一种化学分子性质预测的方法、系统及介质
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及化学分子的性质预测和深度学习技术领域,具体是一种化学分子性质预测的方法、系统及介质。
背景技术
无论是在药物还是在材料研发的过程中,不可避免的是大量测试分子的活性、毒性等分子的相关特性,通过测试来筛选出符合预期的分子作为候选分子。但是这需要研发人员经过大量实验进行验证。这就导致了大量的人力物力的成本付出。除此之外,查阅相关文献,相似反应的经验积累、以及对反应物的化学机理的理解都可以在分子性质预测中发挥重要作用,但是这也对相关实验人员提出了非常高的专业素养。
随着深度学习技术的快速发展,以及相关方向的数据不断地积累,通过数据挖掘的方式来对未知分子的性质进行预测变为可能。很多化学专家都选择借助深度学习技术作为辅助技术,其效果在化工领域都得到验证。但分子的性质预测对数据集样本量具有非常高的要求,故而本发明基于图卷积神经网络构建了一个小样本分子性质预测的框架,提高分子性质预测的准确性,以辅助研发人员快速找到合适性质的分子。
发明内容
本发明的目的在于提供一种化学分子性质预测的方法、系统及介质,用以帮助研发人员快速明确候选分子的性质,解决背景技术中所提及的技术问题。
本发明的第一方面提出来一种技术方案是:一种化学分子性质预测的方法,该方法包括以下步骤:
S100.获取终端收集实验数据集并对数据预处理;
S200.提取分子特征信息;
S300.获取化学分子图的图嵌入向量;
S400.搭建图卷积神经网络模型结构,利用实验数据集中的目标数据进行训练;
S500.利用目标图卷积神经网络模型对预测分子进行分子性质预测。
作为本发明的优选技术方案,获取实验数据集的具体步骤包括:
获取终端发送指令至数据集,并读取目标数据至获取终端。
作为本发明的优选技术方案,数据预处理的具体步骤包括:
标识单元对获取终端读取的目标数据进行标识,并输出表达式标识;
转化单元依据所述目标数据的表达式标识输出分子图标识。
作为本发明的优选技术方案,提取分子特征信息的具体步骤包括:
依据分子图标识中的邻居节点及信息采用邻居聚合算法进行连接,并输出节点向量信息;
将节点向量信息进行组合,用以表示分子图。
作为本发明的优选技术方案,获取化学分子图的图嵌入向量的步骤包括:
依据节点向量信息输出图嵌入向量。
作为本发明的优选技术方案,搭建图卷积神经网络模型结构,利用实验数据集中的目标数据进行训练的具体操作包括:
搭建模型框架,依据该模型框架对多个目标数据进行训练任务,通过不同的目标数据训练任务的样本数据多次迭代更新参数,并输出模型参数θ,该参数将被用来对小样本任务进行迁移训练,实现在该性质上的预测;
对模型参数θ进行初始化设置;
更新模型参数θ,对所有目标数据执行训练任务;
该模型框架采用的是损失函数为分子性质预测损失函数,并且采用交叉熵公式进行具体计算。公式如下:
其中,k代表的是数据集中的任务数量,y
作为本发明的优选技术方案,所述训练任务包括训练training和测试testing。
作为本发明的优选技术方案所述训练training的操作步骤包括:
对目标数据进行随机抽样,并输出n个support集,以及m个query测试集;且n与m的和为目标数据的总数。
第二方面,本发明提供一种化学分子性质预测的系统,用于执行如上述第一方面所述的预测方法;该系统包括:
至少一个存在一个中央处理器,以及一个与中央处理器进行通信连接的存储器,
所述存储器,可以存储被中央处理器调用执行的程序指令,以及相关参数模型。
第三方面,本发明提供一种非暂态计算机可读存储介质,用于存储计算机指令,所述计算机指令使所述计算机执行上述第一方面所述的预测方法。
本发明通过改进在此提供一种化学分子性质预测的方法、系统及介质,与现有技术相比,具有如下改进及优点:
本发明通过图卷积神经网络的迁移学习模型框架,通过多个不同的任务来优化模型参数,以弥补单一任务的训练数据量不足问题,同时该模型能在上述的多个任务中都有不俗的表现,从而能够解决小数据量的问题,由此,能更方便地帮助研究人员从大量的候选的分子中筛选出具有相似性质的分子。
附图说明
下面结合附图和实施例对本发明作进一步解释:
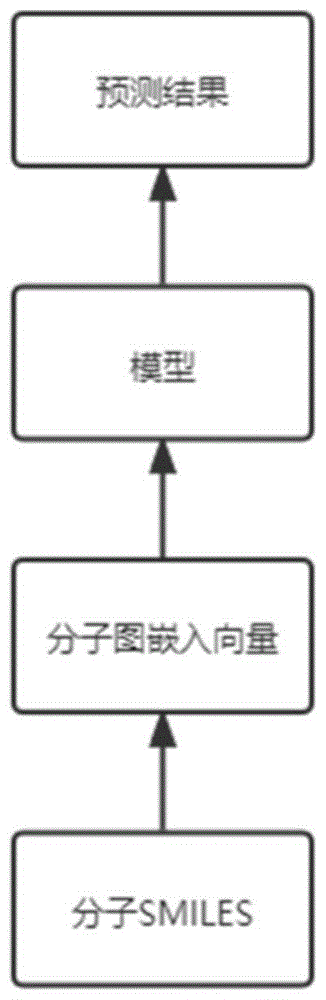
图1为本发明具体实施分子性质预测的流程图;
图2为本发明具体模型参数训练及应用示意图;
具体实施方式
本发明的核心是提供一种化学分子性质预测的方法、系统及介质,以解决背景技术中所提及的问题。
下面将结合附图1至图2对本发明进行详细说明,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,本发明实施例中所使用的“第一”“第二”等描述仅用于描述目的,不应当理解为其指示或隐含指示所限定的技术特征的数量,由此,本说明书各实施例中限定有“第一”“第二”的特征可以表明包括至少一个该被限定的技术特征。
本说明书中所记载的本发明的各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时,应当认为该技术方案的结合不存在。
第一方面,如图1-2所示,本发明为一种化学分子性质预测的方法,该方法包括以下步骤:
S100.获取终端获取实验数据集并对数据预处理;
S200.提取分子特征信息;
S300.获取化学分子图的图嵌入向量;
S400.搭建图卷积神经网络模型结构,利用实验数据集中的目标数据进行训练;
S500.利用目标图卷积神经网络模型对待预测分子进行分子性质预测。
在本发明的一个实施例中,获取化学分子数据构建数据集,该化学分子数据为分子的SMILES表达式;通过Rdkit工具将分子的SMILES表达式转换成分子图,并通过图嵌入的表示方法得到分子图的图嵌入向量,基于该分子图的图嵌入向量构建训练样本;基于图卷积神经图卷积神经网络模型构建预测模型,该预测模型以分子图的图嵌入向量为输入,以分子性质为输出;基于上述训练样本,对构建的预测模型进行预测,优化预测模型中参数θ,得到最终预测模型;对于预测的分子,通过Rdkit工具将分子的SMILES表达式转换成分子图,并通过图嵌入的表示方法得到分子图的图嵌入向量;将上述图嵌入向量输入最终预测模型进行预测,输出分子性质。
本发明通过图卷积神经网络的迁移学习模型框架,通过多个不同的任务来优化模型参数,以弥补单一任务的训练数据量不足问题,同时该模型能在上述的多个任务中都有不俗的表现,从而能够解决小数据量的问题,由此,可以更方便地帮助研究人员从大量的候选的分子中筛选出具有相似性质的分子。
其中,需要说明的是,所述实验数据集的来源主要是数据集tox21与sider,但本发明可用数据集并不限于以上两类。
在本发明的一个实施例中,获取实验数据集的具体步骤包括:
获取终端发送指令至数据集tox21和/或者数据集sider,并读取目标数据至获取终端。
在本发明的一个实施例中,数据预处理的具体步骤包括:
标识单元对获取终端读取的目标数据进行标识,并输出一表达式标识;
转化单元依据所述目标数据的表达式标识输出一分子图标识。
进一步的,标识单元通过SMILES表达式对分子数据进行描述,然后通过Rdkit工具将分子的SMILES表达式转换成分子图,该分子图主要包含了分子的重要节点及化学键特征,例如原子类型、原子手性标签、苯环类型等。需要说明的是,在分子图中,每个节点都代表一个原子,而每一条边都代表一个化学键。
在本发明的一个实施例中,提取分子特征信息的具体步骤包括:
依据分子图标识中的邻居节点及信息采用邻居聚合算法进行连接,并输出节点向量信息;
将节点向量信息进行组合,用以表示分子图。
在本发明的一个实施例中,获取化学分子图的图嵌入向量的步骤包括:
依据节点向量信息输出图嵌入向量。
更进一步,首先,初始化:针对单一的分子图使用节点和边在分子图中的属性来初始化这两个节点和边的表示;
