一种基于心电信号和呼吸信号的人体生理疲劳检测方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明提供一种基于心电信号和呼吸信号的人体生理疲劳检测方法,属于穿戴设备技术领域。
背景技术
1982年第5届国际运动生化会议对于“疲劳”的概念做出统一:机体生理过程不能维持预定的运动强度而运动功能暂时下降,经过适当的休息可以恢复的现象。疲劳可分为生理疲劳和心理疲劳:生理疲劳又被称为身体疲劳,一般是由于生理上的超负荷而引起的,指人进行身体运动时,运动量或工作量超过负荷导致出现身体无力,肌肉酸痛等现象。心理疲劳又被称为精神疲劳,指的是一种缺乏警觉和动机的主观状态,长期从事单调、机械的工作活动,中枢局部神经细胞由于持续紧张而出现抑制,致使人对工作对生活的热情和兴趣明显降低,直至产生厌倦情绪等。本发明主要研究人体生理疲劳检测方法。
人在从事体力工作或者体育锻炼的过程中会产生生理疲劳,生理疲劳会使机体生理过程无法维持预定的运动强度,从而使运动功能暂时下降。例如,运动员、士兵等职业会在训练过程中产生生理疲劳,如果没有得到适当的休息,就可能引发危险;体力工作者长期工作,也会出现不同程度的生理疲劳,可能对生命财产造成不可挽回的损失。生理疲劳的产生时间由多种因素决定,包括个人体质、运动强度、生理状况、外界环境等,不同个体在生理疲劳产生时的表现也会有所不同,因此生理疲劳难以准确预测。
目前的疲劳检测方法主要分为两种:第一种为基于人体行为的疲劳检测,比如通过惯性传感器检测学生上课打瞌睡的行为、通过眼动仪观察司机开车时的眼动轨迹特征,以判断是否进入疲劳状态;第二种为基于人体生理信号的疲劳检测,即通过检测人体心电信号、呼吸信号、脑电信号和表皮肌电信号等生理信号,判断出当前人体是否疲劳。本发明采用第二种疲劳检测方法。
东北大学在2019年提出了一种方法,该方法基于人体心电信号和表皮肌电信号的方法判断矿工的生理疲劳情况,(Chen S,Xu K,Yao X,et al.Information fusion andmulti-classifier system for miner fatigue recognition in plateau environmentsbased on electrocardiography and electromyography signals.[J].ComputerMethods and Programs in Biomedicine,2021,211:106451.)该团队从55名矿工中采取了疲劳状态和非疲劳状态的心电信号和表皮肌电信号,作为疲劳分析的基础信号,并进行了滤波、R波监测和其他预处理。该团队对心电信号进行时域分析和频域分析,提取了RR周期序列、R波峰值和功率谱参数作为特征,对表皮肌电信号主要采用时频分析方法,提取了中值频率、最高频率、平均频率、平均功率和总功率作为特征。通过使用支持向量机、随机森林和XGBoost机器学习算法构建基于心电信号和表皮肌电信号指标的分类器,建立疲劳识别模型。三种机器学习算法构建的分类器准确率分别为89.47%、78.95%和89.47%。
但是该方法存在缺点:
(1)采用的表皮肌电信号对四肢都有佩戴要求,若实现可穿戴设备实时监测,对受试者身体活动影响较大;
(3)该技术算法不够精确,将人体分为“疲劳”、“非疲劳”两种状态,仅判断有无疲劳出现,无法对疲劳状态进行更精确的分类。
发明内容
本发明设计了一种基于心电和呼吸信号对人体生理疲劳进行监测的方法,利用可穿戴设备对人体的生理数据进行实时监测,采用机器学习算法对该数据进行分析,判断人体当前的生理疲劳状态。可穿戴生理监测设备相对轻便,能够在人体运动的过程中穿戴,在不影响工作和训练的情况下,对人体进行监测,结合生理疲劳评估算法,监测人体状态,从而减少或避免由生理疲劳产生带来的损失。
