一种基于超分辨率重构和自适应挤压激励的烟火检测方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及计算机视觉和目标检测技术领域,具体涉及一种基于超分辨率重构和自适应挤压激励的烟火检测方法。
背景技术
火灾是一种会造成巨大损失的灾害,一旦发生严重威胁到我们生命和财产安全。因此如何防治火灾一直是科学家们研究的一个重要课题,如果能尽早发现烟火并及时发出预警信号,在一定程度上可以大大降低火灾带来的损失。近些年来随着人类在计算机视觉等人工智能领域取得的飞速进展,通过计算机识别图像中的特定目标成为了可能。然而火灾中的火焰和烟雾比较特殊,其颜色和形状等视觉特征处于不断变化之中,识别烟火比识别一般的物体要更加困难。
传统的烟火检测主要有基于传感器和基于外观特征两种方式。传统的基于传感器烟火检测主要使用湿度传感器、气体传感器、温度传感器等传感器来分析相对湿度、烟雾颗粒以及环境温度等参数以判断是否发生火灾。但是这些传感器必须很靠近着火点才能发出预警,这种检测方法局限性十分明显。为了及时预警就必须将这些传感器大范围高密度地铺设,使得整个系统非常庞大,性价比低。传统的基于外观特征烟火检测主要通过颜色和温度等外观特征进行学习,并使用特定的分类器判断图像区域内是否存在烟火。但是,仅依靠烟火的颜色特征,往往会将灯光、晚霞等目标误判为烟火。因此,仅通过外观特征不能够全面地描述物体的所有属性,很难满足实际的需求。而基于深度学习学到的特征,能很好地表现出物体的外在和内在的关联特征,具有更好的表达性。
综上所述,基于深度学习的烟火检测仍然是一个具有挑战性的课题。因此,在目标检测任务中提高烟火检测的准确性和鲁棒性,成为现有技术有待解决的问题。
发明内容
为了克服现有技术的不足,本发明的目的在于提供一种基于超分辨率重构和自适应挤压激励的烟火检测方法,该方法可以解决现有技术烟火检测的准确性和鲁棒性偏低等问题,能够加快训练的收敛速度,有效检测图像中的烟火目标,在检测速度不受影响的前提下提高检测精度。
为解决上述问题,本发明所采用的技术方案如下:
一种基于超分辨率重构和自适应挤压激励的烟火检测方法,该方法包括以下步骤:
采集待检测烟火的样本图像,对采集到的样本图像进行数据扩增,对扩增后的样本中的模糊图像使用超分辨率模型进行重构;
对重构后的样本集每张图像中待检测的火信息和烟信息进行标注,得到标注后的数据集,并保存对应的类别及位置信息;
构建烟火检测网络,在其骨干网络和检测层之间添加自适应挤压激励模块,并使用标注后的数据集训练烟火检测网络;
使用Hard-Swish激活函数对烟火检测网络进行训练,以增强烟火检测网络的非线性特征提取能力;
训练烟火检测模型,根据先验框和真实框之间的偏差学习模型参数,选择训练指标最优的烟火检测模型;
将待测试的视频帧图像依次输入到最优的烟火检测模型中,若图像中存在烟火目标且置信度高于设置阈值,则以矩形框的形式被标记出来,并发出预警提示。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,筛选公开数据集和录制燃烧视频进行截图,收集包含待检测烟火的图像样本集,其中烟火样本集的类型包括室内起火、森林起火、车辆起火;时间包括白天起火和夜晚起火;烟雾颜色包括白色烟雾和黑色烟雾。数据扩增的具体方法有:旋转角度、调节亮度和对比度、增加高斯模糊和椒盐噪声,获得扩增后的烟火图像数据集。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,所述对扩增后的样本中的模糊图像使用超分辨率模型进行重构,包括:在筛选出扩增后的烟火图像数据集中的模糊图像后,使用超分辨率对抗生成超分辨率模型SRGAN进行图像重构,利用感知损失和对抗损失提高恢复图像的清晰度和保真度,得到清晰的烟火数据集;其中,超分辨率模型SRGAN由生成器网络和鉴别器网络共同组成,生成器网络包括6个残差模块,以及批归一化层和激活函数层;鉴别器网络包含8个卷积层,其中4个步长为2,并由LeakyReLU函数激活,并连接到2个全连接层上。