一种改进vhost-scsi提升虚拟化存储性能的方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及电子数字数据处理,具体涉及一种改进vhost-scsi提升虚拟化存储性能的方法。
背景技术
提升存储的IO性能对于现代数据中心和云计算环境的重要性不言而喻。随着数字化转型和云计算的快速发展,数据已经成为企业的重要资产,而数据的存储和处理能力直接影响到企业的业务运营和性能。
存储的IO性能指的是存储设备在单位时间内进行读写操作的能力,它是衡量存储设备性能的重要指标之一。在数据中心和云计算环境中,存储的IO性能直接影响到以下方面:
应用性能:存储设备的IO性能限制了应用系统的运行速度和响应时间。如果存储设备的IO性能不足,会导致应用系统的响应慢或者崩溃,从而影响企业的业务运营。
数据中心效率:存储设备的IO性能直接影响到数据中心的效率和运营成本。如果存储设备的IO性能不足,需要增加更多的服务器设备来并行处理满足需求,这将增加数据中心的运营成本和复杂性。
云计算服务提供商的竞争力:对于云计算服务提供商来说,提供具有高IO性能的存储设备是吸引客户的重要手段之一。高IO性能的存储设备可以提高云服务的使用体验和可靠性。
因此,提升存储的IO性能对于数据中心和云计算环境至关重要。传统的存储架构已经无法满足现代应用系统的需求,需要采用更先进的存储技术,如NVMe、分布式存储等,以提高存储设备的IO性能和可扩展性。同时,也需要考虑存储设备的能耗和可靠性等因素,以确保存储设备能够满足企业的需求并降低长期运营成本。
vhost-scsi它通过把virtio的后端实现从Qemu应用层挪到了Host的Kernel层,直接在内核层进行数据收发,避开了用户态与内核态的上下文切换以及中间过程的数据复制,目前是虚拟化存储数据快速本地落盘的最佳方案。但是在硬件设备日益强大的同时,在4K以及4K以下数据量IO读写过程中,软件堆栈的消耗仍然占据了很大一部分比例,所以越是面对高性能存储,存储的软件层面优化显得更加重要。
中国发明专利“一种提升申威平台的虚拟化存储性能的方法及系统”(专利号:CN112148224A)。 本发明公开了一种提升申威平台的虚拟化存储性能的方法及系统,包括:在宿主机上形成磁盘阵列;在磁盘阵列上构建新的存储卷;基于新的存储卷构建文件系统;在构建的文件系统上创建虚拟机;宿主机通过虚拟机实现与客户机的读写操作。该发明是利用LVM cache结合RAID0技术,构建文件系统,并使用KVM虚拟化技术创建虚拟机,提升虚拟化存储IO的读写性能。该专利主要是利用LVM cache 和RAID0来实现性能提升,并未在IO路径堆栈上进行优化,在4K以下小块数据随机存储测试情况下,需要从软件堆栈层面去优化。
中国发明专利“一种云平台加速虚拟机I/O的方法、装置及系统”(专利号:CN114020406A)。本发明公开了一种云平台加速虚拟机I/O的方法、装置、系统及计算机可读存储介质,包括预先创建共享大页内存的虚拟机,并获取目标卷的协议及连接信息;向与虚拟机对应的宿主机上的SPDK vhost-user服务发送创建控制器的请求,以创建vhost-user-scsi控制器;根据目标卷的协议及连接信息使SPDKbdve接管目标卷,将SPDK bdve添加至vhost-user-scsi控制器;将虚拟机与vhost-user-scsi控制器相关联,以便虚拟机内的QUME通过调用vhost-user-scsi控制器以对目标卷进行加速操作;本发明有利于提高加速效率和系统性能。该专利主要是通过解决预先创建共享大页内存的虚拟机的限制来给虚拟机I/O加速,并且主要是用在vhost-user-scsi模块和本专利的方法和场景都不一样。
