一种基于深度学习的电单车剩余里程估计方法及系统
文献发布时间:2023-06-19 11:08:20
技术领域
本发明属于电单车数据分析技术领域,具体涉及一种基于深度学习的电单车剩余里程估计方法及系统。
背景技术
目前,电单车的使用越来越普及,为人们的出行带来了便捷,同时也减轻了环境污染。但是,电单车在行驶中存在剩余里程难确定的问题,容易让驾驶者产生“里程焦虑”。据调研,目前针对电动车的剩余里程估计方法研究较多,但缺乏针对电单车的剩余里程估计方法的研究,不过两者的剩余里程估计方法能够互相借鉴。
现有剩余里程估计方法主要分为3类:间接估计、直接估计和智能估计。
其中,间接估计是目前产业界普遍使用的方法,主要包括:单一影响因素检测估计法和综合影响因素检测估计法。单一影响因素检测估计法是:检测端电压,间接得到开路电压,再间接得到剩余电量SOC(StateofCharge)的取值,进而估计剩余里程,该方法虽然比较简单快捷,但是误差很大。综合影响因素检测估计法是:综合考虑影响SOC的因素,预测SOC值,进而估计剩余里程,由于影响SOC的因素很多且难以直接检测,因此估计的剩余里程和实际工况中的剩余里程会有一定的误差。
直接估计主要是基于剩余里程表征参数(如,标准里程、路况和SOC等),人工分析参数之间的关系,建立数学模型估计剩余里程,该类方法虽然误差较小,但是数学模型复杂、计算量大、对硬件要求高,其成本也相对较高。
智能估计主要是使用不同的算法去分析某两个剩余里程表征参数之间的关系,或分析某一个剩余里程表征参数与剩余里程之间的关系,进而建立模型估计剩余里程,该类方法虽然一定程度上减少了的模型复杂度和计算量,但是忽略了其他剩余里程表征参数的影响,模型的普适性弱且估计的剩余里程和实际的剩余里程会存在一定误差。
综上,现有的剩余里程估计方法还存在着误差较大、数学模型复杂、计算量大和对所需成本高等问题。
发明内容
有鉴于此,本发明提供了一种基于深度学习的电单车剩余里程估计方法及系统,能够实现基于电单车的基本信息及当前行驶时刻的行驶数据估计得到电单车当前的剩余里程。
本发明提供的一种基于深度学习的电单车剩余里程估计方法,包括以下步骤:
步骤1、对电单车剩余里程表征数据的初始样本进行数据预处理得到中间样本,将所述中间样本分类得到不同车型的分类样本;设定所述分类样本中每个数据的权值,对所述分类样本中同一行驶时刻的数据加权求和后,再采用虚假最近邻点算法处理得到重构样本;所述电单车剩余里程表征数据包括车辆铭牌数据及实时行驶数据;
步骤2、基于卷积神经网络建立平均功耗模型,基于BiLSTM建立统计电量模型;采用所述重构样本训练所述平均功耗模型得到各类电单车的最优平均功耗模型,采用所述分类样本训练所述统计电量模型得到各类电单车的最优统计电量模型;
步骤3、应用中,根据待估计剩余里程电单车的型号,选择对应的最优平均功耗模型及最优统计电量模型;将所述待估计剩余里程电单车的当前行驶时刻的剩余里程表征进行数据预处理后分别输入最优平均功耗模型及最优统计电量模型,分别得到所述待估计剩余里程电单车在当前行驶时刻的平均功耗值及统计电量值;计算所述统计电量值与平均功耗值的比值,即可得到所述待估计剩余里程电单车在当前行驶时刻的剩余里程值。