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,使用图像标注软件labelImg标注清晰的烟火数据集中的所有烟火目标,被标注的区域作为正样本,未标注的区域作为负样本,对应的类别信息和位置信息都保存在后缀为xml的文件中。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,所述构建烟火检测网络包括:选择YOLOv5作为基线网络,采用Darknet53作为骨干网络进行特征提取,在其骨干网络和检测层之间添加自适应挤压激励模块;在网络的高层语义检测层上添加特征金字塔池化模块,将用于目标检测的特征图像与局部特征和全局特征融合;在检测层中添加一个尺度为104×104的YOLO检测头进行多尺度特征融合;在104×104和52×52的两个检测尺度上添加感受野模块,通过引入多分支卷积和空洞卷积,从而有效增大感受野。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,所述自适应挤压激励模块的具体结构为:
将输入的一个H×W×C1的特征图分为两条分支,第一条分支首先经过一个全局池化层,输出是1×1×C1,其次经过一个全连接层,输出是1×1×C/r,然后经过一个ReLU激活函数后再输入到一个全连接层中,输出是1×1×C,最后经过一个Sigmoid函数,输出是1×1×C2;第二条分支则直接输出原始的输入特征图H×W×C1,即跳跃连接;
其中,在自适应挤压激励模块中,增加有信道权值变换的相似性度量,用皮尔逊相关系数来衡量两个张量的相似性,表示为公式(1);对于小于相似阈值α的变换,采用残差结构张量加法。对于大于相似阈值α的变换,采用直接替换;
其中,x1为输入张量,x2为输出张量,f1为用于计算两个张量中通道权重的皮尔逊相关系数,α为相似阈值。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,在网络的高级语义图像检测层即特征尺度为13×13的检测通道增加特征金字塔池化模块,具体包括:特征金字塔池化模块首先将输入特征经过1×1的卷积,使信道数减半,然后由四个分支并行操作,分别是卷积核为5×5、9×9、13×13的最大池化和一个跳跃连接,即对卷积操作后的特征图采用5×5、9×9以及13×13的最大池化操作,池化步长均为1,完成上述池化步骤后的特征图再与1×1卷积后的特征图完成进一步的通道合并操作;
将4条支路的输出在通道维度上进行拼接,得到一个新的用于目标检测的特征图像与局部特征和全局特征融合的特征图。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,所述在检测层中添加一个尺度为104×104的YOLO检测头进行多尺度特征融合,包括:
采用骨干网络Darknet53经过下采样得到尺度分别为13×13、26×26、52×52的三种特征图,再经过特征金字塔网络融合这三种检测尺度的特征图;
在三种检测尺度的基础上增加一个尺度为104×104的特征图,即特征图的尺度变为13×13、26×26、52×52、104×104,即使用52×52的特征图首先经过1×1的卷积核运算,对其上采样之后输出尺度变为104×104,最后通过通道拼接与新增加的特征融合,有效利用深层的高语义信息和浅层的高分辨率信息。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,在两个低检测尺度即104×104和52×52的特征图上加入由多分支卷积和空洞卷积组成的感受野模块,其中,感受野模块将不同卷积核尺寸的卷积层形成多个不同的分支,另外引入3个卷积核的大小均为3×3,卷积扩张率分别为1,3,5的空洞卷积;
