大数据视野下的年鉴行政区划信息匹配方法和模型
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及大数据处理技术领域,尤其涉及中文年鉴类大数据中的行政区划信息匹配方法和模型。
背景技术
当前,我国中文统计年鉴类数据很多,基于这些年鉴整合成的数据集平台也不少,如各级统计局、中经、知网、EPS、国泰安、万德等,但是行政区划信息由于简称、全称、俗称、更名、历史名称、从属、合并、拆分、分布等各种原因造成在年鉴数据融合时存在困难或不准确,不能从海量的统计年鉴信息中快速准确的匹配统一的行政区划信息。
发明内容
本发明针对以上问题,提出一种大数据视野下的年鉴行政区划信息匹配方法和模型。
为了实现上述目的,本发明采用以下技术方案:
本发明一方面提出一种大数据视野下的年鉴行政区划信息匹配方法,包括:
以准备好的行政区划标准匹配表为基础,对年鉴样本数据中的地区、指标、来源三列信息进行多重匹配,根据匹配的结果先后进行分层级唯一取值匹配、正则表达式匹配、父级信息最大相似度匹配,直到找到最佳匹配结果,并返回非匹配结果。
进一步地,按照以下方式构建行政区划标准匹配表:
构建标准的行政区划信息规范表,所述标准的行政区划信息规范表包括地区唯一编码、标准规范中文名称、标准规范英文名称、简称、曾用名称或其他名称、行政归属的上一级地区唯一编码、行政区域的层级,正则匹配排除、正则匹配父级名称包含关键字;
基于构建的标准的行政区划信息规范表,构建行政区划标准匹配表,包括:根据地区标准规范中文名称、标准规范英文名称、简称、曾用名称或其他名称得到本级可能名称;根据行政归属的上一级地区唯一编码,得到上级国家名称、省级名称、市级名称、县级名称以及本级可能名称,并合并形成上级可能名称。
进一步地,在对年鉴样本数据中的地区、指标、来源三列信息进行多重匹配之前,还包括:
从不同渠道收集获取统计年鉴的基础数据,并将上述统计年鉴的基础数据归纳为指标、地区、时间、数值、来源五个维度,对上述数据进行清洗,得到年鉴样本数据。
进一步地,该方法具体包括:
把行政区划标准匹配表中的本级可能名称按“|”拆分到行数据,然后利用拆分后的行数据分别对年鉴样本数据中的地区、指标、来源三列信息进行多重匹配;
根据多重匹配的结果进行分层级唯一取值匹配:对匹配结果中,地区和指标中有结果的,以地区和指标匹配中的最小层级作为最终匹配的结果,地区和指标中没有结果的,以来源中匹配中的最小层级作为最终匹配的结果,同时返回行政区划标准匹配表中可能匹配的地区唯一编码和行政区域的层级,并以地区唯一编码统计个数,对于统计数量为1的,直接输出使用,对于统计数量大于1的,则进行后续处理。
进一步地,该方法还包括:
对统计数量大于1的数据拆分匹配的地区唯一编码到行数据,以地区唯一编码与标准的行政区划信息规范表和行政区划标准匹配表的并集进行交集运算,得到所有可能匹配的行政区划数据集;根据所有可能匹配的行政区划数据中的本级可能名称、上级可能名称、正则匹配排除、正则匹配父级名称包含关键字和年鉴样本数据中的地区、指标、来源三列信息构建正则匹配表达式。
进一步地,所述正则匹配表达式包括:
剔除正则匹配表达式:Not Regex_Match([地区|指标|来源],标准的行政区划信息规范表中的正则匹配排除信息),每个目标之间的正则表达式用or进行逻辑连接运算;
