用于语音识别的方法、装置、设备和可读介质
文献发布时间:2024-04-18 20:01:55
技术领域
本公开的示例实施例总体涉及计算机技术领域,并且更具体地,涉及用于语音识别的方法、装置、设备和计算机可读存储介质。
背景技术
随着互联网技术的发展,越来越多的应用或平台等均提供自然语言处理功能,给广大用户带来了诸多便利。具有自然语言处理功能的应用或平台可以基于经训练的机器学习模型向用户提供自然语言处理服务。语音识别任务是自然语言处理任务中的重要任务。期望能够在保证语音识别结果的准确性的同时,提高语音识别的效率。
发明内容
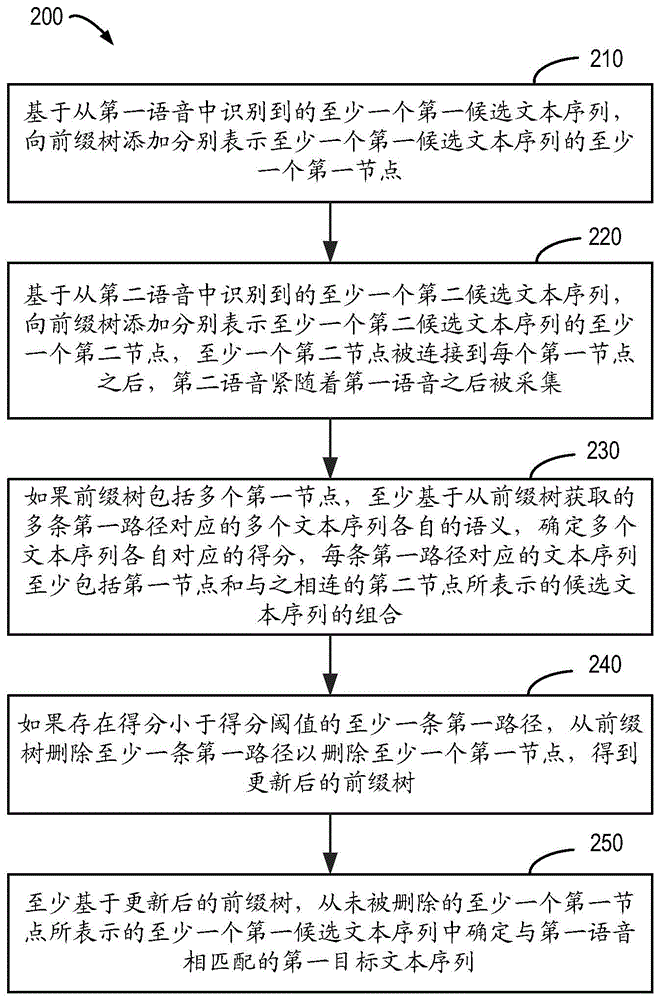
在本公开的第一方面,提供一种用于语音识别的方法。该方法包括:基于从第一语音中识别到的至少一个第一候选文本序列,向前缀树添加分别表示至少一个第一候选文本序列的至少一个第一节点;基于从第二语音中识别到的至少一个第二候选文本序列,向前缀树添加分别表示至少一个第二候选文本序列的至少一个第二节点,至少一个第二节点被连接到每个第一节点之后,第二语音紧随着第一语音之后被采集;如果前缀树包括多个第一节点,至少基于从前缀树获取的多条第一路径对应的多个文本序列各自的语义,确定多个文本序列各自对应的得分,每条第一路径对应的文本序列至少包括第一节点和与之相连的第二节点所表示的候选文本序列的组合;如果存在得分小于得分阈值的至少一条第一路径,从前缀树删除至少一条第一路径以删除至少一个第一节点,得到更新后的前缀树;以及至少基于更新后的前缀树,从未被删除的至少一个第一节点所表示的至少一个第一候选文本序列中确定与第一语音相匹配的第一目标文本序列。
在本公开的第二方面,提供一种用于语音识别的装置。该装置包括:第一节点添加模块,被配置为基于从第一语音中识别到的至少一个第一候选文本序列,向前缀树添加分别表示至少一个第一候选文本序列的至少一个第一节点;第二节点添加模块,被配置为基于从第二语音中识别到的至少一个第二候选文本序列,向前缀树添加分别表示至少一个第二候选文本序列的至少一个第二节点,至少一个第二节点被连接到每个第一节点之后,第二语音紧随着第一语音之后被采集;得分确定模块,被配置为如果前缀树包括多个第一节点,至少基于从前缀树获取的多条第一路径对应的多个文本序列各自的语义,确定多个文本序列各自对应的得分,每条第一路径对应的文本序列至少包括第一节点和与之相连的第二节点所表示的候选文本序列的组合;前缀树更新模块,被配置为如果存在得分小于得分阈值的至少一条第一路径,从前缀树删除至少一条第一路径以删除至少一个第一节点,得到更新后的前缀树;以及文本序列确定模块,被配置为至少基于更新后的前缀树,从未被删除的至少一个第一节点所表示的至少一个第一候选文本序列中确定与第一语音相匹配的第一目标文本序列。
在本公开的第三方面,提供了一种电子设备。该电子设备包括至少一个处理单元;以及至少一个存储器,至少一个存储器被耦合到至少一个处理单元并且存储用于由至少一个处理单元执行的指令,指令在由至少一个处理单元执行时使电子设备执行本公开第一方面的方法。
在本公开的第四方面,提供了一种计算机可读存储介质。该计算机可读存储介质上存储有计算机程序,其可由处理器执行以执行根据本公开的第一方面的方法。
应当理解,发明内容部分中所描述的内容并非旨在限定本公开的实施例的关键特征或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的描述而变得容易理解。
附图说明
在下文中,结合附图并参考以下详细说明,本公开各实现方式的上述和其他特征、优点及方面将变得更加明显。在附图中,相同或相似的附图标记表示相同或相似的元素,其中:
图1示出了本公开的实施例能够在其中实现的示例环境的示意图;
图2示出了根据本公开的一些实施例的用于语音识别的过程的流程图;
图3示出了根据本公开的一些实施例的示例前缀树的示意图;
图4示出了根据本公开的一些实施例的利用机器学习模型执行语音识别任务的过程的示意图;
图5示出了根据本公开的一些实施例的前缀树的关键成员的示意图;
图6示出了根据本公开的某些实施例的前缀树更新的过程的示意图;
图7示出了根据本公开的某些实施例的用于语音识别的装置的示意性结构框图;以及
图8示出了其中可以实施本公开的一个或多个实施例的计算设备的框图。
具体实施方式
下面将参照附图更详细地描述本公开的实施例。虽然附图中示出了本公开的一些实施例,然而应当理解的是,本公开可以通过各种形式来实现,而且不应该被解释为限于这里阐述的实施例,相反,提供这些实施例是为了更加透彻和完整地理解本公开。应当理解的是,本公开的附图及实施例仅用于示例性作用,并非用于限制本公开的保护范围。
在本公开的实施例的描述中,术语“包括”及其类似用语应当理解为开放性包含,即“包括但不限于”。术语“基于”应当理解为“至少部分地基于”。术语“一个实施例”或“该实施例”应当理解为“至少一个实施例”。术语“一些实施例”应当理解为“至少一些实施例”。下文还可能包括其它明确的和隐含的定义。
需要说明的是,本公开的技术方案中,所涉及的用户个人信息的获取,存储和应用等,均符合相关法律法规的规定,且不违背公序良俗。
可以理解的是,在使用本公开各实施例公开的技术方案之前,均应当根据相关法律法规通过适当的方式对本公开所涉及个人信息的类型、使用范围、使用场景等告知用户并获得用户的授权。
例如,在响应于接收到用户的主动请求时,向用户发送提示信息,以明确地提示用户,其请求执行的操作将需要获得和使用到用户的个人信息,从而使得用户可以根据提示信息来自主地选择是否向执行本公开技术方案的操作的电子设备、应用程序、服务器或存储介质等软件或硬件提供个人信息。
作为一种可选的但非限制性的实现方式,响应于接收到用户的主动请求,向用户发送提示信息的方式,例如可以是弹出窗口的方式,弹出窗口中可以以文字的方式呈现提示信息。此外,弹出窗口中还可以承载供用户选择“同意”或“不同意”向电子设备提供个人信息的选择控件。
可以理解的是,上述通知和获取用户授权过程仅是示意性的,不对本公开的实施例构成限定,其他满足相关法律法规的方式也可应用于本公开的实施例中。
如本文中所使用的,术语“模型”可以从训练数据中学习到相应的输入与输出之间的关联关系,从而在训练完成后可以针对给定的输入,生成对应的输出。模型的生成可以基于机器学习技术。深度学习是一种机器学习算法,通过使用多层处理单元来处理输入和提供相应输出。神经网络模型是基于深度学习的模型的一个示例。在本文中,“模型”也可以被称为“机器学习模型”、“学习模型”、“机器学习网络”或“学习网络”,这些术语在本文中可互换地使用。
“神经网络”是一种基于深度学习的机器学习网络。神经网络能够处理输入并且提供相应输出,其通常包括输入层和输出层以及在输入层与输出层之间的一个或多个隐藏层。在深度学习应用中使用的神经网络通常包括许多隐藏层,从而增加网络的深度。神经网络的各个层按顺序相连,从而前一层的输出被提供作为后一层的输入,其中输入层接收神经网络的输入,而输出层的输出作为神经网络的最终输出。神经网络的每个层包括一个或多个节点(也称为处理节点或神经元),每个节点处理来自上一层的输入。
通常,机器学习大致可以包括三个阶段,即训练阶段、测试阶段和应用阶段(也称为推理阶段)。在训练阶段,给定的模型可以使用大量的训练数据进行训练,不断迭代更新参数值,直到模型能够从训练数据中获得一致的满足预期目标的推理。通过训练,模型可以被认为能够从训练数据中学习从输入到输出之间的关联(也称为输入到输出的映射)。训练后的模型的参数值被确定。在测试阶段,将测试输入应用到训练后的模型,测试模型是否能够提供正确的输出,从而确定模型的性能。在应用阶段,模型可以被用于基于训练得到的参数值,对实际的输入进行处理,确定对应的输出。
图1示出了本公开的实施例能够在其中实现的示例环境100的示意图。如图1所示,环境100可以包括电子设备110。
