一种Hive SQL语句执行优化方法、存储介质及电子装置
文献发布时间:2024-04-18 20:01:30
技术领域
本申请涉及大数据技术领域,具体而言,涉及一种Hive SQL语句执行优化方法、存储介质及电子装置。
背景技术
在当今的大数据时代,Hive作为一种数据处理和存储工具,正逐渐成为数据分析和决策支持的重要工具。Hive是由Facebook开发的一种基于Hadoop的数据处理和存储工具,它提供了类似于SQL的查询语言Hive SQL,使得数据分析师和开发人员能够通过HiveSQL语言来处理和操作大数据,因此集成有Hive组件的各类数据操作平台随之产生并广泛使用。
目前集成了Hive组件的数据操作平台在进行Hive SQL语句执行时,首先通过开源的Hive SQL解析器解析语义,但是其仅能解析语义不能识别表类型、获取表的数据文件等数据信息,因此不能对Hive SQL语句执行是否存在性能问题进行识别,那么当Hive SQL语句执行时就可能会出现占用集群特别多的资源,进而影响其他Hive SQL的正常执行,严重影响Hive的数据分析处理性能,而如果通过人工排查Hive SQL语句执行的性能隐患的话,也会存在耗时耗力的问题。
由此可见,现有技术中的Hive SQL语句的执行存在不能提前对执行的性能隐患问题进行排查的缺陷。
发明内容
为了克服上述缺陷,本发明提出了一种Hive SQL语句执行优化方法、存储介质及电子装置,以解决或至少部分地解决Hive SQL语句在执行过程中出现性能问题导致执行效率低下的问题。
在第一方面,本发明提供一种Hive SQL语句执行优化方法,该方法包括:
当数据操作平台接收到Hive SQL语句时,执行以下操作:
解析所述Hive SQL语句得到解析结果,根据所述解析结果形成获取表信息和数据文件信息的请求;
向Mysql数据库发送所述获取表信息和数据文件信息的请求,并获得所述Mysql数据库返回的与所述解析结果对应的表信息和数据文件信息;
基于所述表信息、所述数据文件信息以及所述解析结果判断所述Hive SQL语句的执行是否存在潜在性能问题,并得到判断结果;
根据所述判断结果判断是否执行所述Hive SQL语句。
进一步的,所述方法还包括:所述数据操作平台按照预设时间向集群管理系统发送信息获取请求以获得表信息和数据文件信息,并将获得的所述表信息和所述数据文件信息发送给所述Mysql数据库以完成将所述表信息和所述数据文件信息存储到所述Mysql数据库中。
上述所述集群管理系统包括元数据存储系统和分布式文件存储系统;
所述数据操作平台按照预设时间向集群管理系统发送信息获取请求以获得表信息和数据文件信息具体包括:
按照所述预设时间,所述数据操作平台向所述元数据存储系统发送获取表信息的请求以获得所述表信息;
以及所述数据操作平台向所述分布式文件存储系统发送获取数据文件信息的请求以获得所述数据文件信息。
优选地,上述数据操作平台向所述分布式文件存储系统发送获取数据文件信息的请求以获得所述数据文件信息具体为:
所述数据操作平台根据所述表信息形成获取表级目录信息的请求,向所述分布式文件存储系统发送所述获取表级目录信息的请求,并接收所述分布式文件存储系统返回的表级目录信息;
以及所述数据操作平台根据所述表级目录信息形成获取数据文件信息的请求,向所述分布式文件存储系统发送所述获取数据文件信息的请求,并接收所述分布式文件存储系统返回的数据文件信息。
优选地,上述解析所述Hive SQL语句得到解析结果,根据所述解析结果形成获取表信息和数据文件信息的请求具体为:利用解析器解析所述Hive SQL语句得到解析结果,从所述解析结果中获得表名和字段名,根据获得的所述表名形成获取表信息和数据文件信息的请求;
