单阶段单目3D目标检测网络
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及自动驾驶方法技术领域,尤其涉及一种域自适应的深度语义感知单阶段单目3D目标检测网络。
背景技术
基于视觉的目标检测是自动驾驶系统的重要支柱,其主要任务是对目标类别进行检测和分类,并估计其位置和方向,以感知出行环境。目前,三维物体检测的发展在检测精度方面取得了很好的成绩,但大多数方法在检测网络训练中严重依赖昂贵的3D标签数据集来提供准确的目标信息,而手工制作3D标签数据集缺乏高精度传感器,且成本高、标签精度差。
但是单目相机提供了相对划算和容易安装的解决方案。大多数单眼3D目标检测算法都是根据学习到的大量2D建议,附加一个额外的网络分支来学习3D信息。虽然在过去的5年中,这个想法已经取得了很好的实证成功。一方面在3D探测器的训练过程中,由于需要在2D建议书中列举所有可能的物体位置和大小,这就带来了持续的噪声和额外的计算成本。另一方面,CenterNet先驱者直接从图像平面学习3D目标对象信息,避免了使用局部2D建议的方法不可避免的不必要的计算成本。然而,这些方法的训练成本仍然很高,需要人工标记目标3D包围框的单眼图像。
UDA(无监督域适应)技术旨在从源监督的目标样本上训练一个性能良好的模型(成本低)。其中源样本和目标样本分别为计算机合成的虚拟数据集和真实场景数据集。最近,Wang等人提出了一种弱监督对抗域自适应算法,以提高从合成数据到真实场景的分割性能。然后,应用域因子和偏置权学习域移位,最大限度地减少了域分类损失,以较低的成本学习了真实单眼图像的高成本空间和位置信息。因此,在单目UDA框架上进行三维检测是可取的,即使这是一个具有挑战性的任务。
然而,据作者所知,很少有研究人员将UDA框架用于单目3D目标检测。这是因为之前最先进的算法是从局部的2D建议中学习3D信息,而UDA的优势在于从整个图像平面中获得训练良好的模型。而由此产生的多阶段三维目标检测在二维检测中引入了持续的噪声,这大大增加了网络感知周围环境结构的难度。
发明内容
本发明所要解决的技术问题是如何提供一种能够减少源和目标之间的性能差距,并有效地将多个功能与UDA学习相结合的单阶段单目3D目标检测网络。
为解决上述技术问题,本发明所采取的技术方案是:一种单阶段单目3D目标检测网络,其特征在于包括:深度估计网络模块、语义分割网络模块以及三维物体检测模块,所述深度估计网络模块用于对输入的特征图进行深度估计处理,输出深度特征信息;所述语义分割网络模块用于对输入的特征图进行语义分割处理,输出分割特征信息;所述三维物体检测模块用于对输入的特征图进行三维物体检测,输出关键点特征信息;深度特征信息、分割特征信息以及关键点特征信息通过融合模块进行融合处理后分别输出给关键点网络模块以及回归网络模块进行处理,关键点网络模块以及回归网络模块处理后进行3D目标的检测。
进一步的技术方案在于:所述检测网络还包括对抗学习框架,所述对抗学习框架包括基于融合特征的鉴别器训练模块以及基于CMK的DDM对抗学习模块,所述鉴别器训练模块用于使用输入特征向量来弥合共享低层CNN表示的域差距;所述DDM对抗学习模块用于使用CMK来标记被疏离的具有较大域差异的像素区域,忽略对这些像素区域的训练损失。
进一步的技术方案在于:在源图像上训练语义分割的方法包括如下步骤:
语义分割方法采用基于交叉熵的最大软损失算法进行训练。
进一步的技术方案在于:在源图像上进行深度估计的方法包括如下步骤:
对于深度估计,使用反向深度表示,深度估计的基础是不同深度残差回归的berHu损失;
给定一个源图像
(1)
(2)
其中
进一步的技术方案在于:所述通过融合模块进行融合处理的方法包括如下步骤:
使用关键点网络作为特征融合网络,首先,在返回主分支的残差路径上,对来自特征提取模块的编码特征进行解码,输入到关键点网络;
其次,采用Feat的元素智能产品,融合和执行融合的基础上的壮举;
