一种基于注意力机制的目标追踪方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明属于目标追踪技术领域,更具体地,涉及一种基于注意力机制的目标追踪方法。
背景技术
视觉对象跟踪的目的是在视频序列的每一帧跟踪给定的目标对象。它是计算机视觉中的一项基础任务,具有众多的实际应用。然而,开发一个快速、准确和鲁棒的跟踪器仍然是非常具有挑战性的,因为在具有复杂背景的视频对象上经常发生大量的变形、运动和遮挡。
近年来,基于相似性比较策略开发的孪生网络引起了视觉跟踪界的极大关注。这些孪生网络跟踪器通过骨干网提取的搜索区域和目标模板之间的相互关系来学习一般的相似度图,从而形式化视觉跟踪问题。然而,由于卷积运算的固有局限性,很难学习全局和长期的语义信息交互。因此,这自然就引出了一个有趣的问题:有没有比卷积神经网络更好的特征提取方法?在原始的孪生网络跟踪器中,对象模板只在第一帧中初始化。在目标跟踪过程中,模板保持固定,视频的其余部分与不变的初始帧进行匹配。然而,当目标处于运动状态时,其外观变化往往较大,模板不变可能导致跟踪失败。
为了解决这个问题,最近的Siamese跟踪器通过使用固定学习率的运行平均值实现了一个简单的线性更新策略。此外,这种更新方法在所有维度上都是恒定的,不能进行局部更新,在遮挡的情况下会导致大量不相关的背景信息进入模板,导致跟踪失败。
综上所述,为了目标追踪的稳定性和准确性,应继续研究复杂场景变换以及长时间追踪的环境中,目标追踪问题。
发明内容
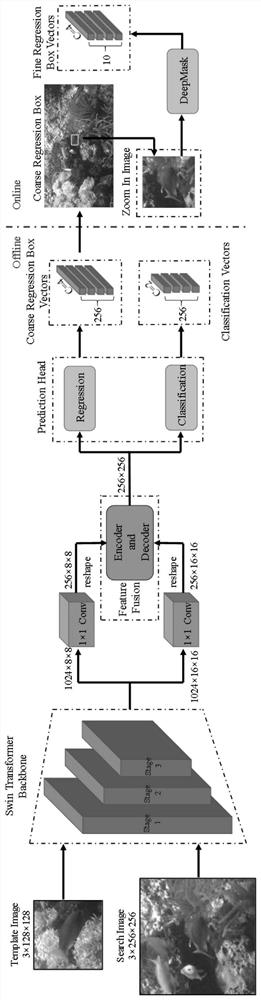
本发明的目的是提出一种基于注意力机制的目标追踪方法。针对目标追踪在实际过程中,背景复杂变换,以及长时间追踪时目标被遮挡情况,以Swin变换块代替卷积神经网络作为骨干,解决了卷积运算的固有局域性。注意力网络学习目标的运动规律,对目标的特征进行融合,对目标的位置进行预测,结合时间和空间两个方面计算目标的相似度进行目标匹配,实现目标追踪的目的。此方法可以减少目标追踪的漏检率,提升多目标追踪的准确度,并解决追踪过程中的目标遮挡问题。
为实现上述目的,按照本发明的一个方面,提供了一种基于深度学习注意力机制下的目标追踪方法,所述方法包括:
(1)获取到样本图像以及搜索区域的解码特征。
(2)将解码获得的图像数据输入到训练好的Swin Transformer Backbone目标特征提取网络模型中,得到目标的位置信息以及空间特征。
(3)将得到的追踪目标位置信息以及空间特征输入注意力特征融合模块,获取到在该时刻的目标融合特征。
(4)将目标的融合特征,和目标当前时刻实际空间特征对比,使用IoU来计算其相似度,选取综合相似度最高的作为待定匹配目标。
(5)进行在线追踪,根据待定匹配目标位置,扩大1.7倍搜索范围,利用DeepMask进行分割获得最优匹配结果,与设定阈值比较,大于阈值匹配成功,如果小则匹配失败。下面结合附图和具体实施方式对本发明作进一步详细的描述;
附图说明
图1为算法跟踪框架图;
图2为编码解码示意图;
图3为在线跟踪结构示意图;
图4为不同融合层的注意力图可视化图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明方法流程如下所示:
(1)获取到样本图像以及搜索区域的解码特征。
1)从预训练数据集上按照时间戳顺序读取,并读取解码图像;
2)对图像进行预处理操作,将图像缩放到512*512像素大小,以适应网络的大小;
(2)将解码获得的图像数据输入到训练好的Swin Transformer Backbone目标特征提取网络模型中,得到目标的位置信息以及空间特征。
Swin Transformer Backbone是一个注意力机制网络,使用Swin Transformer进行目标检测首先需要先线下训练模型参数,然后线上处理图像以得到目标的位置和空间特征
线下训练模型的过程为:标记出图像中的目标位置和目标分类,使得网络可以通过设定的标记进行反向传播确定模型参数;模型训练是一个有监督的训练过程,训练的图像样本同样使用视频中提取的图像,保证与实际使用的场景相似;模型训练是一个反复迭代的过程,通过反馈调节,使得最终模型的输出误差在一定范围内。
1)将解码获得的图像数据输入到训练好的Swin Transformer Backbone目标特征提取网络模型中,通过注意力机制块提取出搜索图像以及样本的目标特征,样本图像维度为
2)将分别得到的图像特征向量,分别通过1*1卷积层来将1024个通道维度降低到256个通道,来为特征数据融合进行数据的预处理。
(3)将得到的追踪目标位置信息以及空间特征输入注意力特征融合模块,获取到在该时刻的目标融合特征。
1)将分别预处理得到的图像特征向量输入编码器-解码器(交叉)注意的多头注意模块,两个交叉特征增强模块同时接收各自分支和另一个分支的特征映射,并通过多头交叉注意将两种特征映射融合在一起。
其中注意力机制是设计特征融合网络的基本要素。给定查询Q、键K和值V,计算方式如下:
