一种植物耐盐碱性相关的HB20蛋白质及其相关生物材料与应用
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及生物技术领域中一种植物耐盐碱性相关的HB20蛋白质及其相关生物材料与应用。
背景技术
世界范围内盐碱地分布广泛,种类众多,这将耕地增效,粮食增产的现实来源。因此,合理有效的开发利用盐碱地资源,对农业可持续发展具有重要意义。目前,大量研究学者使用农艺措施、化学措施以及生物措施等方面技术,开展了对盐碱地的改良和治理工作,其中生物措施主要包括通过品种改良,提高植物抗盐碱能力,从而降低盐碱胁迫对植物造成的危害。阐明植物响应盐碱胁迫的作用机理可以为开展的品种改良工作提供指导和方向,有助于盐碱地资源的有效利用。
发明内容
本发明所要解决的技术问题是如何提高植物抗盐碱能力。
本发明提供了一种蛋白质,名称为HB20,是如下A1)、A2)或A3)的蛋白质:
A1)氨基酸序列是序列表中序列3的蛋白质;
A2)将A1)的蛋白质经过一个或几个氨基酸残基的取代和/或缺失和/或添加得到的与A1)所示的蛋白质具有90%以上的同一性且具有相同活性的蛋白质;
A3)在A1)或A2)的N末端或/和C末端连接蛋白质标签得到的融合蛋白质。
上述蛋白质可人工合成,也可先合成其编码基因,再进行生物表达得到。
上述蛋白质中,所述蛋白质标签(protein-tag)是指利用DNA体外重组技术,与目的蛋白质一起融合表达的一种多肽或者蛋白质,以便于目的蛋白质的表达、检测、示踪和/或纯化。所述蛋白质标签可为Flag标签、His标签、MBP标签、HA标签、myc标签、GST标签和/或SUMO标签等。
上述蛋白质中,同一性是指氨基酸序列的同一性。可使用国际互联网上的同源性检索站点测定氨基酸序列的同一性,如NCBI主页网站的BLAST网页。例如,可在高级BLAST2.1中,通过使用blastp作为程序,将Expect值设置为10,将所有Filter设置为OFF,使用BLOSUM62作为Matrix,将Gap existence cost,Perresidue gap cost和Lambda ratio分别设置为11,1和0.85(缺省值)并进行检索一对氨基酸序列的同一性进行计算,然后即可获得同一性的值(%)。
上述蛋白质中,所述90%以上的同一性可为至少91%、92%、95%、96%、98%、99%或100%的同一性。
与HB20相关的生物材料也属于本发明的保护范围。
本发明所提供的与蛋白质HB20相关的生物材料,为下述B1)至B5)中的任一种:
B1)编码HB20的核酸分子;
B2)含有B1)所述核酸分子的表达盒;
B3)含有B1)所述核酸分子的重组载体、或含有B1)所述表达盒的重组载体;
B4)含有B1)所述核酸分子的重组微生物、或含有B2)所述表达盒的重组微生物、或含有B3)所述重组载体的重组微生物;
B5)含有B1)所述核酸分子的转基因植物细胞系、或含有B2)所述表达盒的转基因植物细胞系、或含有B3)所述重组载体的转基因植物细胞系。
其中,所述核酸分子可以是DNA,如cDNA、基因组DNA或重组DNA;所述核酸分子也可以是RNA,如mRNA或hnRNA等。
上述生物材料中,B1)所述核酸分子为如下b1)或b2)所示的基因:
b1)编码链的编码序列是序列表中序列2的cDNA分子或DNA分子;
b2)编码链的核苷酸是序列表中序列2的cDNA分子或DNA分子。
其中,序列表中的序列2由861个核苷酸组成,编码序列表中的序列3所示的蛋白质。
上述生物材料中,B2)含有B1)所述核酸分子的表达盒(HB20基因表达盒),是指能够在宿主细胞中表达HB20的核酸分子,该核酸分子可包括启动HB20基因转录的启动子。可用于本发明的启动子包括但不限于:组成型启动子,组织、器官和发育特异的启动子,和诱导型启动子。启动子的例子包括但不限于:HB20基因的启动子(序列表序列4);花椰菜花叶病毒的组成型启动子35S;来自西红柿的创伤诱导型启动子,亮氨酸氨基肽酶("LAP",Chao等人(1999)Plant Physiology 120:979-992);来自烟草的化学诱导型启动子,发病机理相关1(PR1)(由水杨酸和BTH(苯并噻二唑-7-硫代羟酸S-甲酯)诱导);西红柿蛋白质酶抑制剂II启动子(PIN2)或LAP启动子(均可用茉莉酮酸曱酯诱导);热休克启动子(美国专利5,187,267);四环素诱导型启动子(美国专利5,057,422);种子特异性启动子,如谷子种子特异性启动子pF128(CN101063139B(中国专利200710099169.7)),种子贮存蛋白质特异的启动子(例如,菜豆球蛋白质、napin,oleosin和大豆beta conglycin的启动子(Beachy等人(1985)EMBO J.4:3047-3053))。它们可单独使用或与其它的植物启动子结合使用。此处引用的所有参考文献均全文引用。