本级正则匹配表达式:Regex_Match([地区|指标|来源],行政区划标准匹配表中的本级可能名称),每个目标字段之间的正则表达式用or进行逻辑连接运算;
父级正则匹配表达式:Regex_Match([地区|指标|来源],行政区划标准匹配表中的上级可能名称),每个目标字段之间的正则表达式用or进行逻辑连接运算;
附加的父级正则匹配表达式:Regex_Match([地区|指标|来源],标准的行政区划信息规范表中的正则匹配父级名称包含关键字),每个目标字段之间的正则表达式用or进行逻辑连接运算;
以上四种正则表达式用AND进行连接运算,最终的正则表达式形式为:(剔除正则匹配表达式)AND(本级正则匹配表达式)AND(父级正则匹配表达式)AND(附加的父级正则匹配表达式)。
进一步地,所述父级信息最大相似度匹配包括:
对查询结果中的上级名称与上级可能名称进行相似字符比较,相同字符最多的记录保留,其它则剔除。
本发明另一方面提出一种基于上述任一所述方法的大数据视野下的年鉴行政区划信息匹配模型,该模型用于实现以下功能:
以准备好的行政区划标准匹配表为基础,对年鉴样本数据中的地区、指标、来源三列信息进行多重匹配,根据匹配的结果先后进行分层级唯一取值匹配、正则表达式匹配、父级信息最大相似度匹配,直到找到最佳匹配结果,并返回非匹配结果。
与现有技术相比,本发明具有的有益效果:
本发明以准备好的行政区划标准匹配表为基础,对年鉴样本数据中的地区、指标、来源三列信息进行多重匹配,根据匹配的结果先后进行分层级唯一取值匹配、正则表达式匹配、父级信息最大相似度匹配,直到找到最佳匹配结果,并返回非匹配结果,进而根据非匹配结果对行政区划标准匹配表进行完善。
通过上述方式,可以从指标名称、数据来源中提取有关行政区划信息,还可以根据关联维度信息正确标识出有从属关系的行政区划信息,进而可以快速高效的匹配标识出统一的行政区划信息,另外,本发明对多个重复名称而隶属不同区域的行政区划信息也有较高的识别能力。通过完善标准匹配表,可以在不改变算法的情况下实现动态学习性更新,从而提高匹配的准确率。
附图说明
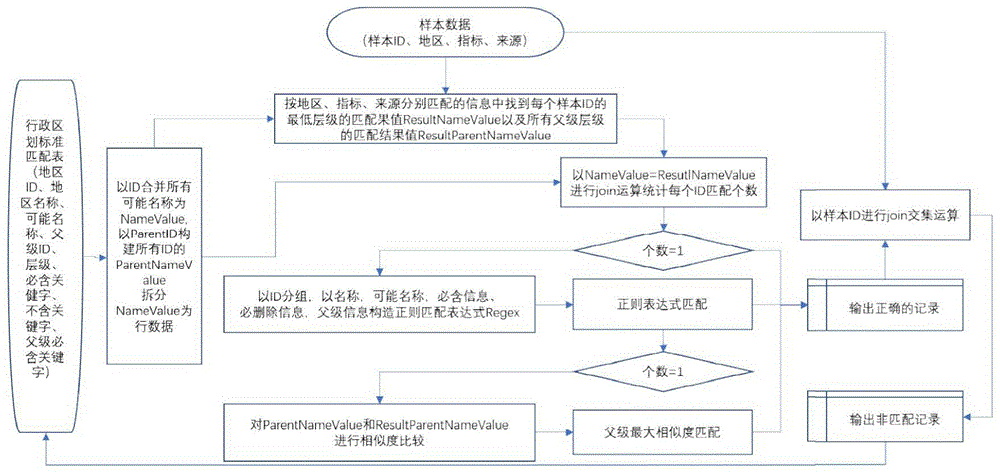
图1为本发明实施例一种大数据视野下的年鉴行政区划信息匹配方法的流程示意图;
图2为本发明实施例根据ParentID处理父级相关信息及关键字查找匹配工作流图;
图3为本发明实施例构造正则表达式工作流图;
图4为本发明实施例年鉴行政区划信息匹配工作流模型;
图5为本发明实施例测试数据匹配结果示例图。
具体实施方式
下面结合附图和具体的实施例对本发明做进一步的解释说明:
如图1所示,一种大数据视野下的年鉴行政区划信息匹配方法,包括:
以准备好的行政区划标准匹配表为基础,对年鉴样本数据中的地区、指标、来源三列信息进行多重匹配,根据匹配的结果先后进行分层级唯一取值匹配、正则表达式匹配、父级信息最大相似度匹配,直到精准的找到最佳匹配结果,并返回非匹配结果以期对行政区划标准匹配表进行补充完善和修订,直到匹配运算出符合预期的结果。
一、匹配字典准备
要准确的从年鉴数据中提取行政区划信息,前提需要一个标准的行政区划信息规范表,否则没法进行比较提取哪些信息是行政区划信息。本文国际行政区划部分采用的ISO国际标准化组织发布的ISO 3166-1、ISO3166-2标准国家代码表,国内部分采用国家统计局2022年发布的《2022年度全国统计用区划代码和城乡划分代码》以及国家统计局印发的《统计用区划代码和城乡划分代码编制规则》(国统字〔2009〕91号)进行编制。
