一种基于深度强化学习的机位调度方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于民航机位调度技术领域,具体地说,是涉及一种基于深度强化学习的机位调度方法。
背景技术
民航机场的停机位调度是在一天之前,根据次日的航班时间表,为即将在机场为起飞、降落和中转的航班分配适当的停机位,最后生成一个停机位调度表,并将此表发送至民航的相关部门以协调停机位的调度工作。在给航班分配停机位的过程中,一方面要考虑航班的类型限制和停留时间限制,避免航班使用停机位的时间产生碰撞。另外一方面需要在满足时间和类型约束的前提下,尽可能地提高安全、效率、经济、质量等指标。
现有技术中,对于民航机位调度,国内外的研究主要关注了两个方面的优化目标:乘客体验和机场效率。从乘客体验的角度来看,停机位调度的优化目标研究早在上世纪70年代就已经开始。当Braaksma和Shortreed首次提出将乘客在机场的总行走距离最小化为目标,他们的目标是提升乘客的旅行便利性。随后,多位研究者纷纷展开相关研究,以深化从乘客体验视角优化停机位调度问题的理解。在这过程中,Mangoubi及其团队专注于最小化转机乘客的行走距离,以优化他们的旅行体验。然后在2001年,Xu和Bailey把旅客的行走时间最小化作为优化目标,从时间角度进一步提升乘客的出行效率。
除了运行效率,停机位调度的鲁棒性也是需要考虑的因素之一。在这方面,研究者们提出了多种优化目标,以保障停机位调度的鲁棒性。比如,降低停机位冲突的数量是一个关键目标。在面对多架航班同时需要使用同一停机位的情况下,如何合理调配,以规避冲突和延误,无疑是一个极富挑战性的问题。
发明内容
本发明的目的在于提供一种基于深度强化学习的机位调度方法,主要解决现有民航机位使用效率低、鲁棒性低的问题。
为实现上述目的,本发明采用的技术方案如下:
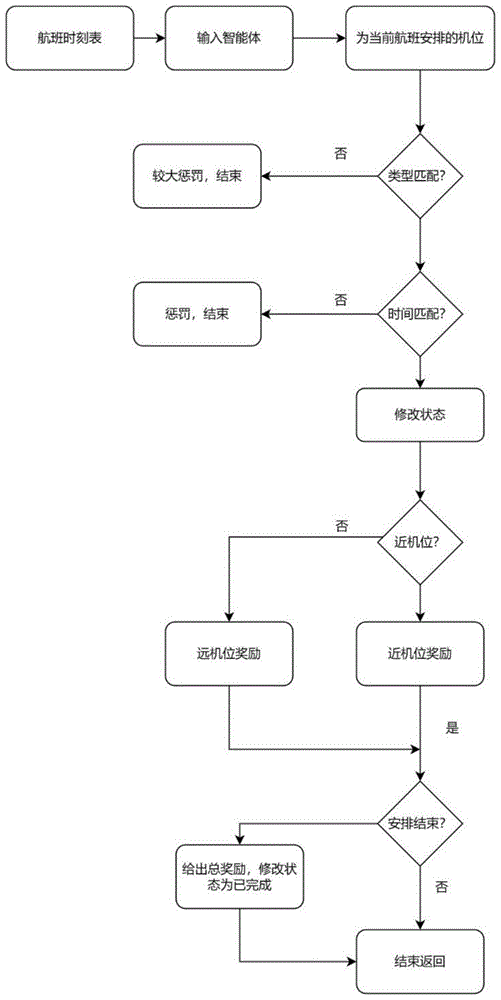
一种基于深度强化学习的机位调度方法,包括以下步骤:
S1,将民航机位基础信息内置于智能体中,向智能体输入需要安排的航班的时刻表;
S2,由智能体为时刻表中的航班以最大化民航机位调度结果的靠桥率作为优化目标依次安排机位,并为优化目标建立机位独占性约束和机位-航班类型匹配约束;
S3,将智能体为当前航班安排的机位输入到民航机位调度环境中,首先由智能体判断大小类型是否匹配,其次再判断时间是否冲突,如果都符合,则进行状态转移操作,修改停机位和航班的状态;
其中,在智能体为当前航班安排的机位输入到民航机位调度环境的过程中,建立包括民航机位调度问题的状态空间模型和动作空间模型的马尔可夫模型,用于描绘智能体与民航机位调度环境间的互动和最优策略的学习过程;
S4,采用基于卷积神经网络的Actor-Critic算法对马尔可夫模型进行模型训练,引导智能体在民航机位调度环境中选择合适的动作对机位进行调度;
S5,根据民航机位调度问题的约束条件和优化目标进行奖励函数的设计,判断安排的机位是近机位还是远机位,如果是近机位则给予近机位立即奖励,如果是远机位则给予远机位立即奖励;
S6,判断所有航班是否都已经安排完毕,如果是,则安排结束,给出环境的总奖励,并修改状态为已完成。
进一步地,在所述步骤S2中,最大化民航机位调度结果的靠桥率的优化目标表达式为:
式中,F是航班数量,S是停机位的总数,x
所述优化目标的约束包括机位独占性约束和机位-航班类型匹配约束;