感受野模块的具体结构为:输入特征图分为四个分支,第一个分支经过1×1的卷积和尺寸为3×3,卷积扩张率为1的空洞卷积;第二个分支经过1×1的卷积、3×3的卷积和尺寸为3×3,卷积扩张率为3的空洞卷积;第三个分支经过1×1的卷积、5×5的卷积和尺寸为3×3,卷积扩张率为5的空洞卷积;前三个分支的输出特征图通道合并,再经过1×1的卷积;第四个分支直接跳跃连接,所有分支的输出特征图相加后用ReLU函数激活。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,所述使用Hard-Swish激活函数对烟火检测网络进行训练,包括:
使用分段线性函数HardSigmoid拟合Sigmoid激活函数,减少由于指数造成的高计算成本,具体表示为公式(2):
其中,x是激活函数的输入;
使用Hard-Swish激活函数,具体表示为公式(3):
其中,x是激活函数的输入。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,使用非极大值抑制算法soft-NMS完成烟火检测网络的后续处理,过滤无效重叠的检测框,其具体包括:将检测框按得分排序,保留得分最高的框,通过权重来降低检测框原有的置信度;对于有重叠的框,重叠区域越大,置信度衰减越严重,最终判断检测框是否应该保留;
将扩增、重构、标注后的数据集送入到烟火检测网络中进行训练,训练过程利用梯度下降法学习模型参数,当损失函数收敛,始终保持在某个值上下浮动,训练完成,此时得到最优的烟火检测模型包括网络结构和权重文件。
根据本发明提供的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,所述将待测试的视频帧图像依次输入到最优的烟火检测模型,包括:
将待测试的视频帧图像逐帧依次输入到训练好的烟火检测模型中,图像中的烟火目标会以矩形框的形式被标记出来;
若图像中存在疑似烟火目标,则根据模型计算得到的置信度与设置的阈值进行比较;
若置信度大于设置阈值,则认为该帧图像中存在烟火目标,系统及时发出预警报告;反之继续检测下一帧图像。
由此可见,相对于现有技术,本发明的有益效果如下:
本发明公开一种具有基于超分辨率重构和自适应挤压激励的烟火检测方法,首先,使用超分辨率模型SRGAN对质量不高的模糊图片进行重构,重构得到的超分辨率图像在取较大的放大因子时仍然可以有效捕捉纹理信息,提高数据集的清晰度;其次,搭建烟火检测网络,采用YOLOv5作为基线网络,并且引入自适应挤压激励模块、特征金字塔池化(SPP)模块和感受野(RFB)模块,可以提高模型的稳定性、丰富特征图像的表达能力和增强特征图像的接收域;然后,采用Hard-Swish激活函数,增强网络的非线性特征提取能力;最后,使用soft-NMS后处理方法,过滤无效重叠的检测框。
因此,与现有的YOLOv5算法相比,本发明加快了模型在训练过程中的收敛速度,在保证检测速度的前提下,可以有效提高多种复杂场景下的烟火检测准确率,对维护人民的生命和财产安全有非常重要的意义。
下面结合附图和具体实施方式对本发明作进一步详细说明。
附图说明
图1是本发明一种基于超分辨率重构和自适应挤压激励的烟火检测方法实施例的流程图。
图2是本发明一种基于超分辨率重构和自适应挤压激励的烟火检测方法实施例的网络结构示意图。
图3是本发明一种基于超分辨率重构和自适应挤压激励的烟火检测方法实施例中所实现烟火检测算法的整体流程框图。
图4是本发明一种基于超分辨率重构和自适应挤压激励的烟火检测方法实施例中关于超分辨率对抗生成网络SRGAN模块的结构示意图。
图5是本发明一种基于超分辨率重构和自适应挤压激励的烟火检测方法实施例中关于自适应挤压激励SASE模块的结构示意图。
图6是本发明一种基于超分辨率重构和自适应挤压激励的烟火检测方法实施例中关于特征金字塔池化SPP模块的结构示意图。
图7是本发明一种基于超分辨率重构和自适应挤压激励的烟火检测方法实施例中关于感受野RFB模块的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