电子设备110可以将目标语音102转换成与目标语音102相匹配的目标文本序列112。也即,电子设备110可以对目标语音102执行语音识别任务以生成对应的目标文本序列112。这里的目标语音可以是任意适当语种、任意时长的语音。例如,电子设备110可以对目标语音102进行语音识别以生成其对应语种的文本序列。例如,电子设备110可以对语种为英文的语音进行识别以生成语种为英文的文本序列。这里的目标语音102可以是电子设备110本地的语音,也可以是电子设备110实时采集到的语音。
电子设备110例如可以利用经训练的机器学习模型115来执行语音识别任务。机器学习模型115例如可以包括但不限于Transformer模型、卷积神经网络(CNN)、循环神经网络(RNN)、深度神经网络(DNN)等任意适当的模型。机器学习模型115可以是电子设备110本地的模型,也可以是被安装在其他电子设备110的模型(例如安装在远端设备中)。
电子设备110可以包括具有计算能力的任何计算系统,例如各种计算设备/系统、终端设备、服务端设备等。终端设备可以是任意类型的移动终端、固定终端或便携式终端,包括移动手机、台式计算机、膝上型计算机、笔记本计算机、上网本计算机、平板计算机、媒体计算机、多媒体平板、掌上电脑、便携式游戏终端、VR/AR设备、个人通信系统(PersonalCommunication System,PCS)设备、个人导航设备、个人数字助理(Personal DigitalAssistant,PDA)、音频/视频播放器、数码相机/摄像机、定位设备、电视接收器、无线电广播接收器、电子书设备、游戏设备或者前述各项的任意组合,包括这些设备的配件和外设或者其任意组合。服务端设备可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络、以及大数据和人工智能平台等基础云计算服务的云服务器。服务端设备例如可以包括计算系统/服务器,诸如大型机、边缘计算节点、云环境中的计算设备,等等。
应当理解,仅出于示例性的目的描述环境100中各个元素的结构和功能,而不暗示对于本公开的范围的任何限制。
如前文所简要提及的,具有自然语言处理功能的应用或平台可以基于经训练的机器学习模型向用户提供自然语言处理服务。语音识别任务是自然语言处理任务中的重要任务。随着人工智能技术的不断进步及普及,人们对语音识别的效果的期望也越来越高。人们除了要求对一段语音的识别的准确率尽可能高外,还要求对音频流实时处理并显示中间结果。也即流式实时语音识别,而不是获取到整个音频后才能显示结果。实时识别一方面可以提升用户直观体验,例如在语音输入和会议字幕场景中,人们希望说话时可以同步看到语音转录结果(也即语音识别结果)。如果说话过程中,屏幕上无任何显示,可能会导致人们觉得交互不畅而失去耐心。另一方面,在复杂的人机交互场景中,语音识别往往是系统中相对靠前的部分,实时给出识别结果有助于提升下游任务效果。如智能客服中的打断和背景噪音过滤功能,都可能使用实时语音识别结果作为特征。
相比传统上的基于隐马尔可夫(HMM)模型的混合框架,端到端语音识别在非实时识别的准确率上取得明显提升。对于实时语音识别,虽然可以通过引入分块(chunk)和注意力(attention)机制来保证语音识别的准确率,但由于模型中的CTC(ConnectionistTemporal Classification,一种用于解决输入和输出序列长度不一、无法对齐的问题的算法)尖峰延迟和分块等待问题,仍会导致语音识别时,推理解码出某个字的时刻相比其在原语音中的时刻有延迟,这会影响结果显示的实时性。
传统上提出了一组基于提示的方案来解决上述的延迟问题。这种基于提示的方案是在当前时刻已获取的音频编码后,填充一个块大小(chunk size)的虚拟编码(也可以称之为虚拟分块或填充分块,padding chunk)。利用端到端模型编码器(encoder)部分具有类似掩码语言模型(Masked LM)预测能力的特性,在解码过程中预测这个填充分块对应的文字,从而在实时识别时能够提前显示未来可能的语音对应的文字,降低识别结果显示延时。因为填充分块本是不存在的,所以通常直接设置其值为0,叫做零填充分块(ZeroPaddingchunk,也可以简称为ZeroPadding,在本文中,二者可以互换地使用)。这种方案要求只能影响中间识别结果,而不影响最终识别结果。因此,对零填充分块进行解码的中间结果应在后续真实音频到来时被全部丢弃,后续音频理论应从零填充分块的前一个分块(也即已经获取到的、可以进行语音识别的分块,其可以称为当前分块,current chunk)开始解码。为满足这种要求,传统上提出了两种解决方式。一种方式是每次音频到来时,都从音频初始时刻重新解码,这样就不必考虑之前的预测对零填充分块解码的影响。另一种方式是,在对零填充分块进行解码前,对已经解码出的当前分块的结果进行备份,后续真实音频到来时,从备份的状态开始解码,而备份状态后对零填充分块的解码结果将被丢弃。
上述描述的从音频起始时刻重新解码的方法,虽然能保证最终结果不受影响,但容易看出,重头开始处理会有很多冗余操作,计算和内存开销很大。此外,这种开销还会随音频长度增加而增长,虽然模型层面能够让文本被提前解码出来,但很大的计算开销会使解码速度变慢,最终还是会影响语音识别结果的显示速度。第二种方法在对零填充分块解码前,对真实语音的解码结果进行了备份,这样后续音频到来时可以从备份处进行解码而不需重头进行解码,避免了大量的冗余计算。但备份也需要内存开销,此外对零填充分块解码后,解码产生路径对应的所有状态不再需要,需进行删除,也是费时的操作。
有鉴于此,本公开的实施例提供了一种用于语音识别的方法。该方法包括:基于从第一语音中识别到的至少一个第一候选文本序列,向前缀树添加分别表示至少一个第一候选文本序列的至少一个第一节点;基于从第二语音中识别到的至少一个第二候选文本序列,向前缀树添加分别表示至少一个第二候选文本序列的至少一个第二节点,至少一个第二节点被连接到每个第一节点之后,第二语音紧随着第一语音之后被采集;如果前缀树包括多个第一节点,至少基于从前缀树获取的多条第一路径对应的多个文本序列各自的语义,确定多个文本序列各自对应的得分,每条第一路径对应的文本序列至少包括第一节点和与之相连的第二节点所表示的候选文本序列的组合;如果存在得分小于得分阈值的至少一条第一路径,从前缀树删除至少一条第一路径以删除至少一个第一节点,得到更新后的前缀树;以及至少基于更新后的前缀树,从未被删除的至少一个第一节点所表示的至少一个第一候选文本序列中确定与第一语音相匹配的第一目标文本序列。以此方式,本公开的实施例可以利用前缀树结构,通过对前缀树中的各个节点的操作来完成语音识别,可以在保证语音识别结果的准确性的同时,提高语音识别的效率。
以下将继续参考附图描述本公开的一些示例实施例。
图2示出了根据本公开的一些实施例的用于语音识别的过程200的流程图。过程200可以被实现在电子设备110处。为便于讨论,将参考图1的环境100来描述过程200。
在框210,电子设备110基于从第一语音中识别到的至少一个第一候选文本序列,向前缀树添加分别表示至少一个第一候选文本序列的至少一个第一节点。在框220,电子设备110基于从第二语音中识别到的至少一个第二候选文本序列,向前缀树添加分别表示至少一个第二候选文本序列的至少一个第二节点,至少一个第二节点被连接到每个第一节点之后,第二语音紧随着第一语音之后被采集。
这里的第一语音和第二语音可以使存储在电子设备110本地的语音,也可以是电子设备110实时采集到的语音,为了方便表述,下文中的第一语音和第二语音指的是电子设备110实时采集到的语音。
在一些实施例中,电子设备110每次识别的语音的时长是固定的,例如可以固定为预定时长的语音。这里的预定时长可以是用户基于执行语音识别任务的机器学习模型的输入要求等所自行设置的,也可以是电子设备110自行确定的。在这种情况下,第一语音和第二语音例如可以均是满足预定时长的语音。示例性的,若第一语音和第二语音均为实时采集到的语音,则第一语音例如可以为第一时刻前的预定时长内采集到的语音,第二语音例如可以为第一时刻后的预定时长内采集到的语音。
