一种多无人艇避碰决策方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于多无人艇自主决策方法,涉及无人艇技术,路径规划算法领域,避碰算法领域以及多无人艇控制方法等,具体涉及一种多无人艇避碰决策方法。
背景技术
近年来,对资源的需求促使各国加大对海洋的勘探和利用,无人驾驶技术发展为海洋勘探和利用提供了技术保障。无人艇作为新型海洋装备,在海洋资源勘探和利用方面广泛应用。对于海洋勘探开发任务,单条无人艇很难完美完成,无人艇集群可以有效地完成海洋监测、海上救援和辅助停泊等任务。无人艇是无人驾驶技术研究的新领域,海洋环境相比陆地环境更加复杂,多无人艇对海上交通工程中的海上安全和环境保护提出了挑战,因此对无人艇航行控制与航行安全提出了更高要求。在海上避碰规则(COLREGs)下保证多无人艇的海上安全航行,实现多无人艇间自主避碰具有重要战略意义。
多无人艇研究中,控制方法主要两种形式:1)集中式控制方法,在一个集中式系统中,控制器可以灵活地协调在同一工作空间中的多条无人艇,群体环境信息已知的条件下避免群体内部发生碰撞。该方法可实现较为精确的控制,但对系统要求较高,且鲁棒性较低,很难扩展到大型群体。2)分布式控制方法,允许每条船根据传感器独立做出决策,它适用于部署大量计算量相对较低的无人艇。对集群中个别无人艇运动出现错误和出现紧急故障有较强鲁棒性。但控制精度较低,响应慢,因此需要搭载较成熟的避碰算法实现海上安全航行。各大科研院所、高校和企业在船舶路径规划与避碰算法进行大量研究,取得一系列研究成果。但是大部分针对单船领域避碰路径规划,在多无人艇领域研究较少。为此需研究一种多无人艇避碰决策方法,实现多无人艇海上安全航行与安全作业。
现有技术对多无人艇控制精度较低,控制方法没有好的泛化能力。人工势场法、动态窗口法以及模型预测控制方法大多应用于单无人艇领域,在多无人艇交互方面应用较少。栅格图法忽略了无人艇运动轨迹平滑特点,速度障碍法在多无人艇领域应用较多,但在避碰过程中会发生震荡运动。深度强化学习为复杂环境中的避碰问题提供了解决方案,但是在多无人艇避碰需要进行网络调整和奖励函数调整,具有随机性。现有避碰算法大部分针对单无人艇,在多无人艇避碰中容易发生震荡运动,陷入局部最优性等问题。
发明内容
本发明的目的在于解决现有方案没有可遵循符合COLREGs的避碰和路径规划算法,不能很好实现多无人艇海上安全航行与安全作业问题,提供一种多无人艇避碰决策方法,同时考虑碰撞风险和COLREGs,通过相互速度障碍区域表示环境信息并评估环境风险,近端策略优化根据评估环境风险决策行为。使用相互速度障碍算法改进近端策略优化算法的行动空间和奖励函数,一个基于递归模块的神经网络被用来将周围不同数量障碍物的状态直接映射为行动,以解决有限信息下的避碰问题。本发明方法开发了一种新的基于相互速度障碍区域和预期碰撞时间的奖励函数,可以适应许多不同的环境并解决稀疏奖励难题。多无人艇在本发明提出的算法控制下具有避碰路径规划能力,并遵守COLREGs。
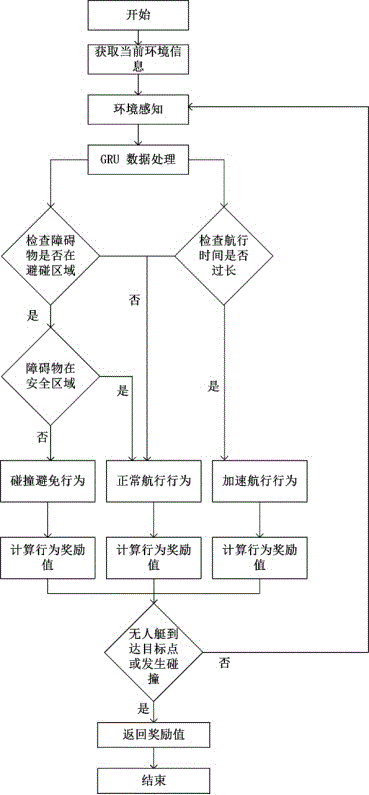
为实现上述目的,本发明的技术方案是:一种多无人艇避碰决策方法,该方法以近端策略优化算法为基础,再辅以相互速度障碍算法的扩展策略,相互速度障碍算法对近端策略优化算法中奖励函数进行改进,解决了强化学习中稀疏奖励的问题,使得网络更新速度更快,学习效率更高,改善了随机性高,学习率低的缺点,如图1所示,该方法具体步骤如下:
步骤1、构建决策模型;
步骤2、载入未知环境,训练模型;
步骤3、设计测试环境,提取当前可监测环境信息;
步骤4、环境感知;
步骤5、数据处理;
步骤6、风险评估,检查当前无人艇风险状态;
步骤7、根据步骤6,针对风险执行相应决策行为;
步骤8、根据步骤7,计算奖励值;
步骤9、判断是否实现避碰,返回奖励值与结果。
对于步骤1,近端策略优化是三网络结构,是策略梯度算法的一种变形,算法结构如图2所示,该算法首先从初始化神经网络开始,设置了两个actor网络,结构为两层,每层256个神经元。其中网络π采样,对旧网络π