上述生物材料中,B2)所述的含有所述核酸分子的表达盒还可包括终止HB20转录的终止子。进一步,所述表达盒还可包括增强子序列。合适的转录终止子包括但不限于:农杆菌胭脂碱合成酶终止子(NOS终止子)、花椰菜花叶病毒CaMV 35S终止子、tml终止子、豌豆rbcS E9终止子和胭脂氨酸和章鱼氨酸合酶终止子(参见,例如:Odell等人(I
可用现有的植物表达载体构建含有所述HB20基因表达盒的重组表达载体。所述植物表达载体包括双元农杆菌载体和可用于植物微弹轰击的载体等。如pMDC99、pAHC25、pWMB123、pBin438、pCAMBIA1302、pCAMBIA2301、pCAMBIA1301、pCAMBIA1300、pBI121、pCAMBIA1391-Xa或pCAMBIA1391-Xb(CAMBIA公司)等。所述植物表达载体还可包含外源基因的3’端非翻译区域,即包含聚腺苷酸信号和任何其它参与mRNA加工或基因表达的DNA片段。所述聚腺苷酸信号可引导聚腺苷酸加入到mRNA前体的3’端,如农杆菌冠瘿瘤诱导(Ti)质粒基因(如胭脂碱合成酶基因Nos)、植物基因(如大豆贮存蛋白质基因)3’端转录的非翻译区均具有类似功能。使用本发明的基因构建植物表达载体时,还可使用增强子,包括翻译增强子或转录增强子,这些增强子区域可以是ATG起始密码子或邻接区域起始密码子等,但必需与编码序列的阅读框相同,以保证整个序列的正确翻译。所述翻译控制信号和起始密码子的来源是广泛的,可以是天然的,也可以是合成的。翻译起始区域可以来自转录起始区域或结构基因。为了便于对转基因植物细胞或植物进行鉴定及筛选,可对所用植物表达载体进行加工,如加入可在植物中表达的编码可产生颜色变化的酶或发光化合物的基因(GUS基因、萤光素酶基因等)、抗生素的标记基因(如赋予对卡那霉素和相关抗生素抗性的nptII基因,赋予对除草剂膦丝菌素抗性的bar基因,赋予对抗生素潮霉素抗性的hph基因,和赋予对methatrexate抗性的dhfr基因,赋予对草甘磷抗性的EPSPS基因)或是抗化学试剂标记基因等(如抗除莠剂基因)、提供代谢甘露糖能力的甘露糖-6-磷酸异构酶基因。从转基因植物的安全性考虑,可不加任何选择性标记基因,直接以逆境筛选转化植株。
上述生物材料中,所述重组微生物具体可为酵母,细菌,藻和真菌。
本发明还提供一种通过抑制上述HB20蛋白质的表达提高植物耐盐碱性的方法,包括如下步骤:抑制受体植物中HB20蛋白质的表达,得到耐盐碱性高于所述受体植物的目的植物。
所述受体植物可为单子叶植物或双子叶植物。所述双子叶植物可为拟南芥。
上述方法中,所述抑制受体植物中HB20蛋白质的表达是通过对受体植物中编码HB20蛋白质的基因进行化学诱变、物理诱变、RNAi、基因组定点编辑或同源重组实现的。
上述方法中,所述基因编辑可采用锌指核酸酶技术(Zinc fingernuclease,ZFN)、类转录激活因子效应物核酸酶技术(Transcription activator-like effectornuclease,TALEN)、成簇的规律间隔的短回文重复序列及其相关系统技术(Clusteredregularly interspaced shortpalindromic repeats/CRISPR associated,CRISPR/Cas9系统),以及其它能实现基因组定点编辑的技术实现的。
为了解决上述技术问题,本发明还提供了植物试剂,其作用为提高植物的耐盐碱性。本发明所提供的植物试剂含有抑制上述HB20蛋白质表达的物质。
为了解决上述技术问题,本发明还提供了一种培育盐碱敏感植物的方法。
本发明所提供的培育盐碱敏感植物的方法,包括将编码所述蛋白质的核酸分子导入目的植物中,得到盐碱敏感植物;所述盐碱敏感植物对盐碱的敏感性高于所述目的植物对盐碱的敏感性。
所述盐碱敏感植物可用作盐碱指示植物。
所述目的植物可为单子叶植物或双子叶植物。所述双子叶植物可为拟南芥。
上述方法中,其中所述的核酸分子可先进行如下修饰,再导入目的植物中,以达到更好的表达效果:
1)修饰邻近起始甲硫氨酸的基因序列,以使翻译有效起始;例如,利用在植物中已知的有效的序列进行修饰;
2)与各种植物表达的启动子连接,以利于其在植物中的表达;所述启动子可包括组成型、诱导型、时序调节、发育调节、化学调节、组织优选和组织特异性启动子;启动子的选择将随着表达时间和空间需要而变化,而且也取决于靶物种;例如组织或器官的特异性表达启动子,根据需要受体在发育的什么时期而定;尽管证明了来源于双子叶植物的许多启动子在单子叶植物中是可起作用的,反之亦然,但是理想地,选择双子叶植物启动子用于双子叶植物中的表达,单子叶植物的启动子用于单子叶植物中的表达;
3)与适合的转录终止子连接,也可以提高本发明基因的表达效率;例如来源于CaMV的tml,来源于rbcS的E9;任何已知在植物中起作用的可得到的终止子都可以与本发明基因进行连接;
