基于级联并行卷积神经网络的多手姿态关键点估计方法
文献发布时间:2023-06-19 11:05:16
技术领域
本发明属于计算机视觉技术领域,涉及一种估计方法,特别涉及一种基于级联并行卷积神经网络的多手姿态关键点估计方法。
背景技术
手势是人类交流的一种自然形式。手在日常生活中扮演的重要角色同时也是我们与世界互动的方式:使用工具,演奏乐器,触摸,做手势。手势的重要性使手势自动识别技术占据了计算机视觉研究的一个重要领域,在人机接口中有着广泛的应用。消费者市场的需求推动了智能手势识别技术的发展,一些虚拟现实(Virtual Reality,VR)、增强现实(Augmented Reality,AR)产品更多的投入市场。
其中手部姿态关键点估计是手势识别的重要内容,是人机交互、虚拟现实、增强现实等实际应用中的关键步骤。因此,基于视觉的手部姿态关键点估计的理论以及技术的研究更具有实际应用价值。现有的手部姿态关键点估计通常是在裁剪后的图像区域进行的,该区域包含固定尺度的单手,对于不同尺度下手部区域的检测还没有得到充分的研究。而通常一幅图像中有多个手部,由于视线距离或手部的物理尺寸而导致其尺度不同,单手检测只能将其分割成多个单手输入再进行整合,这样将消耗大量资源,效率低下,因此研究算法应该能够准确、稳健、同时定位手部区域,从而实现多手手部姿态关键点估计。
综上所述,实现手部姿态关键点估计已成为当前计算机视觉领域的热点问题,且具有重要的意义和研究价值。但由于姿势和外观的歧义,强烈的清晰度,和严重的自遮挡以及彩色图像中灵活的手指运动和外观模糊,相似的手色和背景色等问题使得实现这一目标仍然具有挑战性。
发明内容
为了解决现有手部姿态关键点估计卷积神经网络模型识别多手不准确,耗时及计算量大导致的网络模型应用受限的技术问题,本发明的目的在于,提供一种基于级联并行卷积神经网络的多手姿态关键点估计方法,能够提升识别速度和准确率。
为了实现上述任务,本发明采用如下的技术解决方案:
一种基于级联并行卷积神经网络的多手姿态关键点估计方法,其特征在于,包括以下步骤:
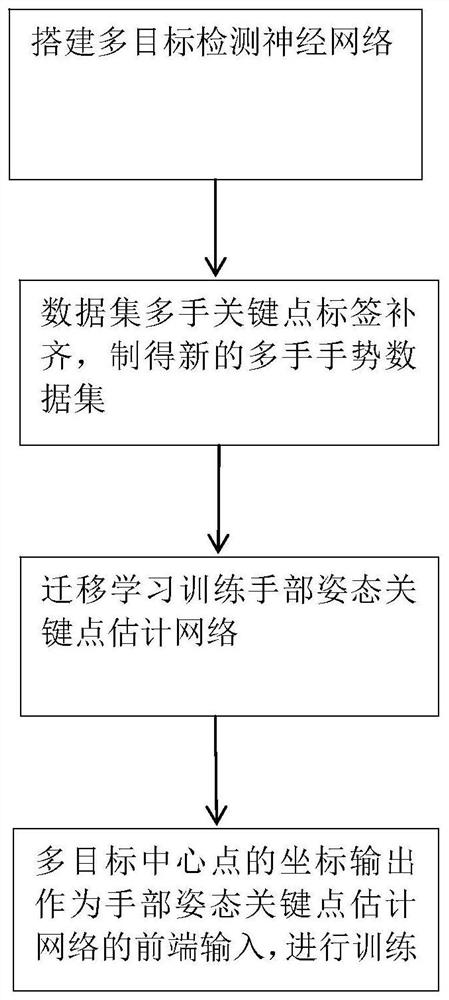
步骤一,获取公开数据集手势图片和标签文件,对于所述手势图片进行多手关键点标签补齐,制得多手手势数据集;
步骤二,基于公开数据集和所述多手手势数据集,搭建多手目标检测网络,用于通过训练实现对图像中多手目标检测;针对同样的手势图像数据集及手势的关键点标签搭建手部姿态关键点估计网络,用于通过训练实现对图像中手部姿态关键点估计;
步骤三,将多手目标检测网络检测多目标中心点的坐标输出,作为手部姿态关键点估计网络的前端作为输入的一部分;
步骤四,利用手部姿态关键点估计网络进行训练,得到模型,从而实现对图像中多手姿态关键点估计。
根据本发明,步骤一所述的多手手势数据集制作方法为:图像数据集包含原始样本图像及对原始样本图像进行手工补齐标注后的标签图像,其中,补齐后的标注信息记录的图像手部关键点标签与原始图像一一对应;采用对原始图像做镜面对称处理的方式重新标记对应图像,以达到强化静态数据集的目的。
进一步地,步骤二中所述的多手目标检测网络为YOLO网络;手部姿态关键点估计网络为Hrnet人脸检测网络迁移学习为手部姿态关键点估计网络。
具体地,步骤二中所述的手部姿态关键点估计网络对所述手部图像进行归一化处理,经过基础提取特征的前期卷积网络后,采用四个连续的多尺度多分辨率的级联并行卷积神经网络进行关节点预测,通过高分辨率的第一层子网,后面网络并行连接高低分辨率子网并且不同分辨率的图像采样到相同尺度反复的融合,即每一层并行子网的分辨率都由前一层高分辨率和依次下降的分辨率组成;得到位置预测结果,所述位置预测结果包括所述手部姿态关键点的位置。