对于步骤2,设计训练环境,近端策略优化算法优化目标是极大化奖励的期望,在计算期望时,采样方法选择重要性采样。重要性采样是实现用在参数为θ'网络下收集数据对θ网络更新的关键,用两个分布函数p,q来描述两条无人艇。计算期望公式如下:
理论上q(x)可以是任意分布,但在实际中p(x)和q(x)相近,从两个分布方差来看
Var
当采样数据达到1000以上时,p(x)=q(x)。
利用重要性采样方法,进行在线策略到离线策略的转换。在策略梯度中,对期望的求解
转换为
其中τ是采样轨迹,
应用到实际环境中,进行梯度更新
其中A
新优化函数
由上式得到近端策略优化定义式
其中β为权重系数,KL散度的作用是用来描述θ,θ'之间的差异性度量,差异性指参数对应的行为(actor)的差异。βKL(θ,θ')为限制条件。
相互速度障碍假设对方使用相同的策略,而非保持匀速运动,如图4所示,可使用公式(9)描述
相互速度障碍不是为其他无人艇速度障碍之外的每条无人艇选择一个新的速度,而是选择当前速度和位于其他无人艇速度障碍之外的速度的平均值,v
考虑到无人艇避碰遵循海上交通避碰规则,在执行避碰策略时,都选择右侧。让无人艇A和无人艇B在彼此的相互速度障碍之外选择新的速度v'
对于步骤2,算法训练模型的运算过程具体分为以下步骤:
步骤2.1、通过设计的未知环境,确定多无人艇当前位置以及各无人艇目标点;
步骤2.2、相互速度障碍评估当前碰撞风险,并将结果反馈给近端策略优化,网络π执行动作并更新位置状态和动作状态,得到网络参数θ';
步骤2.3、网络π
步骤2.4,θ与θ'通过KL散度进行θ'对θ的更新;
步骤2.5、相互速度障碍评估当前碰撞风险中,若检测到碰撞风险,预测障碍物下一时刻的速度状态,通过障碍物下一时刻状态改变无人艇速度大小和方向,使无人艇避开障碍物;
步骤2.6、若距离目标点越来越远,则反馈较低奖励值,调整无人艇运动方向向目标点靠近;
步骤2.7、若选定速度与期望速度相差很大,则反馈较低奖励值,调整无人艇速度向期望速度靠近;
步骤2.8、判断是否完成避碰,若完成且到达目标点,则得到基本避碰路线;
步骤2.9、若没有完成避碰行为,则返回步骤2.1,继续迭代更新直至到达目标点;
步骤2.10、训练N次,得到最优避碰路线算法训练完成,得到训练模型。
对于步骤3,设计测试环境,根据测试环境和当前无人艇位置状态,得到初步信息,用来进行下一时刻的决策。
对于步骤4,监测周围环境信息,用相互速度障碍向量表示。
对于步骤5,GRU神经网络对输入信息处理成相同维度,参见图5。
对于步骤6,每条无人艇的传感器需要设置最大检测范围,需要接收的信号除在可检测范围内他艇尺寸、当前速度、当前艏向和避碰半径。在获得局部环境的先验信息后,可以实现局部避碰路径规划。
对于步骤7,根据相互速度障碍算法评估,执行避碰行为、正常航行或加速行为。
对于步骤8,根据无人艇当前状态与目标点的距离,反馈奖励,指导无人艇下一时刻的决策行为。
对于步骤9,模型通过与环境持续交互来学习动作策略,学习效果由每个训练事件的累积奖励值表示,计算总奖励值与结果。
相较于现有技术,本发明具有以下有益效果:
本发明方法以近端策略优化算法为基础,形成与相互速度障碍算法相结合的扩展策略。该算法进行局部避碰时,相互速度障碍改进奖励函数决定决策行为,周围障碍物及其他环境信息统一由相互速度障碍向量表示,用以策略评估碰撞风险,即在可检测范围内发现障碍物,根据观测障碍物的速度信息(大小和方向)判断下一时刻障碍物的位置是否造成碰撞威胁。近端策略优化根据碰撞风险大小执行避碰行为,避碰行为规则符合COLREGs,以最优路径完成避碰安全航行任务,经加入相互速度障碍后的算法运算流程结构简图如图6所示。
本发明方法进行近端策略优化与相互速度障碍的融合,相互速度障碍用以表示环境信息和奖励函数的改进,提高了算法避碰的效率,解决了容易陷入局部最优和震荡运动的问题,提升了算法的避碰能力,且有良好的泛化能力,总体提高了多无人艇在水面避碰安全航行的效率。
附图说明
图1为多无人艇避碰决策流程图。
图2为近端策略优化算法结构图。
图3为速度障碍算法结构图
图4为相互速度障碍算法结构图。
图5为GRU数据处理流程图。
图6为基于近端策略优化融合相互速度障碍算法结构简图。
图7为双桨无人艇结构图。
图8为多无人艇相互之间避碰验证。
图9为多无人艇避碰静态障碍物验证场景。