所述Mysql数据库返回的与所述解析结果对应的表信息中包含有表名。
所述表信息还包含分区字段标识和分区字段名,所述数据文件信息包含表存储空间;相应的,所述基于所述表信息和所述数据文件信息判断所述Hive SQL语句的执行是否存在潜在性能问题,并得到判断结果具体为:
根据所述分区字段标识、所述分区字段名和所述表存储空间判断所述Hive SQL语句是否符合限制执行条件,是则得到表示存在潜在性能问题的判断结果,否则得到表示不存在潜在性能问题的判断结果;
所述限制执行条件为:所述表存储空间大于预设存储空间,并且所述分区字段标识表示存在分区且解析所述Hive SQL语句获得的字段名中包含所述分区字段名。
优选地,上述数据操作平台根据所述判断结果判断是否执行所述Hive SQL语句具体为:
若所述判断结果为存在潜在性能问题,则所述数据操作平台不执行所述Hive SQL语句;
若所述判断结果为不存在潜在性能问题,则所述数据操作平台执行所述Hive SQL语句。
在第二方面,本发明提供一种Hive SQL语句执行优化装置,所述装置包括:
接收模块,用于接收Hive SQL语句;
解析模块,用于对所述接收模块接收到的所述Hive SQL语句进行解析获得解析结果;
获取模块,用于根据所述解析模块获得的所述解析结果向Mysql数据库发送获取表信息和数据文件信息的请求以获得与所述解析结果对应的表信息和数据文件信息;
判断模块,用于根据所述获取模块获取的所述表信息、所述数据文件信息以及所述解析模块获得的所述解析结果判断所述Hive SQL语句的执行是否存在潜在性能问题并得到判断结果;
执行模块,用于根据所述判断模块得到的所述判断结果判断是否执行所述HiveSQL语句的执行。
在第三方面,本发明提供一种计算机可读的存储介质,所述计算机可读的存储介质包括存储的程序,其中,所述程序运行时执行上述Hive SQL语句执行优化方法的技术方案中任一项技术方案所述的方法。
在第四方面,本发明提供一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为通过所述计算机程序执行上述Hive SQL语句执行优化方法的技术方案中任一项技术方案所述的方法。
本发明上述一个或多个技术方案,至少具有如下一种或多种有益效果:由上述技术方案可知,本申请提供的一种Hive SQL语句执行优化方法,通过事先与集群管理系统进行信息交互以获得可以用于进行潜在性能问题检测的相关信息并写入到Mysql数据库中,当有用户提交Hive SQL语句执行时,可以通过从Mysql中查询获取相关信息进行Hive SQL语句的执行是否存在潜在性能问题的判断,能够实现对Hive SQL语句执行的性能隐患进行事先排查处理,进而能够提高Hive SQL语句执行的效率,有效降低人工排查Hive SQL语句性能隐患的人力成本,以及提高Hive的数据分析处理性能。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本申请的实施例,并与说明书一起用于解释本申请的原理。
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是根据本申请实施例的一种Hive SQL语句执行优化方法的硬件环境示意图;
图2是根据本申请实施例的一种Hive SQL语句执行优化方法的流程示意图;
图3是本申请实施例提供的数据操作平台与集群管理系统进行信息交互的主要步骤示意图;
图4是本申请实施例提供的一种Hive SQL语句执行优化方法的时序图;
图5是本申请实施例提供的一种Hive SQL语句执行优化装置的主要结构框图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
