的连续搬运和传输。虽然在软件层面上也可以进行一些数据的搬运和传输,但是会消耗大量的CPU资源,且功耗较大,故此随之兴起的需要设计专门的硬件接口模块来完成数据的传输。AXI(AdvancedExtensible Interface,高级扩展接口)总线是现有SOC中应用最为广泛的总线标准。
专利201710817858中提出了一种基于SOC的AXI总线接口数据传输系统,能够实现SOC与FPGA的高速数据传输,然而其未对AXI总线的out of order和interleave功能对系统进行优化,对总线不够友好。
专利201910280264.X中设计的重排序电路通过多级的重排序,使网络负载更加均衡。然而每一级的重排序电路都需要输入缓存模块与重组缓存模块,增加了电路面积。
故此如何解决现有技术中对总线性能不够友好、现有数据传输系统只具有简单的数据接收能力数据处理效率低等成了亟需解决的技术问题。
发明内容
为此,需要提供一种实现数据预处理与重排序的数据收发方法,用以解决现有数据传输系统对总线性能不够友好、只具有简单的数据接收能力数据处理效率低等技术问题。具体技术方案如下:
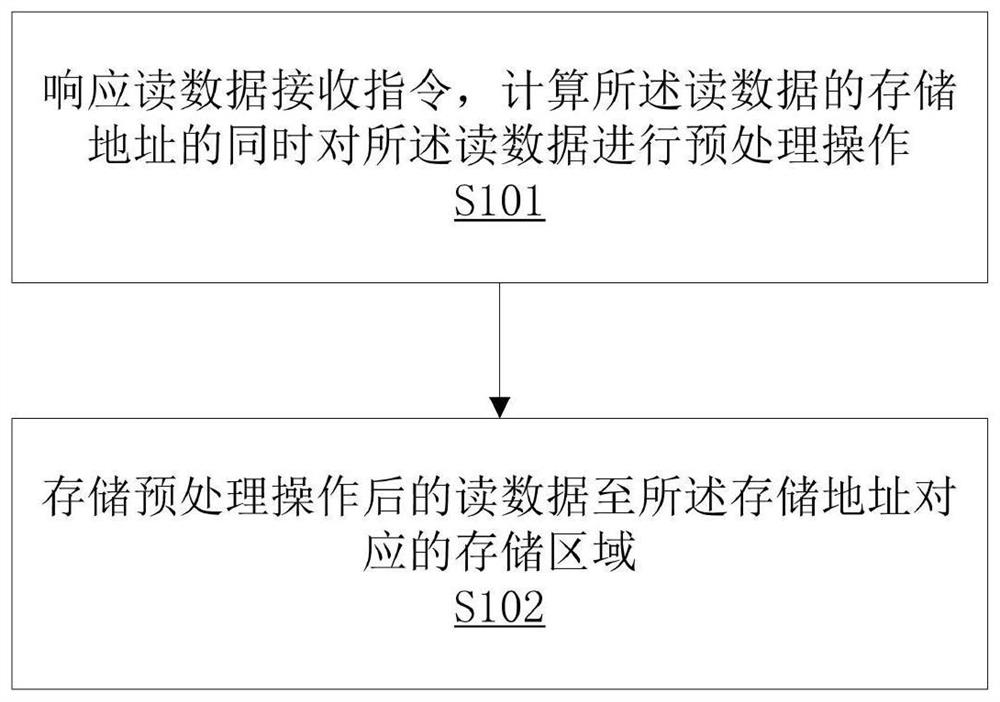
一种实现数据预处理与重排序的数据收发方法,包括步骤:
响应读数据接收指令,计算所述读数据的存储地址的同时对所述读数据进行预处理操作;
存储预处理操作后的读数据至所述存储地址对应的存储区域。
进一步的,所述“响应读数据接收指令”前,还包括步骤:
生成读请求信息、读数据和写数据的对应关系信息、和写请求信息;
将所述写请求信息写入写请求查找表、将所述读数据和写数据的对应关系信息存入读写关系查找表;
发送所述读请求信息至目标主机。
进一步的,所述“计算所述读数据的存储地址”,具体还包括步骤:
根据读数据的返回值计算得读写关系查找表的对应地址;
根据所述对应地址从写关系查找表中取得目标参数;
根据所述目标参数计算得所述读数据对应的存储地址。
进一步的,还包括步骤:
对应更新读写关系查找表和写信息查找表。
进一步的,所述预处理操作包括但不限于:合并、拆分、重组;
所述合并指将连续的多个burst的读数据合并成一个burst的写数据,所述拆分指将一个burst的读数据拆分成多个burst的写数据,所述重组指将相邻的burst的读数据在不改变beat的排列次序的情况下进行重新组合,产生新的写数据;
接收到的读数据存放于buffer中,所述buffer被划分为多个region,每个region的大小相同。
为解决上述技术问题,还提供了一种存储设备,具体技术方案如下:
一种存储设备,其中存储有指令集,所述指令集用于执行:响应读数据接收指令,计算所述读数据的存储地址的同时对所述读数据进行预处理操作;
存储预处理操作后的读数据至所述存储地址对应的存储区域。
进一步的,所述指令集还用于执行:
所述“响应读数据接收指令”前,还包括步骤:
生成读请求信息、读数据和写数据的对应关系信息、和写请求信息;
将所述写请求信息写入写请求查找表、将所述读数据和写数据的对应关系信息存入读写关系查找表;
发送所述读请求信息至目标主机。
进一步的,所述指令集还用于执行:
所述“计算所述读数据的存储地址”,具体还包括步骤:
根据读数据的返回值计算得读写关系查找表的对应地址;
根据所述对应地址从写关系查找表中取得目标参数;
根据所述目标参数计算得所述读数据对应的存储地址。
进一步的,所述指令集还用于执行:
对应更新读写关系查找表和写信息查找表。
进一步的,所述指令集还用于执行:
所述预处理操作包括但不限于:合并、拆分、重组;
所述合并指将连续的多个burst的读数据合并成一个burst的写数据,所述拆分指将一个burst的读数据拆分成多个burst的写数据,所述重组指将相邻的burst的读数据在不改变beat的排列次序的情况下进行重新组合,产生新的写数据;
接收到的读数据存放于buffer中,所述buffer被划分为多个region,每个region的大小相同。
本发明的有益效果是:一种实现数据预处理与重排序的数据收发方法,包括步骤:响应读数据接收指令,计算所述读数据的存储地址的同时对所述读数据进行预处理操作;存储预处理操作后的读数据至对应存储地址。通过该方法,将对读数据的预处理操作与读数据接收过程合并,提高了数据处理效率。