可以理解,电子设备110在第一语音之前和/或第二语音之后还可以采集满足预定时长的第三语音、第四语音等等。在利用机器学习模型来执行语音识别任务时,这样的时长相同(均满足预定时长)的语音也可以被称之为要被提供给机器学习模型的分块,第一语音例如也可以被称之为第一分块,第二语音例如也可以被称之为第二分块等等。
考虑到语音的音准问题(例如发出语音的用户口音不标准所导致的音准问题),电子设备110可以对满足预定时长的语音进行语音识别以生成满足该语音的至少一个第一候选文本序列。在一些实施例中,电子设备110可以将满足预定时长的语音提供给经训练的机器学习模型。机器学习模型对语音进行语音识别并输出与语音对应的至少一个候选文本序列。电子设备110从机器学习模型处获取模型输出,也即获取至少一个候选文本序列。备选地和/或附加地,在一些实施例中,电子设备110还可以利用预先确定的规则和/或算法来对语音进行语音识别以生成至少一个文本序列。示例性的,电子设备110可以对满足预定时长的第一语音进行识别以生成至少一个第一候选文本序列,可以对满足预定时长的第二语音进行识别以生成至少一个第二候选文本序列。
电子设备110可以基于识别出的候选文本序列确定要被添加到前缀树种的节点。前缀树(Trie树,又称单词查找树、键树、字典树等),是一种树形结构,是一种哈希树的变种,是N叉树的一种特殊形式。在一些实施例中,关于向前缀树添加节点的具体方式,针对第一节点,如果第一语音是初始采集到的语音,电子设备110可以将至少一个第一节点连接在前缀树的根节点(被表示为BoS节点)之后。前缀树的根节点不包含字符,也即不包含文本序列。如果第一语音非初始采集到的语音,电子设备110可以将至少一个节点连接到前缀树中在第一语音之前采集到的历史语音对应的每个节点之后。示例性的,若第一语音是紧随着第零语音被采集的语音,电子设备110可以包括至少一个第零节点,至少一个第零节点用于表示与第零语音对应的至少一个第零候选文本序列,至少一个第一节点被连接到每个第零节点之后。类似地,针对第二节点,由于第二语音是紧随着第一语音之后被采集的语音,第二语音非初始采集到的语音,电子设备110可以直接将对应的至少一个第二节点连接到每个第一节点之后。
在一些实施例中,上述的至少一个第一节点也可以统称为第一节点,至少一个第一节点中的每个第一节点也可以称之为上述统称的第一节点所包括的元素。类似地,上述的至少一个第二节点也可以统称为第二节点,至少一个第二节点中的每个第二节点称之为这个统称的第二节点所包括的元素。在这种情况下,也可以将上述过程描述为电子设备110基于从第一语音中识别到的至少一个第一候选文本序列,向前缀树添加表示至少一个第一候选文本序列的第一节点,该第一节点中的每个元素分别用于表示至少一个第一候选文本序列中的一个第一候选文本序列。电子设备110基于从第二语音中识别到的至少一个第二候选文本序列,向前缀树添加表示至少一个第二候选文本序列的第二节点,该第二节点中的每个元素分别用于表示至少一个第二候选文本序列中的一个第二候选文本序列,第二节点被连接到第一节点之后,第二节点所包括的每个元素连接在第一节点的每个元素之后(也即每个第一节点中的元素后均连接有第二节点的全部元素)。
在一些实施例中,由于前缀树中除根节点以外的节点往往仅对应一个字符,与节点对应的候选文本序列(例如第一候选文本序列、第二候选文本序列)例如可以为文本单元。在这种情况下,由于满足预定时长的语音对应的候选文本序列可能包括多个候选文本单元,例如预定时长包括N帧语音,电子设备110可以对每一帧语音进行识别与确定每一帧语音对应的至少一个候选文本单元。示例性的,若第一语音为时长为8帧的语音,针对这8帧中的每一帧语音,电子设备110可以确定该帧语音对应的至少一个候选文本单元。在这种情况下,可以将语音的预定时长确定为第一预定时长,将一帧确定为第二预定时长。电子设备110获取到满足第一预定时长的语音后,对满足第二预定时长的语音进行语音识别(也即对每一帧语音进行语音识别)以确定满足第二预定时长的语音对应的至少一个候选文本单元,并在前缀树中添加表示候选文本单元的至少一个节点。示例性的,电子设备110获取到时长为8帧的语音后,可以将第一帧语音确定为第一语音,并在前缀树中添加表示第一语音的至少一个第一候选文本单元的至少一个第一节点。电子设备110可以将第二帧语音确定为第二语音,并在前缀树中每个第一节点之后添加表示第二帧语音的至少一个第二候选文本单元的至少一个第二节点,等等。
由于满足第一预定时长的语音中可能存在不具有对应候选文本单元的语音(例如第3帧语音无法被识别出候选文本单元),在利用机器学习模型执行语音识别任务时,这种情况可能会导致输入和输出序列长度不一、无法对齐的问题。未解决这样的问题,电子设备110引入了CTC准则,引入了特殊字符“blank”来表示空。CTC准则在解码时计算某一候选识别结果得分的方法为求取可以合并为该候选的所有路径概率之和。假如第一预定时长为5帧,电子设备110确定满足第一预定时长的语音的语音识别结果为ABC,则前缀树中的路经AABC_,A_B_C,AB__C(‘_’表示特殊字符“blank”,每条路径长度等于语音时长5)都是可以合并为ABC的路径,其概率应该加入ABC的得分中。CTC准则路径合并成候选结果的步骤为先将相邻且相同的非特殊字符“blank”合并成一个字符,再去掉所有的特殊字符“blank”符号。
图3示出了根据本公开的一些实施例的示例前缀树300的示意图。如图3所示,前缀树300包括根节点301和其他多个节点。若第一语音为初始采集到的语音,电子设备110从第一语音中识别到文本单元“我”和“卧”后,可以将这两个文本单元分别对应的节点302-1和节点302-2连接在根节点之后。在这种情况下,节点302-1和节点302-2即为第一语音对应的两个第一节点。
若第一语音为非初始采集到的语音,电子设备110例如从第一语音中识别到文本单元“爱”和“唉”后,可以将这两个文本单元分别对应的节点303-1和节点303-2连接到历史语音对应的每个节点之后,也即连接到节点302-1和节点302-2后。在这种情况下,前缀树包括多个节点303-1和多个节点303-2,多个节点303-1和多个节点303-2即为第一语音对应的多个第一节点。在这种情况下,节点302-1后连接后节点303-1和节点303-2,节点302-2后同样连接有节点303-1和节点303-2(图中未示出)。
类似地,若电子设备110从第二语音中识别到文本单元“踢”和“体”,由于这两个文本单元与先前的节点对应的文本单元均不相同,所以可以将这两个文本单元分别对应的节点304-1和节点304-2连接到每个第一语音对应的节点(也即节点303-1和节点303-2)之后,不需要进行合并。每个节点303-1和每个节点303-2后均连接有节点304-1和节点304-2。在这种情况下,前缀树包括多个节点304-1和多个节点304-2,多个节点304-1和多个节点304-2即为第二语音对应的多个第二节点。
返回参考图2,在框230,如果前缀树包括多个第一节点,电子设备110至少基于从前缀树获取的多条第一路径对应的多个文本序列各自的语义,确定多个文本序列各自对应的得分,每条第一路径对应的文本序列至少包括第一节点和与之相连的第二节点所表示的候选文本序列的组合。
如果第一语音是初始采集到的语音,每条第一路径仅包括根节点、一个第一节点和一个第二节点。在这种情况下,每条第一路径对应的文本序列为一个第一文本序列和一个第二文本序列相连接所得到的。如果第一语音非初始采集到的语音,每条第一路径除了包括根节点、一个第一节点和一个第二节点之外,还包括在第一节点和根节点之间的至少一个和历史语音对应的节点。在这种情况下,每条第一路径对应的文本序列为一个第一文本序列、一个第二文本序列以及历史语音对应的一个历史文本序列相连接所得到的。