以解决以下问题:
(1)减小可穿戴设备对受试者活动的影响,并且不影响生理疲劳检测准确率
现有技术一采用基于心电信号和表皮肌电信号的数据采集与分析方法,该方法所用设备对受试者身体活动影响较大;现有技术二仅采用心电信号作为生理疲劳评判依据,准确率相对较低。本发明提出基于心电信号和呼吸信号进行分析,结合多源生理数据融合技术判断人体生理疲劳。既减小了可穿戴设备对受试者运动的影响,又能提升单一心电信号检测的准确率。
(2)算法优化
在现有技术的基础上,本发明对生理疲劳检测算法进行优化,基于ELM网络对生理特征进行分类,再根据历史疲劳状态变化情况,基于LSTM网络模型判断受试者当前所处疲劳场景,疲劳场景包括“体力充沛期”(不疲劳)、“发力期”(疲劳逐渐加深)、“力竭期”(持续疲劳)、“恢复期”(疲劳逐渐减缓),根据该场景对生理疲劳检测结果进行“后处理”,修正ELM网络的生理疲劳检测的结果,增加生理疲劳检测的准确率。不仅判断是否产生疲劳,而且将分类算法的结果设置为“不疲劳”、“一般疲劳”、“非常疲劳”三类,以便准确掌握受试者当前疲劳状态。
本发明具体技术方案为:
一种基于心电信号和呼吸信号的人体生理疲劳检测方法,包括以下步骤:
S1.数据预处理
心电噪声主要包含基线飘移、工频噪声和运动伪影,其中基线飘移和工频噪声由巴特沃斯滤波器和陷波滤波器去除,运动伪影的去除,首先要对运动伪影噪声进行定位。定位分为两步,运动伪影噪声强度估计和运动伪影位置检测。
采用噪声强度检测算法,对心电信号的运动伪影噪声强度进行分析评估,强度评估结果取值区间为[0,1]。接近0和1的值分别表示轻微和强烈的噪声干扰。
运动伪影噪声强度估计方法为
其中,σ
小波变换L计算方法为:
其中,f
σ
根据上述噪声强度检测算法,得出当前检测信息的运动伪影噪声强度估计值σ
运动伪影位置检测利用信号方差变换SVT将信号进行变换,然后采用自适应阈值对噪声信号可能存在的窗口进行定位分析,具体方法如下:
基于噪声强度估计值σ
w=σ
其中,窗口长度w的取值范围是[w
将检测到的心电信号划分窗口,并且进行SVT变换:
其中,y
选用上下两个阈值(上阈值T
M
其中,上下自适应阈值的取值方法如(6)和(7)。
T
γ
γ
其中,μ
在自适应区间的SVT信号窗口将被标记为运动伪影,加入集合M
采用Savitzky-Golay滤波方法,基于最小二乘拟合方法对原始信号X[n]进行拟合,得到噪声拟合多项式:
拟合多项式充当平滑的噪声信号滤波器,将原始信号减去该噪声拟合信号,拟合残差为:
其中,M为单边信号数量,N为多项式阶数,为了让拟合残差C
即:
由公式(10)可知,确定变量M、N和原始信号数据X[n],即可获得噪声拟合多项式p(n)。原始信号X[n]与多项式p(n)做差即可得到纯净的心电信号。
S2.特征提取
基于上一步骤滤波等噪声处理方法,从现场采集的原始数据提取出纯净心电和呼吸信号,根据专家经验对该信号进行手工特征提取,并进行特征比对和筛选,最终保留的特征见下表1。
表1特征名称及对应描述
表1中共有七项特征,前六项特征由心电信号提取,最后一项由呼吸信号提取。R峰为心跳一次产生的电信号中,电位值最高的峰值点;RR间期表示相邻两个R峰中间的时间间隔。
S3.模型搭建和训练
生理疲劳检测模型搭建分为两部分:
第一部分基于超限学习机模型对当前时刻生理信号进行分类判断,得到当前生理疲劳状态,将特征分类得到三种可能的疲劳情况:“不疲劳”、“一般疲劳”、“非常疲劳”,并记录结果用作“后处理”,该过程仅根据当前时刻的生理信号做出判断,准确率相对较低;
第二部分将记录的历史疲劳状态加入到评估中,基于长短期记忆网络模型进行训练,可得到当前人体所处的疲劳场景,疲劳场景也分为四种情况:“体力充沛期”(不疲劳)、“发力期”(疲劳逐渐加深)、“力竭期”(持续疲劳)、“恢复期”(疲劳逐渐减缓)。然后根据人体疲劳场景对当前生理疲劳状态进行二次评估与修正,该过程可称之为“后处理”。