本申请中所使用的一些技术术语说明如下:
SQL:一种结构化查询语言,用于操作数据库的语言。SQL是在数据库中存储、操作和检索数据的标准语言。
MySQL:数据库管理系统,使用SQL语言来查询数据库。
Hive:一个数据仓库工具,用于解决海量结构化日志的数据统计的工具。
Hive SQL:在数据仓库中的类SQL查询语言。基于大数据背景下,SQL被广泛应用在数据仓库中,因此专门针对Hive的特性设计了类SQL查询语言。
Hive MetaStore,用于存储Hive的元数据,负责Hive表结构和表信息的读、写、维护和修改。
HDFS,是一种分布式文件系统,支持主从结构,主节点称为NameNode,NameNode是整个文件系统的管理节点,管理文件系统的命名空间,维护着文件树内所有的文件和目录。
由于Hive提供了一系列的工具,可以对数据执行ETL(Extract-Transform-Load,抽取-转换-加载)操作。本实施例中的数据操作平台集成了Hive组件,该平台可用于接收用户提交的Hive SQL数据处理请求并向用户反馈执行结果。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
根据本申请实施例的一个方面,提供了一种Hive SQL语句执行优化方法。该方法可广泛应用于对智慧家庭(Smart Home)、智能家居、智能家用设备生态、智慧住宅(Intelligence House)生态等全屋智能数字化控制的应用场景的开发工作中。可选地,在本实施例中,上述Hive SQL语句执行优化方法可以应用于如图1所示的由终端设备102和服务器104所构成的硬件环境中。如图1所示,服务器104通过网络与终端设备102进行连接,可用于为终端或终端上安装的客户端提供服务(如应用服务等),可在服务器上或独立于服务器设置数据库,用于为服务器104提供数据存储服务,可在服务器上或独立于服务器配置云计算和/或边缘计算服务,用于为服务器104提供数据运算服务。
上述网络可以包括但不限于以下至少之一:有线网络,无线网络。上述有线网络可以包括但不限于以下至少之一:广域网,城域网,局域网,上述无线网络可以包括但不限于以下至少之一:WIFI(Wireless Fidelity,无线保真),蓝牙。终端设备102可以并不限定于为PC、手机、平板电脑、智能空调、智能烟机、智能冰箱、智能烤箱、智能炉灶、智能洗衣机、智能热水器、智能洗涤设备、智能洗碗机、智能投影设备、智能电视、智能晾衣架、智能窗帘、智能影音、智能插座、智能音响、智能音箱、智能新风设备、智能厨卫设备、智能卫浴设备、智能扫地机器人、智能擦窗机器人、智能拖地机器人、智能空气净化设备、智能蒸箱、智能微波炉、智能厨宝、智能净化器、智能饮水机、智能门锁等。
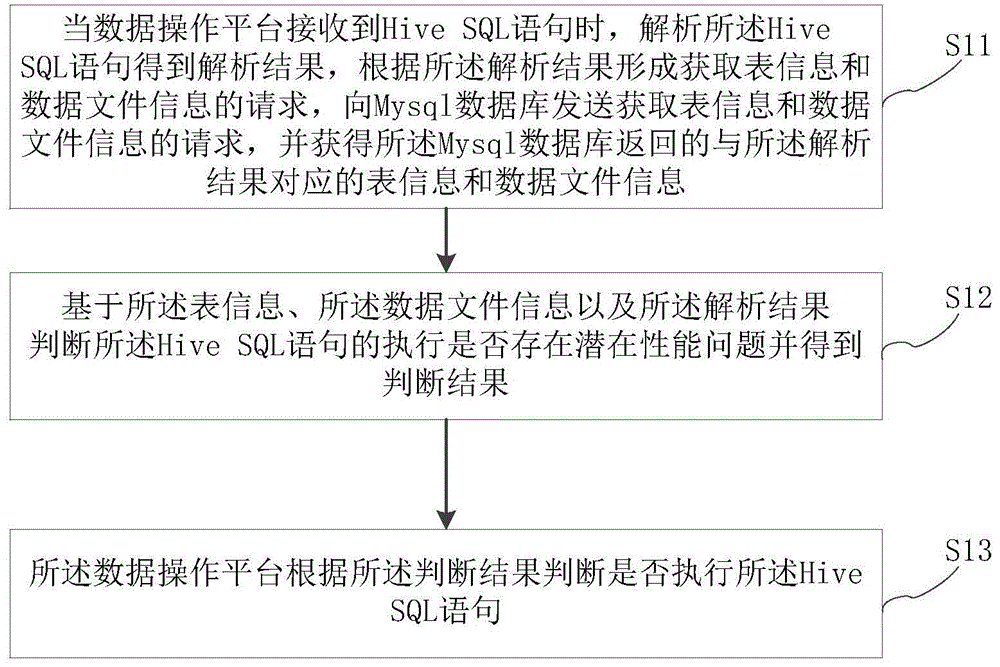
在本实施例中提供了一种Hive SQL语句执行优化方法,可应用于上述计算机终端,一种具体实现方式是,本实施例的Hive SQL语句执行优化方法的执行主体具体为在上述计算机终端上开发的集成了Hive组件的数据操作平台。图2是根据本申请实施例的一种Hive SQL语句执行优化方法的流程图,本实施例中的该方法流程包括如下步骤:
步骤S11:当数据操作平台接收到Hive SQL语句时,解析所述Hive SQL语句得到解析结果,根据所述解析结果形成获取表信息和数据文件信息的请求,向Mysql数据库发送获取表信息和数据文件信息的请求,并获得所述Mysql数据库返回的与所述解析结果对应的表信息和数据文件信息;
