基于人工智能技术的数据库查询处理及优化方法
文献发布时间:2023-06-19 09:38:30
技术领域
本发明涉及高维数据索引技术领域,具体涉及一种基于人工智能技术的数据库查询处理及优化方法。
背景技术
关系型数据库目前最常用的数据库类型,但是除了关系数据库外,还有很多数据是直接构建关系数据库的,从而引出了非关系数据库。随着多媒体的信息的发展,图像、文本、视频和音频等数据喷涌而出。针对这类数据的低耗的存储以及高效的查询成为了目前非常热门的研究话题,这种不同媒体的数据可以简单的称为多模态数据。
不同的模态数据在计算中的存储表达形式是不统一的,也就是维度空间并不相同,所以无法进行统一的存储和查询。所以可以通过将不同的模态数据映射到同一个维度空间,进行存储和近邻查询。由于映射到统一的维度空间需要对多模态数据进行维度压缩处理,必然会导致信息的丢失,所以更少的信息丢失,就会获取更高的查询精度。一般针对高维的多媒体数据,会通过特定的函数(比如Locality Sensitive Hashing函数)进行降维处理,映射到同一个维度空间。一般函数的设计是独立于数据的,所以为了考虑的数据的分布以及数据之间的相关性,通过设计深度学习模型带代替特定设计的函数,会在很大程度上减少信息的损失,提高查询的效率。降维后多模态数据通常有两种表达形式:实值和哈希编码。从空间存储的消耗以及查询的效率两方面考虑,哈希编码的存储效率以及查询效率是远高于实值的表达。针对映射到统一空间(汉明空间)的多模态数据,同时可以构建索引进一步加速查询。针对不同模态数据,多模态非关系数据库的设计,可以对不同模态数据有效的存储以及进行近邻查询,同时可以获取不同模态数据之间的关系,挖掘其更深的潜在价值。
目前,现有技术中对于不同的模态数据,有些采用手动提取特征多媒体数据特征,然后通过人工设定函数进行映射处理,这一类方法有个两个显著缺点:手动提取特征会导致信息的损失较大;人工设定映射函数会独立于数据而忽略数据的内在分布特性;通过深度学习模型来代替手动特征提取以及映射函数,更加重视跨模态之间的关系而忽略了单模态内部的信息,同时监督学习的方法往往没有充分挖掘标签信息;如果将哈希编码的学习和索引查询独立成两部分应用,并不能起到很好的检索的效果,然而针对索引来学习特定的哈希码,可以更好的提高查询效率。
发明内容
针对现有技术的不足,本发明的设计思路包括:1、通过深度学习模型将不同模态的数据映射到同一个维度空间(即汉明空间),从而设计统一的存储策略和查询标准;2、对于不同的模态数据,提取特征时考虑数据内部的局部相关性,同时结合标签模型充分挖掘标签信息,在一定程度上减小语义的信息损失,同时保持模态内部以及模态之间的相似度;3、对于生成的哈希编码,通过鸽巢原理加两级哈希索引加速查询效率,同时由于鸽巢原理的原因,为了减少局部语义相似导致的错误候选集生成,对生成的哈希码进行重组,使生成的哈希码更适合索引,从而将哈希编码的学习以及汉明空间索引有效端到端的结合在一起;基于上述设计思路,最终实现一个端到端的基于人工智能技术的数据库查询处理和优化方法。
为实现上述技术效果,本发明提出一种基于人工智能技术的数据库查询处理及优化方法,包括以下步骤:
步骤1:结合多头自注意力机制,利用卷积神经网络将待查询图像特征转换为图像的特征向量;
步骤2:结合bag-of-word策略,利用全连接网络将被查询文本特征转换为文本的特征向量;
步骤3:利用贝叶斯框架以及分类策略作为损失函数,将图像、文本的特征向量转换成哈希编码;
步骤4:对每条哈希编码通过换列策略重新组合语义,取总代价最小的候选集对应的换列策略作为最终的换列标准,包括:
步骤4.1:对每条哈希编码采用换列策略重新组合语义,得到语义重组之后的哈希编码,定义执行第β次换列策略操作后的重组哈希编码为H
步骤4.2:利用鸽巢原理将每条重组哈希编码H
步骤4.3:根据汉明距离从所有重组哈希编码中确定出所有候选集;
步骤4.4:利用公式(1)计算执行第β次换列策略操作后得到候选集的总代价
式中,
步骤4.5:令β=0,1,2,…,Ω,重复步骤3.2~步骤3.4,计算出每次执行换列策略操作后得到候选集的总代价,将总代价最小的候选集对应的换列策略作为最终的换列标准;