其中,机位独占性约束的表达式为:
式中,S表示停机位的总数,而x
机位-航班类型匹配约束的表达式为:
M
式中,M
进一步地,在本发明中,所述状态空间模型为一个由纵向合并的停机位状态矩阵和航班状态矩阵形成的多维矩阵;
所述停机位状态矩阵由停机位占用时间矩阵、停机位大小类型矩阵、停机位远近类型矩阵纵向合并构成;
其中,停机位占用时间矩阵的为一个(T+1)×S的0/1矩阵,其中0代表该时间步长的机位是空闲的,而1表示该时间步长的机位被占用;
所述停机位大小类型矩阵和停机位远近类型矩阵的表达式均为:
其中α
所述航班停留时间状态矩阵和航班大小类型状态矩阵纵向合并后得到的所述航班状态矩阵表达式为:
式中,β
进一步地,在本发明中,所述动作空间模型的表达式为:
a
其中a
进一步地,在本发明中,在所述步骤S3中,所述状态转移操作包括停机位状态、航班队列状态和所有状态矩阵共同的纵向维度即时间步的状态更新;
当智能体成功为当前航班选择机位后,更新停机位占用状态矩阵,将被选择机位的当前航班停留时间段标记为已被占用,即在停机位状态矩阵中,将对应机位的对应时间步由0变为1;
当智能体成功为当前航班选择机位后,更新航班状态队列,当前航班的分配结束,将当前航班移出航班队列,添加一个新的航班到队列尾部,将队列头部的航班作为新的当前航班。
进一步地,在本发明中,所述奖励函数的表达式为:
式中,δ为基础奖励值,r
进一步地,在本发明中,在所述基于卷积神经网络的Actor-Critic算法中引入一个权重参数刷新速度慢的称为目标网络的神经网络;所述目标网络的构造和卷积神经网络中的主网络保持一致,所述目标网络用于计算动作价值,所述主网络用于计算预测动作价值;
在所述基于卷积神经网络的Actor-Critic算法中引入经验回放技术,对每个时间步,智能体产生的一个四元组(s,a,r,s′),存储在一个称为经验回放缓冲区,的数据结构中;其中,s表示状态,a表示动作,r表示奖励,s′表示下一状态;
在所述基于卷积神经网络的Actor-Critic算法中引入神经网络掩码技术,创建一个与动作空间相同大小的掩码向量;掩码向量中的每个元素与一个动作相关联,对于合法动作,掩码向量中的相应元素设置为0;对于非法动作,相应元素设置为1。
进一步地,在本发明中,所述基于卷积神经网络的Actor-Critic算法包括如下步骤:
S101,由贝尔曼方程近似得到Critic网络中的价值函数,其中,贝尔曼方程表达式为:
式中,R
S102,用蒙特卡洛近似对贝尔曼方程中右边的期望做近似,再将V
S103,设
式中,
S104,对步骤S103的损失函数的梯度的公式进行梯度下降更新,得到Critic梯度下降更新公式:
式中,
S105,同理,得到Actor网络的参数更新公式:
式中,θ
S106,初始化环境状态s,在回合内的每一步,根据当前航班的进港时刻、机型大小以及机位的空闲开始时间和机位可容纳机型约束规则计算出神经网络掩码m,然后输入状态s和神经网络掩码m到Actor网络中,产生一个动作概率分布;
S107,对动作概率分布进行抽样,得到动作a;将动作a和状态s输入到民航机位调度模拟环境中,从而得到下一状态s′和立即奖励r,得到一个五元组(s,a,m,r,s′);
S108,将五元组(s,a,m,r,s′)作为一条经验存入经验回放池D中,然后从经验池D中随机选择N条经验开始训练Critic网络和Actor网络;
S109,训练得到Critic网络对每条经验当前状态s的价值评估