具体地,可以使用开源的解析器解析所述Hive SQL语句得到解析结果,从所述解析结果中获得表名和字段名,根据获得的所述表名形成获取表信息和数据文件信息的请求,然后向Mysql数据库发送所述获取表信息和数据文件信息的请求以获取所述Mysql数据库返回的与所述表名对应的表信息和数据文件信息。所述表信息包含有表名,而所述表信息和所述数据文件信息一一对应,因此根据解析得到的表名可以从Mysql数据库中查找获取与之对应的表信息和数据文件信息。
步骤S12:基于所述表信息、所述数据文件信息以及所述解析结果判断所述HiveSQL语句的执行是否存在潜在性能问题并得到判断结果;
具体地,所述表信息还包含分区字段标识和分区字段名,所述数据文件信息包含表存储空间;
本步骤可以具体为:根据所述分区字段标识、所述分区字段名和所述表存储空间判断所述Hive SQL语句是否符合限制执行条件,是则得到表示存在潜在性能问题的判断结果,否则得到表示不存在潜在性能问题的判断结果;
所述限制执行条件为:所述表存储空间大于预设存储空间,并且所述分区字段标识表示存在分区且解析所述Hive SQL语句获得的字段名中包含所述分区字段名。
步骤S13:所述数据操作平台根据所述判断结果判断是否执行所述Hive SQL语句的执行。
具体地,若所述判断结果为存在潜在性能问题,则所述数据操作平台不执行所述Hive SQL语句;若所述判断结果为不存在潜在性能问题,则所述数据操作平台正常执行所述Hive SQL语句。
进一步地,在上述步骤S11之前还包括,所述数据操作平台按照预设时间向集群管理系统发送信息获取请求以获得表信息和数据文件信息,一种具体实现方式,可以通过在数据操作平台上安装应用程序来实现数据操作平台按照预设时间与所述集群管理系统进行信息交互。所述集群管理系统可用于提供大数据的数据存储服务,所述集群管理系统的一种具体实现方式是包括元数据存储系统和分布式文件存储系统,所述元数据存储系统和所述分布式文件存储系统可以是单个服务器、服务器集群或云计算服务中心。
如图3所示是本实施例提供的数据操作平台与集群管理系统进行信息交互的示意图,基于预先设定的信息交互时间,数据操作平台可以通过调用一个应用程序,来完成与所述集群管理系统进行消息交互以及将信息交互获得的表信息和数据文件信息发送给所述Mysql数据库以完成将所述表信息和所述数据文件信息存储到所述Mysql数据库中。如图3所示的数据操作平台与集群管理系统进行信息交互的过程具体包括以下步骤:
步骤S10-1:数据操作平台与元数据存储系统进行信息交互获得表信息;
在一个示例性实施例中,本步骤可以具体为:按照预设时间,所述数据操作平台向所述元数据存储系统发送获取表信息的请求,并接收所述元数据存储系统返回的表信息。
本实施例中,用于存储表信息的元数据存储系统包括但不限于采用HiveMetaStore进行存储。
步骤S10-2:数据操作平台与分布式文件存储系统进行信息交互获得数据文件信息;
在一个示例性实施例中,本步骤可以具体为:所述数据操作平台根据所述表信息形成获取表级目录信息的请求,向所述分布式文件存储系统发送所述获取表级目录信息的请求,并接收所述分布式文件存储系统返回的表级目录信息;
以及所述数据操作平台根据所述表级目录信息形成获取数据文件信息的请求,向所述分布式文件存储系统发送所述获取数据文件信息的请求,并接收所述分布式文件存储系统返回的数据文件信息。
本实施例中,用于存储数据文件信息的分布式文件存储系统包括但不限于采用Hive NameNode进行存储。
步骤S10-3:数据操作平台将所述表信息和所述数据文件信息写入到Mysql数据库。
在一个示例性实施例中,本步骤可以具体为:数据操作平台通过向Mysql数据库发送数据写入指令来完成将所述表信息和所述数据文件信息写入到Mysql数据库中。