1)超限学习机模型训练方法
采用不同个体的疲劳情况数据提取的特征向量作为样本,划分为训练集和测试集。训练集用作ELM模型训练,并基于神经网络的泛化能力,对测试集进行分类,验证分类模型结果的可靠性。模型训练和测试的具体步骤如下:
(1)建立人工神经网络结构模型
分析样本数据结构:训练样本有N个,特征维度为n,样本输入矩阵X
样本输出维度为m,输出矩阵T
根据样本输入参数特征维度n,确定输入层神经元个数设置为n,本模型为多分类问题,疲劳的数据结果可能性为3,因此将输出层神经元个数设置为3。:
(2)设置隐层节点数和正则化参数
选取不同的隐层节点个数L和正则化参数C,进行多次模型训练,对比选出最合适的参数。
(3)设定各个隐层节点的输入权重和输入偏置
随机生成若干次权矩阵W和输入偏置b,选择效果最好的模型。隐层输入权重矩阵W为
隐层输入偏置矩阵b为
b=(b
(4)计算隐层输出H
选择合适的激活函数g(x),可得到隐层输出H。
(5)计算隐层输出权重β
根据RELM的输出权值矩阵计算方法计算出隐层输出权重β
通过变换隐层节点个数L和正则化参数C及重新生成权矩阵W和输入偏置b,进行多次独立实验,得到不同的隐层输出权重β,组成完整的神经网络参数。将样本测试集带入该网络进行测试,算出样本对不同模型的准确率和误差。选取效果最好的模型,即可用于生理疲劳初步检测。
2)长短期记忆网络模型训练方法
基于LSTM网络模型推断该个体当前所处疲劳场景,即“体力充沛期”“发力期”、“持续疲劳期”或者“体力恢复期”,并根据该结果,对ELM模型的评估结果进行修正;
将受试者的数据分成长度为十分钟的窗口数据,依照受试者所处疲劳场景情况的主观感受,对窗口数据标签进行标定,用作模型训练的样本。
模型训练和测试的具体步骤如下:
(1)确定LSTM网络模型参数
LSTM模型建立需要确定关键参数:输入维度n,输出数据维度m,神经网络隐藏节点数量L。其中,该网络模型的输入为历史疲劳状态,数据形式为长度为n的数字序列,表示从若干分钟前一直到现在时刻,受试者的疲劳状态变化情况。输出包含两个信息,一是受试者当前所处的疲劳场景,二是经过“后处理”的受试者当前疲劳状态。隐藏节点数量经过多次实验训练,选择最合适的数值。
(2)训练LSTM网络模型
根据受试者的主观感受,将采集的生理数据每部分标记对应疲劳场景和疲劳状态,制成训练样本。划分为训练集和测试集,其中训练集用作训练LSTM网络模型,测试集带入训练完成的模型,获取准确率,以评估网络模型的好坏。
(3)调整网络模型
通过调整输入历史疲劳状态时长、隐藏节点数量等值,调整网络准确率,获取准确率最高的网络结构。
本发明提供了一种心电信号和呼吸信号的人体生理疲劳检测方法,利用可穿戴设备采集生理信号,实现实时检测人体生理疲劳,能够防止运动员、士兵等职业会在训练过程中产生生理疲劳,由于没有得到适当的休息引发危险;也可防止司机、医生及精密仪器操作员长期工作出现疲劳,对生命财产造成不可挽回的损失。具体的发明效果如下:
1、本发明抛弃了现有技术采用的较繁琐的表皮肌电信号采集设备,根据心电信号和呼吸信号的可穿戴设备,采集信息并分析人体在运动过程中产生的生理疲劳,降低了受试者在佩戴时产生的不适感。
2、本发明采用ELM网络加LSTM网络“后处理”的结构,优化了算法,使“不疲劳”、“一般疲劳”、“非常疲劳”的三分类模型疲劳检测准确率与二分类模型持平,达到89%,检测出的人体疲劳状态更精准。
附图说明
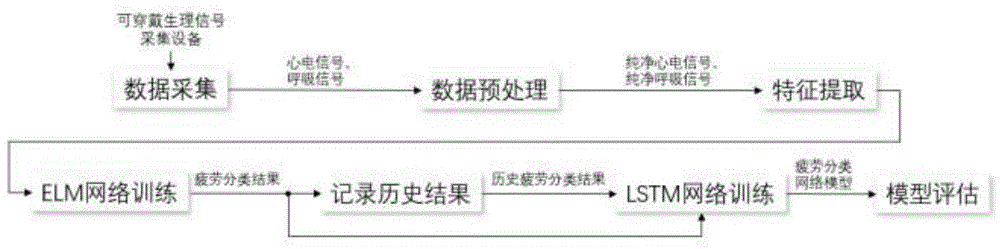
图1为本发明基于可穿戴设备的生理疲劳检测总体流程图;
图2为本发明运动伪影噪声强度估计流程;