之后采用邻居聚合算法,将当前节点周围的邻居节点及信息进行连接;经过几轮算法迭代,当前节点就可拥有周边的节点的向量信息表示,并将其组合作为分子图的表示;
最后,采用分子图最后一层的节点向量均值作为整个分子图的图嵌入向量,作为模型的输入向量。
在本发明的一个实施例中,搭建图卷积神经网络模型结构,利用实验数据集中的目标数据进行训练的具体操作包括:
搭建模型框架,依据该模型框架对多个目标数据进行训练任务,通过不同的目标数据训练任务的样本数据多次迭代更新参数,并输出模型参数θ,该参数将被用来对小样本任务进行迁移训练,实现在该性质上的预测;
对模型参数θ进行初始化设置;
更新模型参数θ,对所有目标数据执行训练任务。
进一步的,具体参照图2搭建模型框架,该模型框架通过同时训练多个任务,通过不同任务的样本数据多次迭代更新参数,最终会得到一个具有较好性能的模型参数θ。面对数据量较小的任务时,基于该模型参数再次进行训练,新训练的模型也可以拥有较好的模型预测性能。该框架的训练主要分为两部分训练training与测试testing。
需要说明的是,多个任务可以是预测分子的亲水性、预测分子的活性等;数据量较小的任务,包括但不限于一个新的预测任务,预测分子的毒性。
首先,采用随机初始化的方法为图卷积神经网络的参数θ,进行初始化设置。
在训练training部分,其主要目的是更新目标模型的参数θ,对所有的训练任务执行如下操作,参数更新参照图2实施:
首先对该批次的训练样本进行随机抽样,分成n份作support集,每个support集都代表一个预测任务,m份作query测试集。取其中一个训练任务为例进行参数更新描述。
本发明在此举例说明:首先取support集中的任务样本a,任务a拥有少量的训练数据。将上一步中得到的分子图向量表示输入到图卷积神经网络中,由图卷积神经网络进行训练,计算损失L,采用梯度下降算法将图卷积神经网络的模型的参数θ更新为θ′。
然后将任务a中的query测试集中的数据输入到θ′参数化的图卷积神经网络中进行测试,同时计算损失值L′,并将结果反馈到图卷积神经网络中。需要说明的是,其他的任务中同步进行上述操作。
最后,对所有任务的损失值L′进行求和,并利用其对图卷积神经网络模型参数进行更新。
在测试testing部分,对所有的测试任务执行如下操作:
对新一批测试任务进行抽样,用t个作support集,s个作query测试集。取单一任务e为例进行描述。取support集中任务e的分子图向量描述数据输入到图卷积神经网络模型利用training部分优化后的模型参数作为初始化参数θ进行学习训练,计算损失值并将θ更新为θ′,然后取query测试集中任务e的测试数据对更新参数后的模型进行测试,得到模型在该任务e中的性能表现结果。
当表现结果符合研究人员的精度要求,则将该模型应用到实际场景中进行预测,预测过程如图1所示:研究人员将新化合物A的SMILES表达式,然后用Rdkit工具将SMILES表达式转换成一个分子图的向量表示,然后由小样本迁移训练后的模型中进行预测,得到化合物A在目标性质下具体的数值。以此来辅助研究人员的研发工作。
需要说明的是t与s的和为其中一个目标数据的抽样总数,且n与m的和为另一个目标数据的抽样总数。
第二方面,本发明提供一种化学分子性质预测的系统,用于执行如上述第一方面所述的预测方法;该系统包括:
至少一个存在一个中央处理器,以及一个与中央处理器进行通信连接的存储器。
所述存储器,可以存储被中央处理器调用执行的程序指令,以及相关参数模型。
第三方面,本发明提供一种非暂态计算机可读存储介质,用于存储计算机指令,所述计算机指令使所述计算机执行上述第一方面所述的预测方法。
以上所述仅为本发明的较佳实施例,并非因此限制本发明的专利保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。