在一个具体的示例性的实施例中,一种Hive SQL语句执行优化方法的执行主体即上述数据操作平台,具体搭载了申请人自主研发的HDOP平台和java应用,所述HDOP平台集成了可以提供Hive服务的Hive组件,可以处理Hive SQL语句。所述java应用主要用于实现Hive SQL语句的解析、实现与存放Hive表信息和数据文件信息的Hive Metastore和HDFSNameNode进行信息交互以及实现与Mysql数据库进行信息交互。如图4所示是本申请实施例提供的一种Hive SQL语句执行优化方法的时序图,具体步骤如下:
首先,按照预先设定的信息交互时间,比如时间达到预设时间时,定时调用所述Java应用以执行以下步骤101至步骤107:
步骤101:Java应用向Hive Metastore发送获取所有表信息的请求;
步骤102:Hive Metastore向Java应用返回所有表信息;
步骤103:Java应用向HDFS NameNode发送获取表级目录信息的请求;
步骤104:HDFS NameNode向Java应用返回表级目录信息;
步骤105:Java应用向HDFS NameNode发送获取数据文件信息的请求;
步骤106:HDFS NameNode向Java应用返回数据文件信息;
步骤107:Java应用向Mysql数据库发送将表信息和数据文件信息写入Mysql的请求;
接下来,当用户在HDOP平台提交了Hive SQL语句时,此时所述Java应用被调用以执行以下步骤201至步骤207:
步骤201:HDOP平台向Java应用发起Hive SQL;
步骤202:Java应用解析Hive SQL获得表名和字段名;
例如,解析以下Hive SQL:
“Select distinct visituserid,loginuserid from
dl_gio_seq.ods_gio_custom_event_1hour_orc
where EVENTNAME='AovLJ3YR_000193'and loginuserid='20012166'andpdate>='20230701'”
可以得到表名dl_gio_seq.ods_gio_custom_event_1hour_orc和字段名EVENTNAME、loginuserid和pdate。
步骤203:Java应用向Mysql数据库发送获取表信息和数据文件信息的请求;
步骤204:Mysql数据库向Java应用返回表信息和数据文件信息;
例如:以一张表为例,返回的表信息包含如下内容:
表名:dl_gio_seq.ods_gio_custom_event_1hour_orc;
分区字段标识:true(表示存在分区)
分区字段名:pdate、phour;
HDFS路径:
hdfs://nameservice1/hive/external/gio/dl_gio_seq/ods_gio_custom_event_1hour_orc
返回的与表名dl_gio_seq.ods_gio_custom_event_1hour_orc对应的数据文件信息如下:
/hive/external/gio/dl_gio_seq/ods_gio_custom_event_1hour_orc/pdate=20230718:44.4G
/hive/external/gio/dl_gio_seq/ods_gio_custom_event_1hour_orc/pdate=20230719:44.1G
/hive/external/gio/dl_gio_seq/ods_gio_custom_event_1hour_orc/pdate=20230720:45.4G
/hive/external/gio/dl_gio_seq/ods_gio_custom_event_1hour_orc/pdate=20230721:43.1G