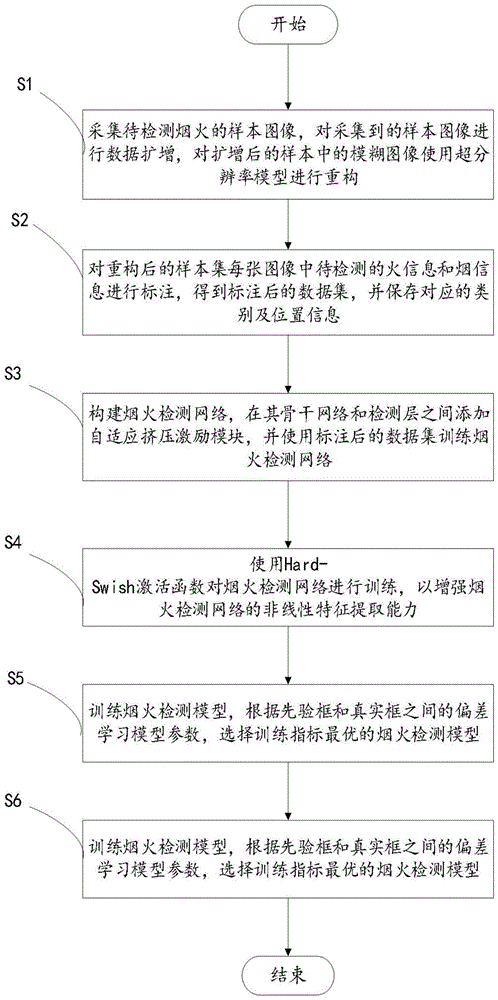
参见图1与图2,本发明提供一种基于超分辨率重构和自适应挤压激励的烟火检测方法,其包括以下步骤:
步骤S1,采集待检测烟火的样本图像,对采集到的样本图像进行数据扩增,对扩增后的样本中的模糊图像使用超分辨率模型进行重构;
步骤S2,对重构后的样本集每张图像中待检测的火信息和烟信息进行标注,得到标注后的数据集,并保存对应的类别及位置信息;
步骤S3,构建烟火检测网络,在其骨干网络和检测层之间添加自适应挤压激励模块,并使用标注后的数据集训练烟火检测网络;
步骤S4,使用Hard-Swish激活函数对烟火检测网络进行训练,以增强烟火检测网络的非线性特征提取能力;
步骤S5,训练烟火检测模型,根据先验框和真实框之间的偏差学习模型参数,选择训练指标最优的烟火检测模型;
步骤S6,将待测试的视频帧图像依次输入到最优的烟火检测模型中,若图像中存在烟火目标且置信度高于设置阈值,则以矩形框的形式被标记出来,并发出预警提示。
在上述步骤S1中,筛选公开数据集和录制燃烧视频进行截图,收集包含待检测烟火的图像样本集,其中烟火样本集的类型包括室内起火、森林起火、车辆起火;时间包括白天起火和夜晚起火;烟雾颜色包括白色烟雾和黑色烟雾。数据扩增的具体方法有:旋转角度、调节亮度和对比度、增加高斯模糊和椒盐噪声,获得扩增后的烟火图像数据集。
在上述步骤S1中,对扩增后的样本中的模糊图像使用超分辨率模型进行重构,包括:在筛选出扩增后的烟火图像数据集中的模糊图像后,使用超分辨率对抗生成超分辨率模型SRGAN进行图像重构,利用感知损失和对抗损失提高恢复图像的清晰度和保真度,得到清晰的烟火数据集;其中,超分辨率模型SRGAN由生成器网络和鉴别器网络共同组成,生成器网络包括6个残差模块,以及批归一化层和激活函数层;鉴别器网络包含8个卷积层,其中4个步长为2,并由Leaky ReLU函数激活,并连接到2个全连接层上。
在上述步骤S2中,使用图像标注软件labelImg标注清晰的烟火数据集中的所有烟火目标,被标注的区域作为正样本,未标注的区域作为负样本,对应的类别信息和位置信息都保存在后缀为xml的文件中。
在上述步骤S3中,构建烟火检测网络包括:选择YOLOv5作为基线网络,采用Darknet53作为骨干网络进行特征提取,在其骨干网络和检测层之间添加自适应挤压激励模块;在网络的高层语义检测层上添加特征金字塔池化模块,将用于目标检测的特征图像与局部特征和全局特征融合;在检测层中添加一个尺度为104×104的YOLO检测头进行多尺度特征融合;在104×104和52×52的两个检测尺度上添加感受野模块,通过引入多分支卷积和空洞卷积,从而有效增大感受野。
具体的,自适应挤压激励模块的具体结构为:
将输入的一个H×W×C1的特征图分为两条分支,第一条分支首先经过一个全局池化层,输出是1×1×C1,其次经过一个全连接层,输出是1×1×C/r,然后经过一个ReLU激活函数后再输入到一个全连接层中,输出是1×1×C,最后经过一个Sigmoid函数,输出是1×1×C2;第二条分支则直接输出原始的输入特征图H×W×C1,即跳跃连接。
其中,在自适应挤压激励模块中,增加有信道权值变换的相似性度量,用皮尔逊相关系数来衡量两个张量的相似性,表示为公式(1);对于小于相似阈值α的变换,采用残差结构张量加法。对于大于相似阈值α的变换,采用直接替换;
其中,x1为输入张量,x2为输出张量,f1为用于计算两个张量中通道权重的皮尔逊相关系数,α为相似阈值。
在本实施例中,在网络的高级语义图像检测层即特征尺度为13×13的检测通道增加特征金字塔池化模块,具体包括:特征金字塔池化模块首先将输入特征经过1×1的卷积,使信道数减半,然后由四个分支并行操作,分别是卷积核为5×5、9×9、13×13的最大池化和一个跳跃连接,即对卷积操作后的特征图采用5×5、9×9以及13×13的最大池化操作,池化步长均为1,完成上述池化步骤后的特征图再与1×1卷积后的特征图完成进一步的通道合并操作;