4)引入增强子序列,如内含子序列(例如来源于Adhl和bronzel)和病毒前导序列(例如来源于TMV,MCMV和AMV)。
所述的核酸分子可通过使用Ti质粒,植物病毒栽体,直接DNA转化,微注射,电穿孔等常规生物技术方法导入植物细胞(Weissbach,1998,Method for Plant MolecularBiology VIII,Academy Press,New York,pp.411-463;Geiserson and Corey,1998,PlantMolecularBiology(2nd Edition)。
上述方法中,所述盐碱敏感植物可为转基因植物,也可为通过杂交等常规育种技术获得的植物。
上述方法中,所述转基因植物理解为不仅包含第一代到第二代转基因植物,也包括其子代。对于转基因植物,可以在该物种中繁殖该基因,也可用常规育种技术将该基因转移进入相同物种的其它品种,特别包括商业品种中。所述转基因植物包括种子、愈伤组织、完整植株和细胞。
HB20基因缺失的拟南芥突变体hb20的盐碱胁迫实验,以及将HB20基因导入突变体hb20的转基因实验证明,抑制HB20基因的表达,能提高植物盐碱性,而在HB20基因缺失的突变体中表达HB20其耐盐碱性恢复至与野生型Col-0相当。因此,通过合理利用HB20基因可以调控植物耐盐碱性,有助于盐碱地资源的有效利用。
附图说明
图1是实施例1中分析盐碱胁迫相关基因的流程图。
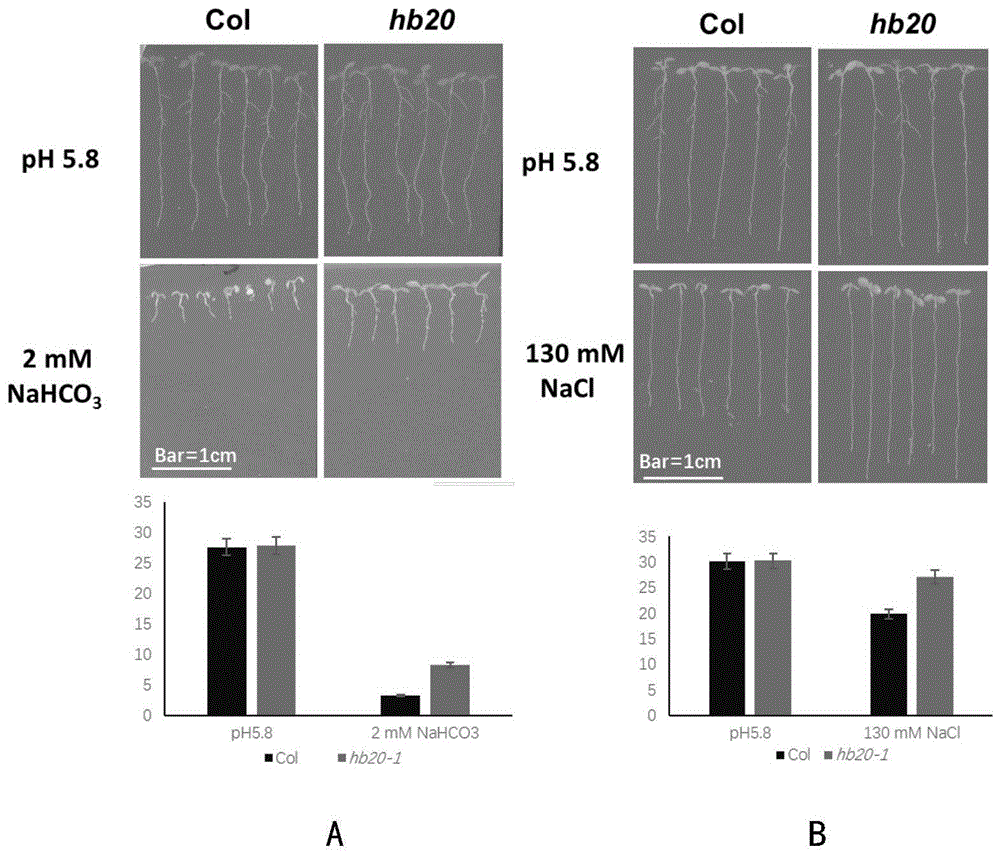
图2是实施例2中HB20基因缺失的突变体hb20在盐碱胁迫下根的表型特征图。
其中,图2的A图是高NaHCO
图3是实施例3中在拟南芥HB20基因缺失突变体hb20中表达HB20的株系及相应突变体对照和野生型对照在正常和130mM NaCl胁迫条件下的根系表型照片。
图4是实施例3中在拟南芥HB20基因缺失突变体hb20中表达HB20的株系及相应突变体对照和野生型对照的主根长度在正常和130mM NaCl胁迫条件下统计图,其中,数据表示为平均值±标准差,重复数为10以上。
图5是实施例3中在拟南芥HB20基因缺失突变体hb20中表达HB20的株系及相应突变体对照和野生型对照在正常和2mM NaHCO
图6是实施例3中在拟南芥HB20基因缺失突变体hb20中表达HB20的株系及相应突变体对照和野生型对照在正常和2mM NaHCO
具体实施方式
下面结合具体实施方式对本发明进行进一步的详细描述,给出的实施例仅为了阐明本发明,而不是为了限制本发明的范围。以下提供的实施例可作为本技术领域普通技术人员进行进一步改进的指南,并不以任何方式构成对本发明的限制。
下述实施例中的实验方法,如无特殊说明,均为常规方法。下述实施例中所用的材料、试剂等,如无特殊说明,均为常规生化试剂,可从商业途径得到。
1载体
下述实施例中载体pMDC99记载于非专利文献“X.Yu et al.,Plastid-localizedglutathione reductase 2-regulated glutathione redox status is essential forArabidopsis root apical meristem maintenance.Plant Cell 25,4451-4468(2013).”,公众可以从山东农业大学所获得,以重复本申请实验,不可作为其它用途使用。
2植物品系
下述实施例中的突变体hb20(货号:SALK_064208、SALK_064218)为NottinghamArabidopsis Stock Centre(NASC)产品,为在拟南芥野生型Col-0的基础上发生了HB20基因缺失突变的拟南芥突变体。
下述实施例中,野生型拟南芥(Arabidopsis thaliana)Columbia-0亚型下文中简称野生型拟南芥Col-0,载于非专利文献“Kim H,Hyun Y,Park J,Park M,Kim M,Kim H,LeeM,Moon J,Lee I,Kim J.A genetic linkbetween cold responses and flowering timethroughFVE inArabidopsis thaliana.Nature Genetics.2004,36:167-171”,公众可以从山东农业大学所获得,以重复本申请实验,不可作为其它用途使用。
下述实施例中,如无特殊说明,序列表中各核苷酸序列的第1位均为相应DNA的5′末端核苷酸,末位均为相应DNA的3′末端核苷酸。
实施例1、拟南芥HB20基因的获得
发明人按照图1的流程,前期通过利用236种拟南芥生态型材料,测定盐碱胁迫下的根发育相关性状,进行全基因组关联分析,获得一个与根长性状具有显著性关联的SNP位点,根据此SNP位点附近2kb内寻找基因,发现了基因座位号AT3G01220(Tair数据库)的HB20基因,根据相关生物信息学分析析发现此基因能够响应盐碱胁迫。