S110,计算出TD误差
和
更新Actor网络和Critic网络的参数值;
S111,更新设定的步数后,由公式
更新Critic目标网络的参数,式中,
S112,在回合内的每一步结束后,将状态s更新为下一步状态s′,如果达到终止状态,该回合结束,否则返回步骤S106进行迭代,使智能体在每个回合中不断地学习和优化其行为策略。
与现有技术相比,本发明具有以下有益效果:
(1)本发明通过对民航机位调度问题以最大化民航机位调度结果的靠桥率作为优化目标进行马尔可夫建模,设定状态空间、动作空间、状态转移以及奖励函数。采用基于卷积神经网络的Actor-Critic算法,通过卷积神经网络提取状态特征,并通过多层全连接神经网络建立策略网络和价值网络的模型结构对马尔可夫模型进行模型训练求解,从而使得在为飞机提供保障时,保障项目全、保障能力强、物资调配快,同时还能够为飞机提供电力和空调,提高靠桥率,能够大量减少燃油消耗并有利于控制机场的污染物排放。对于乘客来说,由于近机位与航站楼直接相接,提升靠桥率,能够大大减少乘客行走距离,显著提高乘客满意度。
(2)本发明通过在基于卷积神经网络的Actor-Critic算法中引入目标网络,目标网络降低了动作价值的更新频率,使得学习过程更加稳定,减少了震荡和发散的风险。同时由于学习过程变得更加稳定,目标网络技术可以加快算法的收敛速度。除此之外,目标网络能够在某种程度上降低过度拟合的可能性,因为它通过引入一定程度的时间差异来减缓了权重更新。
(3)本发明通过在基于卷积神经网络的Actor-Critic算法中引入经验回放技术,经验回放通过允许智能体多次使用存储在缓冲区中的经验数据,提高了数据利用率。同时,利用随机挑选的mini-batch,经验回放策略成功解决了数据间的时序关联问题,使得学习过程更加稳定。此外,经验回放技术允许智能体在训练期间利用已有的经验数据进行离线学习,从而加速整个学习过程。由于随机抽样的使用,经验回放可以降低模型对特定数据样本的过拟合风险。
(4)本发明通过在基于卷积神经网络的Actor-Critic算法中引入神经网络掩码技术,神经网络掩码技术同时可以减少智能体尝试非法动作所花费的时间,从而加速整个学习过程。在某些应用场景中(如自动驾驶、机器人控制等),非法动作可能导致严重后果,使用神经网络掩码技术屏蔽非法动作可以提高系统的安全性。
附图说明
图1为本发明调度方的流程结构示意图。
图2为本发明-实施例中5种算法模型训练对比图。
图3为本发明-实施例中5中算法靠桥率对比图。
具体实施方式
下面结合附图说明和实施例对本发明作进一步说明,本发明的方式包括但不仅限于以下实施例。
实施例
如图1所示,本发明公开的一种基于深度强化学习的机位调度方法,包括以下步骤:
首先,将民航机位基础信息内置于智能体中,向智能体输入需要安排的航班的时刻表;
然后,由智能体为时刻表中的航班以最大化民航机位调度结果的靠桥率作为优化目标依次安排机位,并为优化目标建立机位独占性约束和机位-航班类型匹配约束;其中,最大化民航机位调度结果的靠桥率的优化目标表达式为:
式中,F是航班数量,S是停机位的总数,x
所述优化目标的约束包括机位独占性约束和机位-航班类型匹配约束;
机位独占性约束,即在同一时刻一个机位只能分配给一个航班,其表达式为:
式中,S表示停机位的总数,而x