附图说明
图1为具体实施方式所述一种实现数据预处理与重排序的数据收发方法的流程图;
图2为具体实施方式所述一种实现数据预处理与重排序的数据收发方法应用的模块示意图;
图3为具体实施方式所述支持的数据预处理方式示意图;
图4为具体实施方式所述读写对应关系信息产生时序示意图;
图5为具体实施方式所述读请求接收过程示意图;
图6为具体实施方式所述存储设备的模块示意图。
附图标记说明:
600、存储设备。
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
请参阅图1至图5,在本实施方式中,一种实现数据预处理与重排序的数据收发方法可应用在如图2所示的模块结构中。以下展开具体说明:
步骤S101:响应读数据接收指令,计算所述读数据的存储地址的同时对所述读数据进行预处理操作。
步骤S102:存储预处理操作后的读数据至所述存储地址对应的存储区域。
其中所述“响应读数据接收指令”前,还包括步骤:
生成读请求信息、读数据和写数据的对应关系信息、和写请求信息;
将所述写请求信息写入写请求查找表、将所述读数据和写数据的对应关系信息存入读写关系查找表;
发送所述读请求信息至目标主机。
其中所述读请求信息包括:读请求的地址和控制信息,所述写请求信息包括:写数据的控制信息和地址信息。需要说明的是当数据的写目标是挂载在AXI总线上的其他设备时,则需要产生写数据的地址信息,而当写目标是当前设备的其它模块时,则不需要产生额外写数据的地址信息。
以下结合图2对以上展开具体说明,首先本申请的核心技术思想在于:区别于现有技术是接收完读数据并将其存储以后,才能进行数据的预处理操作,使得数据的处理效率较低,而本申请是在接收读数据的过程中就做了数据的预处理,而后把预处理后的数据对应存储起来,提高了数据的处理效率。
此外本申请还有一个创新点在于支持总线读数据的乱序和交织,提高了总线效率,对总线性能友好,以下会展开说明,现有技术通过一个buffer对乱序的读数据的进行重新排序,此外还需要一个额外的buffer进行数据的处理。而本申请将数据处理过程与读数据的接收过程合并,因而只需要一个buffer即可完成数据的重排序和预处理,以下均会展开说明。
首先如图3所示,在本申请中所述预处理操作包括但不限于:合并、拆分、重组;
所述合并指将连续的多个burst的读数据合并成一个burst的写数据,所述拆分指将一个burst的读数据拆分成多个burst的写数据,所述重组指将相邻的burst的读数据在不改变beat的排列次序的情况下进行重新组合,产生新的写数据。
其次如图2所示,本申请的方法主要是依于图2所示的结构实现,其中各个模块的具体功能如下:
读写信息产生模块完成以下功能:
1.产生读请求的地址和控制信息并发送给AXI主机。
2.产生写数据的控制和地址(若需要)信息,存入写请求查找表。
3.产生读数据和写数据的对应关系信息,存入读写关系查找表。
其中buffer用于缓存AXI总线返回的读数据。buffer被划分为多个region,每个region的大小相同,记为rgn_size。每个region存储一个burst的写数据,简化了写数据的发送过程,并且对应写请求查找表的一行。region中数据的地址和控制信息存储在写请求查找表的对应行中。
写请求查找表中的存储的控制信息包括写数据的burst长度信息wlen,以及该行所对应的buffer region待写入的写数据长度wlen_rmn(单位为beat)。wlen_rmn的初始值与wlen相等。
以上方法的工作过程分为读写信息产生和读数据接收两个阶段。
在读写信息产生阶段,读写信息产生模块产生读请求与写数据的地址和控制信息,以及读数据与写数据的对应关系信息。读写信息产生的时序如图4所示。mread为读请求信号,rid为读请求ID。rid的初始值为0,每当读请求信号有效且被AXI主机接收,rid自增1。读数据与写数据的对应关系信息包括:1.接收读数据时,读数据的第一个beat将存储在哪个region中,由rgn_addr表示;2.接收读数据时,读数据的第一个beat于所在region中的地址,由rgn_beat表示。当mread为高电平时,rgn_addr与rgn_beat被写入读写关系查找表。rel_tab_wr_addr指示读写关系查找表的写地址,wtab_wr_addr指示写信息查找表的写地址,rel_tab_wr_addr与wtab_wr_addr的复位值为0,每当查找表发生写操作,对应查找表的写地址自加1。