步骤5:利用换列标准对哈希编码语义再次进行重新组合得到最终的哈希编码,利用鸽巢原理将最终的哈希编码划分为s段,对每段的哈希编码采用两级哈希索引进行查询处理。
所述步骤1包括:
步骤1.1:利用卷积神经网络提取待查询图像特征的n维特征向量Q;
步骤1.2:将特征向量Q划分为m段的子特征向量{q
步骤1.3:利用查询矩阵W
步骤1.4:利用键矩阵W
步骤1.5:利用值矩阵W
步骤1.6:利用公式(1)~公式(2)对每段子特征向量q
O'=concat(O
步骤1.7:将新的特征向量O'输入到卷积神经网络模型中进行训练,训练过程中利用交叉熵方法、梯度下降策略反向更新卷积神经网络的参数;
步骤1.8:当达到预设迭代次数ζ
所述步骤2包括:
步骤2.1:利用bag-of-word策略将待查询文本特征转化为0-1向量;
步骤2.2:将0-1向量输入到全连接网络模型中进行训练;
步骤2.3:当达到预设迭代次数ζ
所述步骤4.3包括:
步骤4.3.1:计算出两段子哈希编码之间的汉明距离f(x
步骤4.3.2:比较汉明距离f(x
步骤4.3.3:令q=1,2,…ω,遍历计算待查询图像特征的哈希编码与所有被查询文本特征的哈希编码之间的汉明距离并与距离阈值比较,确定出所有的候选集。
所述步骤5中对每段的哈希编码采用两级哈希索引进行查询处理,具体表述为:
步骤5.1:将第r段哈希编码的高d位作为第r段哈希编码的第一级哈希函数,其中r=1,2,……,s;
步骤5.2:利用第一级哈希函数将第r段哈希编码映射到对应的哈希桶中;
步骤5.3:对每个哈希桶中的哈希编码利用除留余数法进行第二级哈希索引,通过两级哈希索引对每段哈希编码进行查询处理。
本发明的有益效果是:
本发明提出了一种基于人工智能技术的数据库查询处理及优化方法,图像、文本的数据内部采用了多头注意力机制,考虑局部区间关系,减少了特征提取过程中的信息损失;不仅考虑模态间的相似程度,同时也考虑模态内的相似程度,使学习到的哈希码精度更高;利用标签网络,充分挖掘了监督标签信息,减少了标签信息损失;对哈希编码进行了语义重组,以及索引优化,加速了查找效率。
附图说明
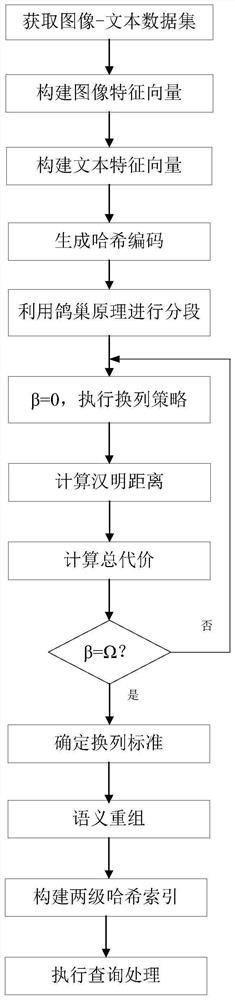
图1为本发明中的基于人工智能技术的数据库查询处理及优化方法流程图。
具体实施方式
下面结合附图和具体实施实例对发明做进一步说明。本发明提出了一个统一的端到端框架,将哈希编码学习和哈希索引优化有机的结合在一起。同时也可以从两阶段来划分:离线阶段和在线阶段。由于训练模型时间复杂度较高,所以一般为离线过程,哈希索引直接在内存中构建索引为在线过程。对于特征学习部分,我们探索了潜在的局部特征相关性,在不需要大量手工标注成本的情况下实现了高精度标注。同时在标签网络保留了多标签的语义信息,保证所有相似对对不同的相似对具有优越的相似性。而且,对于汉明检索,往往是被忽略的一点。我们采用鸽巢原理加两级哈希索引来优化索引,同时我们通过重新组合语义,使生成的哈希码更适合索引,这样将哈希码的学习和索引优化有机端到端的结合在了一起。
如图1所示,一种基于人工智能技术的数据库查询处理及优化方法,包括如下步骤:
步骤1:结合多头自注意力机制,利用卷积神经网络将待查询图像特征转换为图像的特征向量,包括:
步骤1.1:利用卷积神经网络提取待查询图像特征的n维特征向量Q;
步骤1.2:将特征向量Q划分为m段的子特征向量{q
步骤1.3:利用查询矩阵W
步骤1.4:利用键矩阵W
步骤1.5:利用值矩阵W
步骤1.6:利用公式(1)~公式(2)对每段子特征向量q
O'=concat(O
步骤1.7:将新的特征向量O'输入到卷积神经网络模型中进行训练,训练过程中利用交叉熵方法、梯度下降策略反向更新卷积神经网络的参数;
步骤1.8:当达到预设迭代次数ζ
本实施方式中,采用Imaganet数据进行卷积神经网络模型参数的训练。
步骤2:结合bag-of-word策略,利用全连接网络将被查询文本特征转换为文本的特征向量,包括:
步骤2.1:利用bag-of-word策略将待查询文本特征转化为0-1向量,即将文本包含的高频词汇的位置置为1,从而得到一个维度为高频词汇个数的0-1向量;
步骤2.2:将0-1向量输入到全连接网络模型中进行训练;