机位-航班类型匹配约束,即航班必须与安排的机位的类型匹配。在实际场景中,航班类型涉及到航空公司类型约束,航空任务类型约束,航空属性类型约束以及航班机型类型约束。在与民航合作方交流中得知,实际运行过程中,除了航班机型约束,其余三种约束,可以根据实际情况不遵守。本实施例将机位-航班类型约束简化为航班的机型约束,而机型约束实际上是确保机位大小与航班机型大小相匹配的约束。因此将机位和航班机型根据大小分为大、小两种类型。机位可以容纳匹配大小的机型及较小机型。机位-航班类型匹配约束的表达式为:
M
式中,M
其次,将智能体为当前航班安排的机位输入到民航机位调度环境中,首先由智能体判断大小类型是否匹配,其次再判断时间是否冲突,如果都符合,则进行状态转移操作,修改停机位和航班的状态。
其中,在智能体为当前航班安排的机位输入到民航机位调度环境的过程中,建立包括民航机位调度问题的状态空间模型和动作空间模型的马尔可夫模型,用于描绘智能体与民航机位调度环境间的互动和最优策略的学习过程。
停机位的状态信息中包含停机位占用时间状态信息,停机位远近类型状态信息,停机位大小类型状态信息。停机位占用时间状态信息反映的是每个停机位在哪些时间步被占用,而在哪些时间步空闲,是将未来航班安排到空闲机位上的必要信息。停机位远近类型状态信息是反映停机位属于远机位,还是近机位,使智能体能够根据这个状态信息来学习将航班尽可能地安排到近机位上,提高靠桥率。停机位大小类型状态信息标识出了停机位能够容纳的最大机型,使智能体能够根据这个信息,将航班安排到大小匹配的机位上去。
航班状态数据涵盖了现行航班的详细情况及未来航班的预期信息,用一个队列来容纳当前航班和未来航班的状态信息。这是因为航班的调度不仅需要考虑当前航班在停机位上停靠的时间,还需要考虑相邻时间的其它航班的停靠时间,来避免时间上的冲突。因此,航班的状态数据必须涵盖现行航班的详细信息以及预期的未来航班信息。当前航班处于队列的头部,未来航班依次在队列中按到达的时间先后依次排列。每一个航班的状态信息包括航班在机位停留的开始时刻和结束时刻,用一个时间段表示,此外还有航班的大小类型信息。
为了使神经网络更方便地从状态矩阵中提取特征,同时加快模型收敛速度,本实施例将所有状态矩阵均用0/1矩阵进行表示。受启发于AlphaGO的多维矩阵状态空间设计,本实施例将停机位状态矩阵和航班状态矩阵,纵向合并,形成一个多维矩阵作为状态空间。
停机位的状态信息,包括停机位的占用时间,可以通过一个0/1矩阵来表示。在这个矩阵中,横坐标代表机场的停机位编号,而纵坐标表示从当前时刻到设定的时间步长T+1的停机位占用状态。这种表示方式可以在数学上表述为一个(T+1)×S的0/1矩阵。在这个矩阵中,0代表该时间步长的机位是空闲的,而1表示该时间步长的机位被占用。设当前时刻为t,则当前时刻的停机位状态矩阵公式为:
若a
为了维持所有状态矩阵的形状一致性,以便卷积神经网络能够从中提取特征。本实施例将停机位大小类型状态矩阵和停机位远近类型状态矩阵都使用与停机位占用时间矩阵同样的大小的状态矩阵表示。横向代表机场停机位的编号,纵向无实际意义,但是数量与时间步总数保持一致。停机位大小类型状态矩阵和停机位远近类型状态矩阵表达式均为:
其中α
航班状态信息中的航班停留时间状态用一个0/1矩阵进行表示。纵向坐标轴为当前时刻至固定时间步的停机位占用情况,设这个时间步总数为T+1。横向无实际意义,但是为了能够与停机位状态矩阵保持相同形状,将横向维数设置为停机位的数量。数学上,其可以用一个(T+1)×S的0/1矩阵表示。矩阵中全为0的一行代表航班在该时间步不使用机位,为1则代表航班在该时间步需要使用机位。设当前时刻为t,则当前时刻的航班状态矩阵表达式为:
其中β
航班大小类型矩阵用一个全0或者全1的矩阵表示。为了维持状态矩阵的大小一致,也用一个(T+1)×S大小的矩阵表示。矩阵全为1时,代表的是大型机型的航班;相反,如果矩阵全为0,则表示的是小型机型的航班。
将每个航班的两个状态矩阵纵向合并,再将航班队列里所有航班的状态矩阵纵向合并得到航班状态矩阵。
假设智能体同时对F个航班进行机位分配,则动作空间大小为F
a
其中a
在智能体成功为当前航班分配机位后,环境需要给出下一时刻的状态,这就是需要进行状态转移操作。
状态空间的矩阵中涉及到两个部分的状态:停机位状态和航班队列状态。同时还有所有状态矩阵共同的纵向维度,时间步。所以,状态转移是这三部分状态的更新。首先更新航班队列,和停机位占用时间状态矩阵。之后,根据航班队列第一个航班的进港时刻更新时间步的开始时刻,之后将所有状态矩阵的时间步开始时刻更新,将时间步移动到对应时间段。设状态转移后的时间步开始时刻为t
当智能体成功为当前航班选择机位后,更新停机位占用状态矩阵。将被选择机位的当前航班停留时间段标记为已被占用。即在停机位状态矩阵中,将对应机位的对应时间步由0变为1.
更新航班状态队列,当智能体成功为当前航班选择机位后,当前航班的分配结束。将当前航班移出航班队列,添加一个新的航班到队列尾部。将队列头部的航班作为新的当前航班。
每当智能体在民航机位调度环境中做出一个动作选择并引发状态转移,就会获得一个即时奖励。如果航班被分配到近距离的机位,奖励为正值;若被分配到远距离的机位,则奖励为负值。这样可以使智能体尽可能选择近机位进行,从而实现提升靠桥率的优化目标。立即奖励公式为:
其中r
其中F是航班数量,S是机位数量,x
随后,采用基于卷积神经网络的Actor-Critic算法对马尔可夫模型进行模型训练,引导智能体在民航机位调度环境中选择合适的动作对机位进行调度。
基于本实施例构建的马尔可夫模型,解决民航机位调度问题。借助卷积神经网络,对多维状态矩阵的特征进行抽取,然后利用多层全连接网络建立策略网络和价值网络,从而执行Actor-Critic方法。在策略网络的输出之前使用神经网络掩码屏蔽掉非法的动作,即禁止为当前航班选择已经被占用的机位。同时在训练Actor-Critic算法时使用目标网络技术和经验回放技术,来使训练过程更加稳定,加快模型收敛速度,同时减少过拟合的风险。
Actor-Critic算法与卷积神经网络(CNN)相结合,可以实现更高效且精确的调度任务。在此组合中,Actor-Critic方法主导着决策和控制过程,而CNN则负责从环境状态中提取特征并提供有价值的信息。将CNN应用于Actor-Critic算法使其能够从环境状态表示中抽取关键特征,而这些特征的输出则作为Actor和Critic的输入,以便根据这些特征选择动作和评估价值。由于CNN能捕捉局部和全局特征,它提高了Actor-Critic算法的学习速度和准确性,从而加快了收敛速度。同时,CNN具有良好的泛化能力,使得Actor-Critic算法能够在不同环境和任务中泛化以应对新情况。
民航调度问题中的各类矩阵被输入到卷积神经网络中,以提取出特征向量。然后,这些特征向量被独立地输送至Actor网络和Critic网络。这两个网络都由全连接层构成。