中国发明专利“申威平台存储输入输出设备虚拟化性能优化方法及系统”(专利号:CN111796912A)。本发明公开了申威平台存储输入输出设备虚拟化性能优化方法及系统,包括:客户机的模拟处理器QEMU为客户机和宿主机提供共享内存;客户机的模拟处理器QEMU与宿主机通信,告知宿主机共享内存的地址信息;宿主机接收到共享内存的地址信息后,计算出共享内存的地址信息在宿主机用户进程的地址,然后进行读写操作。该专利主要是利用共享内存来加速,主要内容是vhost-scsi方案中已包含了共享内存的技术适配申威平台,并没有额外对于其他平台有通用的加速方法。
中国发明专利“一种数据安全存储和快速调用的方法及移动终端”(专利号:CN109829324A)。本发明公开了一种数据安全存储和快速调用的方法及移动终端,包括:对系统需要存储在开放的公共路径下的数据进行加密;将加密后的数据存储在所述开放的公共路径下;对所述开放的公共路径下的数据进行解密,并将解密后的数据存放至虚拟内存中,并根据存放地址形成映射后路径;对访问路径默认为所述开放的公共路径的系统调用接口进行修改,将所述系统调用接口的访问路径修改为所述的映射后路径,进而使系统从所述虚拟内存中调取解密后的数据使用。本发明不仅可以解决系统默认路径下的数据的安全存储问题,而且可以提高数据的调用速度,避免出现系统卡顿、无响应等现象,很好地解决了数据存储安全性问题与数据调用快速性问题之间的矛盾。该专利只是针对存储在开放的公共路径下的数据进行加密,对I/O效率提升帮助不大。
中国发明专利“一种NVMe-oF用户态客户端的数据访问方法和装置”(专利号:CN114417373A)。本申请的实施例提供一种NVMe-oF用户态客户端的数据访问方法和装置,方法包括:接收虚拟主机vhost设备发送的数据访问请求消息;解析数据访问请求消息,得到第一服务端标识和访问操作指令;基于第一服务端标识选择第一环形队列,通过第一环形队列,将访问操作指令写入第一NVMe-oF服务端的控制指令区域;其中,第一环形队列为vhost设备与第一NVMe-oF服务端之间的队列。该专利主要是针对NVME-oF设备利用DMA减少IO路径,来达到效率提升的方法。
发明内容
本发明的主要目的是提供一种改进vhost-scsi提升虚拟化存储性能的方法,通过将之前被动的事件通知机制,改为主动轮询查询机制使得在4K级别数据存储的时候存储过程更加高效,减少了服务请求反应事件,同时也减少了服务器的能耗。
为了完成上述目的,本发明提供了一种改进vhost-scsi提升虚拟化存储性能的方法,将IOeventfd事件机制修改为Polling主动事件查询,修改方法包括以下步骤:
S100:在Guest Kernel的地址空间发起创建连续的共享内存的申请,并将共享内存分配给SQ、CQ;
S200:将在Guest Kernel中创建的共享内存通过Qemu模块内存地址转换后传给Host Kernel的vHost模块;
S300:通过在Guest端和Host端分配启动Polling线程,不断轮询查询和设置SQ、CQ的关键标识完成Polling逻辑。
优选的,在步骤S100中还包括以下步骤:
S110:按照连续整页内存分配原则,在Guest Kernel的地址空间中划分共享内存,并将整页内存的划分区域分配给SQ、CQ;
S120:在SQ区域空间中划分空间并分配给sq->head、sq->tail、sq->flag;
S130:在CQ区域空间划分空间并分配给cq->head、cq->tail、cq->flag。
进一步优选的,在步骤S200中还包括以下步骤:
S210:在Qemu中预先配置PCI配置空间,并将Qemu中的PCI配置空间的信息对应写入Guest Kernel中的PCI配置空间中,使得Qemu获得Guest Physical Address;
S220:Qemu将Guest Physical Address转换为Host Virtual Address;
S230:在Qemu中通过Ioctl接口将Host Virtual Address传递给 Host Kernel中的Vhost模块。
更进一步优选的,在步骤S300中,是分别通过设置SQ、CQ 的head、tail、flag来完成Polling逻辑的。