进一步优选地,步骤三中所述多手目标检测网络输出一张图片的多个手掌中心点坐标(x
本发明的基于级联并行卷积神经网络的多手姿态关键点估计方法,与现有技术相比,具有以下优点:
1、使用大型的公开数据集对手部姿态关键点估计网络预训练,得到神经网络模型的基础权重,使用补齐标签的多手手势数据集对神经网络模型的基础权重进行微调,得到泛化能力更好的手部姿态关键点估计网络模型,该方法有效地解决了手势图片数据匮乏导致的卷积神经网络模型过拟合问题,大幅提高了训练所得手部姿态关键点估计网络模型的准确率和鲁棒性。同时快速训练适用于更多手势类型的新网络模型。
2、由于将两个单一功能的卷积神经网络结合,利用多目标检测网络得到手掌中心坐标作为手部姿态关键点估计网络的部分输入,有效解决了单一手部姿态关键点估计网络模型找手不准确的的问题,从而实现多手手部姿态关键点检测。
3、由于直接输入是多手图片,输出的也是识别后的多手手部关键点图片,所以该框架有端到端的优点,以上特性,不仅提高了多手手部关键点估计的速度,更大大的提高了识别准确率。
附图说明
图1是本发明的基于级联并行卷积神经网络的多手姿态关键点估计方法流程图。
图2是本发明的基于级联并行卷积神经网络的多手姿态关键点估计方法框架图。
图3是手部姿态关键点估计网络的框架图。
图4是是手部姿态关键点估计网络的高分辨率模块框架图。
图5是手部姿态关键点估计网络的关键点预测模块框架图。
图6是采用本发明的方法结果示意图。
下面结合附图和具体实施例进一步阐述本发明。
具体实施方式
首先需要说明的是,以下的实施例是较优的例子,应理解,本发明不限于这些实施例。本领域普通技术人员可以对本发明的技术方案作各种添加、替换或改动,这些等价形式同样属于本发明的保护范围。
实施例:
如图1和图2所示,本实施例给出一种基于级联并行卷积神经网络的多手姿态关键点估计方法,包括:获取公开数据集手势图片和标签文件,基于公开数据集和多手手势数据集,搭建多手手部姿态关键点检测的级联并行卷积神经网络,用于通过训练实现对图像中多手目标检测,多目标中心点的坐标输出;基于所述手势图片数据集,对所述手势图片进行多手关键点标签补齐,制得新的多手手势数据集。
所述多手手势数据集的制作方法为:图像数据集包含原始样本图像及对原始样本图像进行手工补齐标注后的标签图像,其中,补齐后的标注信息记录的图像手部关键点标签与原始图像一一对应;采用对原始图像做镜面对称处理的方式重新标记对应图像,以达到强化静态数据集的目的。
所述的多手手部姿态关键点检测的级联并行卷积神经网络是指:多手目标检测网络和手部姿态关键点估计网络;其中,多手目标检测网络为YOLO网络,是基于公开数据集和所述多手手势数据集搭建的,用于通过训练实现对图像中多手目标检测;手部姿态关键点估计网络为Hrnet人脸检测网络迁移学习为手部姿态关键点估计网络,是针对同样的手势图像数据集及手势的关键点标签所搭建的,用于通过训练实现对图像中手部姿态关键点估计。
训练多手目标检测网络;多手目标检测网络多目标中心点的坐标输出作为手部姿态关键点估计网络的前端作为输入的一部分;改进后的手部姿态关键点估计网络进行训练,得到模型,从而实现对图像中多手姿态关键点估计。
具体步骤包括:
步骤1:获取公开数据集手势图片和标签文件,对所述手势图片进行多手关键点标签补齐,制得多手手势数据集。本实施例所述的公开数据集是手语数据集NZSL与MPII中的部分多手手势数据集,含原始样本图像及对原始样本图像进行手工标注后的标签图像,标注信息记录的图像标记关键点以及标记框与原始图像一一对应但大部分图片多手标签基本有缺漏;采用对原始图像做镜面对称处理的方式,并重新标记对应图像,达到强化静态手语数据集的目的。用LabelImg程序进行人工补齐标签得到真实目标标签文件。