图3为实施例中原始心电信号;
图4为实施例中SVT变换后的信号;
图5为实施例中阈值定位ECG中的运动伪影;
图6为实施例中跑步时的心电图;
图7为实施例中去除噪声后的心电图;
图8为实施例中生理疲劳检测流程图;
图9为超限学习机一般模型图;
图10为实施例中ELM模型结构图;
图11为实施例中试验设备,依次包括心电信号采集设备(左)、呼吸采集设备(中)和蓝牙路由器(右);
图12为实施例中ELM模型预测结果混淆矩阵;
图13为实施例中LSTM模型预测结果混淆矩阵。
具体实施方式
本发明的方法能够提供一种基于心电信号和呼吸信号的人体生理疲劳检测方法,根据可穿戴设备采集的生理信号,分析人体在运动过程中产生的生理疲劳,该方法总体流程图见图1。下面从数据预处理、特征提取、模型训练、实验验证、数据分析与结论几个方面介绍该发明方案。
一种基于心电信号和呼吸信号的人体生理疲劳检测方法,包括以下步骤:
S1.数据预处理
由于呼吸信号为胸廓压力值,从中提取的有效信息为呼吸速率,噪声影响并不大,所以主要内容为去除心电信号数据中的噪声。心电噪声主要包含基线飘移、工频噪声和运动伪影,其中基线飘移和工频噪声可由巴特沃斯滤波器和陷波滤波器去除,所以本发明去噪内容是运动伪影的去除。
可穿戴设备监测心电信号时,受试者可能处于运动状态或者静息状态,所以首先要对运动伪影噪声进行定位。定位分为两步,运动伪影噪声强度估计和运动伪影位置检测。
采用噪声强度检测算法,对心电信号的运动伪影噪声强度进行分析评估,强度评估结果取值区间为[0,1]。接近0和1的值分别表示轻微和强烈的噪声干扰。它对不同采样频率和噪声水平的有噪声心电信号具有鲁棒性。
图2为运动伪影噪声估计流程。
运动伪影噪声强度估计方法为:
其中,σ
小波变换L计算方法为:
其中,f
σ
根据上述噪声强度检测算法,可得出当前检测信息的运动伪影噪声强度估计值σ
运动伪影位置检测主要是利用信号方差变换(SVT)将信号进行变换,然后采用自适应阈值对噪声信号可能存在的窗口进行定位分析,具体方法如下:
基于噪声强度估计值σ
w=σ
其中,窗口长度w的取值范围是[w
将检测到的心电信号划分窗口,并且进行SVT变换
其中,y
图3与图4为典型的心电原始信号与SVT变换后的信号实例。
选用上下两个阈值(上阈值T
M
其中,上下自适应阈值的取值方法如(6)和(7)。
T
γ
γ
其中,μ
阈值选择运动伪影的信号窗口,如图5所示。
在自适应区间的SVT信号窗口将被标记为运动伪影,加入集合M
采用Savitzky-Golay滤波方法,相比较与卡尔曼滤波等方法,具有较低的时间复杂度,并且可适应窗口长度不断变化的信号数据,更适合采用此方法去除信号中的运动伪影。
Savitzky-Golay滤波的核心思路是基于最小二乘拟合方法对原始信号X[n]进行拟合,得到噪声拟合多项式:
拟合多项式充当平滑的噪声信号滤波器,将原始信号减去该噪声拟合信号,即可快速、简单去除心电信号中的运动伪影噪声。拟合残差为:
其中,M为单边信号数量,N为多项式阶数,为了让拟合残差C
即:
由公式(10)可知,确定变量M、N和原始信号数据X[n],即可获得噪声拟合多项式p(n)。原始信号X[n]与多项式p(n)做差即可得到纯净的心电信号。也可看出Savitzky-Golay滤波器可有任意的长度,因此有利于采样频率较低的ECG信号处理。
下图分别是跑步时的心电图6和经过噪声去除后的心电图7对比。
S2.特征提取
基于上述滤波等噪声处理方法,从现场采集的原始数据提取出纯净心电和呼吸信号,根据专家经验对该信号进行手工特征提取,并进行特征比对和筛选,最终保留的特征见下表1。
表1特征名称及对应描述
表1中共有七项特征,前六项特征由心电信号提取,最后一项由呼吸信号提取。R峰为心跳一次产生的电信号中,电位值最高的峰值点;RR间期表示相邻两个R峰中间的时间间隔。