在一些实施例中,电子设备110确定的多个文本序列各自对应的得分即为这多个文本序列各自的语义得分。电子设备110可以对这多个文本序列进行语义分析以确定每个文本序列对应的语义得分。示例性的,若包含两条第一路径,这两条第一路径对应的文本序列分别为“我爱”和“我唉”,电子设备110可以对这两个文本序列进行语义分析并进行语义打分以确定这两个文本序列分别对应的语义得分。例如,文本序列“我爱”的语义得分为55,文本序列“我唉”的语义得分为15。
在一些实施例中,电子设备110确定的多个文本序列各自对应的得分还包括节点对应的候选文本序列与对应语音的匹配度得分。具体地,电子设备110可以确定多个第一节点对应的多个第一候选文本序列分别与第一语音的多个第一匹配度得分,以及至少一个第二节点对应的至少一个第二候选文本序列分别与第二语音的至少一个第二匹配度得分。匹配度得分可以指示语音被识别为该候选文本序列的概率。示例性的,若电子设备110可以从第一语音识别到两个文本单元“我”和“卧”,电子设备110可以确定第一语音被识别为这两个文本单元各自的概率。例如,第一语音被识别为文本单元“我”的概率为70%,被识别为文本单元“卧”的概率为30%。可以理解,第一语音还可以被识别为其他文本单元,例如还可以被识别为文本单元“窝”。在这种情况下,电子设备110可以确定第一语音被识别为文本单元“我”的概率为55%,被识别为文本单元“卧”的概率为25%,被识别为文本单元“窝”的概率为10%等等。在一些实施例中,在识别出的候选文本序列的数目大于阈值数目的情况下,电子设备110还可以仅将对应的概率(也即匹配度得分)高于匹配度阈值的候选文本序列对应的节点添加至前缀树中。备选地和/或附加地,在一些实施例中,电子设备110还可以基于匹配度得分的数值大小,对与语音对应的多个候选文本序列进行排序。电子设备110例如可以进将匹配度得分最大的几个候选文本序列对应的节点添加至前缀树中。例如可以仅将匹配度得分最大的两个候选文本序列对应的节点添加至前缀树中。
在这种情况下,对于多个第一路径中每条第一路径,电子设备110可以基于该第一路径所包括第一节点对应的第一匹配度得分、第二节点对应的第二匹配度得分以及该第一路径的语义得分,确定该第一路径的得分。每条第一路径的得分例如可以为该条路径中除了根节点之外的所有节点对应的匹配度得分以及语义得分之和。以某条第一路径仅包括根节点、第一节点和第二节点为例,该条第一路径的得分为第一节点对应的第一匹配度得分、第二节点对应的第二匹配度得分以及该第一路径的语义得分之和。
在框240,如果存在得分小于得分阈值的至少一条第一路径,电子设备110从前缀树删除至少一条第一路径以删除至少一个第一节点,得到更新后的前缀树。这里的得分阈值可以是用户预先配置好的,也可以是电子设备110所自行确定的。
如果存在得分小于得分阈值的至少一条第一路径,电子设备110可以通过从前缀树中删除这至少一条第一路径以删除至少一个第一节点。示例性地,若两条第一路径对应的文本序列的得分分别为55和15,且得分阈值为50,则电子设备110可以从前缀树中删除得分为15的第一路径。
在一些实施例中,如果不存在得分小于得分阈值的至少一条第一路径,也即在多条第一路径对应的多个文本序列各自的得分均达到得分阈值的情况下,电子设备110例如可以对这多条第一路径全部进行保留,也即不对前缀树进行更新。示例性的,若两条第一路径对应的文本序列的得分分别为55和60,且得分阈值为50,则电子设备110可以对这两条第一路径全部进行保留,不删除其中的任何一条第一路径。
在一些实施例中,除了基于语义确定路径对应文本序列的得分并基于得分和得分阈值的比较来删除路径之外,电子设备110还可以基于预定数目来删除路径。具体地,针对第一路径,若电子设备110预先获取了针对第一路径的预定数目,前缀数包括的多条第一路径对应的文本序列的得分均达到得分阈值,则电子设备110可以对这多条路径按照得分的大小进行排序,并仅保留排序靠前的、预定数目的至少一个第一路径。也即,电子设备110会删除排序靠后的至少一个第一路径。示例性地,若前缀树共包括6条第一路径,这6条第一路径的文本序列的得分均达到得分阈值(例如得分阈值为5,这6条第一路径对应的得分分别为5.5、6、6、5.5、7、6.5),针对第一路径的余地数目为2,则电子设备110可以仅保留着多条第一路径中对应得分最高的两条第一路径(也即对应得分为7和6.5的两条第一路径),删除剩余的第一路径。
需要注意的是,在第一语音为非初始采集到的语音的情况下,前缀树的多个第一节点之前还连接有与历史语音对应的至少一个节点,电子设备110删除至少一条路径时,仅删除这个至少一条第一路径的第一节点以及第一节点之后所连接的节点,而不删除第一节点之前的节点。
在一些实施例中,若电子设备110在当前时刻获取到了当前时刻之前的预定时长内的语音,并基于这个语音识别到了至少一个候选文本序列,电子设备110可以在前缀树添加表示这至少一个候选文本序列的节点。这样的当前时刻被添加的节点可以被称之为当前时刻的活跃节点。继续参考图3,如图3所示,若当前时刻为T4时刻,则节点305-1和节点305-2为当前时刻的活跃节点。图3中用圆环来表示当前时刻的活跃节点。在一些实施例中,活跃节点还可以包括当前时刻的上一时刻所添加的至少一个节点。具体地,考虑到存在连续两个语音对应的文本序列相同的情况,电子设备110可以基于CTC准则对对应文本序列相同的两个连续节点进行合并。如图3所示,若在T4时刻,电子设备110基于语音确定的文本单元包括文本单元“踢”,由于T3时刻存在文本单元“踢”对应的节点304-1,电子设备110可以不在节点304-1后添加T4时刻获取的文本单元“踢”对应的节点。电子设备110可以直接将T4时刻文本单元“踢”的节点的匹配度分数添加至节点304-1。例如,若在T3时刻节点304-1的匹配度得分为55,在T4时刻文本单元“踢”对应的节点的匹配度得分为35,则在T4时刻电子设备110对节点进行合并后可以使得T3时刻被添加的节点304-1的匹配度得分为90。这里的对匹配度得分进行添加的计算方式例如还可以是乘积,例如,若在T3时刻节点304-1的匹配度得分为0.7,在T4时刻文本单元“踢”对应的节点的匹配度得分为0.5,则在T4时刻对节点进行合并后可以使得T3时刻被添加的节点304-1的匹配度得分为0.35。本公开并不对具体的添加方式进行限定。
在一些实施例中,针对前缀树中除了根节点以外的任意节点,电子设备110可以将节点之前与该节点相连接的节点确定为该节点的父节点,将该节点之后与该节点相连接的节点确定为该节点的子节点。示例性的,节点304-1和节点304-2均为节点303-1的子节点,节点302-1是节点303-1的父节点。
针对前缀树300,在T1时刻,电子设备110从实时获取到的语音可以识别出文本单元“我”和“卧”。电子设备110从根节点301添加与这两个文本单元对应的两个子节点,也即添加节点302-1和节点302-2。在T2时刻,电子设备110从实时获取到的语音可以识别出文本单元“爱”和“唉”。电子设备110将与这两个文本单元对应的节点303-1和303-2添加至每个T1时刻所添加的节点之后。也即将节点303-1和节点303-2添加至节点302-1和节点302-2之后。电子设备110可以得到4个路径,这4个路径对应4个文本序列“我爱”、“我唉”、“卧爱”、“卧唉”。
电子设备110例如可以基于节点的匹配度得分和路径的语义得分确定路径的得分。若文本序列为“我爱”和“我唉”对应的路径的得分为4条路径中得分达到得分阈值、且符合预定数目(例如为2)的两条路径,电子设备110可以将剩余两个路径对应的活节点删除,也即删除该条路径中在T2时刻添加的节点(例如删除连接在节点302-2上的节点303-1和节点303-2)。为了方便表述,下文结合图3来描述路径的删除时,在无特殊示例的情况下,默认针对路径的预定数目为2,且每次有至少2条路径的得分高于得分阈值。电子设备110对前缀树的多条路径进行删除以仅保留对应得分最高、且得分高于得分阈值的两条路径。