在Actor网络中,输入通过Softmax激活函数进行处理,生成一个概率分布,用于表示执行各个动作的可能性。这种概率分布可用于引导智能体在环境中选择合适的动作,同时允许一定程度的探索,以获取更多关于环境的信息。
与此同时,Critic网络的职责是进行动作价值的评价。这个评估有助于引导智能体在学习过程中调整其行为策略,以便更好地优化长期收益。Critic网络的产出能被用作回馈信息,有助于调节Actor网络的参数,以便达成更优的学习效果。
在深度强化学习中,通常使用一个神经网络(如卷积神经网络或全连接神经网络)来表示值函数或Q函数。在学习过程中,这个网络会不断地更新权重,以便更好地逼近真实的值函数。然而,这种不断更新可能导致学习过程不稳定和震荡。
为了解决这个问题,本实施例引入了一个额外的神经网络,称为目标网络。目标网络的构造和主网络保持一致,然而,它的权重参数的刷新速度相对较缓。在训练过程中,目标网络的权重会定时从主网络获取同步。具体来说,目标网络用于计算动作价值,而主网络用于计算预测动作价值。通过这种方式,目标网络技术可以使学习过程更加稳定。
目标网络降低了动作价值的更新频率,使得学习过程更加稳定,减少了震荡和发散的风险。同时由于学习过程变得更加稳定,目标网络技术可以加快算法的收敛速度。除此之外,目标网络能够在某种程度上降低过度拟合的可能性,因为它通过引入一定程度的时间差异来减缓了权重更新。
在基于卷积神经网络的Actor-Critic算法中因为用Critic网络的输出来近似动作价值。所以将目标网络应用于Critic网络的训练过程中。
在强化学习环境下,智能体和环境进行互动,借助试错方式探索最佳策略。在每个时间步,智能体会产生一个四元组(s,a,r,s′)存储在一个称为经验回放缓冲区的数据结构中;其中,s表示状态,a表示动作,r表示奖励,s′表示下一状态。当智能体需要进行学习更新时,经验回放方法将从缓存区随机挑选一组四元组9s,a,r,s′),这称为mini-batch。利用这些提取出来的经验数据来进行Actor网络与Critic网络的更新。
经验回放通过允许智能体多次使用存储在缓冲区中的经验数据,提高了数据利用率。同时,利用随机挑选的mini-batch,经验回放策略成功解决了数据间的时序关联问题,使得学习过程更加稳定。此外,经验回放技术允许智能体在训练期间利用已有的经验数据进行离线学习,从而加速整个学习过程。由于随机抽样的使用,经验回放可以降低模型对特定数据样本的过拟合风险。
在强化学习中,智能体在某些状态下可能会遇到非法动作,即在特定状态下不允许执行的动作。为了确保智能体遵循这些限制,可以使用神经网络掩码技术屏蔽非法动作。这种方式使本实施例有能力在智能体的探索和学习过程中,指导其遵守环境法则。
神经网络掩码技术是通过对神经网络的输出进行修改来实现的。在使用神经网络(如卷积神经网络或全连接神经网络)表示值函数或策略函数时,可以创建一个与动作空间相同大小的掩码向量(mask vector)。掩码向量中的每个元素与一个动作相关联。对于合法动作,掩码向量中的相应元素设置为0;对于非法动作,相应元素设置为1。将网络输出(如Q值或策略概率)与掩码向量进行按元素相乘。这会将非法动作的输出值设置为一个很小的值,从而屏蔽这些动作。通过屏蔽非法动作,神经网络掩码技术确保智能体在学习过程中遵循环境的规则和限制。掩码技术同时可以减少智能体尝试非法动作所花费的时间,从而加速整个学习过程。在某些应用场景中(如自动驾驶、机器人控制等),非法动作可能导致严重后果。使用神经网络掩码技术屏蔽非法动作可以提高系统的安全性。
