一种基于Transformer的烟雾检测算法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及一种基于Transformer的烟雾检测算法,属于图像识别领域。
背景技术
火灾是发生频率非常高的自然灾害之一,给社会和人民安全造成了非常严重的损害,研究快速有效的火灾检测方法具有非常重大的现实意义。由于烟雾的可观察性更强,提前检测火灾初起时的稀薄烟雾,可达到及时预警减少火灾发生的可能性。因此,基于烟雾的火灾检测方法是该领域的主要研究内容。
从人工智能的角度来说,基于视频的烟雾检测方法可以划分为两个分支,一类是基于传统机器学习的烟雾识别方法,另一类是基于深度学习的烟雾识别方法。前者需要人为提取烟雾特征,步骤繁琐且难以保证样本选择的准确性和全局性;后者通过神经网络自主学习烟雾特征,例如CNN、DBN、RNN等,虽能够学习到更高泛化能力与更深层次的表征模型,也通过自主学习加快处理速度,但烟雾识别准确率仍有待提高。且由于人工设计烟雾的表征能力有限,传统方法检测烟雾的效果并不理想。
发明内容
本发明的目的是提供一种基于Transformer的烟雾检测算法,用来提升现有烟雾识别算法的准确率,保证烟雾识别的实时性。
本发明提供的基于Transformer的烟雾检测算法,该方法包括以下步骤:
1)获取视频数据,从视频数据中识别出运动区域,将该运动区域作为烟雾潜在区;
2)从视频数据中抽取连续N帧烟雾潜在区域的图像,对每一帧烟雾潜在区域的图像进行分块处理,将分块处理后的连续N帧图像作为输入数据;
3)将得到的输入数据输入到已训练的Transformer模型中进行检测;
所述的Transformer模型包括有Transformer编码器和平展图斑的线性投影模块,平展图斑的线性投影模块用于对输入到N帧图像进行规范化处理,将输入的图片数据转换成向量数据;所述的Transformer编码器用于对输入的向量数据进行相似性计算;
所述Transformer模型利用训练集训练,所述训练集是由烟雾图像和非烟雾图像构成,训练时,在Transformer编码器中增加一个用于指示图像位置关系的分类向量。
本发明提供了一种基于Transformer的烟雾检测算法,通过获取的连续多帧分块图片展平成的一维向量组和额外新增的一个分类向量,并引入图片位置信息,输入Transformer编码器进行训练,最终输出分类结果。本发明考虑到视频图像的连续性,根据烟雾随时间的变化,通过连续多帧图像的处理,可以对视频数据进行准确的烟雾识别,满足了烟雾识别的实时性,该模型采用了并行化处理的方式,使得训练速度加快同时其还可以捕获全局信息,提高了识别的准确率。
进一步地,所述步骤1)采用动态背景建模的方式从视频数据中识别出运动区域。
进一步地,所述Transformer编码器包括:用于归一化处理的Norm模块、用于建立向量之间特征关系的Multi-Head Attention模块和用于计算特征相似性的MLP模块。
进一步地,所述步骤2)中,选取的连续N帧图像个数为8个。
进一步地,所述步骤2)中,将每一帧烟雾潜在区域分成24×24的图像块。
进一步地,Transformer模型采用Softmax作为分类输出层预测结果在各个类别的概率分布。
进一步地,Transformer模型训练时采用的带权重的交叉熵的损失函数为:
其中,p
附图说明
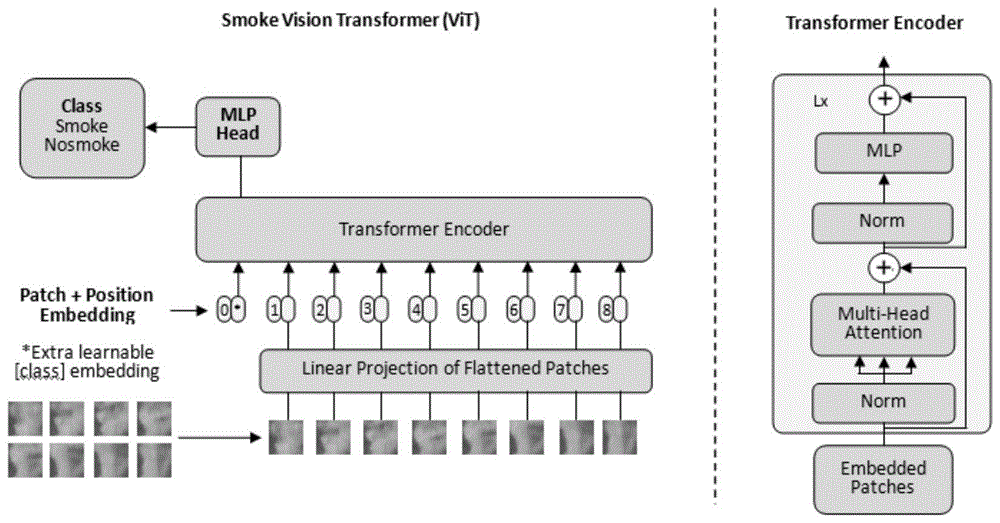
图1是本发明基于Transformer的烟雾检测原理;
图2是本发明烟雾模型推理图;
图3是本发明仿真实验的模型训练过程中Loss曲线;
图4是本发明仿真实验的烟雾视频检测效果图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步地说明。
本发明提供一种基于Transformer的烟雾检测算法,主要是先在VisionTransformer模型下进行烟雾与非烟雾类别训练,再采用Softmax输出分类结果,实现在动态背景下时序烟雾的判定,其烟雾判定流程如图2所示。本发明能够准确识别烟雾,达到烟雾预警的目的,主要步骤如下:首先,获取视频数据,从视频数据中识别出运动区域,将该运动区域作为烟雾潜在区;其次,从视频数据中抽取连续N帧烟雾潜在区域的图像,对每一帧烟雾潜在区域的图像进行分块处理,将分块处理后的连续N帧图像作为输入数据;最后,将得到输入数据输入到已训练的Transformer模型中进行检测。