其中,所述的多手手势数据集制作方法为:图像数据集包含原始样本图像及对原始样本图像进行手工补齐标注后的标签图像,其中,补齐后的标注信息记录的图像手部关键点标签与原始图像一一对应;采用对原始图像做镜面对称处理的方式重新标记对应图像,以达到强化静态数据集的目的。
步骤2:基于公开数据集和所述多手手势数据集,搭建多手目标检测网络,用于通过训练实现对图像中多手目标检测;针对同样的手势图像数据集及手势的关键点标签搭建手部姿态关键点估计网络,用于通过训练实现对图像中手部姿态关键点估计;
本实施例中,所述的多手目标检测网络为YOLO网络;手部姿态关键点估计网络为Hrnet人脸检测网络迁移学习为手部姿态关键点估计网络。
手部姿态关键点估计网络对所述手部图像进行归一化处理,经过基础提取特征的前期卷积网络后,采用四个连续的多尺度多分辨率的级联并行卷积神经网络进行关节点预测,通过高分辨率的第一层子网,后面网络并行连接高低分辨率子网并且不同分辨率的图像采样到相同尺度反复的融合,即每一层并行子网的分辨率都由前一层高分辨率和依次下降的分辨率组成;得到位置预测结果,所述位置预测结果包括所述手部姿态关键点的位置。
利用YOLO网络进行多手目标检测,并输出多手手掌中心点坐标。该网络原理为:先在ImageNet上进行了预训练,其预训练的分类模型采用前20个卷积层,然后添加一个平均池化层和全连接层。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224x224增加到了448x448。测试过程得到每个预测中心点的分类置信度分数后,设置阈值,滤掉得分低的预测点,对保留的预测点进行NMS处理,就得到最终的检测结果。
步骤3:将多手目标检测网络检测多目标中心点的坐标输出,作为手部姿态关键点估计网络的前端作为输入的一部分;
所述多手目标检测网络输出一张图片的多个手掌中心点坐标(x
步骤4:利用手部姿态关键点估计网络进行训练,得到模型,从而实现对图像中多手姿态关键点估计。
本实施例中,训练手部姿态关键点估计网络:该手部姿态关键点估计网络原理为,对数据集手部图像进行归一化处理,手部姿态关键点估计网络采用Hrnet人脸检测网络迁移学习为手部姿态关键点估计网络,该网络以Resnet做为基础框架,2D手势图像在经过YOLO网络后,通过两类模块,即高分辨率模块和关键点预测模块。高分辨率的第一层子网,后面网络并行连接高低分辨率子网并且不同分辨率的图像采样到相同尺度反复的融合,即每一层并行子网的分辨率都由前一层高分辨率和依次下降的分辨率组成。图3列出的4个LAYER层即为并行子网。得到位置预测结果,所述位置预测结果包括所述手部姿态关键点的位置。
高分辨率模块:该模块为关键点的特征融合部分,通过网络中的融合模块生成分辨率依次下降的分支(当仅包含一个分支时,不需要融合)在生成分支时首先判断各个分支维数和通道是否一致,不一致使用1×1卷积进行升维或者降维。为了保持特征的多样化,在1×1卷积后只接入BN层而不使用ReLu激活。
在融合过程中,要判断特征层是否需要上采样或下采样。如图4所示,j
关键点预测模块:目的是生成融合的特征,即上面提到的融合部分的输入特征,以图5第一次特征融合为例,输入w×h×3的图像经过第一层网络处理后,在transition层得到的特征融合部分的输入特征,将原有的一个分支变为两个,分辨率下降。
将多目标中心点的坐标输出作为手部姿态关键点估计网络的前端作为输入的一部分,解决手部姿态关键点全局检测找手不准确的问题,改进后的局部检测手部姿态关键点网络结构进行训练,并输出多手关键点坐标,得到模型,从而实现对图像中多手姿态关键点估计。图6是测试数据集输出效果示意图。
- 基于级联并行卷积神经网络的多手姿态关键点估计方法
- 一种基于级联卷积神经网络的多姿态眼睛定位方法