一种基于典型动作网络的时序动作定位方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明涉及计算机视觉算法研究技术领域,具体涉及一种基于典型动作网络的时序动作定位方法。
背景技术
在万物互联的信息时代,视频作为记录客观世界并传递信息的有效媒介,在生产生活中得到广泛的应用,这也使得视频解译的需求越来越强烈;
为了有效地感知动作的结构,视频动作解译领域的研究者们已经进行深入的探索并取得一系列的成果;Mengmeng Xu等人在2020年的工作G-tad:Sub-graph localizationfor temporal action detection中建模视频片段的时序邻域和语义邻域关系,RunhaoZeng等人在2021年的工作Graph convolutional module for temporal actionlocalization in videos中以图中拓扑结构表示邻近动作提议之间的关系;近期,自注意力机制展现出优良的动作结构建模能力,其中,Ashish Vaswani等人在2017年的工作Attention is all you need中通过密集连接使得视频帧只经过一个序列化操作便能与任意邻近帧进行交互,而邻近帧充分的交互能为视频帧提供丰富的时序上下文信息;然而,图卷积机制和自注意力机制希望为每类动作学习一种唯一确定的表征,但通常忽略类内多样性,忽略一个动作通常含有多个阶段,而每个阶段的视频帧也展现出不同的外观和运动特性;此外,已有方法通常局限于单个视频,甚至视频中一个滑动窗,进行动作结构建模,尚未充分探索跨视频类别级的关系;
为了表征同类动作的多样性并进行跨视频的动作类别级关系建模,研究者已经探索出一些有意义的方法,例如,Wang Luo等人在2021年的工作Action unit memorynetwork for weakly supervised temporal action localization中提出的学习记忆池(Memory Bank),为动作学习类别原型(Prototype),Le Yang等人在2022年的工作Colar:Effective and efficient online action detection by consulting exemplars中从每类动作中选择有代表性的子动作并将其视为典型动作片段;这些建模在特定任务上也得到了相应的性能提升;而上述方法表征力和判别力较差,不能有效地服务于涉及动作结构的视频解译任务;
基于此,亟需设计一种基于典型动作网络的时序动作定位方法,以提高视频解译任务过程中的表征力和判别力,从而解决上述现有技术存在的问题。
发明内容
针对上述存在的问题,本发明旨在提供一种基于典型动作网络的时序动作定位方法,本方法通过考虑一个动作类别,首先,本方法收集此类所有动作实例的每个特征并进行聚类,选取有代表性的特征作为典型动作片段;然后,本方法将典型动作片段划分为三个阶段并按照时间顺序嵌入到一个有向图中,从类别层面全局地构建典型动作网络;接下来,本方法在典型动作网络中设计四种信息交互步骤:阶段内部交互、相邻阶段传递、典型信息聚合和视频帧广播,这四种步骤按顺序处理时序信息,调整典型动作网络中每个典型动作片段的特征,为所处理的每帧视频提供恰当的时序信息引导;最终,典型动作网络模块与已有的时序动作定位方法相结合,取得性能增益的过程,能够有效提高模块的表征力和判别力,具有表征力和判别力好、定位准确的特点。
为了实现上述目的,本发明所采用的技术方案如下:
一种基于典型动作网络的时序动作定位方法,包括
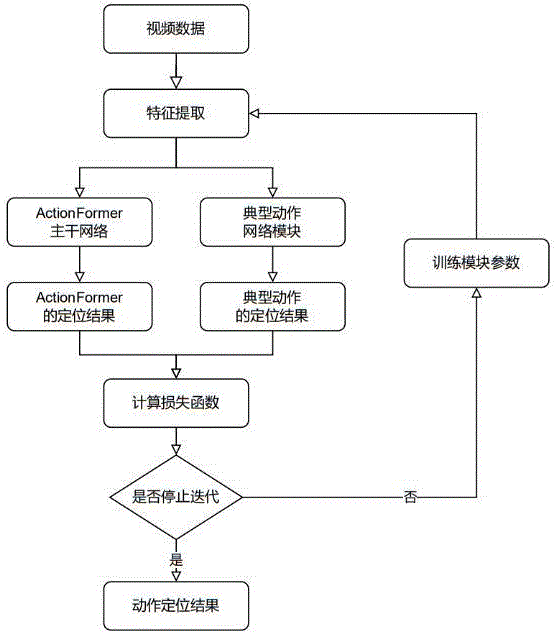
步骤1:从给定视频中抽取视频特征;
步骤2:根据视频特征,利用聚类算法生成典型动作;
步骤3:根据典型动作之间的信息传递关系,构建基于结构信息传递的典型动作网络模块;
步骤4:将典型动作网络模块与时序动作定位方法ActionFormer结合;
步骤5:对典型动作网络模块与时序动作定位方法ActionFormer结合后的结果进行基于相似性比较的分类估计;
步骤6:设置损失函数,对分类结果进行训练和测试。
优选的,步骤1所述的从给定视频中抽取视频特征的过程为
给定视频,利用I3D模型,从给定视频中抽取一系列视频特征,得到给定视频的高层语义表征:
F=[f
其中,
步骤2.1:考虑一类动作,收集所有动作实例的特征表示,使用K-Means算法将特征聚类,得到M个聚类簇;对于每簇特征表示,将最靠近聚类中心的特征当作典型特征,得到M个典型特征;
步骤2.2:在得到M个典型特征后,将每个动作实例均匀地划分为三个阶段:动作开端、动作演变和动作结尾。