rgn_addr与rgn_beat的计算方式如下:
产生的读请求的总长度记为rlen_tot,产生的写请求的总长度记为wlen_tot,wlen_tot延迟一拍得到wlen_tot_ff1。
在某个时钟周期,若rlen_tot>=wlen_tot,如图4的第1、6个clk所示,则读请求信号mread置0,停止发送新的读请求,rgn_addr与rgn_beat维持不变。
若wlen_tot>rlen_tot>=wlen_tot_ff1,如图4的第2、4、5、7个clk所示,信号发生如下更新:rgn_addr=wtab_wr_addr;rgn_beat=rlen_tot-wlen_tot_ff1。
若rlen_tot 读数据返回时,通过查找表中的信息确定每个beat的读数据写入buffer的指定地址。计算所述读数据的存储地址的具体步骤如下:根据读数据的返回值计算得读写关系查找表的对应地址;根据所述对应地址从写关系查找表中取得目标参数;根据所述目标参数计算得所述读数据对应的存储地址。以下结合图5具体展开说明,图5给出了发生乱序和交织时,读数据接收的示例。 根据返回rid值获得读写关系查找表的地址rel_tab_rd_addr。 rel_tab_rd_addr=rid+rid_cnt[rid]×ID_NUM。 其中ID_NUM为系统支持的不同ID的数目。rid_cnt为一个寄存器组,每当接收完当前rid的最后一个beat的读数据,寄存器中的第rid个寄存器rid_cnt[rid]自增1。 2.根据计算出的rel_tab_rd_addr从读写关系查找表中取出rgn_addr以及rgn_beat。rgn_addr同时还是对写信息查找表的访问地址。 3.计算该beat读数据在buffer的存储地址buf_wr_addr: buf_wr_addr=rgn_addr×rgn_size+rgn_beat; 4.对应更新读写关系查找表和写信息查找表。根据rgn_addr取出写信息查找表对应地址的wlen与wlen_rmn。接收一个beat的读数据时,若rgn_beat小于wlen,则rgn_beat自加1,否则rgn_addr自加1,rgn_beat置0。同时,若该地址的wlen_rmn不为0,则将写信息查找表该行的wlen_rmn减1。若wlen_rmn为0,表示该region的数据已经全部接收完成。将该region中的数据发给目标,数据的burst长度等于wlen。 以上方法适用范围广,可移植性强,适用于任何对AXI总线有读访问需求的系统中,且写目标可以是AXI总线上的其余设备或者是该设备的其余模块。 请参阅图2至图6,在本实施方式中,一种存储设备600的具体实施方式如下: 一种存储设备600,其中存储有指令集,所述指令集用于执行:响应读数据接收指令,计算所述读数据的存储地址的同时对所述读数据进行预处理操作; 存储预处理操作后的读数据至所述存储地址对应的存储区域。 进一步的,所述指令集还用于执行: 所述“响应读数据接收指令”前,还包括步骤: 生成读请求信息、读数据和写数据的对应关系信息、和写请求信息; 将所述写请求信息写入写请求查找表、将所述读数据和写数据的对应关系信息存入读写关系查找表; 发送所述读请求信息至目标主机。 其中所述存储设备600内部可包含有如图2所示的模块。 首先如图3所示,在本申请中所述预处理操作包括但不限于:合并、拆分、重组; 所述合并指将连续的多个burst的读数据合并成一个burst的写数据,所述拆分指将一个burst的读数据拆分成多个burst的写数据,所述重组指将相邻的burst的读数据在不改变beat的排列次序的情况下进行重新组合,产生新的写数据。 如图2所示,buffer用于缓存AXI总线返回的读数据。buffer被划分为多个region,每个region的大小相同,记为rgn_size。每个region存储一个burst的写数据,简化了写数据的发送过程,并且对应写请求查找表的一行。region中数据的地址和控制信息存储在写请求查找表的对应行中。 