从拟南芥野生型Col-0克隆得到拟南芥HB20基因,该基因由2233个核苷酸组成,基因组序列如序列表序列1所示。T01转录本的读码框为序列表序列1第293位到第2233位核苷酸,具体如下:序列表序列1第293位到第431位核苷酸为第一外显子,第432位到第507位核苷酸为第一内含子,第508位到第893位核苷酸为第二外显子,第894位到第1653位核苷酸为第二内含子,第1654位到第1989位核苷酸为第三外显子,第1990位到第2233位核苷酸为3’UTR。HB20基因的cDNA序列如序列表中序列2所示,其编码的蛋白名为HB20,HB20含有286个氨基酸残基(如序列表序列3所示)。
从拟南芥野生型Col-0克隆得到拟南芥HB20基因的启动子,其核苷酸序列如序列表的序列4所示。
实施例2、拟南芥HB20基因缺失突变体hb20在盐碱胁迫下的表型特征
实验材料为HB20基因缺失的突变体hb20,以拟南芥野生型Col-0为对照,进行盐碱胁迫,具体为高NaHCO
高NaHCO
基础对照:pH值为5.8的1/2MS固体培养基。
高NaHCO
设置15个重复,处理7天后,测定主根长度(单位为mm),结果见图2的A图,表明HB20基因缺失的突变体hb20在高NaHCO
高NaCl实验:
基础对照:pH值为5.8的1/2MS固体培养基。
高NaCl处理:在pH值为5.8的1/2MS固体培养基的基础上添加NaCl,使其浓度为130mM。
设置15个重复,处理7天后,测定主根长度(单位为mm),结果见图2的B图,表明HB20基因缺失的突变体hb20在高NaCl条件下主根比野生型显著变长,有明显的抗性表型。
综上,hb20突变体在2mM NaHCO
实施例3、在拟南芥HB20基因缺失突变体hb20中表达HB20
以拟南芥HB20基因缺失突变体hb20为受体,表达HB20基因,具体步骤如下:
1、HB20蛋白重组表达载体的构建
以载体pDONR207为入门载体,以载体pMDC99为终载体,根据HB20基因的基因组序列(序列表序列1)和HB20基因的启动子序列(序列表序列4),构建HB20蛋白重组表达载体,具体如下:
提取拟南芥野生型Col-0的基因组DNA作为模板,在第一轮PCR引物和第一轮PCR引物引导下进行两轮PCR扩增,第一轮PCR目的为扩增目标基因序列,同时引入第二轮PCR的同源序列,第二轮PCR扩增第一轮PCR产物,同时引入载体同源序列。
引物序列如下:
第一轮PCR
上游引物:5’-TCCCCGGGTACCTATCCTTGTGGTTACGTTGCTCA-3’;
下游引物:5’-CGAATTCGAGCTCGTTACGGCCGAATGCAAAGAACT-3’。
第一轮PCR结束后使用1%琼脂糖凝胶电泳检测,回收并纯化PCR产物。将得到的纯化产物,进行第二轮PCR。
第二轮PCR
上游引物:5’-TCTAGAGGATCCCCGGGTACC-3’;
下游引物:5’-CATGATTACGAATTCGAGCTC-3’。
第二轮PCR产物使用1%琼脂糖凝胶电泳检测,进行胶回收。pMDC99载体使用Kpn1和Sac1进行双酶切,使用1%琼脂糖凝胶电泳检测后进行回收。使用ExnaseⅡ酶进行重组反应。
最终得到HB20蛋白的重组表达载体,命名为pMDC99-HB20。
pMDC99-HB20的结构描述如下:pMDC99-HB20含有由HB20基因启动子与HB20基因,HB20基因启动子驱动HB20基因的表达,HB20基因启动子的序列为序列表的序列4所示的序列,HB20基因的序列为序列表的序列1所示的序列。
2、在拟南芥HB20基因缺失突变体hb20中表达HB20
将pMDC99-HB20在根癌农杆菌GV3101 Agrobacterium Strain的介导下转化hb20突变体。然后用含有0.05mg/ml潮霉素的1/2MS培养基进行抗性筛选,筛选得到能在含潮霉素培养基上生长的转基因植株。用测序引物对筛选得到的转基因植株进行PCR鉴定,得到转入pMDC99-HB20的株系,通过继代及相关鉴定,获得转入pMDC99-HB20的T4代纯系株系,命名为HB20pro:gHB20/hb20。
3、对转入HB20基因片段的转基因株系进行表型分析
高NaCl实验:
将拟南芥野生型Col-0,突变体hb20和转入HB20基因片段的转基因株系HB20pro:gHB20/hb20在pH值为5.8的1/2MS固体培养基中培养至萌发后4天,进行如下处理(各处理重复数为10以上):
基础对照:pH值为5.8的1/2MS固体培养基。
高NaCl处理:在pH值为5.8的1/2MS固体培养基的基础上添加NaCl,使其浓度为130mM。
