一种基于神经动力学的图像双时间变尺度优化聚类方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明属于信息处理技术领域,具体为一种基于神经动力学的图像双时间变尺度优化聚类方法。
背景技术
随着信息技术的飞速发展,生物、气象和医学等多个领域迫切需要对大规模、高维数据进行分析和处理。因此,近年来出现了许多处理高维数据的数据降维技术,如线性降维方法,非线性降维方法等。非负矩阵分解(Non-negative Matrix Factorization,NMF)作为一种新的线性降维技术,因其非负约束而备受关注。与传统的矩阵分解技术相比,具有非负约束的NMF具有更好的解释性和明确的物理意义。NMF的独特特性使其在文本分析、高光谱解混、盲源信号分离等领域有着广泛的应用。
NMF已广泛应用于各种聚类问题,如图像聚类,文本聚类,社区检测等。为了提高NMF的聚类性能,人们开发了多种NMF的变体。Cai D,He X,Han J等人在“Graphregularized nonnegative matrix factorization for data representation”一文中提出了图正则化非负矩阵分解(Graph Regularized Non-negative Matrix Factorization,GNMF),它使用邻接图来记录数据的几何关系。将流形约束嵌入到矩阵分解过程中,保持了数据在原始空间中的局部不变性,实现了良好的聚类性能。F.Shang,L.Jiao,F.Wang等人观察到流形上不仅有数据,而且有特征,在“Graph dual regularization non-negativematrix factorization for co-clustering”一文中提出了一种图对偶正则化NMF(DNMF)。H.Liu,Z.Wu,X.Li,D.Cai,T.S.Huang等人在“Constrained nonnegative matrixfactorization for image representation”一文中将先验标签信息作为附加约束引入目标函数,提出约束NMF(CNMF)。X.Li,G.Cui,Y.Dong等人在“Graph regularized non-negative low-rank matrix factorization for image clustering”一文中引入了图正则非负低秩矩阵分解,通过引入低秩恢复方案增强了模型的鲁棒性。
DNMF是一种极具竞争性的NMF变体,但它没有考虑到重构过程中引入的噪声会对模型产生重大影响。许多研究者发现稀疏性有助于提高模型对噪声的鲁棒性。现有方法大多采用其他范数逼近L
NMF的优化问题通常可以看作具有非负约束的非凸优化问题。近年来,基于递归神经网络的神经动力学优化方法已被应用于许多优化问题,如线性规划,二次规划,非线性规划,非光滑优化,拟凸优化,分布优化,约束极小极大优化。具有单一RNN的神经动力优化方法可以解决具有单模态目标函数的相关优化问题。Z.Yan,J.Wang,G.Li等人在“Acollective neurodynamic optimization approach to bound-constrainednonconvex optimization”一文中设计了一种集体神经动态优化(CNO)方法。该方法在求解有界约束全局优化问题时表现出良好的性能。基于F范数的平方损失误差函数的NMF模型是一个双凸目标函数。