一种基于空间变量推理的信贷场景风险用户评估方法
文献发布时间:2023-06-19 09:57:26
技术领域
本发明涉及新兴信息技术领域,特别涉及一种基于空间变量推理的信贷场景风险用户评估方法。
背景技术
在现阶段普惠金融的发展背景下,人们在享受快捷方便的金融服务的同时,相应的金融风险呈现零碎化、精细化、高科技化的发展趋势,尤其是信贷领域中所涉及到的欺诈风险与信用风险。目前,各大机构于研究者基于特定的研究方向,对风险评估方案的实时展开研究,一般而言,研究方向可以概括为:基于AI建模自动化评估的研究、基于风险表征数据挖掘的研究以及基于全流程风险控制体系的研究。事实上,对于现在的信贷风控策略而言,往往对用户的地理位置归属有着一定风险偏好,但是,上述的各研究方向中往往会忽视了相应的地理位置信息,没有试图从空间分布的角度上来进行空间推理,对用户风险进行空间位置维度上的解析。
基于空间变量推理的信贷场景风险用户评分方法是通过空间自相关分析、地统计插值法构造描述相关地理位置的特征,再通过评分卡建模方法,对所推断出的特征进行筛选、融合等综合评估,得出最后的风险评分。
发明内容
本发明要解决的技术问题是克服现有技术的缺陷,通过引入地理位置信息以及相应的空间变量推理方法,结合评分卡建模方法,从更多的维度对用户进行风险评估,对现有的用户风险评估方法的研究工作起到一个指向式、扩充式、启发式的作用。
为了解决上述技术问题,本发明提供了如下的技术方案:
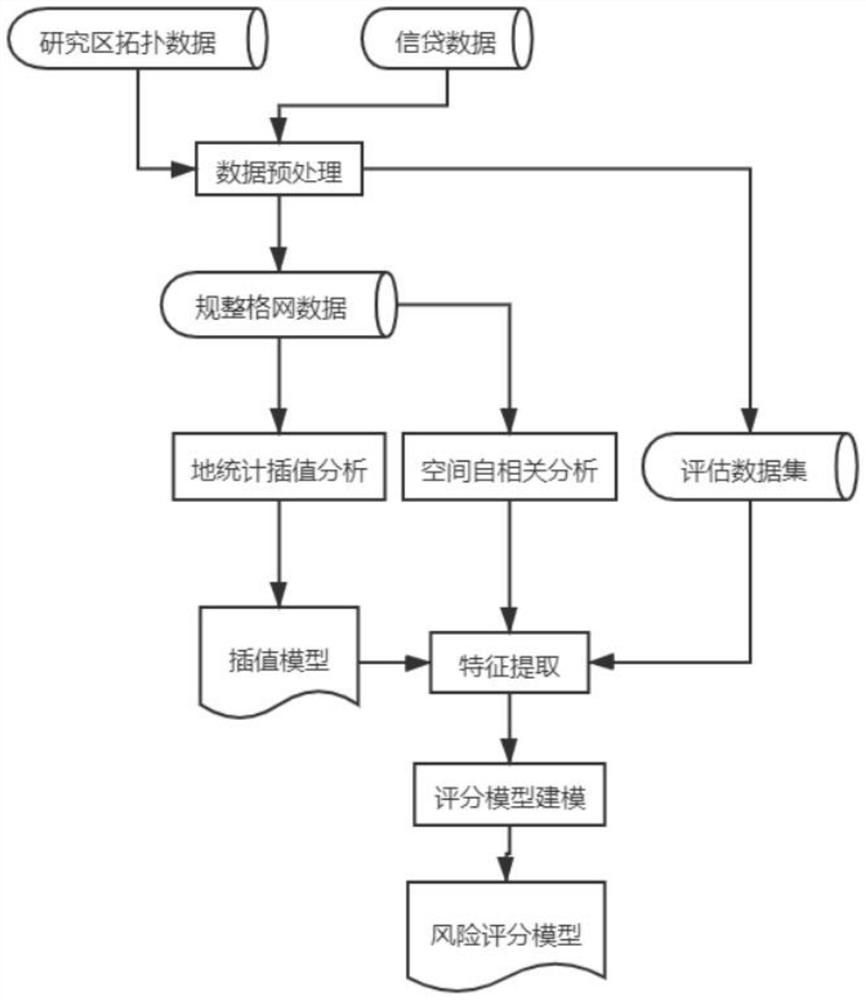
本发明一种基于空间变量推理的信贷场景风险用户评估方法,包括以下步骤:
S1.数据获取:获取待研究区域的形状拓扑数据、信贷数据,所述的形状拓扑数据包含待研究区域的形状边界信息;所述信贷数据包含用户唯一标识、用户好坏标签以及进行授信、借款等操作的时间信息与经纬度信息;
S2.数据预处理:将步骤S1所获取的信贷数据,按照比例分离出训练数据集和评估数据集;同时基于步骤S1所获取的形状拓扑数据,生成指定大小的规整格网,按照训练数据集中的经纬信息与拓扑数据的空间关系,统计格网内的特征指标,生成格网数据;
S3.空间自相关分析,根据步骤S2所处理好的格网数据,分别使用单变量空间自相关方法、双变量空间自相关方法进行分析,得出相应的空间自相关模型及其自相关指数与聚类结果;
S4.地统计插值分析,根据步骤S2所处理好的格网数据,使用地统计插值法进行分析,得出相应的插值模型以及相应的推断出的空间插值分布结果;
S5.特征提取,根据步骤S3所处理好的自相关指数与聚类结果,对于步骤S2中的评估数据集进行处理,提取出不同分析对象下各个样本的自相关指数以及聚类类型,以及根据步骤S4的地统计插值模型,对于步骤S2中的评估数据集进行处理,提取出不同分析对象下各个样本的插值预测结果,形成特征评估数据集;
S6.模型评分,根据步骤S5所处理的特征评估数据集,基于特定的IV值筛选特征,同时采用评分卡建模方法,生成用户风险评分,以描述用户风险程度。