第三,将融合后的特征前馈到剩余的回归模块,生成目标检测框;
最后设
(3)
定义可调超参数
(4)
进一步的技术方案在于:所述通过回归网络模块进行处理的方法包括如下步骤:
目标检测网络的第三个模块是回归分支,用于为热图上的每个关键点构造一个三维边界框;
定义3D边界框回归损失:
(5)
其中
通过联合最小化能量来训练目标检测网络的参数:
(6)
其中
进一步的技术方案在于:所述基于融合特征的鉴别器训练模块的实现方法包括如下步骤:
给定一组源图像和目标图像,用关键点特征作为加权特征向量,其中
(7)
定义语义切分网络的语义特征为
首先,是
然后,将融合特征
G尽量最小化这个目标而D尽量最大化这个目标;
然后,将分类目标最小化为:
(8)/>
对目标图像的训练损失可以表示为:
(9)。
进一步的技术方案在于:所述基于CMK的DDM对抗学习模块的处理过程包括:
构建置信掩码,CMK对能够实现领域对齐的像素点进行估计和标记;
损失重新计算,忽略未标记像素点对应的损失,计算CMK损失。
进一步的技术方案在于:根据CMK重新定义鉴别器损耗如下:
(10)
式中
考虑到无监督机制的CMK预测会以零值来最小化损失,在掩模损失函数中设置正则化项,通过最小化标记为常数“1”的交叉熵来实现非零预测;为CMK损失,可表示为:
(11)
其中
最后,训练损失函数可以表示为:
(12)
其中
采用上述技术方案所产生的有益效果在于:本申请所述网络构建了两个用于语义分割和深度估计的分支网络,将语义和深度特征(仅作为源模型训练中的先验信息)嵌入到目标检测主干网络中,其中深度和语义分割信息作为特征表达,减少了源和目标之间的性能差距。此外,为了解决有效地将多个功能与UDA学习相结合这个问题,本申请提出了一个对抗训练协议,该协议集成了深度、语义和特定目标信息。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1是本发明实施例所述检测网络的原理框图;
图2是本发明实施例中CMK的网络结构图;
图3是本发明实施例中可视化检测到的三维目标图;
图4是本发明实施例中KITTI汽车数据集上不同方法的平均定位误差曲线图;
图5是本发明实施例中不同算法的GPU内存访问测试对比图:从上到下:SMOKE vsMCK-NET vs MonoGRNet vs 本申请。
图6是本发明实施例中CMK掩码可视化之间的目标图像和源图像;
图7是从SYNTHIA数据集和KITTI数据集测试了不同的样本语义分割图;
图8是从SYNTHIA数据集和KITTI数据集测试了不同的样本深度图。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
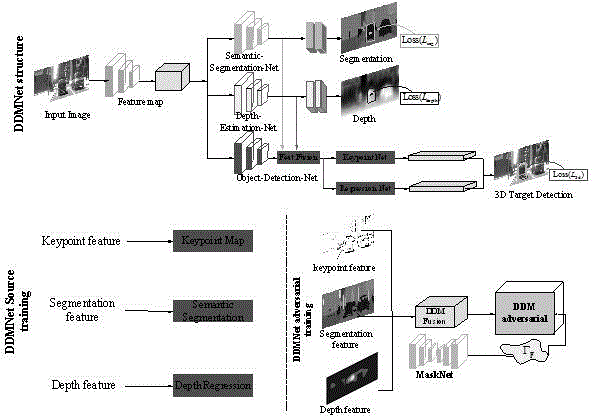
为了降低三维目标标签集的制作成本,本申请提出了在UDA框架下的单目三维目标检测网络,同时进行深度估计和语义分割,如图1所示。
首先,提出了一个嵌入语义和深度特征的单目三维物体检测网络(DDM-NET),在测试时只输入单目图像。还研究了UDA网络中三维关键点、语义和深度特征的融合和表示,旨在在感知场景结构的前提下实现精确的三维目标检测。将特征融合和表示分为特征网络融合和特征融合输出的对抗性训练。
其次,针对源和目标之间缩小域差距的困难和不合理,创造性地在UDA框架中提出了一种置信掩码(CMK),允许一定程度的松弛来折扣DDM-NET没有考虑的失败语义深度特征关键点,提出的CMK的新颖之处在于忽略了源和目标之间固有的区域差异。
第三,在相同的训练模式下,所得到的网络优于现有的所有最先进的单目三维目标检测网络。此外,本申请比较了本申请的DDM-NET与之前直接在目标数据集上训练的作品的性能。
如图1所示,本发明公开了一种域自适应的深度语义感知单阶段单目3D目标检测网络。该网络基于对源场景的理解执行检测任务。显然,语义分割和场景深度分别是对象分类和场景结构的感知结果。本申请的目标是在UDA框架中引入它们用于特定目标的深度语义感知,以提高目标检测。