继续培养4天,主根根长如图3所示,其显著性分析结果见图4。结果表明,转入pMDC99-HB20的hb20突变体株系HB20pro:gHB20/hb20的根长表型恢复至与野生型Col-0相当。表明HB20基因的突变影响植物在盐碱胁迫下的根系发育。
高NaHCO
将拟南芥野生型Col-0,突变体hb20和转入HB20基因片段的转基因株系HB20pro:gHB20/hb20在pH值为5.8的1/2MS固体培养基和2mM NaHCO
高NaHCO
主根根长如图5所示,其显著性分析结果见图6。结果表明,转入pMDC99-HB20的hb20突变体株系HB20pro:gHB20/hb20的根长表型恢复至与野生型Col-0相当。表明HB20基因的突变影响植物在盐碱胁迫下的根系发育。
综上,抑制HB20基因的表达,能提高植物盐碱性,而在HB20基因缺失的突变体中表达HB20其耐盐碱性恢复至与野生型Col-0相当。因此,通过合理利用HB20基因可以调控植物耐盐碱性,有助于盐碱地资源的有效利用。
以上对本发明进行了详述。对于本领域技术人员来说,在不脱离本发明的宗旨和范围,以及无需进行不必要的实验情况下,可在等同参数、浓度和条件下,在较宽范围内实施本发明。虽然本发明给出了特殊的实施例,应该理解为,可以对本发明作进一步的改进。总之,按本发明的原理,本申请欲包括任何变更、用途或对本发明的改进,包括脱离了本申请中已公开范围,而用本领域已知的常规技术进行的改变。按以下附带的权利要求的范围,可以进行一些基本特征的应用。
序列表
<110>山东农业大学
<120>一种植物耐盐性相关的HB20蛋白质及其相关生物材料与应用
<130>GNCSY210352
<160>4
<170>SIPOSequenceListing 1.0
<210>1
<211>2233
<212>DNA
<213>拟南芥(Arabidopsis thaliana)
<400>1
cagaaactat aaaataactt tattacatga actggagaat atatatgaaa tataataata60
agcctaaagc ttttaaaata ttaaggatgg gtcctagaaa cctccctagc ttgatccttt 120
cctcattctt tctctctctt tctcttatat gagaggttga tgagatccac aagaaacacc 180
taactcattt gatagtgatt tccaaatctg caaacaacaa agtatatttg atcatcacta 240
tactgatttc acaatccatt aatcactgat aggtttttgg tggaatacat acatgtatgt 300
gtttgatcca acaacagaag ctggattgag attagagatg gcgtttcctc aacatggttt 360
tatgttccaa caacttcatg aagacaacag tcaagatcag ctcccttctt gtcctcctca 420
tctcttcaat ggtactatac tctctctttc tctcactatt tctccacata aatagatttg 480
agtcatgaat tctgttggtg tatataggag gaggaaacta catgatgaac agatctatgt 540
ctttaatgaa cgtgcaagaa gatcataatc aaaccttgga tgaggagaat ctatcagacg 600
atggggcaca tactatgctg ggagagaaga agaagaggct gcaattagag caagttaagg 660
cattagagaa gagctttgag cttggtaaca agctggagcc agagaggaag atacaactag 720
ctaaagcatt agggatgcaa ccaagacaga tcgcgatttg gtttcaaaac aggagagcta 780
ggtggaagac tagacagctc gagagagatt atgattcact caagaaacag tttgagtctc 840
ttaaatccga caatgcttct ctacttgcct ataacaagaa actccttgct gaggtatgta 900
tctatataag taagtatata tgtgtgttta tatagtaaat aaggtgttta attcaacttt 960
catttctaat ttgattgtgt ttgttttttt ctttggtttt tttatttttg gttttgcact1020
aatagtaata accaacgtaa aataaatcta ggactacaaa tatttttctg attattggct1080