步骤2.3:当达到预设迭代次数ζ
步骤3:利用贝叶斯框架以及分类策略作为损失函数,将图像、文本的特征向量转换成哈希编码;
步骤4:对每条哈希编码通过换列策略重新组合语义,取总代价最小的候选集对应的换列策略作为最终的换列标准,包括:
步骤4.1:对每条哈希编码采用换列策略重新组合语义,得到语义重组之后的哈希编码,定义执行第β次换列策略操作后的重组哈希编码为H
步骤4.2:利用鸽巢原理将每条重组哈希编码H
步骤4.3:根据汉明距离从所有重组哈希编码中确定出所有候选集,包括:
步骤4.3.1:计算出两段子哈希编码之间的汉明距离f(x
步骤4.3.2:比较汉明距离f(x
步骤4.3.3:令q=1,2,…ω,遍历计算待查询图像特征的哈希编码与所有被查询文本特征的哈希编码之间的汉明距离并与距离阈值比较,确定出所有的候选集。
步骤4.4:利用公式(1)计算执行第β次换列策略操作后得到候选集的总代价
式中,
步骤4.5:令β=0,1,2,…,Ω,重复步骤3.2~步骤3.4,计算出每次执行换列策略操作后得到候选集的总代价,将总代价最小的候选集对应的换列策略作为最终的换列标准;
步骤5:利用换列标准对哈希编码语义再次进行重新组合得到最终的哈希编码,利用鸽巢原理将最终的哈希编码划分为s段,对每段的哈希编码采用两级哈希索引进行查询处理;
其中对每段的哈希编码采用两级哈希索引进行查询处理,具体表述为:
步骤5.1:将第r段哈希编码的高d位作为第r段哈希编码的第一级哈希函数,其中r=1,2,……,s;
步骤5.2:利用第一级哈希函数将第r段哈希编码映射到对应的哈希桶中;
步骤5.3:对每个哈希桶中的哈希编码利用除留余数法进行第二级哈希索引,通过两级哈希索引对每段哈希编码进行查询处理,所谓除留余数法即对数据模32取余数,这样就会将数据映射到32个哈希桶中,通过两级哈希加速各部分划分区间内部的查找。
由于在汉明空间上进行的是位运算,所以计算效率很高,查询时顺序遍历也能达到很高的效率,每一条映射后的数据都是二进制编码,可以认为是一种哈希桶,哈希学习模型则可以认为是哈希函数,当来了条查询的时候就通过哈希学习模型映射到相应的桶里,再进行查找。由于采用的是k近邻检索,所以当来了条查询时,先得到其哈希编码,然后从其汉明距离为0的桶里开始查找,查找是否有k条满足条件的结果,如果没有达到k条,则再从汉明距离为1的哈希桶开始查找,直到找到k条近邻为止。对于一条查询数据,假设长度为gbits,则在数据库中查找汉明距离为G的数据时,需要查找的哈希桶的个数为
由于基于过滤和验证的框架来进行的汉明检索方法的效率依赖于候选集的个数,第二阶段需要对所有的候选集进行的验证,所以如果生成的候选集个数越少,那么查询的效率会越高。
表1给出了X1、X2、X3、X4四个候选集,设距离阈值τ=2,查询q=10000000,如果根据换列策略将第1列、第5列,以及第2列、第6列进行交换,得到的结果如表2所示。
从表2可以看出,换列后的查询候选集缩减为了X1,X2,相对变换之前过滤掉了X3,X4。从结果可以看出,如果对生成的汉明编码进行相应的处理,会得到更少的候选集(减少没有意义的候选集的生成),从而提高了查询效率。我们称这种做法为消除部分语义相关性带来的错误候选集生成。由于哈希编码的每一个维度都代表一个语义信息,为了解决部分语义相关性带来的错误候选集生成,本发明采用换列策略重新组合语义,大大提高了查询效率。
表1传统鸽巢原理方法
表2基于换列策略的鸽巢原理
为验证本发明的有效性,利用Pytorch深度学习框架来实现模型结构,并采用不同的训练策略和参数设置测试模型在各个条件下的实际性能,同时进行消融实验验证模型中各个模块对最终性能的影响程度,具体的实验条件为:
CPU:Inter(R)Core(TM)i7-8700 CPU@3.20Hz 3.19GHZ
GPU:RTX 2070
内存:16.00GB
操作系统平台:Ubuntu 16.04LTS
开发语言:C++、Python
深度学习开发框架:Pytoch
开发工具:VIM、Pycharm、clion