DDM-NET网络架构:
1)分割和深度分支
从目标检测网络开始,引入了分割网络和深度网络作为额外的分支,将用于场景理解的特征流反馈给骨干网络(目标检测网络)。
首先在源图像上训练语义分割和深度估计。现有的语义分割方法一般采用基于交叉熵的最大软损失算法进行训练。对于深度估计,使用反向深度表示。深度估计的基础是不同深度残差回归的berHu损失。
给定一个源图像
(1)/>
(2)
其中
2)基于源感知信息的目标检测分支
与以往使用二维方案估计三维物体姿态的技术相比,本申请通过在被检测物体实例上使用多步纠缠模块生成三维包围盒,从而提高了三维参数的收敛性和检测精度。目标检测分支包括特征提取模块、关键点分支和回归分支。
特征提取模块:在本模块中,着重研究深度、语义和检测分支网络的互补作用,特别是在表示形式和融合结构等方面。由于不同任务特征层上的接受域和分辨率不同,选择包含更高分辨率和更高接收域的早期特征域作为编码器和解码器组成的特征提取模块的输入流,其中编码器类似于一个小型的Vgg-16网络,解码器通过反褶积产生高维数的特征流。然后,根据多个任务之间的相关性和差异性,将组合分解后的特征分解流作为目标检测任务的共享特征。
关键点融合网络:使用关键点网络作为特征融合网络,它定义了物体在图像平面上的投影3D中心,以便与其他传感器的感知信息聚合。该方法在特征提取阶段将目标信息的深度信息从深度分支和语义分割分支中分离出来,极大地帮助了三维投影中心的有效训练。
首先,在返回主分支的残差路径上,对来自特征提取模块的编码特征(在输出深度和语义分割之前)进行解码,输入到关键点网络。
其次,采用了名为Feat的元素智能产品。融合和执行融合的基础上的壮举。融合层。
第三,将融合后的特征前馈到剩余的回归模块,生成目标检测框。
最后设
(3)
定义可调超参数
(4)
回归分支:目标检测网络的第三个模块是回归分支,它为热图上的每个关键点构造一个三维边界框。
(5)
其中
因此,本申请通过联合最小化能量来训练目标检测网络的参数:
(6)
其中
DDM对抗性学习框架:
选择带有leak - relus的4个顺序卷积层作为DDM-NET的鉴别器。给定由计算机自动标记的虚拟数据集S(源)和未标记的真实数据集T(目标),DDM框架将源和目标域对齐,使鉴别器无法区分这两个域,从而实现用源数据集训练的网络可以在真实数据集中进行测试。
基于融合特征的鉴别器训练:
考虑在鉴别器中部署深度和语义特征,其功能是通过使用输入特征向量来弥合共享低层CNN表示的域差距。因此,鉴别器期望得到的特征向量具有丰富且具有代表性的域特征。输入深度和语义特征代表了对环境深度和对象类别的感知,从而增强了网络对周围环境的理解,进一步提高了对目标域的主要任务。
为了实现这样的策略,本申请提出了联合对齐:首先合并多特征(深度-语义-关键点特征)。更准确地说,给定一组源图像和目标图像,本申请用关键点特征作为加权特征向量,其中
(7)
定义语义切分网络的语义特征为
然后,将融合特征
G尽量最小化这个目标而D尽量最大化这个目标。
然后,将分类目标最小化为:
(8)
对目标图像的训练损失可以表示为:
(9)
该鉴别器利用深度语义感知映射从空间结构和对象类别等多维度保持域的一致性,有利于源和目标域在特定对象上的对齐。
2)基于CMK的DDM对抗学习
为了避免对其他场景像素的干扰,使用CMK (confidence mask)来标记被疏离的具有较大域差异的像素区域,忽略对这些像素区域的训练损失。如图3所示,基于CMK的领域对抗学习方案主要由两个过程组成:i)构建置信掩码,CMK对能够实现领域对齐的像素点进行估计和标记;ii)损失重新计算,忽略未标记像素点对应的损失,计算CMK损失。这两个过程只在训练过程中同时发生。下面将详细描述这些过程。
面罩结构的构建:本申请训练了一个名为CMK的置信度掩模,用于标记源图像中相应像素的置信度。像素的置信度越高,像素域对齐的概率越高。CMK网络结构如图2所示。