tggattggta ctatttatgt agtatatata tatgtgtata tatatcagtg tatatatata1140
tatatatgta tgtatcttgt gtgtattaaa gtcgtttaat acgaaatgca atagattatt1200
gttaggcaca tgatccaaca ctataagatg tttgtcaaaa gacagtaggt gttttgttta1260
ttaataaaaa ggattcttga tcaatattta caatttaatt aatacattcc catatgacta1320
tcaagtaatg gcatgtgtgc gctaaccaaa tttgacaaga atactgattt ttatatcata1380
tcatttttgt gtgttttaaa tgattttact acttattgaa atgtaatagt tacaagattt1440
tcaaaaatta cttaagctaa gtatatgtaa atatataatt tacatatata gtcttacagt1500
ttatctattt taagttatta gtcattttaa aaatattttg ttaatttaaa ttatatataa1560
ttatgtttat tttaatgata tatagaaatg ataattttta atatctgaat ttctaaaact1620
taacatttga attgtgtgtg atgatggtta aaggtaatgg ctttaaagaa caaagaatgt1680
aatgaaggaa acatagtaaa gagagaagca gaagcttcat ggagcaacaa cggaagcaca1740
gagaatagtt cagacatcaa tctggagatg cctagagaga ccattacaac acatgtgaac1800
acgatcaaag acctattccc ttcatcgatt cgatcatctg cacatgatga tgatcatcat1860
cagaatcatg aaatagttca agaagaaagc ctttgtaaca tgtttaatgg cattgatgaa1920
acgacgccgg ctggttactg ggcatggtct gacccaaacc acaaccacca ccaccaccag1980
ttcaactgat tcatgattct aaagctcaaa aaaaagtcat cagcacgcat caagacaaat2040
gatcataatc atcatcatca tatcatcagg agaagatcaa gacacaattc ttctctttgg2100
aattatgtta ttgctactca tttcaattta aattaatgga gcattttgtt ttctttgggt2160
ttgtagagca ttggtgtata gtgcgaaaat ttgttgttgc tttaatttaa taaaaatcat2220
aaagttcttt gca 2233
<210>2
<211>1397
<212>DNA
<213>人工序列(Artificial Sequence)
<400>2
cagaaactat aaaataactt tattacatga actggagaat atatatgaaa tataataata60
agcctaaagc ttttaaaata ttaaggatgg gtcctagaaa cctccctagc ttgatccttt 120
cctcattctt tctctctctt tctcttatat gagaggttga tgagatccac aagaaacacc 180
taactcattt gatagtgatt tccaaatctg caaacaacaa agtatatttg atcatcacta 240
tactgatttc acaatccatt aatcactgat aggtttttgg tggaatacat acatgtatgt 300
gtttgatcca acaacagaag ctggattgag attagagatg gcgtttcctc aacatggttt 360
tatgttccaa caacttcatg aagacaacag tcaagatcag ctcccttctt gtcctcctca 420
tctcttcaat ggaggaggaa actacatgat gaacagatct atgtctttaa tgaacgtgca 480
agaagatcat aatcaaacct tggatgagga gaatctatca gacgatgggg cacatactat 540
gctgggagag aagaagaaga ggctgcaatt agagcaagtt aaggcattag agaagagctt 600