更进一步优选的,修改方法还包括以下步骤:
在步骤S300中,具体的Polling逻辑如下所示:
S310:在 Host Kernel中启动Sqthread 线程,则开启Polling状态;
S320:将Guest OS中的Sq.head的标识设置为n,n为自然数;
S330:在Host OS中的 Sqthread线程中主动查询Sq.head 标识的数值是否大于Sq.tail 的数值,如果Sq.head 标识的数值大于 Sq.tail 的数值,则说明新的数据已经填充;
S340:在Host OS中通过Sq.head的标识,去取得新的发送的数据;
S350:在Host OS中更新Sq.tail 的标识,标识Host OS端已经取得了新发送过来的数据;
S360:在Host OS中处理新发送过来的数据;
S370:在Host OS中处理完新数据后,更新Cq.head = n,表示n号索引值对应的数据已经处理完毕,轮询接着去判断是否有下一个数据发送,继续步逐n;
S380:在Gest OS中会判断Cq.head 是否达到n了,通知上层应用层sq.head==n的请求已经处理完毕;
S390:在Gest OS中在通知完应用层后,将Cq.tail 更新为n,标识n号请求结果也已经处理完n号索引占用的资源能够释放。
更进一步优选的,在步骤S370中,如果在预定的时间内没有接收到新数据,则将轮询设置成休眠状态。
本发明的有益效果为:
Vhost-scsi技术在性能方面的优势主要得益于其优化了数据传输路径、减少了虚拟化开销以及改进了数据传输机制。Vhost-scsi技术的数据传输使用了IOeventfd和irqfd来进行虚拟机和宿主机之间的通知。IOeventfd用于通知HOST数据已准备好,而irqfd则用于通知虚拟机进行中断注入。通过分析vhost-scsi整个流程后,发现事件通知机制在KVM模块中其实路径比较长,存在相对比较多的性能开销,所以将IOeventfd事件机制改为Polling主动事件查询,这种机制减少了请求反应的延迟,从而提高了性能。
采用本发明,在用fio 的4K随机读写虚拟磁盘的对比测试中,采用Polling方案取代事件通知机制大约有6%左右的iops效率提升。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1是改进前Vhost-scsi 读写请求原来IO流程图;
图2是本发明的Vhost-scsi Polling方案改造后的流程图;
图3是本发明的步骤S300的流程图。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
缩略语和关键术语定义:
KVM:全称Kernel-based Virtual Machine,是一个开源的系统虚拟化模块,它的核心是在Linux操作系统上添加了一个虚拟化模块,通过这个模块,操作系统可以直接运行多个虚拟机,即虚拟客户机(VM - Virtual Machine)
Guest OS:在虚拟化中,一台电脑可以同时运行多个操作系统,每个操作系统被称作一个Guest OS,即虚拟机上的操作系统。
Host OS: 在虚拟机中,Host OS与Guest OS相对应,前者指安装在物理机上的操作系统,后者指安装在虚拟中的操作系统。例如,在一台物理电脑上安装的Ubuntu(乌班图)系统,然后在这个系统上我们创建了1个虚拟机里面装了OpenEuler(欧拉)系统,这种情况下 Ubuntu是Host OS。
Qemu:Qemu全称Quick Emulator,是一个功能强大的开源的虚拟机管理器,结合Linux内核中的KVM模块,可实现对硬件虚拟化的支持。目前在Linux平台通常采用Qemu+KVM来提供虚拟化服务。