图10为多无人艇在动态、静态障碍物场景下的验证。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
针对近端策略优化算法避碰率较低和随机性太高的缺点,以及其容易陷入局部最优解的情况,通过加入相互速度障碍改进近端策略优化算法。
无人艇集群中面临的技术难题之一是相互之间避碰,在复杂海域环境中需要一种好的决策策略保证无人艇安全航行。近端策略优化在未知环境探索中有很好的表现,响应十分迅速,但是在无人艇应用中需要考虑无人艇航行速度低,轨迹平滑等特性,引入相互速度障碍算法改进奖励函数机制,解决有限信息下的避碰问题。
通过对近端策略优化进行改进,加入相互速度障碍相结合的扩展策略,过程如下:
速度障碍的几何定义如图7所示。让
设λ(s,v)表示从s开始,沿v方向的a射线:
λ(s,v)={s+tv|t≥0}
无人艇B生成无人艇A的VO面积通过以下公式给出
表示在一定时刻内无人艇A和B会发生碰撞。
在USVs实际航行中,当每条无人艇将其他无人艇视为移动障碍物并为自己选择一个位于其他无人艇诱导的任何速度障碍物之外的速度时,这种方法会导致不希望的振荡运动。想象一下以下情况。两条无人艇A和B分别以v
然而,在新的情况下,旧的速度v
为解决上述问题,对速度障碍进行改进,用以下公式来描述:
相互速度障碍不是为其他无人艇速度障碍之外的每条无人艇选择一个新的速度,而是选择一个新的速度,即其当前速度和位于其他无人艇速度障碍之外的速度的平均值。无人艇B到无人艇A的相互速度障碍物
考虑到无人艇避碰遵循海上交通避碰规则,在执行避碰策略时,都选择右侧。让无人艇A和无人艇B在彼此的相互速度障碍之外选择新的速度v'
经改进后的算法运算流程结构简图如图6所示。其运算步骤如下:
步骤1、构建决策模型,神经网络结构均为2层,每层256个神经元。
步骤2、训练模型,决策行为本发明无人艇为双桨欠驱动无人艇,如图7所示。无人艇质心c在双桨轴线中心位置,(x
根据刚体力学只是可得双桨差速驱动无人艇的运动学方程为:
其中v为无人艇质心处的线速度,ω为无人艇的转向角速度;
假设无人艇初始位姿向量为S
其中cur表示曲率,ste={-1,0,1},ste=-1表示无人艇左转,ste=0表示无人艇直行,ste=1表示无人艇右转。r
旋转角度
δ=|ste|×l
其中l
移动距离
l
旋转矩阵
迁移矩阵
如果ω≥0.01或ω≤-0.01,下一时刻位置为
如果ω→0,则下一时刻位置为
其中
无人艇移动后双桨中心位姿变换质心坐标
步骤3、设计不同的测试环境,体现模型的泛化能力。
步骤4、周围环境信息统一用向量表示,作为模型输入进行决策。
步骤5、在航行过程中,在保证自身安全航行的同时,还要观察其他船的行为,所有的船同时学习,因此环境处于不断重塑中,无人船可检测到周围其他船数量会不断发生变化,网络学习输入数据维度会发生变化。对于变长输入序列,我们采用GRU算法处理提取有效信息,如图4所示,其中O
步骤6、对于碰撞风险评估,相互速度障碍将环境信息输入到模型,模型通过无人艇周围障碍物的位置信息和速度信息即使调整决策行为。
步骤7、本发明把避碰算法转化为圆线段碰撞检测算法,由相互速度障碍几何定义可以看出,两条无人艇避碰可以转化为质点对于圆的避碰,即把无人艇A看作质点,把无人艇A的半径R
其中
其中
插入参数方程:
P
P
最终得到关于t的二次方程:
求解方程分类讨论判断质点速度轨迹与圆的位置。
步骤8、为了解决稀疏奖励的问题,我们在每一步动作都设置奖励评价函数,靠近目标点且躲避障碍物给予正面奖励,反之给予反面奖励,目的是让其以最短时间最优路径到达目标点。对此本发明针对相对速度障碍算法设置奖励函数描述为R
其中p
步骤9、测试结束根据测试结果和反馈奖励值判断无人艇是否到达目标点。
本发明结合了近端策略优化和相互速度障碍,结合两者的优点,使多无人艇在COLREGs的基础上完美实现避碰,保证了多无人艇执行任务安全航行。
本发明中,算法融合以及运动学模型的使用更贴近实际无人艇的航行状态,多无人艇之间即可独立执行动作,又可协同配合运行,可高效实现多无人艇避碰。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。