进一步地,所述步骤2中基于卷积神经网络建立平均功耗模型,所述卷积神经网络为去掉池化层的新卷积神经网络。
进一步地,所述新卷积神经网络的训练过程为:所述步骤1中采用虚假最近邻点算法处理得到重构样本的同时还要得到滑动窗口,采用所述重构样本,并以所述滑动窗口作为所述新卷积神经网络的步长,训练所述新卷积神经网络得到所述最优平均功耗模型。
进一步地,所述电单车剩余里程表征数据包括车型、电池出厂时间、电机出厂时间、额定电池容量、额定功率、工作温度、变转矩频率、恒功率频率、整车质量、原始车胎状态、行驶里程、环境温度、普遍工况、行驶速度、行驶电压、行驶电流、行驶剩余电量、载重、循环充放电次数、车灯耗电量和行驶车胎状态。
进一步地,所述步骤1与步骤3中的数据预处理包括数据清洗、数据变换和数据集合。
本发明提供的一种基于深度学习的电单车剩余里程估计系统,包括数据处理模块、平均功耗计算模块、统计电量计算模块及剩余里程计算模块;
其中,所述数据处理模块,用于对电单车剩余里程表征数据进行数据预处理得到待分析数据;对训练样本进行数据预处理得到中间样本,将中间样本分类得到不同车型的分类样本,对分类样本中同一行驶时刻的数据加权求和后,再采用虚假最近邻点算法处理得到重构样本;
所述平均功耗计算模块,包含多个针对不同型号的电单车的平均功耗计算子模块;采用所述数据处理模块输出的重构样本对平均功耗计算子模型进行训练;将所述数据处理模块输出的所述待分析数据输入对应型号的训练得到的平均功耗计算子模块中,计算得到电单车平均功耗;
所述统计电量计算模块,包含多个针对不同型号的电单车的统计电量计算子模块;采用所述数据处理模块输出的重构样本对统计电量计算子模块进行训练;将所述数据处理模块输出的所述待分析数据输入对应型号的训练得到的统计电量计算子模块中,计算得到电单车统计电量;
所述剩余里程计算模块,用于根据平均功耗计算模块输出的所述电单车平均功耗及所述统计电量计算模块输出的所述电单车统计电量,计算所述统计电量值与所述平均功耗值的比值得到电单车的剩余里程。
进一步地,所述数据处理模块中的数据预处理的方式为:数据清洗、数据变换和数据集合。
有益效果:
本发明通过采用深度学习的方法分析海量表征数据,智能的分析出每个表征数据之间的关系,使用简单的模型即可完成复杂的任务,相比于传统方法中的人工分析过程电单车剩余里程表征数据之间的物理关系再建立复杂的模型的方式,有效降低了运算量和模型的复杂程度,提高了计算的准确率,使电单车剩余里程的估计更加高效便捷。
附图说明
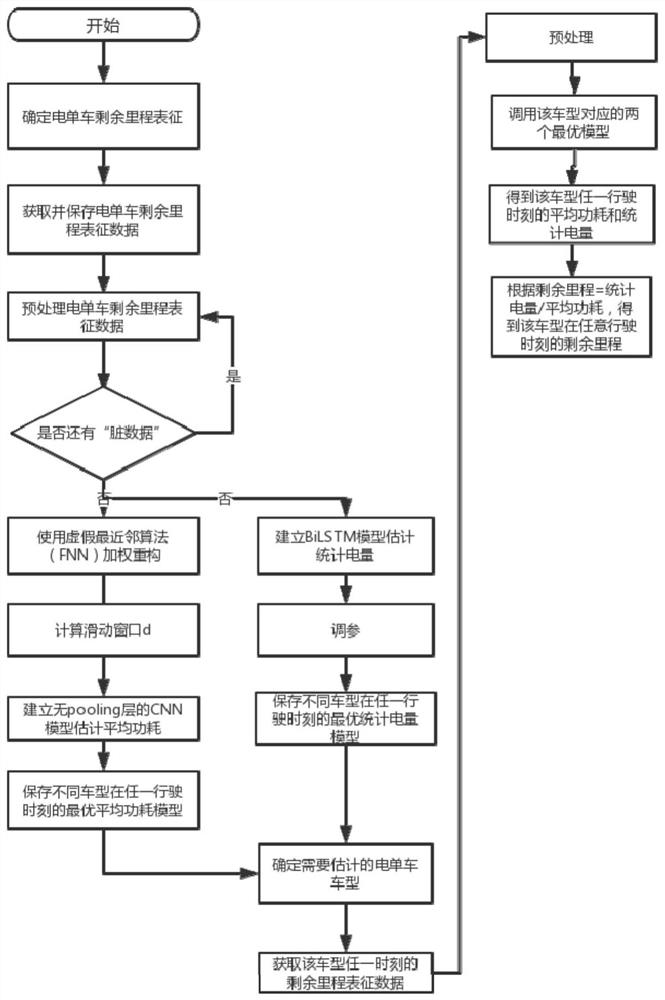
图1为本发明提供的一种基于深度学习的电单车剩余里程估计方法的流程图。
图2为本发明提供的一种基于深度学习的电单车剩余里程估计方法的电单车剩余里程表征的数据处理流程图。
具体实施方式
下面结合附图并举实施例,对本发明进行详细描述。
为了实现更加准确的剩余里程估计,首先需要确定电单车的剩余里程表征数据,通过对相关文献的调研和多年积累的研究经验,本发明确定了影响电单车剩余里程的表征数据包括:铭牌数据和实时行驶数据。