神经网络应用于基于深度强化学习的民航机位调度算法中,Actor网络的输出值通过Softmax函数激活,得到动作的选择概率向量,将这个向量与神经网络掩码向量相乘后,使非法的动作的概率值无限趋近于0变为不可能动作,再由这个修改后的概率向量生成动作的概率分布,然后从这个分布中随机抽样输出Actor网络选择的动作值。
综上,所述基于卷积神经网络的Actor-Critic算法具体包括如下步骤:
S101,由贝尔曼方程近似得到Critic网络中的价值函数,其中,贝尔曼方程表达式为:
式中,R
S102,用蒙特卡洛近似对贝尔曼方程中右边的期望做近似,再将V
S103,设
式中,
S104,对步骤S103的损失函数的梯度的公式进行梯度下降更新,得到Critic梯度下降更新公式:
式中,
S105,同理,得到Actor网络的参数更新公式:
式中,θ
S106,初始化环境状态s,在回合内的每一步,根据当前航班的进港时刻、机型大小以及机位的空闲开始时间和机位可容纳机型约束规则计算出神经网络掩码m,然后输入状态s和神经网络掩码m到Actor网络中,产生一个动作概率分布;
S107,对动作概率分布进行抽样,得到动作a;将动作a和状态s输入到民航机位调度模拟环境中,从而得到下一状态s′和立即奖励r,得到一个五元组(s,a,m,r,s′);
S108,将五元组(s,a,m,r,s′)作为一条经验存入经验回放池D中,然后从经验池D中随机选择N条经验开始训练Critic网络和Actor网络;
S109,训练得到Critic网络对每条经验当前状态s的价值评估
S110,计算出TD误差
和
更新Actor网络和Critic网络的参数值;
S111,更新设定的步数后,由公式
更新Critic目标网络的参数,式中,
S112,在回合内的每一步结束后,将状态s更新为下一步状态s′,如果达到终止状态,该回合结束,否则返回步骤S106进行迭代,使智能体在每个回合中不断地学习和优化其行为策略。
再有,根据民航机位调度问题的约束条件和优化目标进行奖励函数的设计,判断安排的机位是近机位还是远机位,如果是近机位则给予近机位立即奖励,如果是远机位则给予远机位立即奖励;
最后,判断所有航班是否都已经安排完毕,如果是,则安排结束,给出环境的总奖励,并修改状态为已完成。
以国内民航某机场2022年8月8日的实际运行数据中的838架航班和该机场的297个机位作为原始训练数据为例。
表1中摘录了部分凌晨航班数据,表2中摘录了部分白天航班数据。如表1、2中所示,航班的数据中包含,航班的航空公司、航班号、区域属性、机号、机型、计划进港时间、计划出港时间、IATA完整航线、IATA航线属性。其中关键属性为机型、计划进港时间、计划出港时间,这三个属性与为航班安排机位息息相关。机型用来确定与航班机型匹配的机位。计划进出港时间,用来确定航班在机位上的停留时间。两张表表明,深夜的航班在机场的滞留时长更久,通常为6至9小时左右,相比之下,白日的航班在机场的滞留时间更短,通常只有1至3小时左右。
表1凌晨航班数据摘录
表2白天航班数据摘录
表3中摘录了机场的部分机位信息数据。其中包括机位的停靠属性、代理属性、状态属性、长度、宽度属性。其中机位的停靠属性和长度宽度属性是机位的关键属性,用来确定机位是远机位还是近机位(图中叫廊桥机位),以及确定机位最大能停放的机型大小。另外,如表3中所示,虽然机场总共有297个机位,但是有很多机位由于多方面原因不能使用,所以机场总共可供使用的机位是不足297个的。