由图2可以看出,该网络是一个编码器-解码器架构,编码器由6个卷积层组成,对应于卷积核的参数:
解码器为6个上卷积层:
除预测层为sigmoid函数外,每一层的卷积核均为3,预测层对应的输出层和卷积核的尺寸参数为:
基于CMK的损失函数:根据CMK重新定义鉴别器损耗如下:
(10)
式中
考虑到无监督机制的CMK预测会以零值来最小化损失,在掩模损失函数中设置正则化项,通过最小化标记为常数“1”的交叉熵来实现非零预测。为CMK损失,可表示为:
(11)
其中
最后,训练损失函数可以表示为:
(12)
其中
实验方法:
本申请补充了本工作中使用的合成-2-实基准,并定性和定量地比较了所提模型与其他单目3D目标检测算法的性能。
A. 语义分割
数据集:为了评估本申请的方法,本申请使用了一个具有挑战性的合成2实无监督域自适应设置。在这项试验中,SYNTHIA数据集提供了9400张带有像素级语义标签和深度标签的训练图片,被用作源域。对于目标域,本申请采用城市景观数据集KITTI,该数据集提供7481张图片用于训练,7352张图片用于测试。根据Car、pedestrian和cyclist等对象实例在2D边界框中的遮挡和截断程度,将数据集分为三个层次:(1)Easy、(2)Moderate、(3)Hard。在之前的工作中,领域对齐(SYNTHIA-KITTI)并没有被用于三维物体检测任务中,这是本申请首次将其作为评价标准协议。
指标:采用三维方框重叠测量的平均精度(
训练细节:DDM-NET的培训过程分为两个阶段。在第一阶段,本申请使用包含语义标签和深度注释的SYNTHIA数据集作为多任务网络训练的输入。然后,在DDM对抗性学习框架下,联合训练源数据(SYNTHIA)和目标数据(KITTI),以实现源网络应用于真实数据集。DDM-NET在Pytorch 1.1、CUDA 10.0和CUDNN 7.5上实现。实验中测试的图像是通过单台相机拍摄的。所有实验都将图像大小调整为1280 384,初始学习率和小批量分别设为r=0.0002和b=4。对于式(12),loss weights设为
绩效评估
3D检测性能:首先,本申请使用直接在Kitti数据集中训练的不同单目3D目标检测方法评估所提出的DDM-NET的结果。它们被标记为“*”,以区分本申请在SYNTHIA数据集上训练的方法。定量比较结果见表2。本申请可以观察到,本申请的方法在相同的SYNTHIA数据集上训练的方法中取得了最先进的结果。在中度和硬性类别(+45.9%,+23.9%)的APbv(IoU=0.5, 0.7)指标上观察到重要的收益。然而,本申请的方法不如用KITTI数据集训练的方法[15,16,20]。注意,方法[15,16,20]的训练和测试数据使用KITTI数据集,而本申请的方法仅使用KITTI作为测试集,低成本计算机生成图像(SYN)作为训练集。合成数据集(SYNTHIA)和真实数据集(KITTI)在场景布局上的差异导致姿态估计网络的性能有限,导致本申请的方法与其他方法[15,16,20,23]进行不公平的比较。尽管如此,与使用KITTI数据集训练的方法(Mono3D*)相比,本申请使用合成数据集训练的方法仍然在3D检测的硬水平上取得了具有竞争力的结果。
为了定量评价本申请的DDM-NET与其他算法的能力,本申请使用KITTI数据集作为训练集,但本申请的算法在训练时需要使用相应的深度和语义标签,使用KITTI数据集不能满足这一要求。本申请利用网络生成的语义分割和深度图像作为额外的训练输入。得到的深度估计实验结果如表1所示。事实上,网络产生的训练输入与实际图像之间的差距限制了本申请网络的性能。然而,在相同的训练模式下,本申请的DDM-NET比现有的所有最先进的单眼3D目标检测算法都要好。
因此,本申请推测,提高检测精度得益于场景深度和物体类别信息的引入,扩展了网络上的感知层次和范围;另一方面,从多维角度实现源目标域对齐,提高目标检测精度。