为了使模型关注不同方面的信息,使机制考虑到不同的注意分布,将注意机制扩展到多头部,并定义了多头部注意机制,计算方式如下:
H
其中
2)编码器采用多头自我注意和残差结构,对特征图不同位置的信息进行收集和整合,注意机制无法区分输入特征序列的位置信息。因此,我们引入了一个空间位置编码过程的输入
X
其中
3)解码器采用多头交叉注意的方式,以残差的形式融合两个输入的特征向量。与编码器类似,解码器也使用空间位置编码。另外,我们使用FFN模块来增强模型的拟合能力,它是一个全连接的前馈网络,由两个线性变换组成,中间有一个ReLU,计算方式如下:
FFN(x)=max(0,xW
符号W和b分别代表权重矩阵和基向量。下标表示不同的层。因此,解码器的机制可以概括为:
其中
(4)将目标的融合特征,和目标当前时刻实际空间特征对比,使用IoU来计算其相似度,选取综合相似度最高的作为待定匹配目标。
预测器是由一个最简单和最有效的三层感知器组成。感知器包括隐藏维度d和激活函数ReLU。它包含两个分支,即分类分支和粗回归分支。骨干得到的特征图
为了保证样品之间的平衡,将负样品损失减少16倍。我们使用标准的二元交叉熵损失进行分类,计算公式为:
其中y
对于回归,我们遵循应用l
其中y
(5)进行在线追踪,根据待定匹配目标位置,扩大1.7倍搜索范围,利用DeepMask进行分割获得最优匹配结果,与设定阈值比较,大于阈值匹配成功,如果小则匹配失败。
当预测头得到粗回归包围框时,将当前帧搜索区域的粗回归包围框扩大1.7倍得到放大后的图像块,训练后的DeepMask对放大后的图像补丁进行目标分割,得到图像补丁的掩码二值图像,然后通过形态学操作选择连通域最大的掩码,并利用椭圆法来近似目标物体的姿态和椭圆的中心。该点为目标框对角线的交点,其长轴和短轴作为包围框的长度和宽度。所得到的旋转矩形框通常比真实值稍微大一些,并且只需要稍微缩放它就可以得到一个良好的回归边框。
实验测试:
我们在LaSOT和GOT10k数据集上训练模型。骨干网络Swin Tramsformer块使用swin transformer上的预处理参数初始化,其他参数使用Xavier初始化。我们在单个GPU上采用AdamW优化,将骨干学习率设置为2e-5,其他参数的学习率设置为2e-4,并将权值衰减为2e-4。每次迭代的批次大小为25个图像对。我们总共设置了120个epoch,每个epoch有1200次迭代。经过50个时代,学习速度下降了10倍。我们的方法是在Python中使用PyTorch在PC上实现的,使用Intel(R)Core(TM)i5-10400F CPU@2.90GHz 2.90GHz,16GRAM,NvidiaRTX 3060。
实验通过VOT2019数据集中的视频的结果来对比本发明使用方法与目前大部分方法中基于卷积神经网络目标追踪的效果,记A为目标追踪测试结果的准确性,记R为目标追踪种的健壮性,记EAO为目标追踪中的平均重叠率。实验结果如下表1所示。
表1在VOT2019数据集上与其他SOTA跟踪器比较结果
由于Swin Transformer块的结构,骨干网络可以分层构造。像ResNet50一样,SwinTransformer设计了一个具有明显层次的网络。底部的结构处理越来越多的本地数据。位于顶端的网络处理的数据较少,但拥有更多的语义信息。因此,受SiamRPN++的启发,我们尝试对从骨干网不同层提取的特征信息进行多层融合。
与SiamRPN++不同,我们不直接使用线性加权,而是进行自适应融合。如表2所示,3层特征融合并没有达到预期的效果,因此我们探究跟踪目标在不同层融合后的注意力图,探究图4中融合失败的原因。融合我们认为可能的原因不能改善后的效果是输入样本图像和搜索区域图像从主干中提取,获得的特征尺寸在第二阶段,第三阶段和第四阶段是32×32,16×16,8×8(搜索区域),16×16,8×8,4×4(模板区域)。分别从表2可以看出,第二和第四阶段的性能测试很差。在第二阶段,网络的浅层包含更多的简单特征,如边缘或位置,仅使用简单特征是无法跟踪的。在第四阶段,网络的深层包含更多的语义信息,但由于分辨率较低,仅利用第四层无法对其进行跟踪。在融合第二阶段和第四阶段特征后,可以发现将浅层位置信息和深层语义信息相结合,跟踪效果将优于单一的跟踪效果。在进行第2、3、4阶段的融合后,由于第4层的分辨率太小,在融合过程中会对第3层造成一些细微的影响,使得融合后的效果略差于单独的第3层,因此在发明中,我们选择第3层作为后续特征融合的输入。
表2在VOT2018数据集上不同层数融合结果对比
在本专利中,我们提出了一个简单而有效的视觉跟踪框架。通过SwinTransformer块替代原有的卷积网络骨干,我们可以从全局和远程语义信息交互中获得自我注意,并尝试探索注意力机制作为骨干的可能性。同时,增加了在线精细跟踪,大大提高了跟踪器的性能。本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种基于多层次注意力机制的单目标追踪方法
- 一种基于局部注意力机制的3D-ReID多目标追踪方法