一种Hbase与Hdfs之间的数据抽取转换方法及系统
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及大数据处理技术领域,特别涉及一种Hbase与Hdfs之间的数据抽取转换方法及系统。
背景技术
在大数据时代的背景下,处理的数据都以T级PB级来进行计算,传统的技术对处理这样数量级的数据已经渐渐力不从心,应运而生的就是Hadoop集群和Hbase等新技术。例如现在广泛使用的云详单存储,详单存储在Hbase数据库中,但是需要对历史详单进行备份存储,就可以使用该工具将Hbase的数据存储Hdfs中,如果有必要也可以使用该工具将中Hdfs的数据还原到Hbase数据库中。
相比较而言,传统的关系型数据库具有以下缺点:
(1)关系数据库所采用的二维表格数据模型不能有效地处理多维数据,不能有效处理互联网应用中半结构化和非结构化的海量数据,如页面、电子邮件、音频、视频等;
(2)高并发读写的性能低。关系数据库达到一定规模时,非常容易发生死锁等并发问题,导致其读写性能下降非常严重。
网站数据库并发负载非常高,往往要达到每秒上万次读写请求。
(3)支撑容量有限。很多网站每天用户产生海量的用户动态信息。以Facebook为例,一个月就要存储1350亿条用户动态,对于关系数据库来说,在一张1350亿条记录的表里面进行查询,效率是极其低下乃至不可忍受的。
(4)数据库的可扩展性和可用性低。当一个应用系统的用户量和访问量与日俱增的时候,传统的关系型数据库却没有办法像Web Server那样简单地通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供不间断服务的系统来说,对数据库系统进行升级和扩展往往需要停机维护和数据迁移。
发明内容
本发明的目的是针对传统的关系型数据库的缺陷,提供一种一种Hbase与Hdfs之间的数据抽取转换方法及系统,可以快速的将Hbase中的数据备份到Hdfs中,也可以将中Hdfs备份的数据快速还原到Hbase中。
本发明的技术方案如下:
一种Hbase与Hdfs之间的数据抽取转换方法,其特征在于,包括以下步骤:
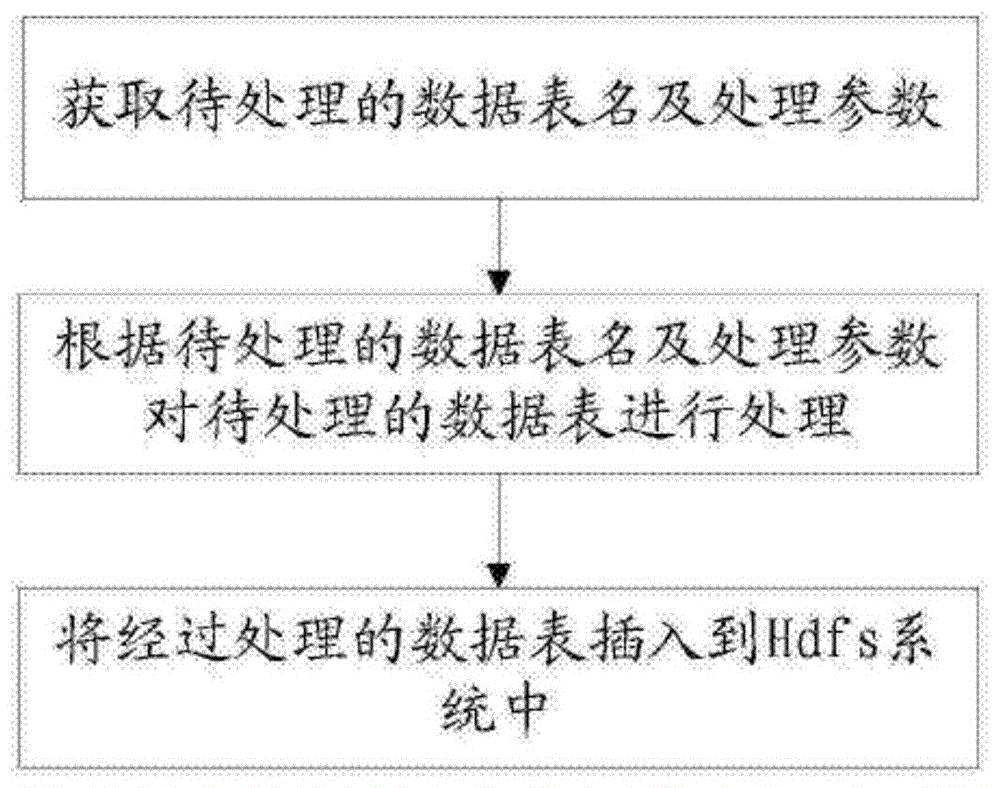
(1)获取待处理的数据表名及处理参数;
(2)根据待处理的数据表名及处理参数对待处理的数据表进行处理;
(3)将经过处理的数据表插入到Hdfs系统中。
上述步骤(2)中,对待处理的数据表进行处理,具体方式是:根据待处理的数据表名及处理参数对待处理的数据表进行抽取或转换。
所述根据待处理的数据表名及处理参数对待处理的数据表进行抽取,具体为抽取参数或者合并参数。
所述根据待处理的数据表名及抽取参数利用map函数进行抽取,并将抽取得到的数据表存入系统中。
所述根据待处理的数据表名及处理参数对待处理的数据表进行转换,具体为将抽取的数据表利用map函数进行切分,得到多个数据库块将所有数据块传递给函数reduce进行合并处理,得到合并数据库块。
一种Hbase与Hdfs之间的数据抽取转换系统,其特征在于,包括获取模块、处理模块和插入模块;所述获取模块,用于获取待处理的数据表名及处理参数;所述处理模块,用于根据待处理的数据表名及处理参数对待处理的数据表进行处理;所述插入模块,用于将经过处理的数据表插入到系统中。