作为本发明的一种优选技术方案,所述的步骤S2中,对于信贷数据,按照比例分离出训练数据集和测试数据集的具体做法是:按照附带的时间信息,进行排序并按照特定的时间单位(月、天、小时等)进行编号,根据所设置的比例,取;根据研究区的拓扑形状,生成制定大小的规则格网的具体做法是:根据待研究区的拓扑形状,根据经度的极大值与极小值,以及纬度的极大值与极小值,两两组合成四个点,然后基于这四个的中的某个点开始,按照预设大小规格进行格网划分,从而得到规整格网数据;按照信贷数据中的经纬信息与拓扑数据的空间关系,统计格网内的特征指标,生成格网数据的具体做法是:对于信贷数据中的经纬度信息,视作为点拓扑,而对于各个格网拓扑,分别统计落入格网内的点个数、用户标签为好用户的点个数以及用户标签为坏用户的点个数,同时计算用户标签为好用户的占比值以及用户标签为坏用户的占比值,此外,还需按照是否超过特定阈值,将占比值处理为0和1(1表示占比值超过特定阈值)。
作为本发明的一种优选技术方案,所述的步骤S3中,对于单/双变量空间自相关的分析方法,具体的做法为:对于处理好的格网数据,分别以点个数、用户标签为好用户的占比、用户标签为坏用户的占比作为分析对象,应用单变量空间自相关分析方法;以用户标签为好用户的个数以及用户标签为坏用户的个数作为分析对象,应用双变量空间自相关分析方法,关于单/双变量空间自相关方法的具体的分析公式如下:
公式(1)中,x,y为变量,若是单变量分析,则x与y所指代的变量为同一个变量主体,若是双变量分析,则x与y所指代的变量分别来自两个不同的变量主体;
作为本发明的一种优选技术方案,所述步骤S4的具体步骤如下:
4.1)分别以用户标签为坏用户的占比及其是否超过特定阈值,作为分析对象,先计算各个格网拓扑的中心点的经纬度坐标,对于不同的样本点,按照特定空间概念模型,与近邻点构造成不同的点对,同时计算各个点对之间的距离以及点对应的属性值之间的差值的绝对值;
4.2)通过最小二乘法,基于特定函数模型拟合两个不同位置的点之间的距离与其属性值差值之间的关系,得出相应的函数模型f(x),所述的函数模型不局限于线性函数、二次函数等;
4.3)针对于任意已知经纬度的点,可以按照如下公式对点的属性值进行估算;
公式(2)中的z
公式(3)中,f是4.2中所拟合出来的函数模型,φ是拉格朗日乘子,d
作为本发明的一种优选技术方案,所述步骤S5中,根据所处理好的自相关指数与聚类结果,对评估数据集进行处理,提取出不同分析对象下各个样本的自相关指数以及聚类类型的具体做法为:基于附加了不同分析对象的自相关指数以及聚类类型的属性格网数据,按照评估数据集中的经纬度信息是否落于格网拓扑内的空间关系判断,将格网拓扑的自相关指数预计聚类类型的属性拼接到评估数据集,作为评估数据集中的特征属性;根据地统计插值模型,对于评估数据集进行处理,提取出不同分析对象下各个样本的插值预测结果的具体做法为:基于评估数据集的经纬度信息,使用不同分析对象下的地统计插值模型对其进行预测,得出相应的预测值,拼接到评估数据集,作为评估数据集中的特征属性。
作为本发明的一种优选技术方案,所述的步骤S6中,基于特定的IV值筛选特征的具体做法是:对于特征评估数据中所有的自相关指数、聚类结果、插值预测值,以及用户好坏标签,进行IV值的测算,按照特定的IV阈值进行筛选,只保留超过阈值的特征;采用评分卡建模方法,生成用户风险评分的具体做法为:对于基于特定IV阈值所筛选出来的特征,应用机器学习模型对特征与好坏标签进行整合,应用特定公式,将机器学习模型所预测出的似然概率转换为评分,作为最后的风险评分,具体评分公式如下:
p
与现有技术相比,本发明的有益效果如下:
本发明的有益效果是通过充分利用已有的、经过用户授权所采集到的GPS经纬度数据,通过引入空间变量推理的结果,可以在地理位置的维度上对用户风险倾向进行描述,丰富用户风险评估的维度。扩展了原有的分析方法和思路,对后续各个领域的用户画像、用户风险评估具有重要的理论、实践意义和推广应用价值。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明的技术路线图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例1
本发明提供一种基于空间变量推理的信贷场景风险用户评估方法,包括以下步骤:
S1.数据获取:获取待研究区域的形状拓扑数据、信贷数据,所述的形状拓扑数据包含待研究区域的形状边界信息;所述信贷数据包含用户唯一标识、用户好坏标签以及进行授信、借款等操作的时间信息与经纬度信息;
S2.数据预处理:将步骤S1所获取的信贷数据,按照比例分离出训练数据集和评估数据集;同时基于步骤S1所获取的形状拓扑数据,生成指定大小的规整格网,按照训练数据集中的经纬信息与拓扑数据的空间关系,统计格网内的特征指标,生成格网数据;
S3.空间自相关分析,根据步骤S2所处理好的格网数据,分别使用单变量空间自相关方法、双变量空间自相关方法进行分析,得出相应的空间自相关模型及其自相关指数与聚类结果;
S4.地统计插值分析,根据步骤S2所处理好的格网数据,使用地统计插值法进行分析,得出相应的插值模型以及相应的推断出的空间插值分布结果;
S5.特征提取,根据步骤S3所处理好的自相关指数与聚类结果,对于步骤S2中的评估数据集进行处理,提取出不同分析对象下各个样本的自相关指数以及聚类类型,以及根据步骤S4的地统计插值模型,对于步骤S2中的评估数据集进行处理,提取出不同分析对象下各个样本的插值预测结果,形成特征评估数据集;
S6.模型评分,根据步骤S5所处理的特征评估数据集,基于特定的IV值筛选特征,同时采用评分卡建模方法,生成用户风险评分,以描述用户风险程度。
步骤S2中,对于信贷数据,按照比例分离出训练数据集和测试数据集的具体做法是:按照附带的时间信息,进行排序并按照特定的时间单位(月、天、小时等)进行编号,根据所设置的比例,取;根据研究区的拓扑形状,生成制定大小的规则格网的具体做法是:根据待研究区的拓扑形状,根据经度的极大值与极小值,以及纬度的极大值与极小值,两两组合成四个点,然后基于这四个的中的某个点开始,按照预设大小规格进行格网划分,从而得到规整格网数据;按照信贷数据中的经纬信息与拓扑数据的空间关系,统计格网内的特征指标,生成格网数据的具体做法是:对于信贷数据中的经纬度信息,视作为点拓扑,而对于各个格网拓扑,分别统计落入格网内的点个数、用户标签为好用户的点个数以及用户标签为坏用户的点个数,同时计算用户标签为好用户的占比值以及用户标签为坏用户的占比值,此外,还需按照是否超过特定阈值,将占比值处理为0和1(1表示占比值超过特定阈值)。