优选的,步骤3所述的构建典型动作网络模块的过程包括
步骤3.1:连接属于同一阶段的多个典型动作,并在每两个典型动作之间进行双向的信息交互;
步骤3.2:从“动作开端”到“动作演变”和从“动作演变”到“动作结尾”两种信息传递;将开端阶段的每个典型特征与演变阶段的所有典型特征连接,将演变阶段的每个典型特征与结尾阶段的所有典型特征连接,最终,在不同阶段典型特征之间建立一个有向图;
步骤3.3:将典型信息聚合到视频帧,为动作解译任务提供时序信息支持;同时将视频帧特征与所有典型特征逐个比较,并使用注意力机制自适应地从各个动作阶段聚合特征;
步骤3.4:使用视频帧广播操作将当前视频帧的特性传递给典型动作网络模块;每个典型动作综合考虑其自身特征和正在处理的视频帧特征,按照注意力机制更新自身特征。
优选的,在步骤3所述的典型动作网络模块中,典型动作以图变换网络的形式运行,具体过程为:
1.首先,初始化图变换网络的节点特征和边特征
(1)使用一个线性变换层将典型动作特征
(2)在初始化阶段,拼接x
(3)典型动作网络模块每层使用图变换网络,对于第l层的图变换网络,其第i个节点的特征为
(4)为计算节点v
其中,
2.按照下式计算相似性
根据如下公式更新节点v
3.使用图变换网络中的标准操作来处理节点特征,依次使用残差连接,逐层正则化和前馈网络;
4.综合考虑节点自身的位置编码、邻近节点的位置编码和连接邻近节点边的特征,更新每个节点的位置编码p
其中,Γ(·)表示与节点特征所类似的信息传播过程中,计算时只考虑节点的位置编码,而不考虑节点的特征信息。
优选的,步骤4所述的将典型动作网络模块与时序动作定位方法ActionFormer结合的过程包括
步骤4.1:将典型动作网络模块引入ActionFormer,在ActionFormer方法的网络结构中构建一个额外分支;
步骤4.2:使用最大池化操作将特征进行下采样,得到和ActionFormer相同数量的代表性特征;
步骤4.3:使用增强的视频特征,参考ActionFormer以一阶段无锚点的形式求解时序动作定位任务。
优选的,步骤5所述的基于相似性比较的分类估计过程包括
步骤5.1:在典型动作网络模块中,最后一层图变换网络的节点特征表示为
其中,
步骤5.2:对于动作类别分类任务,从所有类别的典型动作网络模块中搜集视频帧特征,得到特征表示
其中,
优选的,步骤6所述的训练和测试过程包括
步骤6.1:在训练阶段,设损失函数按照如下式:
L=L
其中,L
表示Focal loss,用于动作类别的分类;/>
给定典型动作分支的预测结果,参考ActionFormer算法计算典型分支相应的损失项L
步骤6.2:在测试阶段,使用超参β融合ActionFormer算法的预测结果s
s=β·s
本发明的有益效果是:本发明公开了一种基于典型动作网络的时序动作定位方法,与现有技术相比,本发明的改进之处在于:
本发明提出了一种基于典型动作网络的时序动作定位方法,本方法能有效地服务于涉及动作结构的视频解译任务;作为一个有表征力的模块,首先,每一个被选择的典型动作片段对应于一系列具有清晰外观特征和运动模式的视频帧,这种典型动作片段所对应的清晰特征能够代表许多与之相似的特征;其次,典型动作网络将一类动作划分为三个阶段:动作开端、动作演变和动作结尾,能够显式地表征同类动作的结构;更进一步的,典型动作网络的每个阶段均包含多个典型动作片段,能够恰当地反映同一阶段动作所具有的外观和运动多样性;作为一个有判别力的模块,首先,相比于大部分训练视频的特征,典型动作网络参与所有视频帧的训练,在与所有样本的交互中被充分地训练,成为具有判别力的模块;此外,给定视频特征,传统方法通常学习具有额外参数的分类器来预测分类得分,而典型动作网络通过比较视频特征与各个典型动作的相似性来预测分类得分,这种不引入额外参数的做法能进一步增强典型动作网络的特征判别力;
作为一个兼具表征力和有判别力的模块,本方法所提出的典型动作网络能与ActionFormer方法高效结合,有效地建模动作结构和跨视频依赖关系,服务于时序动作定位任务;相比于已有的时序动作定位方法,本发明的方法能在有限的计算开销下,取得更高的定位准确度;具有表征力和判别力好、定位准确的优点。
附图说明
图1是本发明基于典型动作网络的时序动作定位方法的流程图。
图2是本发明实施例2部分训练数据的可视化图。
图3是本发明实施例2基于典型动作网络的时序动作定位方法的实验结果图。
具体实施方式
为了使本领域的普通技术人员能更好的理解本发明的技术方案,下面结合附图和实施例对本发明的技术方案做进一步的描述。