进一步地,由于连接在节点302-2上的节点303-1和节点303-2被删除,节点302-2不是当前时刻的活跃节点且没有子节点,电子设备110将节点302-2也从前缀树300中删除。类似地,在T3时刻,若电子设备110得到的多个路径中的文本序列“我爱踢”和“我爱体”对应的得分最高,电子设备110可以删除这两个路径之外的其他路径在T3时刻的活跃节点。电子设备110删除连接在节点302-1之后的节点303-2以及连接在节点303-2之后的节点304-1和节点304-2。在T4时刻,若电子设备110得到的多个路径中的文本序列“我爱踢足”和“我爱踢毽”对应的得分最高,电子设备110可以删除这两个路径之外的其他路径在T4时刻的活跃节点。电子设备110删除连接在节点303-1后节点304-2以及连接在节点304-2之后的节点305-1和节点305-2。
在框250,电子设备110至少基于更新后的前缀树,从未被删除的至少一个第一节点所表示的至少一个第一候选文本序列中确定与第一语音相匹配的第一目标文本序列。
在一些实施例中,如果更新后的前缀树被删除至剩余单个第一节点,电子设备110可以将该单个第一节点对应的第一候选文本序列确定为第一目标文本序列。需要注意的是,剩余单个第一节点不代表包含该第一节点的路径的数目为1。继续参考图3,针对电子设备110在T1时刻在前缀树300上添加的节点302-1和节点302-2,若将这两个节点确定为第一节点,将在T2时刻添加的节点确定为第二节点,则在T2时刻,电子设备110基于路径与路径得分的比较以及预定数目,删除节点302-2以及与其连接的节点303-1和节点303-2。也即电子设备110在T2时刻仅保留节点301-节点302-1-节点303-1和节点301-节点302-1-节点303-2这两条路径。可以发现,此时前缀树300仅包括单个第一节点302-1,但是却包括两条第一路径。
在一些实施例中,电子设备110例如可以执行多轮次的对多个第一节点的删除操作直到前缀树仅包括单个第一节点。在一些实施例中,若通过删除至少一条第一路径来从前缀树删除至少一个第一节点之后,该前缀树包括未被删除的两个以上的第一节点,则电子设备110还可以基于第三语音来继续进行删除操作。
具体地,电子设备110例如可以基于从第三语音中识别到的至少一个第三候选文本序列,向更新后的前缀树添加分别表示至少一个第三候选文本序列的至少一个第三节点。至少一个第三节点被连接到未被删除的至少一个第一节点对应的路径中的每个第二节点之后,第三语音紧随着第二语音之后被采集。如果更新后的前缀树包括两个以上的第一节点,电子设备110可以基于两个以上的第一节点对应的多条第二路径对应的多个文本序列各自的语义,确定多条第二路径对应的多个文本序列各自对应的得分。每条第二路径对应的文本序列至少包括第一节点、与第一节点相连的第二节点和与第二节点相连的第三节点所表示的候选文本序列的组合。电子设备110可以从更新后的前缀树中删除得分小于得分阈值的至少一条第二路径以删除至少一个第一节点,得到再次更新后的前缀树。这里的针对第二路径的得分阈值与前文针对第一路径的得分阈值可以是相同的阈值,也可以是不同的阈值。电子设备110可以至少基于再次更新后的前缀树,从未被删除的至少一个第一节点所表示的至少一个第一候选文本序列中确定与第一语音相匹配的第一目标文本序列。
可以理解,若基于包括第三节点的第二路径对第一节点进行删除操作之后还包括至少两个第一节点,电子设备110还可以基于第四语音、第五语音等继续对第一节点执行删除操作,直至前缀树仅包括单个第一节点。
可以理解,若电子设备110基于第一语音仅识别出了一个第一候选文本序列,也即电子设备110仅在前缀树中添加一个第一节点,电子设备110可以直接将该第一节点对应的第一候选文本序列确定为第一目标文本序列。
在一些实施例中,如果在接下来的预定时长内不再获取到语音,电子设备110例如可以基于至少一个第一候选文本序列中每个第一候选文本序列与第一语音的第一匹配度得分,来从至少一个第一候选文本序列中选择第一目标文本序列。在这种情况下,由于电子设备110在接下来的预定时长内不再获取到语音,电子设备110可以确定语音获取结束,电子设备110进而基于已经获取到的语音来从至少一个第一候选文本序列中选择第一目标文本序列。电子设备110例如可以直接基于每个第一候选文本序列与第一语音的第一匹配度得分,来从至少一个第一候选文本序列中选择第一目标文本序列。电子设备110例如还可以基于前缀树所包括的多个路径中每个路径的得分,将得分最高的路径所包括的第一节点对应的第一候选文本序列确定为第一目标文本序列,其中每个路径至少包括第一节点(例如还可以包括于历史语音对应的历史节点)。第一目标文本序列即为针对第一语音的识别结果。
图4示出了根据本公开的一些实施例的利用机器学习模型执行语音识别任务的过程400的示意图。机器学习模型包括编码器430和解码器460。这里的编码器430和解码器460均可以是可以执行CTC算法的编码器和解码器,编码器430和解码器460例如均可以包括用于执行CTC算法的CTC模块(图中未示出)。
电子设备110可以获取语音流410,这个语音流410例如可以是电子设备110实时采集到的语音流。电子设备110采集语音流410时,可以按照一定的长度和偏移将语音流410分块,比如取长度为25ms的片段提取音频特征(也可以称之为语音特征)。音频特征是一个一维向量,这样语音流410就变成了随时间排列的一个个一维向量,可以用二维向量(T,D)表示,其中T表示时间,D表示特征维度。为了减少计算量和提取更深层的音频特征,电子设备110可以利用卷积神经网络对提取到的音频特征进行降采样,即将多个时刻的特征向量变成一个特征向量,如降采样因子为4,则降采样后的音频特征变成(t,D),其中t=T//4。降采样后的特征按固定的时间长度来被分成不同的分块,如图4所示的分块401、分块402、分块403等。图4所示处的每个分块的大小为8,即8个连续时刻的特征组成一个分块。电子设备110将分块提供给编码器430。编码器430其中的注意力机制及卷积网络可以对音频特征进行编码,并学习到其和建模单元(此处为文本单元或文本序列)的关系,结合CTC模块,输出每个时刻所有建模单元的概率(也即匹配度得分)。也即输出每个时刻对应的多个文本单元各自的匹配度分数。电子设备110可以用二维向量(t,vocab_size+1)表示,其中vocab_size指词典大小,词典中的词以单字表示,一个词典例如可以为[‘我’,‘爱’,‘踢’,‘足’,‘球’,‘毽’,‘子’],此时词典大小为7。由于CTC准则还引入了特殊字符“blank”表示空,所以维度中还需有一位表示特殊字符“blank”的概率。
基于分块的流式实时语音识别要实时给出中间结果,即每来一个分块,电子设备110都需要给出从语音开头到当前分块的识别结果。假设图4中已经采集到的语音降采样后得到16帧,即当前时刻为t15,这些帧构成分块401和分块402,分块402是当前待处理的分块,而分块401是注意力机制中为计算分块402的缓存。假设t0-t15时刻对应原始语音的内容为“我爱踢”的全部发音和“足”的部分发音。由于CTC尖峰延迟问题,在对分块402解码后,识别结果可能是“我爱踢”甚至是“我爱”,相比语音真实内容少了一到两个文本单元。少的文本单元需要后续语音到来,并凑齐一个分块大小(即图中的t23及分块403),才能被确定。这种等待会直接影响用户体验。