步骤S3中,对于单/双变量空间自相关的分析方法,具体的做法为:对于处理好的格网数据,分别以点个数、用户标签为好用户的占比、用户标签为坏用户的占比作为分析对象,应用单变量空间自相关分析方法;以用户标签为好用户的个数以及用户标签为坏用户的个数作为分析对象,应用双变量空间自相关分析方法,关于单/双变量空间自相关方法的具体的分析公式如下:
公式(1)中,x,y为变量,若是单变量分析,则x与y所指代的变量为同一个变量主体,若是双变量分析,则x与y所指代的变量分别来自两个不同的变量主体;
步骤S4的具体步骤如下:
4.1)分别以用户标签为坏用户的占比及其是否超过特定阈值,作为分析对象,先计算各个格网拓扑的中心点的经纬度坐标,对于不同的样本点,按照特定空间概念模型,与近邻点构造成不同的点对,同时计算各个点对之间的距离以及点对应的属性值之间的差值的绝对值;
4.2)通过最小二乘法,基于特定函数模型拟合两个不同位置的点之间的距离与其属性值差值之间的关系,得出相应的函数模型f(x),所述的函数模型不局限于线性函数、二次函数等;
4.3)针对于任意已知经纬度的点,可以按照如下公式对点的属性值进行估算;
公式(2)中的z
公式(3)中,f是4.2中所拟合出来的函数模型,φ是拉格朗日乘子,d
步骤S5中,根据所处理好的自相关指数与聚类结果,对评估数据集进行处理,提取出不同分析对象下各个样本的自相关指数以及聚类类型的具体做法为:基于附加了不同分析对象的自相关指数以及聚类类型的属性格网数据,按照评估数据集中的经纬度信息是否落于格网拓扑内的空间关系判断,将格网拓扑的自相关指数预计聚类类型的属性拼接到评估数据集,作为评估数据集中的特征属性;根据地统计插值模型,对于评估数据集进行处理,提取出不同分析对象下各个样本的插值预测结果的具体做法为:基于评估数据集的经纬度信息,使用不同分析对象下的地统计插值模型对其进行预测,得出相应的预测值,拼接到评估数据集,作为评估数据集中的特征属性。
步骤S6中,基于特定的IV值筛选特征的具体做法是:对于特征评估数据中所有的自相关指数、聚类结果、插值预测值,以及用户好坏标签,进行IV值的测算,按照特定的IV阈值进行筛选,只保留超过阈值的特征;采用评分卡建模方法,生成用户风险评分的具体做法为:对于基于特定IV阈值所筛选出来的特征,应用机器学习模型对特征与好坏标签进行整合,应用特定公式,将机器学习模型所预测出的似然概率转换为评分,作为最后的风险评分,具体评分公式如下:
p
本实施例选取中国大陆地区作为研究区进行展示,具体的主要步骤如前所述,不再重复赘述,仅展示针对该实施例的具体实现细节和实现效果。
步骤S1数据获取:获取待研究区域的形状拓扑数据、信贷数据,所述的形状拓扑数据包含待研究区域的形状边界信息,参考坐标系为WGS84;所述信贷数据包含用户唯一标识、用户好坏标签以及时间信息与经纬度信息,根据用户是否通过授信作为用户的好坏标签,同时采用用户的授信申请时的时间作为时间信息、授权采集的GPS信息作为经纬度信息,其中经纬度也属于WGS84坐标系;