S3.模型训练
生理疲劳检测流程图如图8所示。
本发明生理疲劳检测模型搭建分为两部分:
第一部分基于超限学习机模型对当前时刻生理信号进行分类判断,得到当前生理疲劳状态,将特征分类得到三种可能的疲劳情况:“不疲劳”、“一般疲劳”、“非常疲劳”,并记录结果用作“后处理”,该过程仅根据当前时刻的生理信号做出判断,准确率相对较低;
第二部分将记录的历史疲劳状态加入到评估中,基于长短期记忆网络模型进行训练,可得到当前人体所处的疲劳场景,疲劳场景也分为四种情况:“体力充沛期”(不疲劳)、“发力期”(疲劳逐渐加深)、“力竭期”(持续疲劳)、“恢复期”(疲劳逐渐减缓)。然后根据人体疲劳场景对当前生理疲劳状态进行二次评估与修正,该过程可称之为“后处理”。
1)超限学习机模型训练方法
2004年黄广斌教授提出超限学习机模型(Extreme Learning Machine,ELM)来解决传统神经网络面临的问题。ELM是一种单隐层前馈神经网络,包含输入层、隐含层、输出层共三层,其基本的结构如图9所示。其隐含层参数是随机生成的,输出层的参数是基于最小二乘法解析得到的。这种方式是免迭代的,同时避免了反向传播会陷入局部最优的缺点。并且具有速度更快,泛化能力更强的优势。
传统的ELM基于经验风险最小化准则(Emperical Risk Minimization,ERM),通过求解经验风险的最小值逼近真实期望风险最小值,基于经验风险最小化准则的模型在实际应用过程中存在学习精度和预测精度不一致问题,可能存在过度拟合的问题,这种模型很容易误导最终的判断。对此,邓万宇教授等人提出在ELM中加入表示模型复杂度的正则化项,减少过拟合,使训练模型更具有泛化能力,即正则化超限学习机(Regularized ELM,RELM)。
RELM的输出权值矩阵表示方法见公式11:
其中,H表示隐层输出矩阵,C表示正则化参数,L表示隐层神经元个数,N表示训练样本个数,T为期望输出向量,I表示单位矩阵。
本实验将采用不同个体的疲劳情况数据提取的特征向量作为样本,划分为训练集和测试集。训练集用作ELM模型训练,并基于神经网络的泛化能力,对测试集进行分类,验证分类模型结果的可靠性。模型训练和测试的具体步骤如下:
(1)建立人工神经网络结构模型
分析样本数据结构:训练样本有N个,特征维度为n,样本输入矩阵X
样本输出维度为m,输出矩阵T
根据样本输入参数特征维度n,确定输入层神经元个数设置为n,本模型为多分类问题,疲劳的数据结果可能性为3,因此将输出层神经元个数设置为3。如图10所示:
(2)设置隐层节点数和正则化参数
选取不同的隐层节点个数L和正则化参数C,进行多次模型训练,对比选出最合适的参数。
(3)设定各个隐层节点的输入权重和输入偏置
随机生成若干次权矩阵W和输入偏置b,选择效果最好的模型。隐层输入权重矩阵W为
隐层输入偏置矩阵b为
b=(b
(4)计算隐层输出H
选择合适的激活函数g(x),可得到隐层输出H。
(5)计算隐层输出权重β
根据RELM的输出权值矩阵计算方法计算出隐层输出权重β
通过变换隐层节点个数L和正则化参数C及重新生成权矩阵W和输入偏置b,进行多次独立实验,得到不同的隐层输出权重β,组成完整的神经网络参数。将样本测试集带入该网络进行测试,算出样本对不同模型的准确率和误差。选取效果最好的模型,即可用于生理疲劳初步检测。
2)长短期记忆网络模型训练方法
长短期记忆网络(Long Short Term Memory,LSTM)是循环神经网络中的一种,用于时序数据的预测。LSTM的出现主要是用来解决传统RNN长期依赖问题。对于传统的RNN,随着序列间隔的拉长,由于梯度爆炸或梯度消失等问题,使得模型在训练过程中不稳定或根本无法进行有效学习。