实施例1:如图1-图3所示的一种基于典型动作网络的时序动作定位方法,本发明的基本思想是:考虑一个动作类别,首先,本方法收集此类所有动作实例的每个特征并进行聚类,选取有代表性的特征作为典型动作片段;然后,本方法将典型动作片段划分为三个阶段并按照时间顺序嵌入到一个有向图中,从类别层面全局地构建典型动作网络;接下来,本方法在典型动作网络中设计四种信息交互步骤:阶段内部交互、相邻阶段传递、典型信息聚合和视频帧广播,这四种步骤按顺序处理时序信息,调整典型动作网络中每个典型动作片段的特征,为所处理的每帧视频提供恰当的时序信息引导;最终,典型动作网络模块与已有的时序动作定位方法相结合,取得性能增益;其具体过程包括
步骤1:抽取视频特征
给定视频,利用I3D模型,从给定视频中抽取一系列视频特征,得到给定视频的高层语义表征:
F=[f
其中,
步骤2:根据视频特征,利用聚类算法生成典型动作
步骤2.1:考虑一类动作,首先收集所有动作实例的特征表示,然后使用K-Means算法将特征聚类,得到M个聚类簇;对于每簇特征表示,将最靠近聚类中心的特征当作典型特征,得到M个典型特征;
其中,所述K-Means算法由MacQueen J在1967年的工作Classification andanalysis ofmultivariate observations中提出;
步骤2.2:在得到M个典型特征后,将每个动作实例均匀地划分为三个阶段:动作开端、动作演变和动作结尾;根据典型特征在其对应的动作实例中所处的位置,确定典型特征所属的阶段;对于不同动作类别,三个阶段通常含有不同数量的典型动作;
步骤3:构建基于结构信息传递的典型动作网络模块
给定三个阶段所对应的典型动作,利用阶段内部交互、相邻阶段传递、典型信息聚合及视频帧广播四种信息传递机制,构建有向图G
步骤3.1:首先,连接属于同一阶段的多个典型动作,并在每两个典型动作之间进行双向的信息交互;考虑一个特定的动作阶段,多个典型动作能反映此阶段的动作在外观特性和运动模式上的多样性;因此,阶段内部交互便于典型动作捕获相同时序片段中的多样性;
步骤3.2:第二步包含从“动作开端”到“动作演变”和从“动作演变”到“动作结尾”两种信息传递;
将开端阶段的每个典型特征与演变阶段的所有典型特征连接,将演变阶段的每个典型特征与结尾阶段的所有典型特征连接,最终,在不同阶段典型特征之间建立一个有向图;相邻阶段传递能够帮助每个典型特征显式地感知其前驱典型和后继典型,从而显式地表征动作的结构信息;
步骤3.3:经过阶段内部和阶段之间充分的信息交互,典型动作网络能为所处理的视频帧准确地传递结构信息;此时,将典型信息聚合到视频帧,为动作解译任务提供时序信息支持;视频帧特征与所有典型特征逐个比较,并使用注意力机制自适应地从各个动作阶段聚合特征;经过典型信息聚合,视频帧特征能够充分地感知当前动作的结构信息;
步骤3.4:使用视频帧广播操作将当前视频帧的特性传递给典型动作网络模块;每个典型动作综合考虑其自身特征和正在处理的视频帧特征,按照注意力机制更新自身特征;视频帧广播操作能使得典型动作根据视频帧的特性做出适应性的调整,从而在下一层信息传播过程中产生更具有表征力的典型特征;
步骤4:将典型动作网络模块与时序动作定位方法ActionFormer(时序动作定位方法ActionFormer由Chen-Lin Zhang等人在2022年的工作Zhang C L,Wu J,LiY.Actionformer:Localizing moments of actions with transformers[C]//EuropeanConference on Computer Vision.Springer,Cham,2022:492-510.中提出)结合,具体做法是:
步骤4.1:首先将典型动作网络模块引入ActionFormer,即在ActionFormer方法的网络结构中构建一个额外分支,插即用地服务于已有方法,在和典型动作的交互过程中,ActionFormer方法能为每帧提供完整的典型动作信息,帮助进行动作建模;
步骤4.2:然后,使用最大池化操作将特征进行下采样,得到和ActionFormer相同数量的代表性特征;
步骤4.3:接下来,使用增强的视频特征,参考ActionFormer以一阶段无锚点的形式求解时序动作定位任务;
步骤5:基于相似性比较的分类估计
步骤5.1:在典型动作网络模块中,最后一层图变换网络的节点特征可以表示为
其中,
步骤5.2:对于动作类别分类任务,本方法从所有类别的典型动作网络模块中搜集视频帧特征,得到特征表示
对于动作边界回归任务,本方法利用3层1D卷积神经网络,预测当前时刻到所属动作边界的距离