可见,存在分区时返回的数据文件信息中包含有各个分区表的存储空间,根据各个分区表的存储空间可以计算得到表存储空间,若不存在分区则返回的数据文件中直接包含表存储空间。
步骤205:Java应用判断Hive SQL执行是否存在潜在的性能问题;
例如,预设存储空间为500GB,若是经过判断:表存储空间超过500GB、有分区字段但是该Hive SQL的过滤条件中未用到分区字段,则断定Hive SQL的执行会存在全表扫描的性能风险。
步骤206:Java应用向HDOP平台返回判断结果;
步骤207:HDOP平台根据判断结果决定是否限制Hive SQL执行。
例如,若判断结果是存在潜在的性能问题,则不执行所述Hive SQL,并报错,若判断结果是存在潜在的性能问题,则正常执行所述Hive SQL。
进一步,本发明还提供了一种Hive SQL语句执行优化装置。
参阅附图5,图5是根据本发明的一个实施例的Hive SQL语句执行优化装置的主要结构框图。如图5所示,本发明实施例中的Hive SQL语句执行优化装置主要包括接收模块301、解析模块302、获取模块303、判断模块304和执行模块305。在一些实施例中,接收模块301、解析模块302、获取模块303、判断模块304和执行模块305中的一个或多个可以合并在一起成为一个模块。在一些实施例中接收模块301可以被配置成接收Hive SQL语句。解析模块302可以被配置成对接收模块301接收到的Hive SQL语句进行解析获得解析结果。获取模块303可以被配置成根据所述解析模块302获得的解析结果向Mysql数据库发送获取表信息和数据文件信息的请求以获得与所述解析结果对应的表信息和数据文件信息。判断模块304可以被配置成根据所述表信息、所述数据文件信息以及所解析结果判断Hive SQL语句的执行是否存在潜在性能问题并得到判断结果。执行模块305被配置成根据所述判断结果判断是否执行所述Hive SQL语句。一个实施方式中,具体实现功能的描述可以参见上述方法实施例中各步骤的描述,在此不再赘述。
应该理解的是,由于各个模块的设定仅仅是为了说明本发明的装置的功能单元,这些模块对应的物理器件可以是处理器本身,或者处理器中软件的一部分,硬件的一部分,或者软件和硬件结合的一部分。因此,图中的各个模块的数量仅仅是示意性的。本领域技术人员能够理解的是,可以对装置中的各个模块进行适应性地拆分或合并。对具体模块的这种拆分或合并并不会导致技术方案偏离本发明的原理,因此,拆分或合并之后的技术方案都将落入本发明的保护范围内。
进一步,本发明还提供了一种电子装置。该电子装置包括处理器和存储装置,所述存储器中存储有计算机程序,所述处理器可以被配置成用于执行存储器中的计算机程序,该程序包括但不限于执行上述方法实施例的一种Hive SQL语句执行优化方法的程序。
进一步,本发明还提供了一种计算机可读存储介质。在根据本发明的一个计算机可读存储介质实施例中,计算机可读存储介质可以被配置成存储执行上述方法实施例的一种Hive SQL语句执行优化方法的程序,该程序可以由处理器加载并运行以实现上述一种Hive SQL语句执行优化方法。为了便于说明,仅示出了与本发明实施例相关的部分,具体技术细节未揭示的,请参照本发明实施例方法部分。该计算机可读存储介质可以是包括各种电子设备形成的存储装置设备,可选的,本发明实施例中计算机可读存储介质是非暂时性的计算机可读存储介质。
以上所述仅是本申请的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本申请原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本申请的保护范围。