vhost-scsi:是一种在Host上模拟Scsi设备的虚拟磁盘技术,它作为虚拟磁盘提供给虚拟机使用的一种存储方式。Vhost-scsi最大的特点是高性能,它通过把Virtio的后端实现从Qemu应用层挪到了Host的Kernel层,直接在内核层进行数据收发,避开了用户态与内核态的上下文切换以及中间过程的数据复制,减少了IO流程的堆栈,在4K 随机读写的测试情况下,对Iops的提升由明显帮助。
Vhost-scsi中的事件通知机制:Vhost-scsi的IO流程是在Guest Kernel中发起,它会把需要传输的数据保存在Vring的Describe item中,然后在PCI空间写入Virtqueue索引值,触发KVM模块,通过绑定的Ioeventfd告知后端存储哪个Vring队列中有了新数据需要处理。
Vhost-scsi改Polling机制:就是在Guest Kernel和 Host Kernel中创建公用的共享内存,通过一系列约定的协议通过Polling主动查询共享内存中的flag来发现有新数据需要处理,这样可以减少等待时间,进一步提高IO效率。
SQ(Submit Queue): SQ是用户空间提交IO请求的队列。当用户进程需要通过系统调用向内核提交IO请求时,这些请求被放入SQ中。SQ队列中的请求按照先进先出(FIFO)的顺序排列,以便内核线程进行处理。 在提交IO请求时,用户进程需要提供相关的I/O操作参数,如起始地址、操作类型(读/写)、数据长度等。这些参数会被封装成一个请求结构体,然后通过系统调用提交到SQ中。 当内核线程从SQ中读取请求时,会根据请求的类型和参数执行相应的I/O操作。完成操作后,内核线程会将操作结果写回到共享内存中,并使用CQ(Completion Queue)将完成通知给用户进程。
CQ(Completion Queue): CQ是用于通知用户进程IO操作完成队列。当内核线程完成一个IO操作后,会将完成通知放入CQ中。用户进程可以通过系统调用不断地从CQ中读取完成通知,以便处理已完成的IO操作,SQ和CQ使用了共享内存作为通信介质,使得IO发起端和IO接收处理端可以高效地进行交互。通过主动查询IO请求、减少系统调用次数,Polling可以显著提升磁盘I/O性能。
Vhost-scsi技术在性能方面的优势主要得益于其优化了数据传输路径、减少了虚拟化开销以及改进了数据传输机制。Vhost-scsi技术的数据传输使用了IOeventfd和Irqfd来进行虚拟机和宿主机之间的通知。IOeventfd用于通知Host数据已准备好,而Irqfd则用于通知虚拟机进行中断注入。通过分析Vhost-scsi整个流程后,发现事件通知机制在KVM模块中其实路径比较长,存在相对比较较多的性能开销,所以我们把进一步优化的重点放在把 IOeventfd事件机制改为Polling主动事件查询。这种机制减少了请求反应的延迟,从而提高了性能。
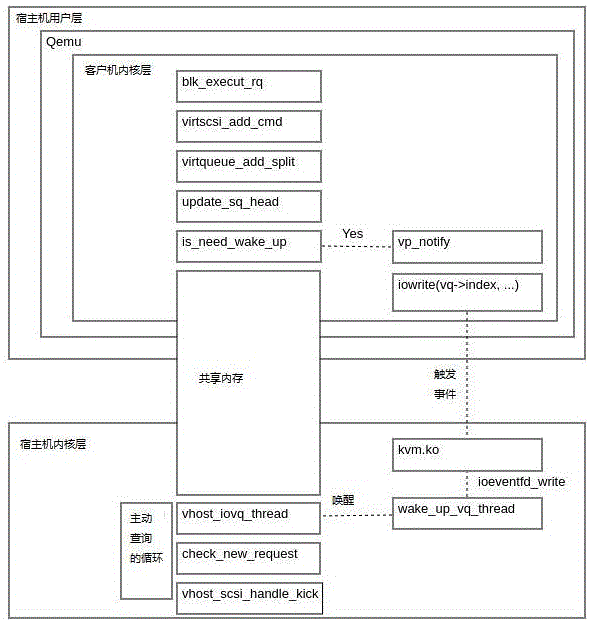
如图1所示,为改进前Vhost-scsi 读写请求原来IO流程。图1中描述了以下流程:
Guest中: 某某上层->通用块设备层->virtscsi层->virtio层。
Host中:vhost(virtio)层->vhost_scsi层->具体物理IO落盘。
由图1中可知,vhost-scsi方案IO流程中从 Guest -> Host 的事件通知机制是通过 kvm 转发事件,会经过比较长软件堆栈。
改进后的Vhost-scsi Polling的流程图请参考图2。由图2中可知,换成主动轮询共享内存标识来替换事件,会有减少事件通知的程序堆栈调用的耗时。
经过图1和图2对比可知,图2中vp_notify->iowrite(vq->index ...) 这条路径这是改造之前的数据通知的路径,本申请依然保留这条路径,将其起到通知vhost-scsi中已休眠轮询线程的焕醒的作用。这条路径改造之前就存在,也是之前Vhost机制本来存在的,它的最终实现也是通过写PCI空间数据,这个PCI空间在Qemu中会把这个空间和Irqfd绑定,Guest中写这个PCI空间值,Host Kernel中就会触发绑定的中断事件,然后再通过Virtio协议,接着处理IO请求。