所述处理模块具体用于根据待处理的数据表名及处理参数对待处理的数据表进行抽取或转换。
所述处理参数为抽取参数或者合并参数。
根据待处理的数据表名及处理参数对待处理的数据表进行抽取,具体为根据待处理的数据表名及抽取参数利用map函数进行抽取,并将抽取得到的数据表存入Hdfs系统中。
根据待处理的数据表名及处理参数对待处理的数据表进行转换,具体为将抽取的数据表利用map函数进行切分,得到多个数据库块将所有数据块传递给reduce函数进行合并处理,得到合并数据库块。
本发明可以将历史的数据抽取保存到Hdfs分布式文件系统当中,当需要历史数据的时候,又可以把Hdfs中的数据恢复到Hbase中,根据环境的不同通过配置的修改来实现数据的抽取备份保存,同时还不影响到生成Hbase的正常使用。
附图说明
图1为本发明方法步骤流程图;
图2为本发明系统结构图。
具体实施方式
如图1所示,本发明提供的一种Hbase与Hdfs之间的数据抽取转换方法,包括以下步骤:
(1)获取待处理的数据表名及处理参数;
(2)根据待处理的数据表名及处理参数对待处理的数据表进行处理;
(3)将经过处理的数据表插入到Hdfs系统中。
上述方法中,所述根据待处理的数据表名及处理参数对待处理的数据表进行处理,具体为,根据待处理的数据表名及处理参数对待处理的数据表进行抽取或转换。
所述处理参数为抽取参数或者合并参数。
所述根据待处理的数据表名及处理参数对待处理的数据表进行抽取,具体为根据待处理的数据表名及抽取参数利用map函数进行抽取,并将抽取得到的数据表存入Hdfs系统中。
所述根据待处理的数据表名及处理参数对待处理的数据表进行转换,具体为将抽取的数据表利用map函数进行切分,得到多个数据库块将所有数据块传递给reduce函数进行合并处理,得到合并数据库块。
如图2所示,本发明提供的一种与之间的数据抽取转换系统,包括获取模块1、处理模块2和插入模块3;
所述获取模块1,用于获取待处理的数据表名及处理参数;
所述处理模块2,用于根据待处理的数据表名及处理参数对待处理的数据表进行处理;
所述插入模块,用于将经过处理的数据表插入到Hdfs系统中。
所述处理模块2具体用于根据待处理的数据表名及处理参数对待处理的数据表进行抽取或转换。
所述处理参数为抽取参数或者合并参数。
根据待处理的数据表名及处理参数对待处理的数据表进行抽取,具体为根据待处理的数据表名及抽取参数利用map函数进行抽取,并将抽取得到的数据表存入Hdfs系统中。
根据待处理的数据表名及处理参数对待处理的数据表进行转换,具体为将抽取的数据表利用map函数进行切分,得到多个数据库块将所有数据块传递给reduce函数进行合并处理,得到合并数据库块。
本发明是采用MapReduce框架进行开发,所以该工具在抽取数据时也是分布式运算,所以保证了抽取的效率。同时可以根据传递的参数进行配置修改抽取的表、输出文件的压缩格式,根据集群环境的配置对MapReduce程序执行进行调优的配置,达到一个合理的抽取速度,在不影响生产的情况下达到最高的速度进行抽取。
- 一种Hbase与Hdfs之间的数据抽取转换方法及系统
- 一种基于HDFS海量数据快速导入HBase的方法