将4条支路的输出在通道维度上进行拼接,得到一个新的用于目标检测的特征图像与局部特征和全局特征融合的特征图。
在本实施例中,在检测层中添加一个尺度为104×104的YOLO检测头进行多尺度特征融合,包括:
采用骨干网络Darknet53经过下采样得到尺度分别为13×13、26×26、52×52的三种特征图,再经过特征金字塔网络融合这三种检测尺度的特征图;
在三种检测尺度的基础上增加一个尺度为104×104的特征图,即特征图的尺度变为13×13、26×26、52×52、104×104,即使用52×52的特征图首先经过1×1的卷积核运算,对其上采样之后输出尺度变为104×104,最后通过通道拼接与新增加的特征融合,有效利用深层的高语义信息和浅层的高分辨率信息。
在本实施例中,在两个低检测尺度即104×104和52×52的特征图上加入由多分支卷积和空洞卷积组成的感受野模块,其中,感受野模块将不同卷积核尺寸的卷积层形成多个不同的分支,另外引入3个卷积核的大小均为3×3,卷积扩张率分别为1,3,5的空洞卷积;
其中,感受野模块的具体结构为:输入特征图分为四个分支,第一个分支经过1×1的卷积和尺寸为3×3,卷积扩张率为1的空洞卷积;第二个分支经过1×1的卷积、3×3的卷积和尺寸为3×3,卷积扩张率为3的空洞卷积;第三个分支经过1×1的卷积、5×5的卷积和尺寸为3×3,卷积扩张率为5的空洞卷积;前三个分支的输出特征图通道合并,再经过1×1的卷积;第四个分支直接跳跃连接,所有分支的输出特征图相加后用ReLU函数激活。
在上述步骤S4中,使用Hard-Swish激活函数对烟火检测网络进行训练,包括:
使用分段线性函数HardSigmoid拟合Sigmoid激活函数,减少由于指数造成的高计算成本,具体表示为公式(2):
其中,x是激活函数的输入;
使用Hard-Swish激活函数,具体表示为公式(3):
其中,x是激活函数的输入。
然后,使用非极大值抑制算法soft-NMS完成烟火检测网络的后续处理,过滤无效重叠的检测框,其具体包括:将检测框按得分排序,保留得分最高的框,通过权重来降低检测框原有的置信度;对于有重叠的框,重叠区域越大,置信度衰减越严重,最终判断检测框是否应该保留;
将扩增、重构、标注后的数据集送入到烟火检测网络中进行训练,训练过程利用梯度下降法学习模型参数,当损失函数收敛,始终保持在某个值上下浮动,训练完成,此时得到最优的烟火检测模型包括网络结构和权重文件。
在上述步骤S6中,将待测试的视频帧图像依次输入到最优的烟火检测模型,包括:
将待测试的视频帧图像逐帧依次输入到训练好的烟火检测模型中,图像中的烟火目标会以矩形框的形式被标记出来;
若图像中存在疑似烟火目标,则根据模型计算得到的置信度与设置的阈值进行比较;
若置信度大于设置阈值,则认为该帧图像中存在烟火目标,系统及时发出预警报告;反之继续检测下一帧图像。
在实际应用中,如图3所示,本发明的一种基于超分辨率重构和自适应挤压激励的烟火检测方法,该方法流程分为数据准备、网络设计和模型检测三部分,具体步骤描述如下:
一、数据准备:
对收集到的烟火样本图像进行数据扩增,对扩增后的样本中的模糊图像使用超分辨率模型SRGAN进行重构,再将重构后的样本集中每张图像待检测的火和烟进行标注,分别标注为fire和smoke两种标签,得到标注后的数据集;
筛选公开数据集和录制燃烧视频进行截图,收集包含待检测烟火的图像样本集,其中烟火样本集的类型包括室内起火、森林起火、车辆起火;时间包括白天起火和夜晚起火;烟雾颜色包括白色烟雾和黑色烟雾。数据扩增的具体方法有:旋转角度、调节亮度和对比度、增加高斯模糊和椒盐噪声,获得扩增后的烟火图像数据集;