在本公开的实施例中,可以结合零填充分块,在当前时刻获取到分块402且为获取到分块403时,直接在分块402后面添加特征为0的8帧,得到分块420(也即零填充分块),利用编码器430和解码器460具有的类似掩码语言模型的预测的能力,对分块420进行编解码,以对分块403对应的内容进行预测。编码器430可以相关联地输出分块402和分块420对应的编码结果440和编码结果450。解码器460可以对这两个编码结果进行解码,以输出与分块402对应的文本识别结果和与分块403对应的预测结果。这样在只获取到t15帧时(也即获取到分块402且未获取到分块403),电子设备110就有可能识别出“我爱踢足”甚至“我爱踢足球”。需要注意的是,这里对分块420的编解码不影响后续获取到分块403后对分块403的编解码。
对于针对分块420和分块403的编解码操作,由于基于零填充分块的解码较为复杂,每次除了解码当前分块(也即分块402)中的帧,还需解码零填充分块(也即分块420)中的帧。电子设备110还需要保证对分块420的解码不会影响分块402中已解码帧的状态,否则分块403解码的初始状态就会发生变化,导致最终识别结果不一致。零填充分块解码对当前分块已解码状态的影响包括两个方面:第一方面,误修改了当前分块最后一帧对应的活跃节点得分;第二方面,误将当前分块活跃节点删除。上述第一方面出现的一种可能情况为,零填充分块第一帧解码所得到的候选文本单元和当前分块的最后一帧解码的候选文本单元相同,这种情况按CTC准则合并后,不会新建节点,当前分块原来保存的得分会被新的得分覆盖。上述第二方面出现的可能情形为,当前分块的活跃节点在后续零填充分块解码过程中,不是活跃节点了,会被裁剪掉而造成误删除。
为了保证对分块420的编解码不会影响对分块403的编解码,本公开的实施例还提出了前缀树节点成员和解码方式。图5示出了根据本公开的一些实施例的前缀树的关键成员500的示意图。针对上述第一方面的问题,电子设备110可以将当前分块解码阶段和零填充分块解码阶段的得分用不同变量(例如图5中所示的real_chunk和zero_chunk)表示,避免误修改问题。由于CTC准则涉及到特殊字符“blank”,所以在解码时电子设备110可以分别计算路径以特殊字符“blank”和不以特殊字符“blank”结尾的两种得分,相加作为候选得分。因为两种得分的计算方式一样,从简洁和通用性考虑,可以统一用“score”表示。每个分块内都是按时间逐帧解码的,当前帧某条路径的得分例如可以等于上一帧对应路径的语义得分与该帧某个建模单元的匹配度得分之和,例如(score(‘CBA’)=score(‘CB’)+prob(‘A’))。因此又分别用“prev”和“cur”保存上一帧和当前帧的路径得分。针对上述第二方面的问题,电子设备110可以使用real_chunk_exists和zero_chunk_exists分别表示在对当前分块和零填充分块解码时,当前节点存在与否。节点如果不存在,不必在物理上从前缀树中直接删除,只需设置这两种标志位即可。只有该节点标志位为假(false)且没有子节点,才需物理上将其删除。在零填充分块解码时规定,只有zero_chunk_exists和real_chunk_exists均为假时,才能在物理上从前缀树中删除。由于当前分块活跃节点的real_chunk_exists为真(true),即使零填充分块解码阶段该节点需删除,也只会将zero_chunk_exists设置为假,因此它在物理上不会被删除。此外,节点中“char”表示当前节点包含的字符(也即文本单元和/或文本序列),“parent”用于指向当前节点的父节点,在获取实时识别结果时,从当前节点按父节点一直回溯到根节点,经过的所有节点中的字符拼接起来并逆序,就是实时识别结果。“children”用以指向当前节点的所有子节点,每个子节点用其字符值和地址的映射表示。
图6示出了根据本公开的某些实施例的前缀树更新的过程600的示意图。当前分块的音频经过特征提取、降采样后,得到T帧。电子设备110在当前分块之后添加长度为T帧、值为0的零填充分块,两者经过编码和CTC后,即得到2T帧的建模单元中每帧建模单元的概率601,也即每帧建模单元的匹配度得分。
在框610,电子设备110获取当前帧建模单元概率。
在框620,电子设备110遍历树获取上一帧解码完后的活跃节点(S_active)。
在框630,电子设备110取当前帧中概率最高的N1个建模单元得到集合(top_ele)。
在框640,电子设备110对集合中每个元素(ele),分别确定活跃节点中每个元素和其合并后的树节点,并更新相应的得分。
在框650,电子设备110遍历树并将得分最高的N2个树节点设置为真,其他设置为假,删除冗余节点。
在框660,电子设备110判断当前帧是否是零填充分块的最后一帧。
在框670,如果当前帧是零填充分块的最后一帧,则实时解码完毕,找到树中得分最高节点,回溯得到实时识别结果。否则,在框680,电子设备110将下一帧作为当前帧来继续处理下一帧。上述是解码流程的抽象概括,因为零填充分块实时识别解码要考虑之前所说的当前分块得分误修改和节点误删除问题。因此图6中上述步骤在当前分块和零填充分块解码阶段处理逻辑也不相同。具体如下(为便于描述,对当前分块进行解码简称阶段一,对零填充分块解码简称阶段二):
首先,阶段一选取real_chunk_exists为真的节点作为活跃节点;阶段二选取zero_chunk_exists为真的节点作为活跃节点。
其次,阶段一活跃节点中元素(已解码路径)和元素合并后得到的新路径在树中对应的节点(已存在或新增得到),其real_chunk_score_cur和zero_chunk_score_cur值均设置为活跃节点中元素real_chunk_scroe_prev值与元素概率之和,real_chunk_exists和zero_chunk_exists均设置为真。阶段一节点中零填充分块和当前分块相关的值保持一致,是为了使用零填充分块相关的值进行阶段二的解码。阶段二将解码中间结果保存在零填充分块相关的变量中,如果合并后得到的新路径对应的节点在树中已存在,只利用zero_chunk_score_pre更新zero_chunk_score_cur的值,同时将zero_chunk_exists设置为真。如果合并后节点在树中不存在,则新建树节点,新节点中零填充分块相关的值修改方法和节点已存在的情况一致。而当前分块相关的得分均设置为0,并且real_chunk_exists设置为假,表示该节点不是在当前分块解码时创建的,便于后续删除的处理。容易看出,因为阶段一和阶段二解码的得分用zero_chunk_score和real_chunk_score分别表示,就不会出现real_chunk_score被误修改的情况。
第三,合并并更新节点的real_chunk_score_cur和zero_chunk_score_cur后,需通过任意适当的裁剪方式(例如波束(beam)裁剪)确定当前帧解码后的较优解码路径,作为下一帧解码的初始候选路径。这里的裁剪指的就是上述的对前缀树中的节点和路径进行的删除操作。阶段一将裁剪后保留节点的real_chunk_exists和zero_chunk_exists均设置为真,其他节点这两种变量设置为假,如果某节点real_chunk_exits为假,并且没有子节点,则将该节点从树中删除。阶段二将裁剪后保留节点的zero_chunk_exitsts设置为真,其他节点的zero_chunk_exitsts设置为假,而real_chunk_exists保持不变,只有节点的zero_chunk_exists和real_chunk_exists均为假,并且没有子节点时,才能将其从树中删除,这样当前分块解码阶段保留的候选节点就不会在零填充分块阶段解码时被误删除(因为real_chunk_exists为真)。此外,为提高解码效率,在基于直方图裁剪方法的基础上,本发明引入基于阈值的裁剪,设置得分阈值s_threshold,如果节点的score_cur小于树中活跃节点最大的score_cur与s_threshold的差值,则该节点不能作为解码后的活跃节点。