mirflickr25K数据集是从Flickr网站上收集的25000对图像-文本组成。每个实例由24个类别中选择的一个或多个标签进行注释。我们在实验中选择了至少有20个文本标记的点,然后我们得到了20,015个实例。每个文本模态根据数据集中提供的高频词汇表示为一个1,386维的向量,采用的单词袋(BOW)技术。我们随机选择2000对图像-文本对作为查询集,其余的作为检索数据库。然后我们从检索数据库中随机选择10,000个实例进行训练。
nus-wide数据集包含269,648对图像-文本,每个图像-文本对由一个或多个包含81个概念的标签注释。我们选择了其中195,834图像-文本对,它们属于21个最常见概念。每个实例的文本表示为1000-维bag-of-words向量。随机选择2,100对图像-文本对作为查询集,其余的作为检索数据库。然后我们从检索数据库中随机选择10,500个实例进行训练。
实验指标主要是通过平均精度map、召回率与精度两个指标来度量的。
平均精度map实验对比如表3:主要针对64bit维度空间的图查文(简称I->T)和文查图(简称T->I)的map精度对比:
表3平均精度MAP实验对比表
从表3给出的对比结果可以看出,本方法的map精度均优于其他跨模态检索方法,其中SCM为文献《Large-scale supervised multimodal hashing with semanticcorrelation maximization》(D.Zhang and W.J.Li.Large-scale supervisedmultimodal hashing with semantic correlation maximization.In AAAI,pages 2177–2183,2014)中给出的方法,SePH为文献《Semantics-preserving hashing for cross-viewretrieval》(Z.Lin,G.Ding,M.Hu,and J.Wang.Semantics-preserving hashing forcross-view retrieval.In CVPR,2015)中给出的方法,DCMH为文献《Deep Cross-ModalHashing》(Qing-Yuan Jiang,Wu-Jun Li:Deep Cross-Modal Hashing.CVPR 2017:3270-3278)中给出的方法,PRDH为文献《Pairwise relationship guided deep hashing forcross-modal retrieval》(Yang,E.,Deng,C.,Liu,W.,Liu,X.,Tao,D.,&Gao,X.(2017,February).Pairwise relationship guided deep hashing for cross-modalretrieval.In Thirty-first AAAI conference on artificial intelligence)中给出的方法,SSAH为文献《Self-supervised adversarial hashing networks for cross-modalretrieval》(Li,C.,Deng,C.,Li,N.,Liu,W.,Gao,X.,&Tao,D.(2018).Self-supervisedadversarial hashing networks for cross-modal retrieval.In Proceedings of theIEEE conference)中给出的方法,AGAH为文献《Adversary Guided Asymmetric Hashingfor Cross-Modal Retrieval》(Gu,W.,Gu,X.,Gu,J.,Li,B.,Xiong,Z.,&Wang,W.(2019,June).Adversary Guided Asymmetric Hashing for Cross-Modal Retrieval.InProceedings of the 2019on International Conference on Multimedia Retrieval(pp.159-167))中给出的方法。
- 基于人工智能技术的数据库查询处理及优化方法
- 基于人工智能技术的数据库查询处理及优化方法