H.Che,J.Wang,A.Cichocki等人在“Bicriteria sparse nonnegativematrix factorization via two-timescaleduplex neurodynamic optimization”一文中针对双凸优化问题提出了一种双时间尺度双工神经动力系统(TDNO)来解决稀疏NMF(SNMF)问题。与CNO相比,TDNO系统具有较低的空间复杂度。然而,TDNO系统中设定的尺度因子仍然是一个固定常数,没有考虑到系统的动态特性。此外,为了寻求更快的收敛速度,TDNO系统中的比例因子往往需要设置得尽可能大。然而,这通常是不可行的。因此,设计一种空间复杂度低、计算时间短的神经动力学优化方法是该领域亟待解决的挑战之一。
发明内容
基于上述技术背景,本发明提供了一种基于神经动力学的图像双时间变尺度优化聚类方法。具体为先提出了一种新的算法模型,称为稀疏图对偶正则化非负矩阵分解,然后开发了一个新的双时间变尺度双神经动力学优化(TTDNO)系统来解决双凸优化问题。
本发明是通过以下技术方案实现的。
本发明所述的一种基于神经动力学的图像双时间变尺度优化方法,按以下步骤:
步骤1:构建稀疏图对偶正则化非负矩阵分解(Sparse Graph Dual-RegularizedNonnegative Matrix Factorization,SDNMF)模型如下:
其中,‖·‖
L
当k=1时,
步骤2:对式(2)的B,Y矩阵执行向量化操作,得到新的目标函数如下:
其中b,y为对B,Y矩阵执行向量化操作如下:
b=vec(B)=(b
y=vec(Y)=(y
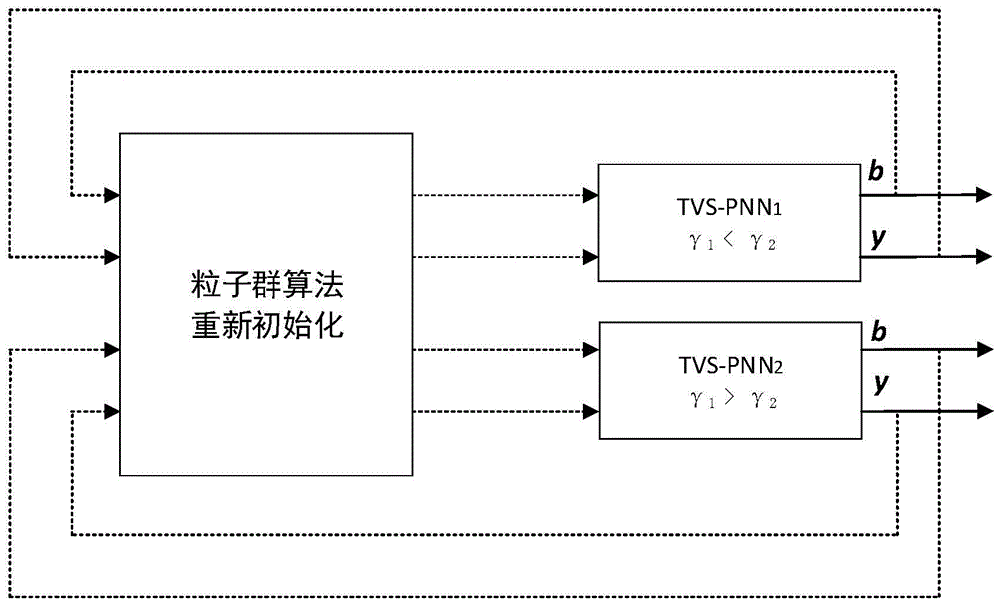
步骤3:提出了一种新的双时间变尺度双神经动力学优化(TTDNO)系统;
步骤3.1:约束优化问题一般可表述为:
min H(ζ)
s.t.ζ∈Ξ
其中ζ=(ζ
首先,提出了一种求解上述问题KKT点的时变尺度投影神经网络(TVS-PNN):
其中,γ是一个称为尺度因子的常数,
步骤3.2:提出的神经动力学模型如下:
其中Ξ
(1)幂指数形式:
ζ(γ,t)=t
(2)指数形式:
ζ(γ,t)=γe
与现有的TDNO系统相比,TTDNO系统增加了时变尺度的功能,有助于进一步增强算法的开发能力。
步骤4:TTDNO系统的算法流程如下:
4.1:输入一个原始的高维数据矩阵Z,并将其元素的值归一化,使其值范围为[0,1];
4.2:设置误差容限φ=[φ
4.3:随机初始化神经元的初始状态b
4.4:设置个人最优解为:
4.5:设置全局最优解为:S
4.6:进行迭代更新:
4.6.1:粒子依据TVS-PNN动力学方程进行局部搜索,获得个人最优解
4.6.3:更新种群全局最优位置:
4.6.4:引入粒子群优化算法(Particle Swarm Optimization,PSO),PSO通过一组粒子执行搜索操作,并随机创建粒子的初始位置。每个粒子表示一个潜在解,其位置信息由位置向量ζ表示。该算法假设粒子群在预设的空间范围内移动到全局最优,每个粒子的移动速度用一个速度向量v来描述。为了便于后续讨论,定义ζ
ζ
其中,ω∈[0,1]是一个固定参数;a
4.6.5:为了进一步提高搜索效率,使用小波突变改善种群的早熟收敛问题,进而提高种群多样性。具体规则如下:
首先,定义一个关于粒子多样性的评价函数:
其中,M代表总体中的粒子数。
4.6.6:将所得到的η与设定的阈值η
其中,J
其中,ψ∈[-2.5c,2.5c],c=exp(10(i/i
4.7:如果i≤i
4.8:将4.7中得到的b、y,重新转化为矩阵形式,得到最优矩阵B、Y。
步骤5:进行聚类,计算准确率AC(Accuracy,AC)和归一化互信息量NMI(Normalized Mutual Information,NMI)来衡量聚类性能,包括以下步骤:
5.1:准确率AC计算
准确率是一个常用的聚类评价指标,代表预测成功的样本数与总体样本数的比值。定义为:
其中,s
5.2:归一化互信息量(NMI)计算
互信息量用来衡量预测结果与真实结果之间的相似程度。需要指出的是,NMI是基于互信息函数和熵函数来对聚类结果进行评价的。它的定义为:
其中c表示聚类个数,n
本发明的有益效果在于:本发明所提的SDNMF模型在聚类分析中拥有较好的性能。SDNMF在DNMF的基础上对解矩阵施加L
附图说明
图1为TTDNO求解框架图。
图2为基于SDNMF的聚类框架图。
图3为TTDNO算法求解流程图。
具体实施方式
为了发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施,对本发明进行进一步的详细说明。此处所描述的具体实施例仅用于本发明技术方案,并不限于本发明。
本发明提供一种技术方案:一种基于神经动力学的图像双时间变尺度优化聚类方法。其流程如图3所示,包括以下步骤:
步骤1:构建稀疏图对偶正则化非负矩阵分解(Sparse Graph Dual-RegularizedNonnegative Matrix Factorization,SDNMF)模型如下:
步骤2:对式(2)的B,Y矩阵执行向量化操作,得到新的目标函数如下:
步骤3:提出了一种新的双时间变尺度双神经动力学优化(TTDNO)系统;
步骤3.1:约束优化问题一般可表述为:
min H(ζ)
s.t.ζ∈Ξ
其中ζ=(ζ
首先,提出了一种求解上述问题KKT点的时变尺度投影神经网络(TVS-PNN):
其中,γ是一个称为尺度因子的常数,
步骤3.2:提出的神经动力学模型如下:
其中Ξ
其中,λ和μ为正则化参数,α和β为平衡稀疏性和分解误差的非负参数,L
ζ(γ
(1)幂指数形式:
ζ(γ,t)=t
(2)指数形式:
ζ(γ,t)=γe
与现有的TDNO系统相比,TTDNO系统增加了时变尺度的功能,有助于进一步增强算法的开发能力。
步骤4:TTDNO系统的算法流程如下:
4.1:输入一个原始的高维数据矩阵Z,并将其元素的值归一化,使其值范围为[0,1];
4.2:设置误差容限φ=[φ
4.3:随机初始化神经元的初始状态b
4.4:设置个人最优解为:
4.5:设置全局最优解为:S
4.6:进行迭代更新:
4.6.1:粒子依据TVS-PNN动力学方程进行局部搜索,获得个人最优解
4.6.3:更新种群全局最优位置:
4.6.4:引入粒子群优化算法(Particle Swarm Optimization,PSO),PSO通过一组粒子执行搜索操作,并随机创建粒子的初始位置。标准PSO更新规则如下:
ζ
其中,ω∈[0,1]是一个固定参数;a
4.6.5:为了进一步提高搜索效率,使用小波突变改善种群的早熟收敛问题,进而提高种群多样性。具体规则如下:
首先,定义一个关于粒子多样性的评价函数:
其中,M代表总体中的粒子数。
4.6.6:将所得到的η与设定的阈值η
其中,J
其中,ψ∈[-2.5c,2.5c],c=exp(10(i/i
4.7:如果i≤i
4.8:将4.7中得到的b、y,重新转化为矩阵形式,得到最优矩阵B、Y。
步骤5:进行聚类,计算准确率AC(Accuracy,AC)和归一化互信息量NMI(Normalized Mutual Information,NMI)来衡量聚类性能,包括以下步骤:
5.1:准确率AC计算
准确率是一个常用的聚类评价指标,代表预测成功的样本数与总体样本数的比值。定义为:
其中,s
5.2:归一化互信息量(NMI)计算