其中,铭牌数据,包括车型、电池出厂时间、电机出厂时间、额定电池容量、额定功率、工作温度、变转矩频率、恒功率频率、整车质量、原始车胎状态。实时行驶数据,包括行驶里程、环境温度、普遍工况、行驶速度、行驶电压、行驶电流、行驶剩余电量、载重、循环充放电次数、车灯耗电量、行驶车胎状态,出发地、目的地、使用时长。
考虑到影响电单车剩余里程的表征数据很多,本发明确定的电单车剩余里程表征数据是对实际的电单车剩余里程影响较大的。在确定电单车剩余里程表征数据时,遵循的原则是包括但不仅限于上述电单车剩余里程表征数据,电单车剩余里程表征数据选取的越多估计结果越准确。
本发明提供的一种基于深度学习的电单车剩余里程估计方法,如图1所示,具体包括以下步骤:
步骤1、对获取到的电单车剩余里程表征数据的初始样本进行数据清洗、数据变换和数据集合得到中间样本,将中间样本分类得到不同车型的分类样本;设定分类样本中每个数据的权值,对分类样本中同一行驶时刻的数据加权求和后,再采用虚假最近邻点算法处理得到重构样本;电单车剩余里程表征数据包括车辆铭牌数据及实时行驶数据。
电单车剩余里程表征数据的获取方式,包括:通过人工读取等方式,获得不同车型的车辆铭牌数据,并保存至后台数据存储中心;通过实时检测不同车型在任一行驶时刻的实时行驶数据,通过无线通信的方式保存到后台数据存储中心。
对电单车剩余里程表征数据的初始样本进行数据预处理得到中间样本的过程,如图2所示,为从后台数据存储中心获取不同车型的剩余里程表征数据,然后对不同车型的剩余里程表征数据,使用python内置库numpy和pandas进行数据清洗、数据变换和数据集合操作,本发明中的数据预处理包括数据清洗、数据变换和数据集合。具体包括:
步骤1.1、调用df.dropnull()函数去除数据缺失值;
步骤1.2、检查是否有格式和内容错误的数据,使用python库统一调整错误格式和用null替换内容错误的数据;
步骤1.3、去除逻辑错误,如数据值偏离正常值,则对类别数据使用Onehot进行编码,对文本数据使用Labelhot进行编码;然后,对处理后的数据进行归一化,即将数据投影到(0,1)区间内;
步骤1.4、对处理完的数据根据不同的车型分类保存数据。
本发明中,为了体现不同数据的重要程度,提出了在虚假最近邻(FNN)算法中融入加权求和的思想,基于此重新划分组合数据实现样本重构。其中,加权求和是指对所有剩余里程表征数据,根据其影响剩余里程变化的程度高低,赋予每个剩余里程表征数据不同的初始权重值,影响程度高的权重值高,影响程度低的权重值小,权重之和应等于1,进而得到加权样本,然后使用虚假最近邻(FNN)算法对加权样本进行处理。重构样本的相邻两条数据之间的关系性会更大。
具体来说,使用虚假最近邻算法(FNN)对预输入数据进行加权重构的过程,包括:
步骤1.5、针对某一车型的剩余里程表征数据,初始化每个剩余里程表征数据的权重,根据经验,判断每个剩余里程表征数据影响剩余里程估计的程度,影响程度高的赋予大权重,影响程度小的赋予小权重,即,每个剩余里程表征数据的权重可以表示为:w