步骤S2数据预处理:将步骤S1所获取的信贷数据,按照申请时间的日期从0开始,进行整数编号并进行排序,按照8:2比例分离信贷数据集,取前80%的数据作为训练数据集,后20%的数据作为评估数据集;同时基于步骤S1所获取的形状拓扑数据,生成10KM*10KM的规整格网,按照训练数据集中的经纬信息与拓扑数据的空间关系,统计格网内的点个数、授信通过/拒绝用户个数、授信通过/拒绝率等特征指标,生成格网数据;
步骤S3空间自相关分析,根据步骤S2所处理好的格网数据,选取点个数、通过率、通过率是否超过30%三个特征值作为分析对象,分别使用单/双变量空间自相关方法,在这里选取通过率与通过率是否超过30%的双变量空间自相关分析作为示例:选取Queen’sCase作为空间概念模型,描述空间近邻关系以确认相应的空间权重值,同时计算各个格网下的自相关指数,并根据z-score标准化后的属性值是否大于0,以及自相关指数的显著性检验结果,得出相应的聚类结果,将自相关指数与聚类类型的结果拼接到格网的属性数据中,其余分析对象的单/双变量空间自相关分析亦可参考上述示例;
步骤S4地统计插值分析,根据步骤2)所处理好的格网数据,选取通过率、通过率是否超过30%三个特征值作为分析对象,这里以通过率是否超过30%作为示例:设置空间概念模型为K近邻,其中3≤K≤18;此外,基于指数函数去拟合距离与变量差值之间的关系,指数函数的具体公式参考如下:
通过最小二乘法,可以得知公式(5)中的r的近似解,根据所拟合的函数模型f(x),结合公式(3)即可得到的插值模型;
步骤S5特征提取,根据步骤S3所处理好的自相关指数与聚类结果,对于步骤S2中的评估数据集进行处理,提取出所有分析对象下各个样本的自相关指数以及聚类类型,以及根据步骤S4的地统计插值模型,对于步骤S2中的评估数据集进行处理,提取出所有分析对象下各个样本的插值预测结果,形成特征评估数据集;
步骤S6模型评分,根据步骤S5所处理的特征评估数据集,按照IV≥0.02,同时选取lightgbm模型进行建模,设置所有的聚类类型为离散型变量,按照用户是否首逾30天构造用户好坏标签,训练模型;通过设置base=400,PD0=10来将lightgbm模型所预测出的样本概率按照公式(4)进行分数转换,以描述用户风险程度;
基于所得出的风险评分,可以进行相应的评估,本实施例基于反欺诈场景的建模,根据用户是否首逾30天,对风险评分分别进行IV值评估以及建模KS评估,结果IV=0.08,且建模KS值能在原来的基础上提升0.03。
相对于现有的方法,本发明主要基于地理位置信息,引入空间自相关分析、地统计插值分析法,在地理空间的维度上进行推理,从而丰富用户在地理空间维度上的信息,便于评估其风险倾向。
与现有技术相比,本发明的有益效果如下:
本发明的有益效果是通过充分利用已有的、经过用户授权所采集到的GPS经纬度数据,通过引入空间变量推理的结果,可以在地理位置的维度上对用户风险倾向进行描述,丰富用户风险评估的维度。扩展了原有的分析方法和思路,对后续各个领域的用户画像、用户风险评估具有重要的理论、实践意义和推广应用价值。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于空间变量推理的信贷场景风险用户评估方法
- 一种基于随机森林算法的消费信贷场景的风险评估方法