在图2中,vhost_scsi_handle_kick:是Host端按照vhost-scsi原有逻辑接收Guest (通过kvm模块)IO事件通知的对应处理函数。
virtqueue_add_split:是Guest端virtio在split模式下添加数据的函数。
为实现Vhost-scsi事件通知机制改造成Polling轮询机制需要解决以下问题:
1、如何在地址空间创建连续的共享内存。
如果内存地址只有Guest知道,Host不知道,Guest写的内存的标识, Host 不知道去哪里查,就不能传递IO事件,因此需要打通从Guest Kernel 到 Host Kernel的共享内存。我们知道虚拟内存地址连续,物理内存地址不一定连续,所以我们需要一段Host /Guest看上去都是连续的一段内存。 GPA(guest physic address) -> HVA(host virtualaddress) -> HPA(host physic address)。如果保证虚拟地址空间和物理地址空间的内存都是连续的这是第一个需要解决的问题。为了解决共享内存的问题,可以通过在GuestKernel申请一段整页内存,划定一定区域给SQ、CQ来做记录用。
因此,本实施例中为实现Vhost-scsi事件通知机制改造成Polling轮询机制的第一个步骤为:
S100:在Guest Kernel的地址空间发起创建连续的共享内存的申请,并将共享内存分配给SQ、CQ。
在本步骤中,具体还包括以下步骤:
S110:按照连续整页内存分配原则,在Guest Kernel的地址空间中划分共享内存,并将整页内存的划分区域分配给SQ、CQ。在本步骤中,可以通过分析如果我们在Guest 中按照整页分配,这样在Host视角这段内存也是连续的。在申请的整页内存中划分区域给SQ、CQ。
具体的,先估算一下需要的具体内存大小,然后按照内存整页的大小(我们实际page_size:4096)去分配共享内存。举个例子,工作人员要申请4088字节大小的内存,它比4096小,所以工作人员申请1个整page就够了。如果要申请4097字节大小的内存,它比4096大,一个page装不下,所以工作人员就需要申请2个page的大小也就是(4096x2=)8192字节的共享内存了。
我们发现在Guest中按照整page的size申请的内存,在Qemu中它也会按照整page去向Host的内存管理模块申请。这样Guest中的内存就不会是由Host中散列表内存组成,而是由一块连续的整内存组成。这样才方便我们GuestOS 和 HostOS对同一块共享内存进行操作。
如上所述,只有分配整页对齐的内存,它的GPA才是连续的。这是由于虚拟地址空间看上去是连续的,但是物理地址是散列表形式的,对于Vhost这段拿了就需要各种转换才能正确识别 Guest标识的数据,如果是连续的内存 Vhost kernel端能够方便高效的轮询处理。
S120:在SQ区域空间中划分空间并分配给sq->head、sq->tail、sq->flag。
sq->flag 的作用是标识是否需要唤醒,假设在Host端的Sq poll 轮询发现一段时间上层没有数据下发下来,就会先把sq->flag设置为“FLAG_VRING_SQ_NEED_WAKEUP”(意思是下次发数据前需要先唤醒vhost sqpoll thread),然后再让Sqpoll thread 进入睡眠状态(节省CPU消耗),过段时间Guest发送数据前就会先检测 sq->flag是否有 needwakeup 的标识,如果有的话,它会走之前的kick流程通知到vhost 这段来,先让vhostsqpoll thread 恢复轮询状态,再设置sq->head 标识。S130:在CQ区域空间划分空间并分配给cq->head、cq->tail、cq->flag。