第四,阶段一和阶段二解码结束后,找到zero_chunk_score_cur最高的树节点,往前回溯到根节点,回溯路径中所有节点的字符字段拼接起来并逆序,即为基于提示的语音识别的实时结果。之所以选择zero_chunk_score_cur最大的节点,是因为他记录了阶段一和阶段二所有帧解码形成的最优候选。
由此,本公开的实施例通过对树节点中得分和节点是否存在成员的特殊设计,以及不同解码阶段对成员变量值的不同更新策略,解决了基于树结构解码中误修改和删除当前分块活跃节点的问题。
上述描述了电子设备110对语音流进行编解码以及对前缀树进行更新的详细内容,下面来描述这样的语音识别的一种示例场景。在一些实施例中,这样的语音识别方案可以被应用于会议场景。例如,若参与会议的人员期望电子设备110可以实时采集会议人员的语音并呈现相应的文本序列的情况下,电子设备110可以采用这样的语音识别方案来执行语音识别任务。
在这样的场景中,电子设备110可以在用户界面实时地呈现与用户的语音相对应的文本序列,这样的文本序列例如也可以被称之为字幕。这样的用户界面例如可以为会议应用的用户界面。
在一些实施例中,在未确定第一目标文本序列之前(也即在获取第一语音且基于第一语音识别出至少一个第一候选文本序列后),电子设备110可以基于至少一个第一候选文本序列中各自与第一语音的第一匹配度得分,从至少一个第一候选文本序列中选择要被呈现在用户界面中的第一文本序列。示例性的,电子设备110可以将至少一个第一候选文本序列中第一匹配度得分最高的一个第一候选文本序列确定为要被呈现在用户界面中的第一文本序列。在一些实施例中,除了匹配度得分,电子设备110还可以对至少一个第一候选文本序列进行语义分析以确定至少一个第一候选文本序列各自对应的语义得分。电子设备110进而可以对至少一个第一候选文本序列中每个第一候选文本序列对应的语义得分和第一匹配度得分进行累加,并将累加后得到的得分(也即第一候选文本序列对应的第一匹配度得分+第一候选文本序列对应的语义得分)最高的第一候选文本序列确定为第一文本序列。可以理解,后续针对第二文本序列的确定等同样可以结合候选文本序列对应的语义得分。
在一些实施例中,在第一语音之后未采集到具有预定时长的第二语音的情况下,电子设备110至少基于第一文本序列来生成与第二语音相对应的预测文本序列。具体地,在第一语音为初始采集到的语音的情况下,电子设备110可以基于第一文本序列来生成预测文本序列。这里具体的预测方式可以为上述所介绍的基于当前分块和零填充分块来预测零填充分块对应的分块的方式。在第一语音为非初始采集到的语音的情况下,电子设备110可以基于第一文本序列以及历史文本序列来生成预测文本序列。这里的历史文本序列例如可以是前缀树中对应得分最高的路径对应的历史文本序列。电子设备110进而在用户界面呈现第一文本序列和预测文本序列。
在一些实施例中,在采集到第二语音并识别到至少一个第二候选文本序列之后,电子设备110还可以基于至少一个第二候选文本序列各自与第二语音的第二匹配度得分,从至少一个第二候选文本序列选择要被呈现在用户界面中的第二文本序列。示例性的,电子设备110可以将至少一个第二候选文本序列中第二匹配度得分最高的一个第二候选文本序列确定为第二文本序列。如果预测文本序列与第二文本序列不同,电子设备110可以在用户界面将预测文本序列切换为第二文本序列。
进一步地,如果所确定的第一目标文本序列与第一文本序列不同,电子设备110还可以在确定第一目标文本序列之后将用户界面中呈现的第一文本序列切换为第一目标文本序列。示例性的,若电子设备110先前呈现的是第一文本序列以及第二文本序列,响应于第一目标文本序列与第一文本序列不同,电子设备110可以切换至呈现第一目标文本序列和第二文本序列。
由此,可以实现实时呈现语音对应的字幕,且可以自行将字幕中呈现的错误的文本序列切换至正确的文本序列,有助于提示用户的用户体验。
综上所述,本公开的实施例可以利用前缀树结构,通过对前缀树中的各个节点的操作来完成语音识别,可以在保证语音识别结果的准确性的同时,提高语音识别的效率。
本公开的实施例还提供了用于实现上述方法或过程的相应装置。图7示出了根据本公开的某些实施例的用于语音识别的装置700的示意性结构框图。装置700可以被实现为或者被包括在电子设备110中。装置700中的各个模块/组件可以由硬件、软件、固件或者它们的任意组合来实现。
如图7所示,装置700包括第一节点添加模块710,被配置为基于从第一语音中识别到的至少一个第一候选文本序列,向前缀树添加分别表示至少一个第一候选文本序列的至少一个第一节点。装置700还包括第二节点添加模块720,被配置为基于从第二语音中识别到的至少一个第二候选文本序列,向前缀树添加分别表示至少一个第二候选文本序列的至少一个第二节点,至少一个第二节点被连接到每个第一节点之后,第二语音紧随着第一语音之后被采集。装置700还包括得分确定模块730,被配置为如果前缀树包括多个第一节点,至少基于从前缀树获取的多条第一路径对应的多个文本序列各自的语义,确定多个文本序列各自对应的得分,每条第一路径对应的文本序列至少包括第一节点和与之相连的第二节点所表示的候选文本序列的组合。装置700还包括前缀树更新模块740,被配置为如果存在得分小于得分阈值的至少一条第一路径,从前缀树删除至少一条第一路径以删除至少一个第一节点,得到更新后的前缀树。装置700还包括文本序列确定模块750,被配置为至少基于更新后的前缀树,从未被删除的至少一个第一节点所表示的至少一个第一候选文本序列中确定与第一语音相匹配的第一目标文本序列。
在一些实施例中,装置700还包括:第一文本序列确定模块,被配置为如果前缀树包括单个第一节点,将单个第一节点对应的第一候选文本序列确定为与第一语音相匹配的第一目标文本序列。
在一些实施例中,得分确定模块730包括:匹配度得分确定模块,被配置为确定多个第一节点对应的多个第一候选文本序列分别与第一语音的多个第一匹配度得分,以及至少一个第二节点对应的至少一个第二候选文本序列分别与第二语音的至少一个第二匹配度得分;语义得分确定模块,被配置为基于多条第一路径对应的多个文本序列各自的语义,确定多个文本序列各自的语义得分;确定模块,被配置为对于多个第一路径中每条第一路径,基于该第一路径所包括第一节点对应的第一匹配度得分、第二节点对应的第二匹配度得分以及该第一路径的语义得分,确定该第一路径的得分。
在一些实施例中,文本序列确定模块750包括:第三节点添加模块,被配置为基于从第三语音中识别到的至少一个第三候选文本序列,向更新后的前缀树添加分别表示至少一个第三候选文本序列的至少一个第三节点,至少一个第三节点被连接到未被删除的至少一个第一节点对应的路径中的每个第二节点之后,第三语音紧随着第二语音之后被采集;第二得分确定模块,被配置为如果更新后的前缀树包括两个以上的第一节点,基于两个以上的第一节点对应的多条第二路径对应的多个文本序列各自的语义,确定多条第二路径对应的多个文本序列各自对应的得分,每条第二路径对应的文本序列至少包括第一节点、与第一节点相连的第二节点和与第二节点相连的第三节点所表示的候选文本序列的组合;节点删除模块,被配置为如果存在得分小于得分阈值的至少一条第二路径,来从更新后的前缀树中删除至少一个第一节点,得到再次更新后的前缀树;以及目标文本序列确定模块,被配置为至少基于再次更新后的前缀树,从未被删除的至少一个第一节点所表示的至少一个第一候选文本序列中确定与第一语音相匹配的第一目标文本序列。
在一些实施例中,文本序列确定模块750包括:第一确定模块,被配置为如果更新后的前缀树被删除至剩余单个第一节点,将单个第一节点对应的第一候选文本序列确定为第一目标文本序列;以及第二确定模块,被配置为如果在接下来的预定时长内不再获取到语音,基于至少一个第一候选文本序列中每个第一候选文本序列与第一语音的第一匹配度得分,来从至少一个第一候选文本序列中选择第一目标文本序列。