tgagcttggt aacaagctgg agccagagag gaagatacaa ctagctaaag cattagggat 660
gcaaccaaga cagatcgcga tttggtttca aaacaggaga gctaggtgga agactagaca 720
gctcgagaga gattatgatt cactcaagaa acagtttgag tctcttaaat ccgacaatgc 780
ttctctactt gcctataaca agaaactcct tgctgaggta atggctttaa agaacaaaga 840
atgtaatgaa ggaaacatag taaagagaga agcagaagct tcatggagca acaacggaag 900
cacagagaat agttcagaca tcaatctgga gatgcctaga gagaccatta caacacatgt 960
gaacacgatc aaagacctat tcccttcatc gattcgatca tctgcacatg atgatgatca1020
tcatcagaat catgaaatag ttcaagaaga aagcctttgt aacatgttta atggcattga1080
tgaaacgacg ccggctggtt actgggcatg gtctgaccca aaccacaacc accaccacca1140
ccagttcaac tgattcatga ttctaaagct caaaaaaaag tcatcagcac gcatcaagac1200
aaatgatcat aatcatcatc atcatatcat caggagaaga tcaagacaca attcttctct1260
ttggaattat gttattgcta ctcatttcaa tttaaattaa tggagcattt tgttttcttt1320
gggtttgtag agcattggtg tatagtgcga aaatttgttg ttgctttaat ttaataaaaa1380
tcataaagtt ctttgca 1397
<210>3
<211>286
<212>PRT
<213>拟南芥(Arabidopsis thaliana)
<400>3
Met Tyr Val Phe Asp Pro Thr Thr Glu Ala Gly Leu Arg Leu Glu Met
1 5 1015
Ala Phe Pro Gln His Gly Phe Met Phe Gln Gln Leu His Glu Asp Asn
202530
Ser Gln Asp Gln Leu Pro Ser Cys Pro Pro His Leu Phe Asn Gly Gly
354045
Gly Asn Tyr Met Met Asn Arg Ser Met Ser Leu Met Asn Val Gln Glu
505560
Asp His Asn Gln Thr Leu Asp Glu Glu Asn Leu Ser Asp Asp Gly Ala
65707580
His Thr Met Leu Gly Glu Lys Lys Lys Arg Leu Gln Leu Glu Gln Val
859095
Lys Ala Leu Glu Lys Ser Phe Glu Leu Gly Asn Lys Leu Glu Pro Glu
100 105 110
Arg Lys Ile Gln Leu Ala Lys Ala Leu Gly Met Gln Pro Arg Gln Ile
115 120 125
Ala Ile Trp Phe Gln Asn Arg Arg Ala Arg Trp Lys Thr Arg Gln Leu
130 135 140
Glu Arg Asp Tyr Asp Ser Leu Lys Lys Gln Phe Glu Ser Leu Lys Ser
145 150 155 160
Asp Asn Ala Ser Leu Leu Ala Tyr Asn Lys Lys Leu Leu Ala Glu Val
165 170 175
Met Ala Leu Lys Asn Lys Glu Cys Asn Glu Gly Asn Ile Val Lys Arg
180 185 190
Glu Ala Glu Ala Ser Trp Ser Asn Asn Gly Ser Thr Glu Asn Ser Ser
195 200 205
Asp Ile Asn Leu Glu Met Pro Arg Glu Thr Ile Thr Thr His Val Asn
210 215 220