本发明根据历史疲劳发展趋势,基于LSTM网络模型推断该个体当前所处疲劳场景,即“体力充沛期”“发力期”、“持续疲劳期”或者“体力恢复期”,并根据该结果,对ELM模型的评估结果进行修正,能够提高生理疲劳检测结果的准确性。
将受试者的数据分成长度为十分钟的窗口数据,依照受试者所处疲劳场景情况的主观感受,对窗口数据标签进行标定,用作模型训练的样本。
模型训练和测试的具体步骤如下:
(1)确定LSTM网络模型参数
LSTM模型建立需要确定关键参数:输入维度n,输出数据维度m,神经网络隐藏节点数量L。其中,该网络模型的输入为历史疲劳状态,数据形式为长度为n的数字序列,表示从若干分钟前一直到现在时刻,受试者的疲劳状态变化情况。输出包含两个信息,一是受试者当前所处的疲劳场景,二是经过“后处理”的受试者当前疲劳状态。隐藏节点数量经过多次实验训练,选择最合适的数值。
(2)训练LSTM网络模型
根据受试者的主观感受,将采集的生理数据每部分标记对应疲劳场景和疲劳状态,制成训练样本。划分为训练集和测试集,其中训练集用作训练LSTM网络模型,测试集带入训练完成的模型,获取准确率,以评估网络模型的好坏。
(3)调整网络模型
通过调整输入历史疲劳状态时长、隐藏节点数量等值,调整网络准确率,获取准确率最高的网络结构。
实验验证:
1)实验对象
本发明从北京科技大学中选择了10名男性学生作为研究对象,通过现场测试收集数据。受试者的基本信息如下:平均年龄为24±2岁,平均身高为173.2±5.1cm,平均体重为68.2±8.2kg。并且受试者均未患有心血管疾病史,健康状况良好,实验前一天均保持至少八小时的充足睡眠。使受试者熟悉实验过程,以确保数据客观性。为了完成对生理数据运动情况下的噪声处理和人体生理疲劳检测两个内容,使受试者完成两次测试。基于两次测试获取的信号完成后续处理。
2)实验设备
本实验采用的设备为山西颐康鑫悦有限公司型号为BW-ECG-CHA的可穿戴心电采集设备,同为该公司型号为FHYDCSH1的可穿戴胸带呼吸采集设备,以及北京桂花网络科技有限公司研发的Cassia S2000蓝牙路由器,设备如图11所示。
3)实验过程
整体实验过程分如下几个步骤:
(1)向受试者解释实验目标和实验过程,确保他们理解每个步骤的内容和意义。
(2)统计所有受试者的基本信息,包括年龄,身高,体重,身体是否健康,有无心血管疾病史等。
(3)收集静息情况下的生理信号。使受试者佩戴好实验设备,静坐在椅子上十分钟,采集相应数据。
(4)收集运动情况下的生理信号。使受试者重复坐下-起立的动作,持续采集数据五分钟。休息二十分钟后,使受试者保持慢跑,持续采集数据五分钟。
(5)收集不同疲劳情况的生理信号。使受试者静坐十分钟后在操场上跑步,并每隔五分钟询问受试者的主观生理疲劳感受,疲劳感受分为三类:“不疲劳”,“一般疲劳”,“非常疲劳”,做好疲劳感受记录,作为数据标签。
数据分析与结论:
本发明模型的生理疲劳检测结果准确度,分为基于ELM网络检测人体生理疲劳的模型准确度和采用LSTM网络“后处理”的生理疲劳检测的准确度,并与其他研究所用方法准确度作比较。本发明采用绘制混淆矩阵的分析方法,并根据混淆矩阵计算出模型的准确率、精确率、召回率和特异度。
ELM模型和LSTM模型的生理疲劳检测分类结果混淆矩阵如图12和图13所示。
该模型的性能如表2所示
表2生理疲劳检测结果精确率、召回率和特异度
为了对比结果的准确性,本发明与其他研究的分类方法进行了比较,见表3,需要说明的是,本发明分类方法为三分类,其他大部分研究只进行疲劳和非疲劳二分类研究。
表3不同分类模型准确率
结果可见本发明的分类方法基于ELM模型进行初步生理疲劳检测结果准确率较低,仅为78.75%,但根据LSTM网络的“后处理”后,检测的准确率可达到88.89%,与其他研究的二分类结果准确度类似,高于其他研究的三分类结果准确率。整体具有较好的生理疲劳识别效果。