在一些实施例中,第一语音和第二语音均是满足预定时长的语音。
在一些实施例中,第一语音和第二语音均为实时采集到的语音,第一语音为第一时刻前的预定时长内采集到的语音,第二语音为第一时刻后的预定时长内采集到的语音。
在一些实施例中,第一节点添加模块710包括:第一连接模块,被配置为如果第一语音是初始采集到的语音,将至少一个第一节点连接在前缀树的根节点之后;以及第二连接模块,被配置为如果第一语音非初始采集到的语音,将至少一个节点连接到前缀树中在第一语音之前采集到的历史语音对应的每个节点之后。
在一些实施例中,装置700还包括:第一选择模块,被配置为在未确定第一目标文本序列之前,基于至少一个第一候选文本序列中各自与第一语音的第一匹配度得分,从至少一个第一候选文本序列中选择要被呈现在用户界面中的第一文本序列。
在一些实施例中,装置700还包括:预测文本序列生成模块,被配置为在第一语音之后未采集到具有预定时长的第二语音的情况下,至少基于第一文本序列来生成与第二语音相对应的预测文本序列;以及第一呈现模块,被配置为在用户界面呈现第一文本序列和预测文本序列。
在一些实施例中,装置700还包括:第二选择模块,被配置为在采集到第二语音并识别到至少一个第二候选文本序列之后,基于至少一个第二候选文本序列各自与第二语音的第二匹配度得分,从至少一个第二候选文本序列选择要被呈现在用户界面中的第二文本序列;以及第一切换模块,被配置为如果预测文本序列与第二文本序列不同,在用户界面将预测文本序列切换为第二文本序列。
在一些实施例中,装置700还包括:第二切换模块,被配置为如果所确定的第一目标文本序列与第一文本序列不同,在确定第一目标文本序列之后将用户界面中呈现的第一文本序列切换为第一目标文本序列。
在一些实施例中,用户界面包括会议应用的用户界面。
装置700中所包括的单元和/或模块可以利用各种方式来实现,包括软件、硬件、固件或其任意组合。在一些实施例中,一个或多个单元和/或模块可以使用软件和/或固件来实现,例如存储在存储介质上的机器可执行指令。除了机器可执行指令之外或者作为替代,装置700中的部分或者全部单元和/或模块可以至少部分地由一个或多个硬件逻辑组件来实现。作为示例而非限制,可以使用的示范类型的硬件逻辑组件包括现场可编程门阵列(FPGA)、专用集成电路(ASIC)、专用标准品(ASSP)、片上系统(SOC)、复杂可编程逻辑器件(CPLD),等等。
应当理解,以上方法中的一个或多个步骤可以由适当的电子设备或电子设备的组合来执行。这样的电子设备或电子设备的组合例如可以包括图1中的电子设备110。
图8示出了其中可以实施本公开的一个或多个实施例的电子设备800的框图。应当理解,图8所示出的电子设备800仅仅是示例性的,而不应当构成对本文所描述的实施例的功能和范围的任何限制。图8所示出的电子设备800可以用于实现图1的电子设备110或图7的装置700。
如图8所示,电子设备800是通用电子设备的形式。电子设备800的组件可以包括但不限于一个或多个处理器或处理单元810、存储器820、存储设备830、一个或多个通信单元840、一个或多个输入设备850以及一个或多个输出设备860。处理单元810可以是实际或虚拟处理器并且能够根据存储器820中存储的程序来执行各种处理。在多处理器系统中,多个处理单元并行执行计算机可执行指令,以提高电子设备800的并行处理能力。
电子设备800通常包括多个计算机存储介质。这样的介质可以是电子设备800可访问的任何可以获得的介质,包括但不限于易失性和非易失性介质、可拆卸和不可拆卸介质。存储器820可以是易失性存储器(例如寄存器、高速缓存、随机访问存储器(RAM))、非易失性存储器(例如,只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、闪存)或它们的某种组合。存储设备830可以是可拆卸或不可拆卸的介质,并且可以包括机器可读介质,诸如闪存驱动、磁盘或者任何其他介质,其可以能够用于存储信息和/或数据并且可以在电子设备800内被访问。
电子设备800可以进一步包括另外的可拆卸/不可拆卸、易失性/非易失性存储介质。尽管未在图8中示出,可以提供用于从可拆卸、非易失性磁盘(例如“软盘”)进行读取或写入的磁盘驱动和用于从可拆卸、非易失性光盘进行读取或写入的光盘驱动。在这些情况中,每个驱动可以由一个或多个数据介质接口被连接至总线(未示出)。存储器820可以包括计算机程序产品825,其具有一个或多个程序模块,这些程序模块被配置为执行本公开的各种实施例的各种方法或动作。
通信单元840实现通过通信介质与其他电子设备进行通信。附加地,电子设备800的组件的功能可以以单个计算集群或多个计算机器来实现,这些计算机器能够通过通信连接进行通信。因此,电子设备800可以使用与一个或多个其他服务器、网络个人计算机(PC)或者另一个网络节点的逻辑连接来在联网环境中进行操作。
输入设备850可以是一个或多个输入设备,例如鼠标、键盘、追踪球等。输出设备860可以是一个或多个输出设备,例如显示器、扬声器、打印机等。电子设备800还可以根据需要通过通信单元840与一个或多个外部设备(未示出)进行通信,外部设备诸如存储设备、显示设备等,与一个或多个使得用户与电子设备800交互的设备进行通信,或者与使得电子设备800与一个或多个其他电子设备通信的任何设备(例如,网卡、调制解调器等)进行通信。这样的通信可以经由输入/输出(I/O)接口(未示出)来执行。
根据本公开的示例性实现方式,提供了一种计算机可读存储介质,其上存储有计算机可执行指令,其中计算机可执行指令被处理器执行以实现上文描述的方法。根据本公开的示例性实现方式,还提供了一种计算机程序产品,计算机程序产品被有形地存储在非瞬态计算机可读介质上并且包括计算机可执行指令,而计算机可执行指令被处理器执行以实现上文描述的方法。
这里参照根据本公开实现的方法、装置、设备和计算机程序产品的流程图和/或框图描述了本公开的各个方面。应当理解,流程图和/或框图的每个方框以及流程图和/或框图中各方框的组合,都可以由计算机可读程序指令实现。
这些计算机可读程序指令可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理单元,从而生产出一种机器,使得这些指令在通过计算机或其他可编程数据处理装置的处理单元执行时,产生了实现流程图和/或框图中的一个或多个方框中规定的功能/动作的装置。也可以把这些计算机可读程序指令存储在计算机可读存储介质中,这些指令使得计算机、可编程数据处理装置和/或其他设备以特定方式工作,从而,存储有指令的计算机可读介质则包括一个制造品,其包括实现流程图和/或框图中的一个或多个方框中规定的功能/动作的各个方面的指令。
可以把计算机可读程序指令加载到计算机、其他可编程数据处理装置、或其他设备上,使得在计算机、其他可编程数据处理装置或其他设备上执行一系列操作步骤,以产生计算机实现的过程,从而使得在计算机、其他可编程数据处理装置、或其他设备上执行的指令实现流程图和/或框图中的一个或多个方框中规定的功能/动作。
附图中的流程图和框图显示了根据本公开的多个实现的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或指令的一部分,模块、程序段或指令的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
以上已经描述了本公开的各实现,上述说明是示例性的,并非穷尽性的,并且也不限于所公开的各实现。在不偏离所说明的各实现的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实现的原理、实际应用或对市场中的技术的改进,或者使本技术领域的其他普通技术人员能理解本文公开的各个实现方式。
- 测定图像管理用服务器、测定图像管理系统及方法
- 图像管理系统、图像管理服务器、图像管理方法及生产图像管理系统的方法