其中,卷积核的大小设置为3,前2层网络使用层归一化,3层网络均使用ReLU激活函数;
步骤6:训练和测试:
步骤6.1:在训练阶段,设损失函数按照如下形式计算:
L=L
其中,L
表示Tsung-Yi Lin等人在2017年的工作Focal loss for dense objectdetection中提出的Focal loss,用于动作类别的分类;/>
给定典型动作分支的预测结果,可以参考ActionFormer算法计算典型分支相应的损失项L
步骤6.2:在测试阶段,使用超参β融合ActionFormer算法的预测结果s
s=β·s
优选的,所述的典型动作网络模块基于Deep Graph Libray 0.8.2(所述DeepGraph Libray 0.8.2由Minjie Wang等人在2019年的工作Wang M,Zheng D,Ye Z,etal.Deep graph library:A graph-centric,highly-performant package for graphneural networks[J].arXiv preprint arXiv:1909.01315,2019.中提出)实现,在典型动作网络模块中,典型动作以图变换网络(Graph Transformer)的形式运行,具体做法为:
1.首先,初始化图变换网络的节点特征和边特征
(1)使用一个线性变换层将典型动作特征
(2)在初始化阶段,拼接x
其中,所述随机游走策略由Pan Li等人在2020年的工作LiP,WangY,Wang H,etal.Distance encoding:Design provably more powerful neural networks for graphrepresentation learning[J].Advances in Neural Information Processing Systems,2020,33:4465-4478.中提出;
(3)典型动作网络模块每层使用图变换网络,对于第l层的图变换网络,其第i个节点的特征为
(4)为计算节点v
其中,
2.然后,按照如下形式计算相似性
根据如下公式更新节点v
3.最终,使用图变换网络中的标准操作来处理节点特征,依次使用残差连接,逐层正则化(Layer Normalization)和前馈网络(Feed Forward Network);为简化表述过程,上述操作只考虑单头自注意力机制,但这些操作能便捷地拓展到多头自注意力机制,从而使典型动作网络模块具有更强的表征能力;
4.与此同时,本实施例综合考虑节点自身的位置编码、邻近节点的位置编码和连接邻近节点边的特征,更新每个节点的位置编码p
其中,Γ(·)表示与节点特征所类似的信息传播过程中,只不过计算时只考虑节点的位置编码,而不考虑节点的特征信息。
实施例2:为验证如本实施例1所述的基于典型动作网络的时序动作定位方法的有效性,设计本实施例对上述方法进行验证,其具体过程包括
步骤1:构建数据集
本实施例使用THUMOS14和ActivityNet-v1.3两个数据集进行实验;THUMOS14数据集来源于:http://crcv.ucf.edu/THUMOS14/,ActivityNet-v1.3数据集来源于:http://activity-net.org/;THUMOS14训练数据集共包含20种动作类别,ActivityNet-v1.3训练数据集共包含200种动作类别,每条训练视频包含多个动作实例;如图2所示,利用本实施例所述方法对所有视频单独处理;
步骤2:抽取视频特征
给定视频,利用I3D模型,从给定视频中抽取一系列视频特征,得到给定视频的高层语义表征:
F=[f
其中,
I3D模型在Kinetics-400数据集上完成预训练,Kinetics-400数据集来源于:https://deepmind.com/research/open-source/kinetics;
步骤3:构建典型动作网络模块
本实施例使用Deep Graph Libray 0.8.2实现典型动作网络模块,在典型动作网络模块中,典型动作以图变换网络(Graph Transformer)的形式运行,具体做法是:
步骤3.1:首先,初始化图变换网络的节点特征和边特征,使用一个线性变换层将典型动作特征
步骤3.2:在初始化阶段,拼接x
步骤3.3:典型动作网络模块每层使用图变换网络,对于第l层的图变换网络,其第i个节点的特征为
为计算节点v
其中,
步骤3.4:然后,按照如下形式计算相似性
根据如下公式更新节点v