互信息量用来衡量预测结果与真实结果之间的相似程度。需要指出的是,NMI是基于互信息函数和熵函数来对聚类结果进行评价的。它的定义为:
其中c表示聚类个数,n
本发明的效果可以通过以下实验做进一步的说明。
1.仿真条件
本发明所有实验均是在搭载主频为3.40GHz的i7-6700CPU的PC端进行的,仿真软件为MATLAB2019a。
2.实验内容
为了验证本发明所提出的方法在聚类应用中的有效性,本发明在ORL数据集、Yale数据集、PIE数据集、COIL20数据集上进行了聚类实验。
(1)ORL数据集包含40个人的400张面部图像,每个人有10张不同表情和姿势的面部图像。
(2)Yale数据集包含15个人的165张面部图像,每个人在不同的表情、灯光和姿势下拥有15张真实的面部图像。
(3)PIE数据集包含不同姿势、光线和表情的多人面部图像。在这里,本发明选择了其中68人的2856张照片。
(4)COIL20数据集包含20个对象的1440个图像,每个对象总共有72个图像。
需要注意的是,为了方便实验,本发明将所有图像的大小调整为32×32。表1列出了这四个数据集的详细情况。
表1四个数据集的信息
为了验证SDNMF模型及其优化算法TTDNO系统的优越性,本发明将其与目前最流行的聚类算法进行比较。实验中比较的算法如下:
1、NMF:非负矩阵分解算法。它将数据矩阵分解为两个非负的低维子矩阵,从得到原始数据的低维表示。
2、GNMF:它基于原始的NMF对系数矩阵Y施加图约束。图正则化参数和最近邻数分别设为100和5。
3、DNMF:它还在GNMF的基础上对基矩阵B施加了图约束。图正则化参数和最近邻数分别设为100和5。
4、GSNMF:在DNMF的基础上,对基矩阵B和系数矩阵Y施加L
5、SDNMF
6、SDNMF
7、SDNMF
其中NMF在“Learning the parts of objects by non-negative matrixfactorization”中有详细介绍,Cai D,He X,Han J等人在“Graph regularizednonnegative matrix factorization for data representation”一文中提出了GNMF,F.Shang,L.Jiao,F.Wang等人在“Graph dual regularization non-negative matrixfactorization for co-clustering”一文中提出了DNMF,P.Deng,T.Li,H.Wang等人在“Graph regularized sparse non-negative matrix factorization for clustering”一文中介绍了GSNMF。
在SDNMF模型中需要设置的参数有λ、μ、α、β、ν和最近邻数τ。根据经验,本发明设τ=5和v=0.01,logλ=logμ=2,logα=logβ=1。
在本实验中,每个模型随机选取K个聚类进行10次聚类实验,记录均值和标准差(均值±标准差)。
表2在ORL数据集上的聚类性能
表3在YALE数据集上的聚类性能
表4在PIE数据集上的聚类性能
表5在COIL20数据集上的聚类性能
表2-5分别显示了ORL、Yale、PIE和COIL20数据集上的聚类结果。以表2为例,本发明将在下面详细分析实验结果。
1)与NMF相比,DNMF和GNMF具有明显的优势,说明流形信息的加入显著提高了模型的聚类性能。GSNMF在DNMF的基础上对分解后的矩阵施加L
2)与GSNMF相比,SDNMF
3)与SDNMF
4)SDNMF
同样,通过分析表3-5也可以得到同样的结论。