主要信息有,地区唯一编码(ID)、标准规范中文名称(Name_cn)、标准规范英文名称(Name_en)、简称(Short_Name)(有多个名称时用“|”号分隔表示,以下以“(|)”表示有多个不同信息的表达方法)、曾用名称或其他名称(Other_Names(|))、行政归属的上一级ID(Parent_ID)、行政区域的层级(Level)(目前用1-5分别表示国、省、市、县、乡),正则匹配排除(Drop_keyword(|))、正则匹配父级名称包含关键字(Parent_name_keyword(|))以及其它可能用到的信息。目前我们已经收集整理了48300条国、省、市、县、级五级行政区划信息。相应的示例样本见表1。
表1、五级行政区划标准信息规范样表(正式基本信息样本数已达48300条)
根据表1的基本信息,需要对表1信息进行进一步加工处理,补充、丰富完善,形成年鉴行政区划匹配用的信息表。主要补充完善的信息有:根据Name_cn、Name_en、Short_Name、Other_Names得到本级可能名称(NameValue),根据Parent_ID,得到上级国家名称(国家_Name)、省级名称(省级_Name)、市级名称(市级_Name)、县级名称(县级_Name)以及对应的可能名称(NameValue)、并合并形成上级可能名称(ParentNameValue)。补充完善后的行政区划信息示例样本见表2。
表2、行政区划标准信息规范补充信息示例数据集
二、样本数据收集
从各级统计局、知网(CNKI)、万德(WIND)、中经(CEINET)、国泰安(CSMAR)、EPS、国研网等不同渠道收集获取大量统计年鉴的基础数据,这些数据基本信息内容可以大概归纳为指标、地区、时间、数值、来源等五个维度,其中涉及到行政区划信息的大概有三个维度,即地区、指标、来源。从各级统计局官网收集到的年鉴数据,有很多为EXCEL格式的二维表格,这种格式需要通过四象限提取法处理为一维标准表格数据,有关如何提取清洗这类年鉴数据的可参考《基于工作流的统计年鉴数据清洗模型构建》《河南农业科学》2021年10期。作为一种可实施方式,摘取部分典型样本数据作为示例数据进行说明。
表3、典型年鉴样本示例数据集(目前收集到的样本数据集为2亿条)
在上述样本数据集中,有些可以使用地区直接识别的,如序号为1,2,3,5,6,7,16等样本,有些需要在地区和指标中进行识别的,如序号为19,20,21,23等样本,有些需要地区、指标、来源同时进行识别的,如序号为24的样本,有些是在来源中进行识别的,如序号为4的样本。层级为4、5的样本,如果名称不唯一,通常需要更多的条件进行识别处理。就目前收集到的4万多个年鉴数据文件,涉及总数据量2亿条的原始数据来看,基本上都在上述可能的情况中。
三、匹配模型构建
依据表1-表3的数据,我们就可以来构建行政区划匹配规则和模型。
第一、可能名称唯一值直接匹配:
把表2的本级可能名称NameValue按“|”拆分到行数据,然后利用这个拆分后的行数据分别去表3中地区、指标、来源中进行多重查找匹配,对匹配结果,地区和指标中有结果的,以地区和指标匹配中的最小层级(Level最大值),地区和指标中没有结果的,以来源中匹配中的最小层级(Level)作为最终匹配的结果,并同时返回表2可能匹配的行政区划ID和Level层级,并以行政区划ID统计个数,凡是统计数量为1的,我们可以确认为唯一值精准匹配,可以直接输出使用,统计数量大于1的,一般是名称有重复,如鼓楼区,全国有4个县区级鼓楼区,城关镇,全国有102个乡镇级城关镇,对这种情况,则需要进入下一步处理。下表4为上述匹配规则的结果示例数据集。