Thr Ile Lys Asp Leu Phe Pro Ser Ser Ile Arg Ser Ser Ala His Asp
225 230 235 240
Asp Asp His His Gln Asn His Glu Ile Val Gln Glu Glu Ser Leu Cys
245 250 255
Asn Met Phe Asn Gly Ile Asp Glu Thr Thr Pro Ala Gly Tyr Trp Ala
260 265 270
Trp Ser Asp Pro Asn His Asn His His His His Gln Phe Asn
275 280 285
<210>4
<211>1414
<212>DNA
<213>拟南芥(Arabidopsis thaliana)
<400>4
tatccttgtg gttacgttgc tcaagtcacc aacttgtctc ctcaagccac tgagaaagat60
gttcataggt tcttctctca ctgtggtatc gtcgagctcg ttgaaatcac cgggtaacaa 120
caacgttcat tgttcagtaa attattaatc attcttgaat ctgtttatat tttgtttcat 180
gtctccatgg atttcaggtg ccaaggggat gcattaacgg cttatgtaac cttcagagat 240
gcgtatgctc tggatatggc tgtgttactt agcgtaagtc ccttaattag ctagaaattt 300
ccagtatgat cttcttggca ttgattttaa tgttgatctt cagggagcta cgatcgttga 360
tcaaaccgtt tggatatcgg tctacggtgt ctatttacat gaatctaaca atctcagaca 420
agaagaagac tatagtgtta cggtaacatt aaaaacaata cttactaggt tactttaggt 480
tataagccaa agattctcga aaatgtttct ttgtaggtga ctcgttcaga cgcgtttgct 540
tcatcgcctg gagaggccat aaccgtggct caacaagttg tgcagacgat gttagctaaa 600
ggctacgttt taagcaaaga cgcgattggt aaagccaaag ctttggatga gtctcagaga 660
ttttcaagct tggtagcgac caaattggca gagatcagcc attaccttgg cctcacacag 720
aacattcagt cgagtatgga actcgtgaga tcagcggacg agaagtatca tttctcggat 780
ttcactaaat ccgcggttct tgtcacgggc acagctgctg tagccgcagc caccattaca 840
gggaaagtgg ctgcagctgc agcgactagt gtggtcaaca gtcgttactt tgctaatggg 900
gctttatggt tctcagatgc tttgggccgg gctgcaaaag cagcggccca tatcggtgga 960
ggaggaagca attgatgtaa aaagtctttg ggcttccttg gaaaacataa ataaatgata1020
tgtgaggttt taaagcataa aaggtgttgt gaaaagaaaa agaaaaaaaa aaccatcatg1080
aagatatgat tagtaacgtt acatgatcga aaatatttga ggcagaaact ataaaataac1140
tttattacat gaactggaga atatatatga aatataataa taagcctaaa gcttttaaaa1200
tattaaggat gggtcctaga aacctcccta gcttgatcct ttcctcattc tttctctctc1260
tttctcttat atgagaggtt gatgagatcc acaagaaaca cctaactcat ttgatagtga1320
tttccaaatc tgcaaacaac aaagtatatt tgatcatcac tatactgatt tcacaatcca1380
ttaatcactg ataggttttt ggtggaatac atac1414
- 一种与植物氮的吸收利用相关的SiTGAL5蛋白质及其相关生物材料与应用
- 一种植物耐盐性相关的LIP1蛋白质及其相关生物材料与应用