其中,如图1左图所示,Transformer模型包括有Transformer编码器和平展图斑的线性投影模块,平展图斑的线性投影模块用于对输入到N帧图像进行规范化处理,将输入的图片数据转换成向量数据;Transformer编码器用于对输入的向量数据进行相似性计算,如图1右图所示,该编码器主要包括了用于归一化处理的Norm模块、用于建立向量之间特征关系的Multi-Head Attention模块和用于计算特征相似性的MLP模块。
其中,Transformer模型利用训练集训练,该训练集是由烟雾图像和非烟雾图像构成,训练时,在Transformer编码器中增加一个用于指示图像位置关系的分类向量。
1.视频图像处理
获取视频数据,利用传统运动信息,通过动态背景建模找出视频中的运动区域,将该运动区域作为烟雾潜在区域。
2.时序图像处理
从视频数据中抽取连续8帧烟雾潜在区域的图像作为要分析的数据,将每一帧烟雾潜在区域的图像进行分块处理,将其分割成24×24的图像块,可以得到一个8×24×24的数据结构作为输入数据;其中,每张图片均为3通道图片,则每张图片的数据结构为24×24×3。作为其他实施方式,连续图像帧数和图像分块大小可以根据实际情况确定。
3.Transformer模型检测
将得到的输入数据输入已训练的Tranformer模型中进行检测,过程如下:
1)输入连续8帧烟雾潜在区域24×24的图像块;
2)通过平展图斑的线性投影模块对输入的连续8帧烟雾潜在区域24×24的图像块进行规范化处理,将这连续8帧图像分割后的每个图像块通过线性投影处理全部展平成一维向量,得到8个一维向量组作为下一步向量输入数据;
3)新增一个用于分类的向量,因为Transformer模型值用到了Encoder编码器结构,没有解码的过程,在分类过程中,如果使用任意一个已经得到的向量组数据对8个输入向量进行分类,则无法保证分类时的公平性及准确性,所以需要额外新增一个用于分类的向量;该新增向量同样作为一个可学习的变量,与8个输入向量进行拼接,此时共得到9个向量;并对这9个向量引入位置信息,因为将图像展平成向量进行学习训练过程中会改变图像信息中的位置关系,通过增加位置信息,可以很好地保留图片信息之间的绝对位置关系或相对位置关系,此时得到9个包含位置信息的向量;
4)将得到的9个向量输入Transformer编码器中,首先通过Norm模块对每个向量数据进行归一化处理,保证向量之间的稳定性;其次通过Multi-Head Attention模块进行向量特征提取,该模块可以捕获不同位置信息,同时可通过增加Head数目提高模型长距离捕获能力;随后再一次使用Norm模块对Multi-Head Attention模块处理后数据进行归一化处理;最后通过MLP模块计算处理后特征向量之间的相似性;
5)采用Softmax作为分类输出层预测结果在各个类别的概率分布,得到烟雾类别和非烟雾类别结果;
其中,使用带权重的交叉熵计算损失函数实现分类,损失函数公式如下:
式中,p
为了进一步验证本发明的准确性,通过在自建的序列图片数据集上进行实验,总计59174组序列图片,包括烟雾序列和非烟雾序列。其中随机划分54174组序列图片用来训练,5000组序列图片用来评估和测试,烟雾Transformer识别模型训练过程中损失如图3所示,另外还通过3D-CNN、3D-ResNet和本发明算法进行对比实验,测试本发明算法的准确性和其他性能。
通过训练之前随机划分好的5000组序列图片进行评估和测试,最终得到的准确率和召回率如表1所示,可以明显看出经过训练后的烟雾Transformer模型具有较高的准确率和召回率。
表1
同时,在图片输入尺寸为320×320时,本发明推理测试最终结果如图4所示,其中,矩形框是背景建模得到的潜在运动区域,圆圈是烟雾识别Transformer模型判定为烟雾的区域。通过实验得到,检测一张烟雾图片的所用时间约为11毫秒,fps约为91。实验结果证明,本发明算法烟雾识别速度较快,准确率较高,推理速度也达到实时,具有较高的应用价值。