表1-不同算法在鸟瞰图(APbv)和3D方框(AP3D)上的性能比较
其中Mono3D[16] 是指:X. Chen, H. Ma, J. Wan, et al. Monocular 3dobject detection for autonomous driving[C]// Proceedings of the Conference onComputer Vision and Pattern Recognition. IEEE, 2147–2156, 2016.
其中Deep3DBox[23] 是指:A. Mousavian, D. Anguelov, J. Flynn, et al. 3DBounding Box Estimation Using Deep Learning and Geometry[C]// Proceedings ofthe Conference on Computer Vision and Pattern Recognition, arXiv: 1612.00496,2017.
Multi-Fusion[20]是指:B. Xu, Z. Chen. Multi-level fusion based 3dobject detection from monocular images[C]// Proceedings of the Conference onComputer Vision and Pattern Recognition. IEEE, 2345-2353, 2018.
MonoGRNet[15]是指:Z. Qin, J. Wang, Y. Lu. MonoGRNet: A GeometricReasoning Network for Monocular 3D Object Localization[C]// Proceedings ofthe Conference on Computer Vision and Pattern Recognition. IEEE, arXiv:1811.10247, 2019.
在Kitti数据集上的检测结果示例如图3所示。从非遮挡车辆检测中可以看出,本申请的方法检测到的三维包围盒与实际车辆一致,很好地包围了车辆的四个车轮。对于车辆密集区域的车辆中心定位,本申请有了很大的改进。即使图像中车辆的边界被严重截断,本申请的检测结果也能满足自动驾驶场景中车辆突然从侧面出现时避免相互碰撞的要求。通过上述比较,证明了DDM-NET在目标检测性能上的优越性。
3D定位估计。表2所示的三维物体定位结果表明,在相同的训练情况下,DDM-Net在尺寸评价指标(高度、宽度、长度)上优于现有的所有单眼方法。通过对“SMOKE”和“本申请”的对比,可以看出“本申请”对3D盒子角的检测能力更强。因此,语义分支和深度分支的提取对规模估计具有重要意义。此外,本申请的方法从深度和语义分支上分享了必要的三维盒子回归特征,简化了直接从图回归的过程,加快了三维盒子的检测。
表2-三维边界框元素误差比较,以粗体显示最佳结果
图4定量显示了三维位置误差。从许多基于单目图像的检测算法中可以看出,深度估计误差随着目标距离的增大而增大,尤其是对距离较远的小目标的检测。但是,我本申请的模型在对象上有更健壮的性能。当目标距离相机30米及以上时,本申请的方法在定位误差上明显优于MonoGRNet[15]和3DOP[38]。
3DOP[38]是指:X. Chen, K. Kundu, Y. Zhu, et al. 3d object proposalsusing stereo imagery for accurate object class detection[J], IEEETransactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 25,pp. 1259-1272, 2018.