写请求查找表中的存储的控制信息包括写数据的burst长度信息wlen,以及该行所对应的buffer region待写入的写数据长度wlen_rmn(单位为beat)。wlen_rmn的初始值与wlen相等。 以上指令集的执行工作过程分为读写信息产生和读数据接收两个阶段。 在读写信息产生阶段,读写信息产生模块产生读请求与写数据的地址和控制信息,以及读数据与写数据的对应关系信息。读写信息产生的时序如图4所示。mread为读请求信号,rid为读请求ID。rid的初始值为0,每当读请求信号有效且被AXI主机接收,rid自增1。读数据与写数据的对应关系信息包括:1.接收读数据时,读数据的第一个beat将存储在哪个region中,由rgn_addr表示;2.接收读数据时,读数据的第一个beat于所在region中的地址,由rgn_beat表示。当mread为高电平时,rgn_addr与rgn_beat被写入读写关系查找表。rel_tab_wr_addr指示读写关系查找表的写地址,wtab_wr_addr指示写信息查找表的写地址,rel_tab_wr_addr与wtab_wr_addr的复位值为0,每当查找表发生写操作,对应查找表的写地址自加1。 rgn_addr与rgn_beat的计算方式如下: 产生的读请求的总长度记为rlen_tot,产生的写请求的总长度记为wlen_tot,wlen_tot延迟一拍得到wlen_tot_ff1。 在某个时钟周期,若rlen_tot>=wlen_tot,如图4的第1、6个clk所示,则读请求信号mread置0,停止发送新的读请求,rgn_addr与rgn_beat维持不变。 若wlen_tot>rlen_tot>=wlen_tot_ff1,如图4的第2、4、5、7个clk所示,信号发生如下更新:rgn_addr=wtab_wr_addr;rgn_beat=rlen_tot-wlen_tot_ff1。 若rlen_tot 读数据返回时,通过查找表中的信息确定每个beat的读数据写入buffer的指定地址。进一步的,所述指令集还用于执行:所述“计算所述读数据的存储地址”,具体还包括步骤:根据读数据的返回值计算得读写关系查找表的对应地址;根据所述对应地址从写关系查找表中取得目标参数;根据所述目标参数计算得所述读数据对应的存储地址。 以下结合图5具体展开说明,图5给出了发生乱序和交织时,读数据接收的示例。 根据返回rid值获得读写关系查找表的地址rel_tab_rd_addr。 rel_tab_rd_addr=rid+rid_cnt[rid]×ID_NUM。 其中ID_NUM为系统支持的不同ID的数目。rid_cnt为一个寄存器组,每当接收完当前rid的最后一个beat的读数据,寄存器中的第rid个寄存器rid_cnt[rid]自增1。 2.根据计算出的rel_tab_rd_addr从读写关系查找表中取出rgn_addr以及rgn_beat。rgn_addr同时还是对写信息查找表的访问地址。 3.计算该beat读数据在buffer的存储地址buf_wr_addr: buf_wr_addr=rgn_addr×rgn_size+rgn_beat 4.对应更新读写关系查找表和写信息查找表。根据rgn_addr取出写信息查找表对应地址的wlen与wlen_rmn。接收一个beat的读数据时,若rgn_beat小于wlen,则rgn_beat自加1,否则rgn_addr自加1,rgn_beat置0。同时,若该地址的wlen_rmn不为0,则将写信息查找表该行的wlen_rmn减1。若wlen_rmn为0,表示该region的数据已经全部接收完成。将该region中的数据发给目标,数据的burst长度等于wlen。 以上存储设备600适用范围广,可移植性强,适用于任何对AXI总线有读访问需求的系统中,且写目标可以是AXI总线上的其余设备或者是该设备的其余模块。 需要说明的是,尽管在本文中已经对上述各实施例进行了描述,但并非因此限制本发明的专利保护范围。因此,基于本发明的创新理念,对本文所述实施例进行的变更和修改,或利用本发明说明书及附图内容所作的等效结构或等效流程变换,直接或间接地将以上技术方案运用在其他相关的技术领域,均包括在本发明的专利保护范围之内。
- 一种实现数据预处理与重排序的数据收发方法和存储设备
- 一种大数据预处理文本数据生成处理流程实现方法