一种自适应对象的类别分析方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明涉及对象分类领域,特别是涉及对象实现预定目标结果缺失情况下的对象分类确定,即特别涉及一种自适应对象的类别分析方法。
背景技术
在给定目标情况下对对象集合进行分类是研究过程中的普遍问题。一般情况下希望得到影响对象实现预定目标的因素,以及在这些因素影响下对象实现目标的程度,即对象结果。这时被分析系统具有输入值和输出值,可使用例如神经网络等智能分析方法来寻求对应关系。再依据该对应关系实现对对象的分类、排序或判别。但上述条件是理想的,可以设想在必须对对象进行预测性分析时对象的结果是缺失的。不能使用类似神经网络这种同时需要输入和输出的方法来研究对象特征。特别是在系统可靠性或系统安全等领域,必须事先分析的情况下必然没有对象运行的结果。这时只能根据目标,影响对象实现目标的因素,以及对象集合本身展开研究,实现对对象集合分类等研究。这类似于故障树分析中的结构重要度,因为它不需要具体事件的发生概率,只针对系统结构进行分析。
关于各类对象集合的分类研究较多。这些成果针对不同目标研究了各种对象的类别分析方法,提出了很多有益思想和算法,并取得了良好效果。但这些方法面对对象运行结果缺失情况仍难以适用。特别是一些需要对象运行结果形成对应关系的智能方法更不能使用。这些问题在安全领域最为突出,必须在对象运行前对对象进行研究,将对象按照是否能完成目标进行分类。最终保证系统运行安全。
为解决上述问题,本发明根据三支决策思想,使用联系数表示对象分类,使用k均值聚类算法(K-means)确定分项系数,最终整合所有因素的分类联系数,实现只通过目标-因素-对象,无需结果的自适应对象的类别分析方法。为对象结果缺失条件下的对象分类提供支持。
发明内容
本发明的目的在于提供一种自适应对象的类别分析方法,解决现有技术中的对象的类别分析方法在对象结果缺失条件下无法实现对象分类的技术问题。
本发明提供了一种自适应对象的类别分析方法,确定对象实现预定目标结果缺失情况下的对象分类,借助联系数提出了一种以因素-对象为基础的自适应对象的类别分析方法;基于三支决策思想借助联系数表示单因素同异反对象分类情况;并借助K-means计算联系数各分项系数;通过同异反因素图得到所有因素影响下所有对象的同异反分类联系数;当目标和因素种类不变,对象数量变化时,对象的同异反分类分布相同;用于结果缺失条件下的自适应对象分类;
对象分类的联系数表示方法:
基于目标-对象-因素对应关系进行对象分类研究。设被研究对象集合为U={u
就单因素f
设
最终建立了对于单因素f
基于K-means的分类与分项系数确定;
前节给出了单因素分类表示方法,即μ
K-means在某种意义上是根据数据分布特征自适应地进行聚类分析的方法。使用K-means的好处是可根据U中对象在f
对于正向因素,即因素值越大,对象越接近要求的目标,Max(X
对X
因素-对象的分类联系数;
根据单因素对象集合分类联系数μ
将所有对象在各因素条件下进行的同异反分类联系数进行融合的方法,即将μ
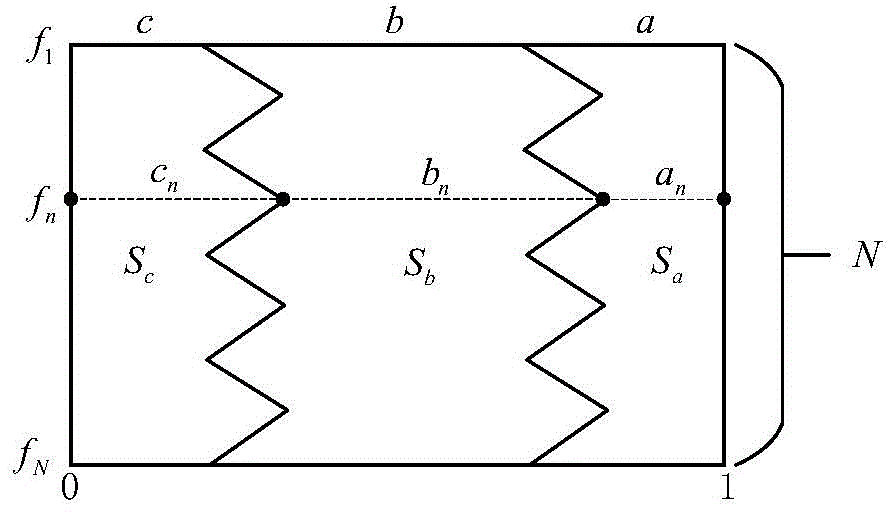
以正向因素绘制此图,1代表与目标相同(最近)的情况,0代表与目标相反(最远)的情况,则有因素f
同异反因素图中两条折线将其划分为三部分,分别代表了对于所有对象在多因素影响下针对目标的同异反特征分布。同异反特征占据的区域可表示为