表3机位数据摘录
表4是机位-机型约束信息的部分摘录。从表4中可以看出,每一个机位可以匹配的机型规则十分复杂,不利于算法实现和验证效果。所以之后需要对机位-机型约束进行简化处理。
表4是机位-机型约束信息的部分摘录
对于航班数据,首先需要处理的是航班的计划进出港时刻。将数据以时间格式直接输入并不适于程序进行数据处理。所以将时间数据统一转化为分钟表示。首先将航班数据中的最早的航班的进港时刻作为基准时刻,设置为0,其余时间根据与基准时刻的分钟数差值设置,通过这种方式将所有进出港时刻转化为整数。另外对于航班复杂的机型,我们根据机型的大小,将所有机型简化为两种机型,即大机型,小机型,可以直接使用0/1表示两种机型。转化后的部分示例数据如表5所示。同时,将航班的ID简化为如1,2,3…的序列。航班数据总数为838条,其中大机型占比30%,小机型占比70%。
表5航班简化数据摘录
对于机位数据,除去不能正常使用的机位,可用机位总数为250个。在这个250个机位中有74个为近机位,约占30%左右。此外,在远机位中大型机位约占比55%,小型机位约占比45%。在近机位中,大型机位约占比40%,小型机位约占比60%。
根据上述数据,本实施例分别使用基于深度强化学习的民航机位调度方法、先来先服务算法、最短时间优先算法、遗传算法、禁忌搜索算法进行调度。设置迭代次数为1000次,训练结果如图所示,算法的迭代次数被标示在横坐标上,纵坐标为算法的靠桥率。其中因为先来先服务算法与最短时间优先算法是固定策略的算法,所以在训练过程的图像为一条平行与横坐标轴的直线。而基于深度强化学习的民航机位调度算法、遗传算法、禁忌搜索算法的靠桥率随着迭代次数的增加而逐渐提升,直到最后算法收敛稳定。由图2可以看出,基于深度强化学习的民航机位调度算法(DRL-AGA)的靠桥率依次高于禁忌搜索算法(TabuSearch),遗传算法(GA),最短时间优先算法(STF)和先来先服务算法(FCFS)。因此,本实施例的调度方法取得了较好的实验结果。
根据五种算法的训练结果,得到五种算法的机位调度结果的靠桥率对比图如图3所示。本实施例的基于深度强化学习的民航机位调度算法的靠桥率能够达到81.5%,高于禁忌搜索算法和遗传算法的79.5%和78.5%的靠桥率,更远高于先来先服务算法和最短时间优先算法的75.2%和67.8%的靠桥率。
综上,本实施例采用基于深度强化学习的民航机位调度方法,利用卷积神经网络提取环境状态的特征信息,能够应对复杂的状态空间。通过经验回放技术,能够避免陷入数据前后序列的相关性中,得到更加泛化的策略。通过目标网络技术能够使算法稳定收敛。最后通过神经网络掩码技术,能够避免非法的机位调度结果。通过这些技术和设计,最终该方法的调度结果能够达到0.815的靠桥率,取得了很好的效果。比禁忌搜索算法高3.5%,比遗传算法高4.4%,比最短时间优先算法高7.8%,比先来先服务算法高20.2%。
上述实施例仅为本发明的优选实施方式之一,不应当用于限制本发明的保护范围,但凡在本发明的主体设计思想和精神上作出的毫无实质意义的改动或润色,其所解决的技术问题仍然与本发明一致的,均应当包含在本发明的保护范围之内。
- 一种基于深度强化学习的计算卸载调度方法
- 基于深度强化学习的零超调量无人机位置控制方法及装置
- 基于深度强化学习的零超调量无人机位置控制方法及装置