cq->flag是保留项,其用途是在 Guest端也加一个轮询,用来接收完成事件的,如果轮询一段事件发现没有完成事件,Guest中对应的thread进入睡眠前也需要把cq->flag设置为 need wakeup 状态,下次Host Kernel端发送完成事件前也需要先唤醒,再改cq->head值。
2、如何把在Guest Kernel中创建的共享内存把内存地址转换后传给Host Kernel的vHost模块,即,本申请的步骤S200:将在Guest Kernel中创建的共享内存通过Qemu模块内存地址转换后传给Host Kernel的vHost模块。
也就是说,如果只是Guest Kernel知道共享内存地址,Host Kernel不知道那肯定整个流程流转不了。需要两端都能操作同一块内存空间。
在本申请中,是通过以下具体步骤实现的:
S210:在Qemu中预先配置PCI配置空间,并将Qemu中的PCI配置空间的信息对应写入Guest Kernel中的PCI配置空间中,使得Qemu获得Guest Physical Address;
S220:Qemu将Guest Physical Address转换为Host Virtual Address;
S230:在Qemu中通过Ioctl接口将Host Virtual Address传递给 Host Kernel中的Vhost模块。
3、vhost-scsi 在 Host Kernel中的Polling逻辑,也就是本实施例中的步骤S300:通过设置SQ、CQ完成Polling逻辑。
需要设计一套Polling逻辑流程图,尽量在Loop的时候可以少加锁,在大量请求的时候能高效运转。具体的Polling逻辑流程图如图3所示。
其中,在步骤S300中,通过在Guest端的Host端分配启动Polling线程,不断轮询查询和设置SQ、CQ的关键标识完成Polling逻辑。
具体的,修改方法还包括以下步骤:
在步骤S300中,具体的Polling逻辑如下所示:
S310:在 Host Kernel中 调用了 vhost_iovq_thread[start],也就是在 HostKernel中启动Sqthread 线程,则开启Polling状态;
S320:将Guest OS中的Sq.head的标识设置为n,n为自然数,如图3所示,在本实施例中,n=3;
S330:在Host OS中的 Sqthread线程中主动查询(check_new_request)Sq.head标识的数值是否大于 Sq.tail 的数值,如果Sq.head 标识的数值大于 Sq.tail 的数值,则说明新的数据已经填充;
S340:在Host OS中通过Sq.head的标识,去取得新的发送的数据(get_request);
S350:在Host OS中更新Sq.tail 的标识,标识Host OS端已经取得了新发送过来的数据;
S360:在Host OS中处理新发送过来的数据(handle_request);
S370:在Host OS中处理完新数据后,更新Cq.head = 3,表示3号索引值对应的数据已经处理完毕,轮询接着去判断是否有下一个数据发送,继续步逐3;
S380:在Gest OS中会判断Cq.head 是否达到3了,通知上层应用层sq.head==3的请求已经处理完毕;
S390:在Gest OS中在通知完应用层后,将Cq.tail 更新为3,标识3号请求结果也已经处理完3号索引占用的资源能够释放。
4、如果没有数据的时候,在没有请求的时候,能让loop停下来休息(闲时不要占用CPU),等到再次有新请求的时候,polling又可以继续高效运转。
为了应对上述问题,本实施例在步骤S370中增加了一个预定时间,如果在预定时间内没有接收到新数据,则将轮询设置成休眠状态。
显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
- 用于轨道车辆的除雪机构和具有其的轨道车辆
- 一种具有螺旋上下升降转水平输送机构
- 备胎升降机构和具有其的车辆
- 备胎升降机构及具有其的车辆