表4、地区可能名称关键字查询匹配结果示例表
第二、正则表达式匹配:
对表4中数量大于1的数据拆分匹配的行政区划ID到行数据,以行政区划ID与表1和表2的并集进行交集运算,得到所有可能匹配的行政区划数据集。根据这个新数据集中的NameValue、ParentNameValue、Drop_KeyWord、ParenNameKeyWord和表3中的地区、指标、来源三列信息构建正则匹配表达式。四种正则表达式的公式分别为:
剔除正则匹配表达式:Not Regex_Match([地区|指标|来源],表1中的drop_keyword信息),每个目标之间的正则表达式用or进行逻辑连接运算;
本级正则匹配表达式:Regex_Match([地区|指标|来源],表2中的NameValue),每个目标字段之间的正则表达式用or进行逻辑连接运算;
父级正则匹配表达式:Regex_Match([地区|指标|来源],表2中的ParentNameValue),每个目标字段之间的正则表达式用or进行逻辑连接运算;
附加的父级正则匹配表达式:Regex_Match([地区|指标|来源],表1中的ParentNameKeyWord),每个目标字段之间的正则表达式用or进行逻辑连接运算;
以上四种正则表达式用AND进行连接运算。最终的正则表达式形式为:(剔除正则匹配表达式)AND(本级正则匹配表达式)AND(父级正则匹配表达式)AND(附加的父级正则匹配表达式)。
如南京市鼓楼区:(REGEX_Match([地区],'.*(鼓楼区).*')OR REGEX_Match([指标],'.*(鼓楼区).*'))and(REGEX_Match([地区],'.*(南京|南京市|江苏|江苏省).*')ORREGEX_Match([指标],'.*(南京|南京市|江苏|江苏省).*')OR REGEX_Match([来源],'.*(南京|南京市|江苏|江苏省).*'));
开封市鼓楼区:(REGEX_Match([地区],'.*(鼓楼区).*')OR REGEX_Match([指标],'.*(鼓楼区).*'))and(REGEX_Match([地区],'.*(开封|开封市|河南|河南省).*')ORREGEX_Match([指标],'.*(开封|开封市|河南|河南省).*')OR REGEX_Match([来源],'.*(开封|开封市|河南|河南省).*'));
河南省卢氏县城关镇:(REGEX_Match([地区],'.*(城关镇).*')OR REGEX_Match([指标],'.*(城关镇).*'))and(REGEX_Match([地区],'.*(三门峡|三门峡市|卢氏|卢氏县|河南|河南省).*')OR REGEX_Match([指标],'.*(三门峡|三门峡市|卢氏|卢氏县|河南|河南省).*')OR REGEX_Match([来源],'.*(三门峡|三门峡市|卢氏|卢氏县|河南|河南省).*'));
实际上,是为每个潜在可能匹配的行政区划ID构建了只属于本ID的正则匹配规则,在匹配的对象区域、指标、来源中分别匹配本身的可能名称或者剔除关键或者在相应的上级名称匹配自己的上一级行政区划可能名称。下表5为表4中匹配数量大于1的可能ID构建的正则匹配表达式,受篇幅所限,表5只列出部分构建的正则表达式。