算法效率的比较。表3显示了运行结果的算法运行效率。对于得到的神经网络参数,SMOKE的网络参数为2.4*106,MCK-NET的网络参数为2.7*106,MonoGRNet的网络参数为4.2*106,本申请算法的网络参数为1.9*106。虽然本申请的网络参数接近于SMOKE,但本申请的运行时间至少比SMOKE解决方案快20%。这是因为本申请需要的输入图像分辨率只有640*640,因此不需要花费更多的操作时间来达到新的状态。其次,由于本申请只使用一个阶段来估计回归的3D变量,发现本申请的方法比MCK-NET/ MonoGRNet快60%。然后,单组件任务和本申请的DDM-NET的平均训练时数如表3所示。数值结果表明,由于多任务的联合训练,本文提出的网络结构平均比之前的系统快了近16%。
表3-不同算法运行效率比较。
此外,本申请粗略估计了所提算法在边缘设备(NVIDIA Jetson Xavier NX)上的效率。图5显示了在DDM-Net测试中测量的GPU内存访问情况。由于网络结构的优化,与SMOKE相比,大大减少了内存访问次数。测试时消耗的GPU内存为0.77G。可以观察到,本申请的算法的运行时间将从GTX 2080Ti设备上的0.026s更改为NVIDIA Jetson Xavier NX上的0.102s。该算法的计算性能约为SMOKE算法的1.21倍。请注意,如果使用更高级的自动驾驶处理芯片,而不是像实际的特斯拉芯片那样使用板载芯片,运行时间可能会减少。
消融研究:
在表4中报告了一系列实验,包括7个训练设置,S1到S5: S1是基线模型(BM)(不引入深度和语义分割),S2是改进的SMOKE(使用深度和语义分割特征的关键点融合网络),S5是本申请的DDM-NET。中间设置S3到S4相当于使用或不使用鉴别器训练中的融合特征和DDM对抗学习中的CMK掩码。首先,本申请注意到共享深度和语义信息确实有助于提高主要任务(3D对象检测)的性能。与S4相比,S5的改进体现了关键点网络在特征层面表达和整合深度特征和语义特征的有效性。事实上,S5将融合特征输入到DDM对抗性学习中,比S4性能更好(例如方位0.216 vs. 0.169,尺寸0.70 vs. 0.064)。不过,在S3中,源和目标之间的对齐像素会由于较大的域间隙而导致精度降低。本申请的深度语义感知框架S5采用特征融合和CMK掩模,性能最好:允许对具有较大间隙的像素区域进行一定程度的松弛。S3到S5的改进体现了CMK掩模的优势。
表4-使用和不使用建议组件训练的模型的性能比较
那么,本申请的DDM-NET各个模块的平均运行时间和整体运行时间如表5所示。S1-S5的运行时间分别为0.032、0.457、0.463、0.514和0.521,由此可以推断出各个模块的运行时间:语义深度分支网络为0.457,约占DDM-NET总运行时间的81.5%,判别器训练模块为0.057s,约为DDM-NET运行时间的1.2%,CMK掩码模块为0.057s,回归模块推理剩余时间为0.032s。总的来说,这种时间成本在离线应用中至少是可以接受和满意的,因为本申请提出的网络结构比之前的系统平均快14%,具体对比见表5。
表5-使用和不使用建议组件训练的模型的性能比较。
考虑到深度-语义对齐中布局极不一致的区域对其他像素区域的影响,本申请采用基于优化后的三维中心投影和对应深度的置信度掩码(CMK)对区域差异较大的疏离像素区域进行标记。图6显示了网络预测的可解释掩码。分析结果表明,可解释掩码上大部分白色像素(置信度高),表明所提出的网络对目标进行了深度到语义的关系处理,实验结果表明,对这些目标的检测精度确实有很大的提高。相反,掩蔽后的MaskNet对于远处(图中为灰色)清晰度较低或遮挡较低的物体可信度较低,说明模型网络无法明确物体上的深度-语义对应关系。实验中对这些物体的检测精度进一步说明了这一问题。
本申请训练和比较了一组模型,以证明CMK处理偏差的有效性,并在表VII中评估检测和定位性能,其中“BM”代表基线模型(不引入CMK和CMK损失,(2)“SFM-BM”表示使用SFMLearner[36]将掩码输入到DDM对抗性学习框架,(3)“Mask - bm”表示Mask[32]对DDM对抗性学习框架的输入,DDM- cmk是本申请的框架。
SFMLearner[36]是指:C. Godard, O. M. Aodha, G. J. Brostow.Unsupervised monocular depth estimation with left-right consistency[C]//Proceedings of the Conference on Computer Vision and Pattern Recognition,6602–6611.