筛选出扩增后的烟火图像数据集中的模糊图像,使用超分辨率对抗生成网络SRGAN进行图像重构,利用感知损失和对抗损失提高恢复图像的清晰度和保真度,得到清晰的烟火数据集。如图4所示,SRGAN由生成器网络和鉴别器网络共同组成,生成器网络包括6个残差模块,以及批归一化(BN)层和激活函数层。鉴别器网络包含8个卷积层,其中4个步长为2,并由Leaky ReLU函数激活,最终连接到2个全连接层上。
使用图像标注软件labelImg标注清晰的烟火数据集中的所有烟火目标,被标注的区域作为正样本,未标注的区域作为负样本,对应的类别信息和位置信息都保存在后缀为xml的文件中。
二、网络设计:
构建烟火检测网络,使用标注后的数据集训练烟火检测网络,使用Hard-Swish激活函数训练,增强网络的非线性特征提取能力。根据梯度下降法学习和调整模型的参数,得到训练指标最佳的检测模型。
其中,烟火检测网络包括:选择YOLOv5作为基线网络,在其骨干网络之后、检测层之前添加自适应挤压激励(SASE)模块,提高网络的通道集中度,使网络训练更加稳定;在网络的高层语义检测层上添加特征金字塔池化(SPP)模块,将用于目标检测的特征图像与局部特征和全局特征融合,丰富特征图像的表达能力;在检测层中添加一个尺度为104×104的YOLO检测头进行多尺度特征融合,使检测层对应的像素值更多;在104×104和52×52的两个检测尺度上添加感受野(RFB)模块,通过引入多分支卷积和空洞卷积,可以有效地增大感受野。
其中,选择YOLOv5作为初始的基线网络,采用Darknet53作为骨干网络进行特征提取,经过五次下采样得到三种不同尺度用于训练的特征图像,有利于进一步增强特征提取能力。在骨干网络之后、检测网络之前添加SASE模块,如图5所示,SASE模块的具体结构为:输入一个H×W×C1的特征图分为两条分支,第一条分支首先经过一个全局池化层(Globalpooling),输出是1×1×C1,其次经过一个全连接层(FC),输出是1×1×C/r,然后经过一个ReLU激活函数后再输入到一个全连接层中,输出是1×1×C,最后经过一个Sigmoid函数,输出是1×1×C2;第二条分支则是直接输出原始的输入特征图H×W×C1,即跳跃连接。在SASE模块中,增加了信道权值变换的相似性度量。用皮尔逊相关系数来衡量两个张量的相似性,如公式(1)。对于小于相似阈值α的变换,采用残差结构张量加法。对于大于相似阈值α的变换,采用直接替换。
为了进一步提高网络表达特征的能力,在网络的高级语义图像检测层即特征尺度为13×13的检测通道增加SPP模块。如图6所示,SPP模块首先将输入特征经过1×1的卷积,使信道数减半,然后由四个分支并行操作,分别是卷积核为5×5、9×9、13×13的最大池化和一个跳跃连接,即对卷积操作后的特征图采用5×5、9×9以及13×13的最大池化操作,池化步长均为1,完成上述池化步骤后的特征图再与1×1卷积后的特征图完成进一步的通道合并操作。将4条支路的输出在通道维度上进行拼接,得到一个新的特征图。SPP模块将用于目标检测的特征图像与局部特征和全局特征融合,丰富了特征图像的表达能力。
骨干网络Darknet53经过五次下采样得到尺度分别为13×13、26×26、52×52的三种特征图,再经过特征金字塔网络(FPN)融合这三种尺度的特征图,增强模型检测不同大小目标的能力。本发明在原有三种检测尺度的基础上增加一个尺度为104×104的特征图,增强模型适应更大差异目标的能力,即特征图的尺度变为13×13、26×26、52×52、104×104。52×52的特征图首先经过1×1的卷积核运算,再对其上采样之后输出尺度变为104×104,最后通过通道拼接与新增加的特征融合,有效利用深层的高语义信息和浅层的高分辨率信息。