以目标构建同异反三类聚类分析;以因素和对象关系形成联系数;由于缺失结果,该方法是对分类问题的结构性分析;同时K-means在没有对象结果情况下可实现自适应对象分类。因此上述方法是基于联系数和因素-对象的针对目标的自适应对象的类别分析方法,满足前文所述的理论基础。使用K-means进行聚类分析取决于数据的分布情况,因此3个聚类中心位置对联系数同异反分量系数有直接影响。这取决于各对象的因素值分布情况,这也是自适应的基础。
本申请中未特别注明含义的字母均为中间变量。
本发明的有益技术效果:本发明提供的自适应对象的类别分析方法,在对象结果缺失条件下也能实现对象分类。
附图说明
图1示出了同异反因素图。
具体实施方式
下面结合附图对本发明作进一步阐述:
本发明提供了一种自适应对象的类别分析方法,确定对象实现预定目标结果缺失情况下的对象分类,借助联系数提出了一种以因素-对象为基础的自适应对象的类别分析方法;基于三支决策思想借助联系数表示单因素同异反对象分类情况;并借助K-means计算联系数各分项系数;通过同异反因素图得到所有因素影响下所有对象的同异反分类联系数;当目标和因素种类不变,对象数量变化时,对象的同异反分类分布相同;用于结果缺失条件下的自适应对象分类;
对象分类的联系数表示方法:
基于目标-对象-因素对应关系进行对象分类研究。设被研究对象集合为U={u
就单因素f
设
最终建立了对于单因素f
基于K-means的分类与分项系数确定;
前节给出了单因素分类表示方法,即μ
K-means在某种意义上是根据数据分布特征自适应地进行聚类分析的方法。使用K-means的好处是可根据U中对象在f
对于正向因素,即因素值越大,对象越接近要求的目标,Max(X
对X
因素-对象的分类联系数;
根据单因素对象集合分类联系数μ
将所有对象在各因素条件下进行的同异反分类联系数进行融合的方法,即将μ
如图1所示,以正向因素绘制此图,1代表与目标相同(最近)的情况,0代表与目标相反(最远)的情况,则有因素f
同异反因素图中两条折线将其划分为三部分,分别代表了对于所有对象在多因素影响下针对目标的同异反特征分布。同异反特征占据的区域可表示为
以目标构建同异反三类聚类分析;以因素和对象关系形成联系数;由于缺失结果,该方法是对分类问题的结构性分析;同时K-means在没有对象结果情况下可实现自适应对象分类。因此上述方法是基于联系数和因素-对象的针对目标的自适应对象的类别分析方法,满足前文所述的理论基础。使用K-means进行聚类分析取决于数据的分布情况,因此3个聚类中心位置对联系数同异反分量系数有直接影响。这取决于各对象的因素值分布情况,这也是自适应的基础。
被研究对象为一些电气系统,以对象实现功能为目标进行分类。设对象集合为U={u
表1各对象在各因素上的数值
使用上述方法对对象集合U={u
U/f
Uf
Uf
进一步借助同异反因素图,计算同异反特征占据的区域分别为S
综上,由于实际问题中获得目标-因素-对象-结果的对应关系是困难的,特别是在对象没有运行得到结果的情况下。因此预测时得到对象运行结果是不可能的。因此只能对目标-因素-对象对应关系进行研究。这相当于研究的输入基础数据是目标-因素-对象,对应的输出数据是对象结果,当两者都存在时使用类似神经网络的方法是可行的。当目标不变,因素种类不变,同类对象数量变化时,仍然服从相同的对象分类分布,即具有相同的同异反分项系数。借助该特征可最终实现预测条件下的新对象集合分类。
- 一种基于DWT和LSTM的短期风力发电功率预测方法及系统
- 一种基于小波长短期记忆网络的超短期风电功率预测方法
- 一种基于超短期功率预测数据的储能优化控制方法及系统
- 基于蚁群优化的超短期功率预测数据的修正方法及系统