Mask[32]是指:F. S. Saleh, M. S. Aliakbarian, M. Salzmann, et al.Effective use of synthetic data for urban scene semantic segmentation [C] //Proceedings of European Conference on Computer Vision, pages 86–103.Springer, Cham, 2018.
通过对“BM”和“SFM-BM”的对比,如表6所示,可以验证掩码网络应用的输入在深度估计和目标检测精度上都有提高。与MASK-BM和SFM-BM相比,DDM-CMK表明本申请的网络结构在实现深度语义对应方面是最好的,并进一步补偿了检测精度。
表 6 有CMK掩码和无CMK损耗的目标检测网络性能对比
深度语义感知对抗性适应对深度估计和语义分割的影响
为了分析深度语义感知对抗性适应对深度估计和语义分割的影响,本申请随后探讨了深度语义感知对抗性适应对其他分支任务的贡献。
对深度估计的影响:这个实验证明了深度语义感知对抗适应带来的卓越性能。由于DDM对抗性学习作用于其他子任务(深度分割和语义分割)。本申请采用不同的组合进行实验,并在表7中评价检测定位性能。本文对子任务性能的两个版本进行了如下分析:(a)D是一个深度估计模型[35],不使用所提出的DDM对抗学习。(b)“DDM-D”是指将DDM对抗性学习引入深度网络(D);(c)“S”是一个不使用DDM对抗学习的语义分割模型[35]。(d)“DDM-S”相当于改进的S (Semantic segmentation with DDM对抗性学习),DDM- net是本申请的框架,它引入了分割和深度网络作为附加分支。
[35]是指:T. H. Vu, H. Jain, M. Bucher, et al. DADA: Depth-AwareDomain Adaptation in Semantic Segmentation[C]// Proceedings of the Conferenceon Computer Vision and Pattern Recognition, arXiv: 1904.01886, 2019.
表7-不同算法的深度和语义分割评
本申请可以发现,“D”和DDM-D的比较已经证明了通过DDM对抗学习进行深度估计的优势。此外,本申请提出的网络优于其他模型,给出了最先进的结果在语义分割评估。语义分割样本如图7所示。本申请可以观察到所提出的模型如何逐步提供更好的语义分割。这一事实在步骤中更加明显:基于深度特征的对抗性学习逐渐明显,如最后一列中的示例所示。图8为SYNTHIA数据集和KITTI数据集深度测试的可视化结果。可以看到,本申请的方法可以产生清晰、尖锐的深度输出,并能很好地保存物体边界和细长的结构(树木、电线杆等)。因此,本申请的DDM-Net对这些区域提供了合理的预测-有时甚至接近真实的深度。
综上,本申请提出了一种新的单级单目三维目标检测网络,该网络引入了额外的深度和语义分割信息。为了有效地结合UDA学习的多种特征,本申请提出了一种集成深度、语义和特定目标信息的对手训练协议。针对对手训练协议中对象域差距的严重和不合理,本申请创造性地在UDA框架中提出了一种信心掩码(CMK),允许一定程度的放松,以对DDM-NET未考虑的关键点的语义深度域对齐失败进行折扣。在相关数据集上,本申请的模型优于所有现有的最先进的单眼3D目标检测算法。