在两个低检测尺度即104×104和52×52的特征图上加入由多分支卷积和空洞卷积组成的感受野(RFB)模块,通过模拟人类视觉的感受野来加强网络的特征提取能力。感受野模块将不同卷积核尺寸的卷积层形成多个不同的分支,另外引入3个卷积核的大小均为3×3,卷积扩张率(dilation rate)分别为1,3,5的空洞卷积。如图7所示,感受野模块的具体结构为:输入特征图分为四个分支,第一个分支经过1×1的卷积和尺寸为3×3,卷积扩张率为1的空洞卷积;第二个分支经过1×1的卷积、3×3的卷积和尺寸为3×3,卷积扩张率为3的空洞卷积;第三个分支经过1×1的卷积、5×5的卷积和尺寸为3×3,卷积扩张率为5的空洞卷积;前三个分支的输出特征图通道合并,再经过1×1的卷积;第四个分支直接跳跃连接(shortcut),所有分支的输出特征图相加后用ReLU函数激活。
本实施例采用Hard-Swish激活函数,可以增强网络的非线性特征提取能力。首先可以用分段线性函数HardSigmoid拟合Sigmoid激活函数,减少由于指数造成的高计算成本,具体为公式(2)。
本发明在此基础上改用Hard-Swish激活函数,分段函数可以减少内存访问的数量,大幅减低延迟成本,因此可以提高在移动设备上计算性能。具体公式为公式(3)。
在本实施例中,本发明使用更加有效的非极大值抑制算法soft-NMS完成烟火检测的后处理,过滤无效重叠的检测框。烟火检测中会生成若干个烟火候选区域,尤其是在真实目标附近会有很多高置信度的检测框。通常的做法是采用NMS算法,将检测框按得分排序,然后保留得分最高的框,同时删除与该框重叠面积大于一定比例的其它框。如果两个检测框重叠面积很大,分数较低的检测框会被删除,从而导致该物体没有被检测出来,降低模型的平均准确率。另一方面,NMS的阈值难以确定,设置过小会增加漏检,设置过高会增加误检。因此本发明使用soft-NMS代替NMS算法,不直接删除所有IOU大于阈值的框,而是通过权重来降低检测框原有的置信度,对于有重叠的框,重叠区域越大,置信度衰减越严重。
然后,将扩增、重构、标注后的数据集送入到烟火检测网络中进行训练,训练过程利用梯度下降法学习模型参数,当损失函数收敛,始终保持在某个值上下浮动,训练完成,此时得到最佳的烟火检测模型包括网络结构和权重文件。
训练过程中的设备相关配置、参数设置为:
操作系统:ubuntu16.04,运行环境:python3.8+pytorch1.3.1,GPU:NVIDIAGeForce GTX 1080Ti,GPU加速库:CUDA10.0+CUDNN7.4.1;
输入网络的图像尺寸:416×416,初始学习率:0.001,学习率调整方式为指数衰减,每个动量参数:0.9,权重衰减正则项:0.0005,训练轮次:2000。
三、模型检测:
将待测试的视频帧图像逐帧依次输入到训练好的烟火检测模型中,图像中的烟火目标会以矩形框的形式被标记出来;
若图像中存在疑似烟火目标,则根据模型计算得到的置信度与设置的阈值进行比较。若置信度大于设置的阈值,则认为该帧图像中存在烟火目标,系统及时发出预警报告;反之继续检测下一帧图像。
相对于现有技术,本发明公开一种具有基于超分辨率重构和自适应挤压激励的烟火检测方法,首先,使用超分辨率模型SRGAN对质量不高的模糊图片进行重构,重构得到的超分辨率图像在取较大的放大因子时仍然可以有效捕捉纹理信息,提高数据集的清晰度;其次,搭建烟火检测网络,采用YOLOv5作为基线网络,并且引入自适应挤压激励模块、特征金字塔池化(SPP)模块和感受野(RFB)模块,可以提高模型的稳定性、丰富特征图像的表达能力和增强特征图像的接收域;然后,采用Hard-Swish激活函数,增强网络的非线性特征提取能力;最后,使用soft-NMS后处理方法,过滤无效重叠的检测框。
因此,与现有的YOLOv5算法相比,本发明加快了模型在训练过程中的收敛速度,在保证检测速度的前提下,可以有效提高多种复杂场景下的烟火检测准确率,对维护人民的生命和财产安全有非常重要的意义。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
上述实施方式仅为本发明的优选实施方式,不能以此来限定本发明保护的范围,本领域的技术人员在本发明的基础上所做的任何非实质性的变化及替换均属于本发明所要求保护的范围。