步骤3.5:最终,使用图变换网络中的标准操作来处理节点特征,依次使用残差连接,逐层正则化(Layer Normalization)和前馈网络(Feed Forward Network);为了简化表述过程,上述操作只考虑单头自注意力机制,但这些操作能便捷地拓展到多头自注意力机制,从而使典型动作网络模块具有更强的表征能力;
与此同时,本实施例综合考虑节点自身的位置编码、邻近节点的位置编码和连接邻近节点边的特征,更新每个节点的位置编码p
其中,Γ(·)表示与节点特征所类似的信息传播过程中,只不过计算时只考虑节点的位置编码,而不考虑节点的特征信息;
步骤4:结合典型动作网络模块和ActionFormer
步骤4.1:首先将典型动作网络模块引入时序动作定位方法ActionFormer,在和典型动作的交互中本方法能为每帧提供完整的典型动作信息,帮助进行动作建模;
步骤4.2:然后,使用最大池化操作将特征进行下采样,得到和ActionFormer相同数量的代表性特征;
步骤4.2:接下来,使用增强的视频特征,参考ActionFormer以一阶段无锚点的形式求解时序动作定位任务,具体来讲:
(1)对于动作类别分类任务,本方法从所有类别的典型动作网络模块中搜集视频帧特征,可以得到特征表示
(2)对于动作边界回归任务,本方法利用3层1D卷积神经网络,预测当前时刻到所属动作边界的距离
其中,卷积核的大小设置为3,前2层网络使用层归一化,3层网络均使用ReLU激活函数;
本方法所提典型动作网络模块无需修改已有的ActionFormer方法的网络结构,而是构建一个额外分支,即插即用地服务于已有方法,并能显著地提升其在时序动作定位任务上的性能,可得到的时序动作定位结果如图3所示;
步骤5:训练和测试
在训练阶段,损失函数按照如下形式计算
L=L
其中,L
表示Tsung-Yi Lin等人在2017年的工作Lin TY,Goyal P,Girshick R,etal.Focal loss for dense object detection[C]//Proceedings of the IEEEinternational conference on computer vision.2017:2980-2988.中提出的Focalloss,用于动作类别的分类;/>
给定典型动作分支的预测结果,可以参考ActionFormer算法计算典型分支相应的损失项L
在测试阶段,使用超参β融合ActionFormer算法的预测结果s
s=β·s
本方法使用Navaneeth Bodla等人在2017年的工作Bodla N,Singh B,ChellappaR,et al.Soft-NMS--improving object detection with one line of code[C]//Proceedings of the IEEE international conference on computer vision.2017:5561-5569.中提出的Soft-NMS方法,对时序动作定位结果进行后处理,移除高度重叠的动作实例,产生时序动作定位的最终结果;
步骤6:参数设置。
本方法参考Devin Kreuzer等人在2021年的工作KreuzerD,Beaini D,HamiltonW,et al.Rethinking graph transformers with spectral attention[J].Advances inNeural Information Processing Systems,2021,34:21618-21629.和Vijay PrakashDwivedi等人在2022年的工作Dwivedi V P,Luu A T,LaurentT,et al.Graph neuralnetworks with learnable structural andpositional representations[J].arXivpreprint arXiv:2110.07875,2021.设置图变换网络层的相关参数,将节点特征和位置编码特征的维度设置为64;
此外,本方法根据验证集的实验性能调节超参数;最终,典型数量M设置为10,典型动作层数设置为3,损失系数λ设置为1.0,融合系数β设置为0.5。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 一种控制清洁模式的方法和清洁机器人
- 一种基于万向轮的升降装置、清洁机器人及其控制方法
- 一种基于虚拟边界的清洁机器人跌落控制方法及芯片
- 一种可转动的柔性驱动光伏清洁机器人及控制方法
- 机器人清洁器和包括机器人清洁器的机器人清洁器系统及机器人清洁器系统的控制方法
- 清洁机器人及用于清洁机器人的控制装置、控制系统和控制方法