对某一行驶时刻的剩余里程表征数据采用上述权重进行加权求和,然后采用FNN算法划分样本重新划分样本,可取前2/3的数据为训练集,后1/3为验证集。
步骤1.6、设置初始滑动窗口d=1,构造样本向量,计算虚假最近邻向量的个数,计算样本向量和虚假最近邻向量的欧氏距离,然后得出虚假最近邻向量的个数,滑动窗口d增加1,重复步骤1.6,直到虚假最近邻向量个数减少到趋近于0,此时,d即为所求的滑动窗口大小,根据d的大小重构样本,重复上述操作,完成所有车型的样本重构和滑动窗口大小的计算。
步骤2、基于卷积神经网络建立平均功耗模型,基于BiLSTM建立统计电量模型;采用重构样本训练平均功耗模型得到各类电单车的最优平均功耗模型,采用分类样本训练统计电量模型得到各类电单车的最优统计电量模型。
本发明为了进一步减轻重叠卷积操作、减少计算量,还可将卷积神经网络中的池化层去掉,以此作为平均功耗模型。此时,步骤1中计算得到的滑动窗口则可作为无pooling层的CNN模型的步长。
步骤3、应用中,根据待估计剩余里程电单车的型号,选择对应的最优平均功耗模型及最优统计电量模型;将待估计剩余里程电单车的当前行驶时刻的剩余里程表征数据进行数据清洗、数据变换和数据集合后分别输入最优平均功耗模型及最优统计电量模型,分别得到待估计剩余里程电单车在当前行驶时刻的平均功耗值及统计电量值;计算统计电量值与平均功耗值的比值,即可得到待估计剩余里程电单车在当前行驶时刻的剩余里程值。
本发明中,统计电量是指不同车型在任一行驶时刻的剩余电量估计值;平均功耗是指不同车型在任一行驶时刻的行车功耗,包括行驶功耗、车灯功耗、制动功耗等。
基于本发明提供的一种基于深度学习的电单车剩余里程估计方法,本发明提出了一种基于深度学习的电单车剩余里程估计系统,包括:数据处理模块、平均功耗计算模块、统计电量计算模块及剩余里程计算模块。
其中,数据处理模块,用于对电单车剩余里程表征数据进行数据预处理得到待分析数据;用于对训练样本进行数据预处理得到中间样本,再将中间样本分类得到不同车型的分类样本,对分类样本中同一行驶时刻的数据加权求和后,再采用虚假最近邻点算法处理得到重构样本。
平均功耗计算模块,包含多个针对不同型号的电单车的平均功耗计算子模块,采用数据处理模块输出的重构样本对平均功耗计算子模型进行训练;将数据处理模块输出的待分析数据输入其对应的平均功耗计算子模块中,计算得到电单车的平均功耗。平均功耗计算子模块为基于卷积神经网络建立的平均功耗模型。
统计电量计算模块,包含多个针对不同型号的电单车的统计电量计算子模块,采用数据处理模块输出的重构样本对统计电量计算子模块进行训练;将数据处理模块输出的待分析数据输入其对应的统计电量计算子模块中,计算得到电单车的统计电量。统计电量计算子模块为基于BiLSTM建立的统计电量模型。
剩余里程计算模块,用于根据平均功耗计算模块输出的电单车的平均功耗及统计电量计算模块输出的电单车统计电量,计算统计电量值与平均功耗值的比值得到电单车的剩余里程。
综上,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于深度学习的电单车剩余里程估计方法及系统
- 基于电动客车动态过程质量估计的剩余里程计算方法