表5、潜在行政区域正则匹配表达式构建示例数据集
/>
/>
只所以选择在潜在可能匹配的行政区划ID上构建正则表达式,这是因为在潜在可能匹配的行政区划ID是个小范围的数据集,如果在全部数据集上构建正则表达式,那将是48300个正则表达式,如果拿这个数量去匹配目标数据集的话,将会产生笛卡尔乘积的匹配数量,使得匹配的效率很低,目标数据量大时,很难有高效率的表现。如表4有12条匹配数量大于1的记录,对匹配数量求和则对应241个潜在行政区划ID,那么需要构建241个正则表达式,匹配241*12=2892次即可,而不是48300*12=579600次。最终正则匹配的结果是12条信息,匹配成功15个数据结果,其中有9条结果为唯一匹配,有6条信息为重复匹配,需要进一步处理,参见表6。
表6、正则表达式匹配结果示例数据集
/>
/>
第三、父级信息最大相似度匹配:
由于我们的父级信息采用了县+市+省三级,在正则表达式中只要这三级中任意一级满足父级匹配条件,则匹配成功。像表6中序号为23、24的城关镇就匹配了三门峡三个县的信息,实际上我们只需要匹配卢氏县的信息即可,这需要分级进行逐级匹配,因为并不知道哪一级信息确定或缺失,所以这里采用一种对查询结果中的上级名称(Reseult_ParentNameValue)与上级可能名称(ParentNameValue)进行相似字符比较,相同字符最多的记录保留,其它则剔除。很明显在序号为23的3条记录中,ID为411224100的记录父级信息匹配程度最高,达到了6个字符相同,而其它记录,则分别只有3、4个,序号为24的记录同样如此,因此正确的匹配结果为ID=411224100。
表7、父级信息最大相似度匹配结果示例数据集
/>
合并上述三种方法的正确匹配结果并与原始样本数据进行比较,我们发现序号为26的样本无法正确匹配,经过人工查询江苏省镇江市丹阳市河阳镇属于历史名称,目前已改名为司徒镇,我们只需要在表1的五级行政区划标准信息找到丹阳市司徒镇相关信息,在其它名称中增加河阳镇即可,再次运算模型,即可得到正确结果,表8为表3样本数据的最终匹配输出结果,每条数据都正确匹配上了对应的ID和正式规范名称。
表8、样本匹配结果示例数据集
/>
四、模型测试验证
根据上述思路和方法,我们用Alteryx Designer学习版构建了一个全自动的大数据视野下的年鉴行政区划信息匹配模型,并把该模型打包成为一个年鉴区域匹配组件,方便在任意地方进行调用处理。
图2-图5为该模型的部分工作流截图。
该模型有2个输入,R为行政区划基础信息表,S为年鉴原始数据文件;2个输出,T为正确匹配结果,F为未匹配成功结果。对CNKI上获取的农林牧渔业总产值和第一产业增加值两个文件共815638条原始数据进行匹配测试,仅用32.7秒便成功匹配数据集813286条,实现每秒匹配数据2万条以上,匹配准确率达到99.7%,未匹配成功数据集2356条,检查未匹配成功的数据集,都集中在历史名称或未在行政区划基础信息表中进行登记的区域名称,只需要慢慢完善行政区划基础信息表内容即可实现正确匹配。
以上所示仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 信息匹配模型的训练、信息匹配方法和装置
- 一种VR/AR环境下的利用视野中心轨迹给设备输入信息或指令的方法